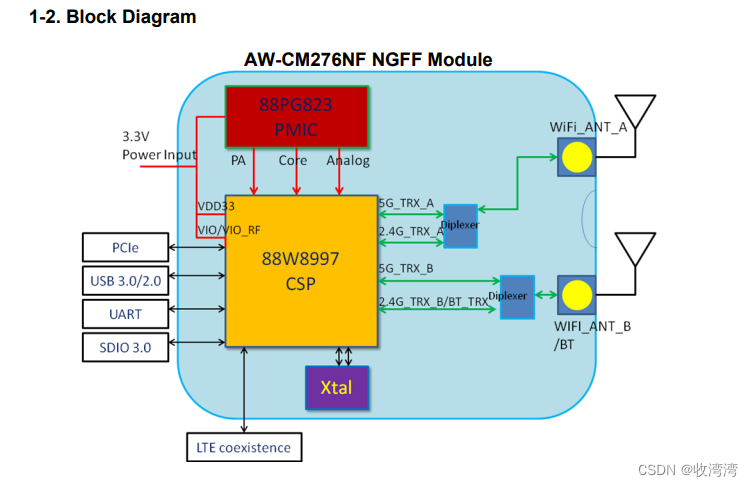
List 和HashSet同时查询40万条数据,谁的效率更高?
//**1.下面是List底层源码**
public boolean contains(Object o) {
//如果查到我们想要查询的值则返回一个true,否则返回false,
return indexOf(o) >= 0;//这里是调用了indexOf方法,并且判断是否有值>=0;
}
//下面再看IndexOf这个方法,是如何给我们实现40w条数据当中如何进行查询
public int indexOf(Object o) {
//判断我里面是否有我们输入的值,所以我们如果要查询的话,肯定是要走else
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
//直接看这里,ArrayList他这里是一个循环
for (int i = 0; i < size; i++)
//内部是使用if来判断,判断40w条数据当中,是否有我们需要查询的值,查询到了并且会返回,如果需要查询40w次,也就是意味着需要循环判断40w次,所以这种效率是非常低下。
if (o.equals(elementData[i]))
return i;
}
return -1;
}
}
HashSet
// HashSet的contains()方法,可以看到HashSet底层他是调用了map集合的containsKey方法
public boolean contains(Object o) {
return map.containsKey(o);
}
//containsKey方法,他调用了getNode方法,
public boolean containsKey(Object key) {
调用getNode方法,并且这里做了一个判断,其意思是,我们add的时候,他是做了一个 hash值的运算,然后当我们去取的时候,他是直接计算我们要取的值的Hash值,
return getNode(hash(key), key) != null;
}
//这个是 getNode 方法,可以看到这两个参数,他是根据你传进去的key和hash值存放到对应的节点。所以我们再使用hashSet进行查询的时候,hashset他是根据对象的hash值和key来直接进行定位的,所以其效率要高于ArrayList。
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}大数据量很大时,由于HashSet对存入值进行hash处理,所以在比对是否存在时会非常快