Redis高级特性和应用(慢查询、Pipeline、事务、Lua)
Redis的慢查询
许多存储系统(例如 MySQL)提供慢查询日志帮助开发和运维人员定位系统存在的慢操作。所谓慢查询日志就是系统在命令执行前后计算每条命令的执行时间,当超过预设阀值,就将这条命令的相关信息(例如:发生时间,耗时,命令的详细信息)记录下来,Redis也提供了类似的功能。
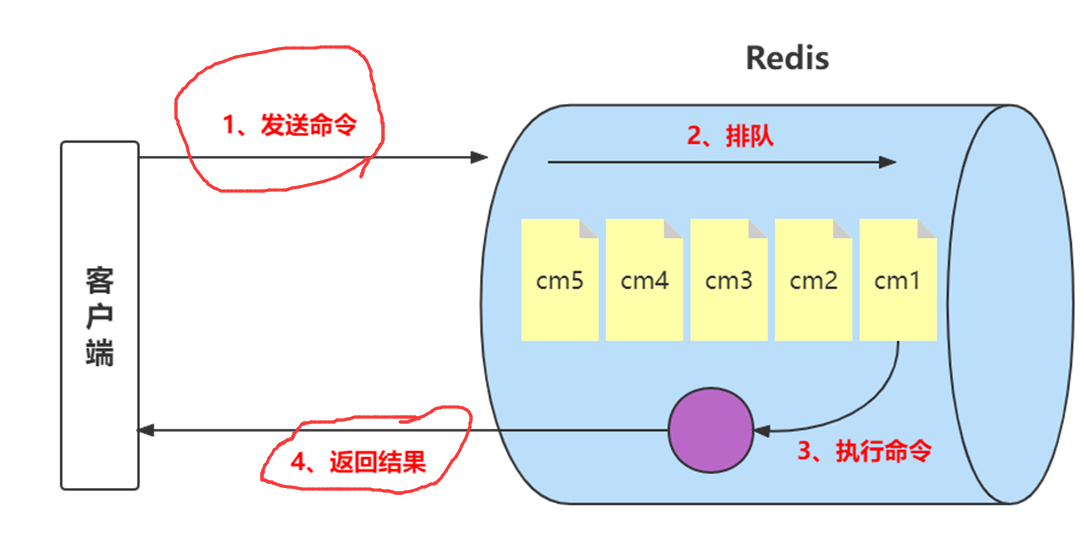
Redis客户端执行一条命令分为如下4个部分:
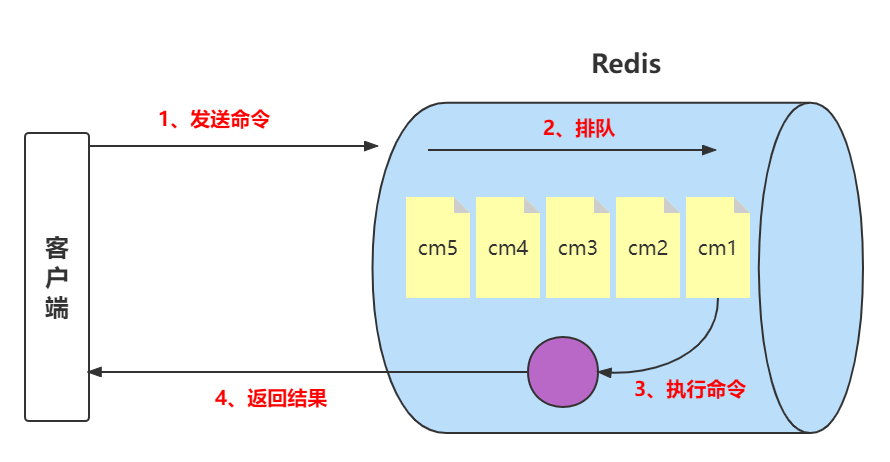
1、发送命令
2、命令排队
3、命令执行
4、返回结果
需要注意,慢查询只统计步骤3的时间,所以没有慢查询并不代表客户端没有超时问题。因为有可能是命令的网络问题或者是命令在Redis在排队,所以不是说命令执行很慢就说是慢查询,而有可能是网络的问题或者是Redis服务非常繁忙(队列等待长)。
慢查询配置
对于任何慢查询功能,需要明确两件事:多慢算慢,也就是预设阀值怎么设置?慢查询记录存放在哪?
Redis提供了两种方式进行慢查询的配置
1、动态设置
慢查询的阈值默认值是10毫秒
参数:slowlog-log-slower-than就是时间预设阀值,它的单位是微秒(1秒=1000毫秒=1 000 000微秒),默认值是10 000,假如执行了一条“很慢”的命令(例如keys *),如果它的执行时间超过了10 000微秒,也就是10毫秒,那么它将被记录在慢查询日志中。
我们通过动态命令修改
config set slowlog-log-slower-than 20000

使用config set完后,若想将配置持久化保存到Redis.conf,要执行config rewrite

config rewrite

注意:
如果配置slowlog-log-slower-than=0表示会记录所有的命令,slowlog-log-slower-than<0对于任何命令都不会进行记录。
2、配置文件设置(修改后需重启服务才生效)
打开Redis的配置文件redis.conf,就可以看到以下配置:

slowlog-max-len用来设置慢查询日志最多存储多少条

另外Redis还提供了slowlog-max-len配置来解决存储空间的问题。


实际上Redis服务器将所有的慢查询日志保存在服务器状态的slowlog链表中(内存列表),slowlog-max-len就是列表的最大长度(默认128条)。当慢查询日志列表被填满后,新的慢查询命令则会继续入队,队列中的第一条数据机会出列。
虽然慢查询日志是存放在Redis内存列表中的,但是Redis并没有告诉我们这里列表是什么,而是通过一组命令来实现对慢查询日志的访问和管理。并没有说明存放在哪。这个怎么办呢?Redis提供了一些列的慢查询操作命令让我们可以方便的操作。
慢查询操作命令
获取慢查询日志
slowlog get [n]
参数n可以指定查询条数。
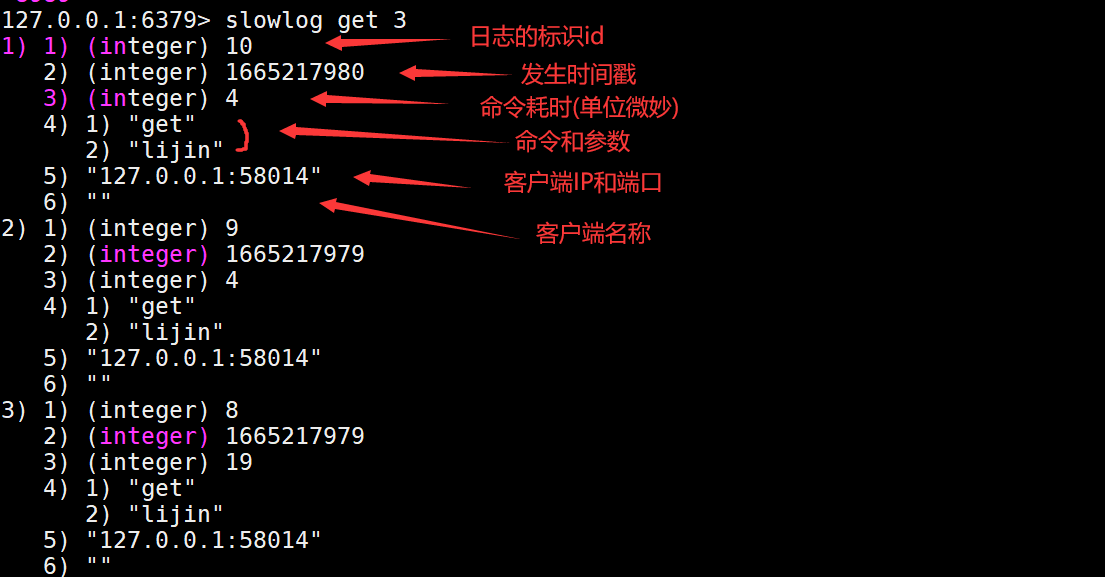
可以看到每个慢查询日志有6个属性组成,分别是慢查询日志的标识id、发生时间戳、命令耗时(单位微秒)、执行命令和参数,客户端IP+端口和客户端名称。
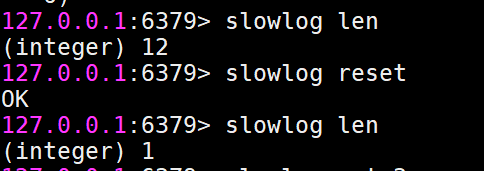
获取慢查询日志列表当前的长度
slowlog len

慢查询日志重置
slowlog reset
实际是对列表做清理操作
慢查询建议
慢查询功能可以有效地帮助我们找到Redis可能存在的瓶颈,但在实际使用过程中要注意以下几点:
slowlog-max-len配置建议:
建议调大慢查询列表,记录慢查询时Redis会对长命令做截断操作,并不会占用大量内存。增大慢查询列表可以减缓慢查询被剔除的可能,线上生产建议设置为1000以上。
slowlog-log-slower-than配置建议: 配置建议:默认值超过10毫秒判定为慢查询,需要根据Redis并发量调整该值。
由于Redis采用单线程响应命令,对于高流量的场景,如果命令执行时间在1毫秒以上,那么Redis最多可支撑OPS不到1000。因此对于高OPS场景的Redis建议设置为1毫秒或者更低比如100微秒。
慢查询只记录命令执行时间,并不包括命令排队和网络传输时间。因此客户端执行命令的时间会大于命令实际执行时间。因为命令执行排队机制,慢查询会导致其他命令级联阻塞,因此当客户端出现请求超时,需要检查该时间点是否有对应的慢查询,从而分析出是否为慢查询导致的命令级联阻塞。
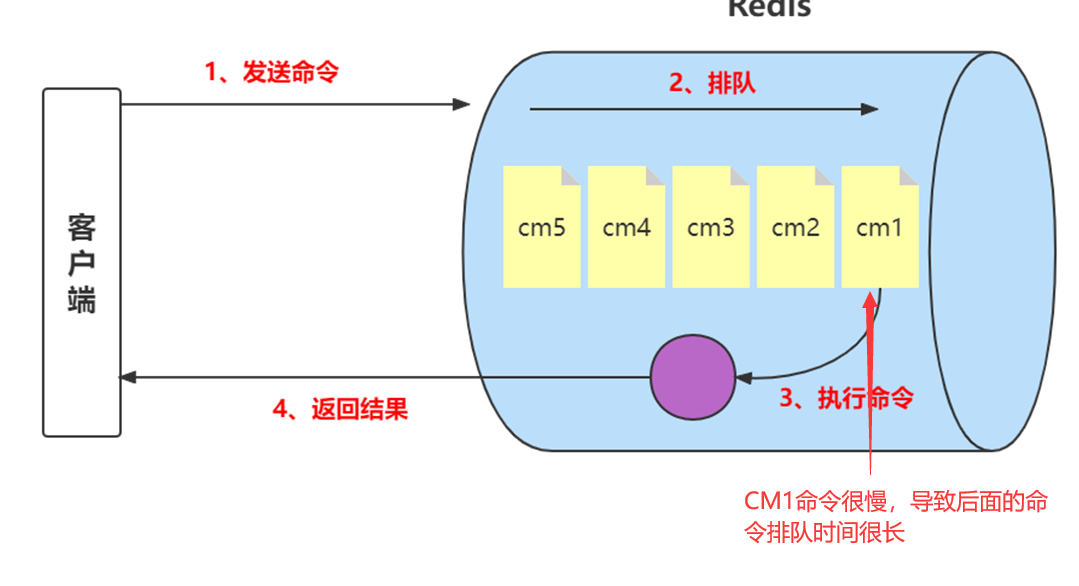
由于慢查询日志是一个先进先出的队列,也就是说如果慢查询比较多的情况下,可能会丢失部分慢查询命令,为了防止这种情况发生,可以定期执行slow get命令将慢查询日志持久化到其他存储中。
Pipeline
前面我们已经说过,Redis客户端执行一条命令分为如下4个部分:1)发送命令2)命令排队3)命令执行4)返回结果。
其中1和4花费的时间称为Round Trip Time (RTT,往返时间),也就是数据在网络上传输的时间。
Redis提供了批量操作命令(例如mget、mset等),有效地节约RTT。
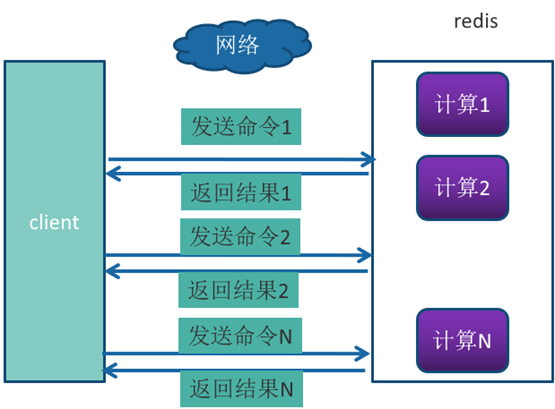
但大部分命令是不支持批量操作的,例如要执行n次 hgetall命令,并没有mhgetall命令存在,需要消耗n次RTT。
举例:Redis的客户端和服务端可能部署在不同的机器上。例如客户端在本地,Redis服务器在阿里云的广州,两地直线距离约为800公里,那么1次RTT时间=800 x2/ ( 300000×2/3 ) =8毫秒,(光在真空中传输速度为每秒30万公里,这里假设光纤为光速的2/3 )。而Redis命令真正执行的时间通常在微秒(1000微秒=1毫秒)级别,所以才会有Redis 性能瓶颈是网络这样的说法。
Pipeline(流水线)机制能改善上面这类问题,它能将一组 Redis命令进行组装,通过一次RTT传输给Redis,再将这组Redis命令的执行结果按顺序返回给客户端,没有使用Pipeline执行了n条命令,整个过程需要n次RTT。
使用Pipeline 执行了n次命令,整个过程需要1次RTT。
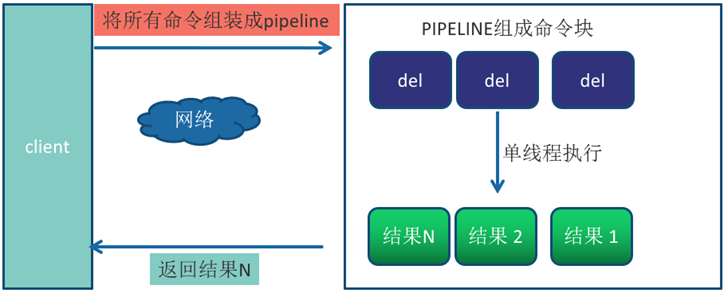
Pipeline并不是什么新的技术或机制,很多技术上都使用过。而且RTT在不同网络环境下会有不同,例如同机房和同机器会比较快,跨机房跨地区会比较慢。
redis-cli的--pipe选项实际上就是使用Pipeline机制,但绝对部分情况下,我们使用Java语言的Redis客户端中的Pipeline会更多一点。
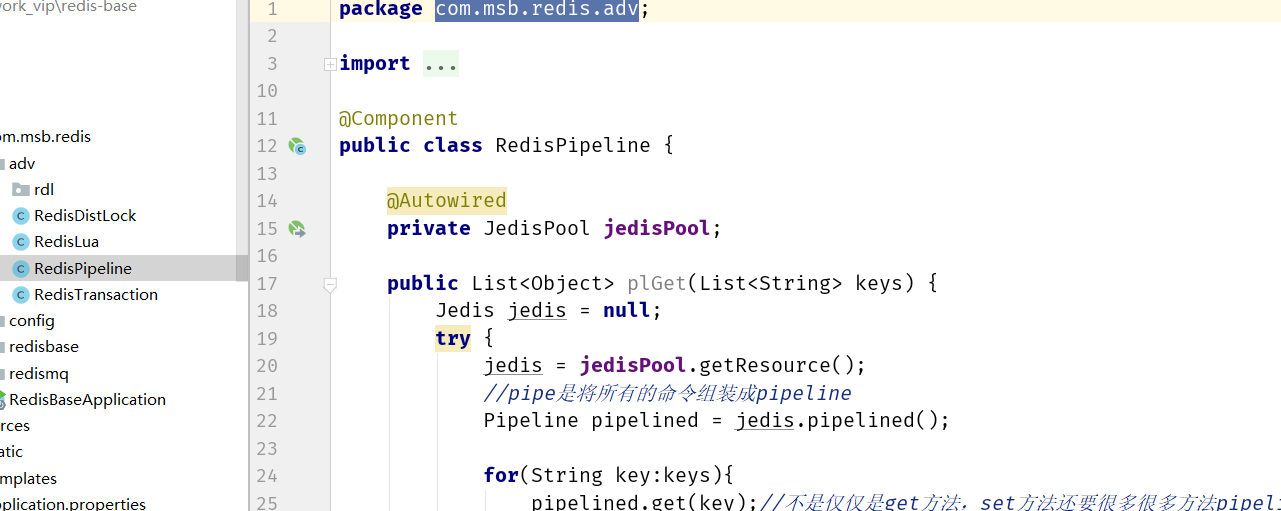
代码参见:
com.msb.redis.adv.RedisPipeline
总的来说,在不同网络环境下非Pipeline和Pipeline执行10000次set操作的效果,在执行时间上的比对如下:

差距有100多倍,可以得到如下两个结论:
1、Pipeline执行速度一般比逐条执行要快。
2、客户端和服务端的网络延时越大,Pipeline的效果越明显。
Pipeline虽然好用,但是每次Pipeline组装的命令个数不能没有节制,否则一次组装Pipeline数据量过大,一方面会增加客户端的等待时间,另一方面会造成一定的网络阻塞,可以将一次包含大量命令的Pipeline拆分成多次较小的Pipeline来完成,比如可以将Pipeline的总发送大小控制在内核输入输出缓冲区大小之内或者控制在单个TCP 报文最大值1460字节之内。
内核的输入输出缓冲区大小一般是4K-8K,不同操作系统会不同(当然也可以配置修改)
最大传输单元(Maximum Transmission Unit,MTU),这个在以太网中最大值是1500字节。那为什么单个TCP 报文最大值是1460,因为因为还要扣减20个字节的IP头和20个字节的TCP头,所以是1460。
同时Pipeline只能操作一个Redis实例,但是即使在分布式Redis场景中,也可以作为批量操作的重要优化手段。
事务
大家应该对事务比较了解,简单地说,事务表示一组动作,要么全部执行,要么全部不执行。
例如在社交网站上用户A关注了用户B,那么需要在用户A的关注表中加入用户B,并且在用户B的粉丝表中添加用户A,这两个行为要么全部执行,要么全部不执行,否则会出现数据不一致的情况。
Redis提供了简单的事务功能,将一组需要一起执行的命令放到multi和exec两个命令之间。multi 命令代表事务开始,exec命令代表事务结束。另外discard命令是回滚。
一个客户端
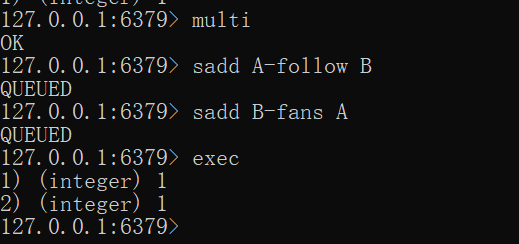
另外一个客户端
在事务没有提交的时查询(查不到数据)
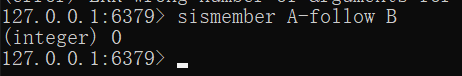
在事务提交后查询(可以查到数据)

可以看到sadd命令此时的返回结果是QUEUED,代表命令并没有真正执行,而是暂时保存在Redis中的一个缓存队列(所以discard也只是丢弃这个缓存队列中的未执行命令,并不会回滚已经操作过的数据,这一点要和关系型数据库的Rollback操作区分开)。
只有当exec执行后,用户A关注用户B的行为才算完成,如下所示exec返回的两个结果对应sadd命令。
但是要注意Redis的事务功能很弱。在事务回滚机制上,Redis只能对基本的语法错误进行判断。
如果事务中的命令出现错误,Redis 的处理机制也不尽相同。
1、语法命令错误

例如下面操作错将set写成了sett,属于语法错误,会造成整个事务无法执行,事务内的操作都没有执行:
2、运行时错误
例如:事务内第一个命令简单的设置一个string类型,第二个对这个key进行sadd命令,这种就是运行时命令错误,因为语法是正确的:

可以看到Redis并不支持回滚功能,第一个set命令已经执行成功,开发人员需要自己修复这类问题。
Redis的事务原理
事务是Redis实现在服务器端的行为,用户执行MULTI命令时,服务器会将对应这个用户的客户端对象设置为一个特殊的状态,在这个状态下后续用户执行的查询命令不会被真的执行,而是被服务器缓存起来,直到用户执行EXEC命令为止,服务器会将这个用户对应的客户端对象中缓存的命令按照提交的顺序依次执行。
Redis的watch命令
有些应用场景需要在事务之前,确保事务中的key没有被其他客户端修改过,才执行事务,否则不执行(类似乐观锁)。Redis 提供了watch命令来解决这类问题。
客户端1:

客户端2:

客户端1继续:

可以看到“客户端-1”在执行multi之前执行了watch命令,“客户端-2”在“客户端-1”执行exec之前修改了key值,造成客户端-1事务没有执行(exec结果为nil)。
Redis客户端中的事务使用代码参见:
com.msb.redis.adv.RedisTransaction

Pipeline和事务的区别
PipeLine看起来和事务很类似,感觉都是一批批处理,但两者还是有很大的区别。简单来说。
1、pipeline是客户端的行为,对于服务器来说是透明的,可以认为服务器无法区分客户端发送来的查询命令是以普通命令的形式还是以pipeline的形式发送到服务器的;
2、而事务则是实现在服务器端的行为,用户执行MULTI命令时,服务器会将对应这个用户的客户端对象设置为一个特殊的状态,在这个状态下后续用户执行的查询命令不会被真的执行,而是被服务器缓存起来,直到用户执行EXEC命令为止,服务器会将这个用户对应的客户端对象中缓存的命令按照提交的顺序依次执行。
3、应用pipeline可以提服务器的吞吐能力,并提高Redis处理查询请求的能力。
但是这里存在一个问题,当通过pipeline提交的查询命令数据较少,可以被内核缓冲区所容纳时,Redis可以保证这些命令执行的原子性。然而一旦数据量过大,超过了内核缓冲区的接收大小,那么命令的执行将会被打断,原子性也就无法得到保证。因此pipeline只是一种提升服务器吞吐能力的机制,如果想要命令以事务的方式原子性的被执行,还是需要事务机制,或者使用更高级的脚本功能以及模块功能。
4、可以将事务和pipeline结合起来使用,减少事务的命令在网络上的传输时间,将多次网络IO缩减为一次网络IO。
Redis提供了简单的事务,之所以说它简单,主要是因为它不支持事务中的回滚特性,同时无法实现命令之间的逻辑关系计算,当然也体现了Redis 的“keep it simple”的特性,下一小节介绍的Lua脚本同样可以实现事务的相关功能,但是功能要强大很多。
Lua
Lua语言是在1993年由巴西一个大学研究小组发明,其设计目标是作为嵌入式程序移植到其他应用程序,它是由C语言实现的,虽然简单小巧但是功能强大,所以许多应用都选用它作为脚本语言,尤其是在游戏领域,暴雪公司的“魔兽世界”,“愤怒的小鸟”,Nginx将Lua语言作为扩展。Redis将Lua作为脚本语言可帮助开发者定制自己的Redis命令。
Redis 2.6 版本通过内嵌支持 Lua 环境。也就是说一般的运用,是不需要单独安装Lua的。
通过使用LUA脚本:
1、减少网络开销,在Lua脚本中可以把多个命令放在同一个脚本中运行;
2、原子操作,redis会将整个脚本作为一个整体执行,中间不会被其他命令插入(Redis执行命令是单线程)。
3、复用性,客户端发送的脚本会永远存储在redis中,这意味着其他客户端可以复用这一脚本来完成同样的逻辑。
不过为了我们方便学习Lua语言,我们还是单独安装一个Lua。
在Redis使用LUA脚本的好处包括:
1、减少网络开销,在Lua脚本中可以把多个命令放在同一个脚本中运行;
2、原子操作,Redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。换句话说,编写脚本的过程中无需担心会出现竞态条件;
3、复用性,客户端发送的脚本会存储在Redis中,这意味着其他客户端可以复用这一脚本来完成同样的逻辑
Lua入门
安装Lua
Lua在linux中的安装
到官网下载lua的tar.gz的源码包
1、wget http://www.lua.org/ftp/lua-5.3.6.tar.gz 2、tar -zxvf lua-5.3.6.tar.gz 进入解压的目录: 3、cd lua-5.3.6 4、make linux 5、make install(需要在root用户下) 如果报错,说找不到readline/readline.h, 可以root用户下通过yum命令安装 yum -y install libtermcap-devel ncurses-devel libevent-devel readline-devel 安装完以后再make linux / make install 最后,直接输入 lua命令即可进入lua的控制台:
Lua基本语法
Lua 学习起来非常简单,当然再简单,它也是个独立的语言,自成体系,不可能完全在本课中全部讲述完毕,如果工作中有深研Lua的需要,可以参考《Lua程序设计》,作者罗伯拖·鲁萨利姆斯奇 (Roberto Ierusalimschy)。

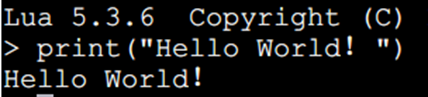
现在我们需要:print("Hello World!")
可以在命令行中输入程序并立即查看效果。
或者编写一个Lua脚本

然后执行

注释
单行注释
两个减号是单行注释: --
多行注释
--[[ 注释内容 注释内容 --]]
标示符
Lua 标示符用于定义一个变量,函数获取其他用户定义的项。标示符以一个字母 A 到 Z 或 a 到 z 或下划线 _ 开头后加上 0 个或多个字母,下划线,数字(0 到 9)。
最好不要使用下划线加大写字母的标示符,因为Lua的语言内部的一些保留字也是这样的。
Lua 不允许使用特殊字符如 @, $, 和 % 来定义标示符。 Lua 是一个区分大小写的编程语言。因此在 Lua 中 LIJIN与lijin 是两个不同的标示符。以下列出了一些正确的标示符:

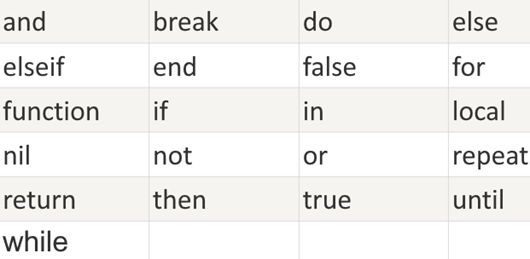
关键词
以下列出了 Lua 的保留关键词。保留关键字不能作为常量或变量或其他用户自定义标示符:
同时一般约定,以下划线开头连接一串大写字母的名字(比如 _VERSION)被保留用于 Lua 内部全局变量。
全局变量
在默认情况下,变量总是认为是全局的。
全局变量不需要声明,给一个变量赋值后即创建了这个全局变量,访问一个没有初始化的全局变量也不会出错,只不过得到的结果是:nil。
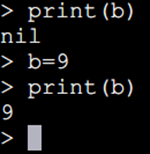
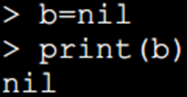
如果你想删除一个全局变量,只需要将变量赋值为nil。这样变量b就好像从没被使用过一样。换句话说, 当且仅当一个变量不等于nil时,这个变量即存在。
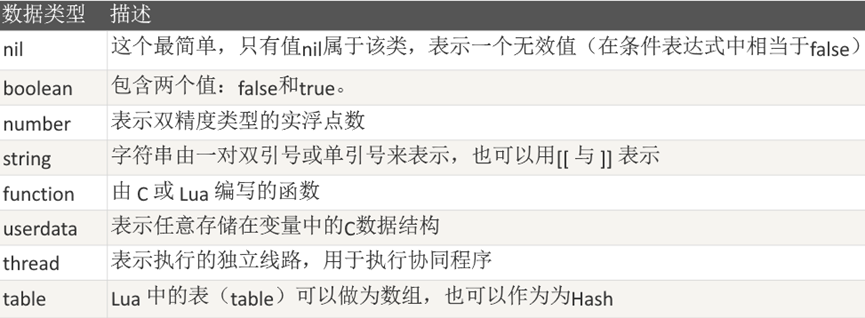
Lua中的数据类型
Lua 是动态类型语言,变量不要类型定义,只需要为变量赋值。 值可以存储在变量中,作为参数传递或结果返回。
Lua 中有 8 个基本类型分别为:nil、boolean、number、string、userdata、function、thread 和 table。
我们可以使用 type 函数测试给定变量或者值的类型。

我们只选择几个要点做说明:
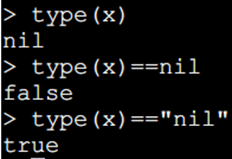
1、nil 类型表示一种没有任何有效值,它只有一个值 – nil,对于全局变量和 table,nil 还有一个"删除"作用,给全局变量或者 table 表里的变量赋一个 nil 值,等同于把它们删掉,nil 作类型比较时应该加上双引号 "。
2、boolean 类型只有两个可选值:true(真) 和 false(假),Lua 把 false 和 nil 看作是 false,其他的都为 true,数字 0 也是 true。
3、Lua 默认只有一种 number类型 -- double(双精度)类型。
print(type(2)) print(type(2.2)) print(type(0.2)) print(type(2e+1)) print(type(0.2e-1))
都被看作是 number 类型
4、字符串由一对双引号或单引号来表示,也可以用[[ 与 ]] 表示,一般来说,单行文本用双引号或单引号,多行文本用[[ 与 ]] 。
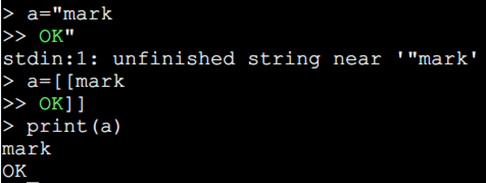
5、在对一个数字字符串上进行算术操作时,Lua 会尝试将这个数字字符串转成一个数字。
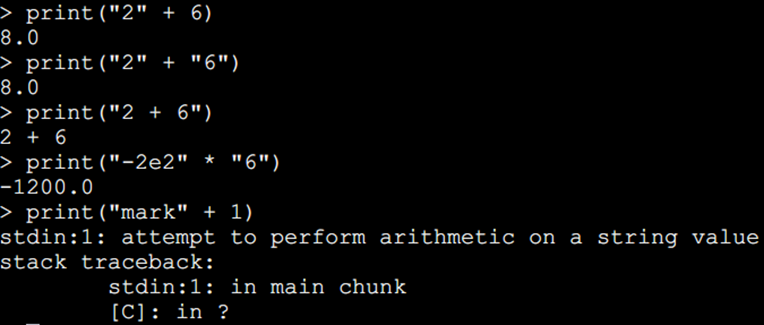
6、字符串连接使用的是 ..

7、使用 # 来计算字符串的长度,放在字符串前面

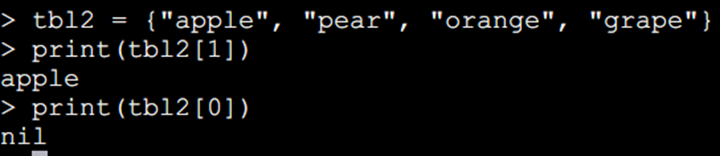
8、table可以做为数组,也可以作为为Hash,table 不会固定长度大小,有新数据添加时 table 长度会自动增长,没初始的 table 都是 nil

不同于其他语言的数组把 0 作为数组的初始索引,可以看到在Lua里表的默认初始索引一般以 1 开始。
把table做hash表用:

Lua 中的函数
在 Lua中,函数以function开头,以end结尾,funcName是函数名,中间部分是函数体:
function funcName () --[[ 函数内容 --]] end
比如定义一个字符串连接函数:
function
contact(str1,str2)
return
str1..str2
end
print(contact("hello","Lijin"))
Lua 变量
变量在使用前,需要在代码中进行声明,即创建该变量。
编译程序执行代码之前编译器需要知道如何给语句变量开辟存储区,用于存储变量的值。
Lua 变量有:全局变量、局部变量。
Lua 中的变量全是全局变量,那怕是语句块或是函数里,除非用 local 显式声明为局部变量。局部变量的作用域为从声明位置开始到所在语句块结束。
变量的默认值均为 nil。

Lua中的控制语句
Lua中的控制语句和Java语言的差不多。
循环控制
Lua支持while 循环、for 循环、repeat...until循环和循环嵌套,同时,Lua提供了break 语句和goto 语句。
我们重点来看看while 循环、for 循环。
for 循环
Lua 编程语言中 for语句有两大类:数值for循环、泛型for循环。
数值for循环
Lua 编程语言中数值 for 循环语法格式:
for var=exp1,exp2,exp3 do
<执行体>
end
var 从 exp1 变化到 exp2,每次变化以 exp3 为步长递增 var,并执行一次 "执行体"。exp3 是可选的,如果不指定,默认为1。
泛型for循环
泛型 for 循环通过一个迭代器函数来遍历所有值,类似 java 中的 foreach 语句。Lua 编程语言中泛型 for 循环语法格式:
--打印数组a的所有值
a = {"one", "two", "three"}
for i, v in ipairs(a) do
print(i, v)
end

i是数组索引值,v是对应索引的数组元素值。ipairs是Lua提供的一个迭代器函数,用来迭代数组。
tbl3={age=18,name='lijin'}
for i, v in pairs(tbl3) do
print(i,v)
end
while循环
while(condition)
do
statements
end
a=10 while(a<20) do print("a= ",a) a=a+1 end
if条件控制
Lua支持if 语句、if...else 语句和if 嵌套语句。
if 语句语法格式如下:
if(布尔表达式) then --[ 在布尔表达式为 true 时执行的语句 --] end if...else 语句语法格式如下: if(布尔表达式) then --[ 布尔表达式为 true 时执行该语句块 --] else --[ 布尔表达式为 false 时执行该语句块 --] end
Lua 运算符
Lua提供了以下几种运算符类型:
算术运算符
+ 加法 - 减法 * 乘法 / 除法 % 取余 ^ 乘幂 - 负号 关系运算符 == 等于 ~= 不等于 > 大于 < 小于 >= 大于等于 <= 小于等于 逻辑运算符 and 逻辑与操作符 or 逻辑或操作符 not 逻辑非操作符
Lua其他特性
Lua支持模块与包,也就是封装库,支持元表(Metatable),支持协程(coroutine),支持文件IO操作,支持错误处理,支持代码调试,支持Lua垃圾回收,支持面向对象和数据库访问,更多详情请参考对应书籍。
Java对Lua的支持
目前Java生态中,对Lua的支持是LuaJ,是一个 Java 的 Lua 解释器,基于 Lua 5.2.x 版本。
Maven
<dependency>
<groupId>org.luaj</groupId>
<artifactId>luaj-jse</artifactId>
<version>3.0.1</version>
</dependency>
参考代码
参见luaj模块,请注意,本代码仅供参考,在工作中需要使用Lua语言或者Java中执行Lua脚本的,请自行仔细学习Lua语言本身和luaj-jse使用,不提供任何技术支持。一般这种形式用得非常少。
Redis中的Lua
eval 命令
命令格式
EVAL script numkeys key [key ...] arg [arg ...]
命令说明
1、script 参数:
是一段 Lua 脚本程序,它会被运行在Redis 服务器上下文中,这段脚本不必(也不应该)定义为一个 Lua 函数。
2、numkeys 参数:
用于指定键名参数的个数。
3、key [key...] 参数: 从EVAL 的第三个参数开始算起,使用了 numkeys 个键(key),表示在脚本中所用到的那些 Redis 键(key),这些键名参数可以在 Lua 中通过全局变量 KEYS 数组,用1为基址的形式访问(KEYS[1],KEYS[2]···)。
4、arg [arg...]参数:
可以在 Lua 中通过全局变量 ARGV 数组访问,访问的形式和 KEYS 变量类似(ARGV[1],ARGV[2]···)。
示例
eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second

在这个范例中key [key ...] 参数的作用不明显,其实它最大的作用是方便我们在Lua 脚本中调用 Redis 命令
Lua 脚本中调用 Redis 命令
这里我们主要记住 call() 命令即可:
eval "return redis.call('mset',KEYS[1],ARGV[1],KEYS[2],ARGV[2])" 2 key1 key2 first second

evalsha 命令
但是eval命令要求你在每次执行脚本的时候都发送一次脚本,所以Redis 有一个内部的缓存机制,因此它不会每次都重新编译脚本,不过在很多场合,付出无谓的带宽来传送脚本主体并不是最佳选择。
为了减少带宽的消耗, Redis 提供了evalsha 命令,它的作用和 EVAL一样,都用于对脚本求值,但它接受的第一个参数不是脚本,而是脚本的 SHA1 摘要。
这里就需要借助script命令。
script flush :清除所有脚本缓存。
script exists :根据给定的脚本校验,检查指定的脚本是否存在于脚本缓存。
script load :将一个脚本装入脚本缓存,返回SHA1摘要,但并不立即运行它。
script kill :杀死当前正在运行的脚本。
这里的 SCRIPT LOAD 命令就可以用来生成脚本的 SHA1 摘要
script load "return redis.call('set',KEYS[1],ARGV[1])"

然后就可以执行这个脚本
evalsha "c686f316aaf1eb01d5a4de1b0b63cd233010e63d" 1 key1 testscript
redis-cli 执行脚本
可以使用 redis-cli 命令直接执行脚本,这里我们直接新建一个 lua 脚本文件,用来获取刚刚存入 Redis 的 key1的值,vim redis.lua,然后编写 Lua 命令:
local value = redis.call('get','key1')
return value

然后执行
./redis-cli -p 6379 --eval ../scripts/test.lua
也可以
./redis-cli -p 6379 script load "$(cat ../scripts/test.lua)"
Redis与限流
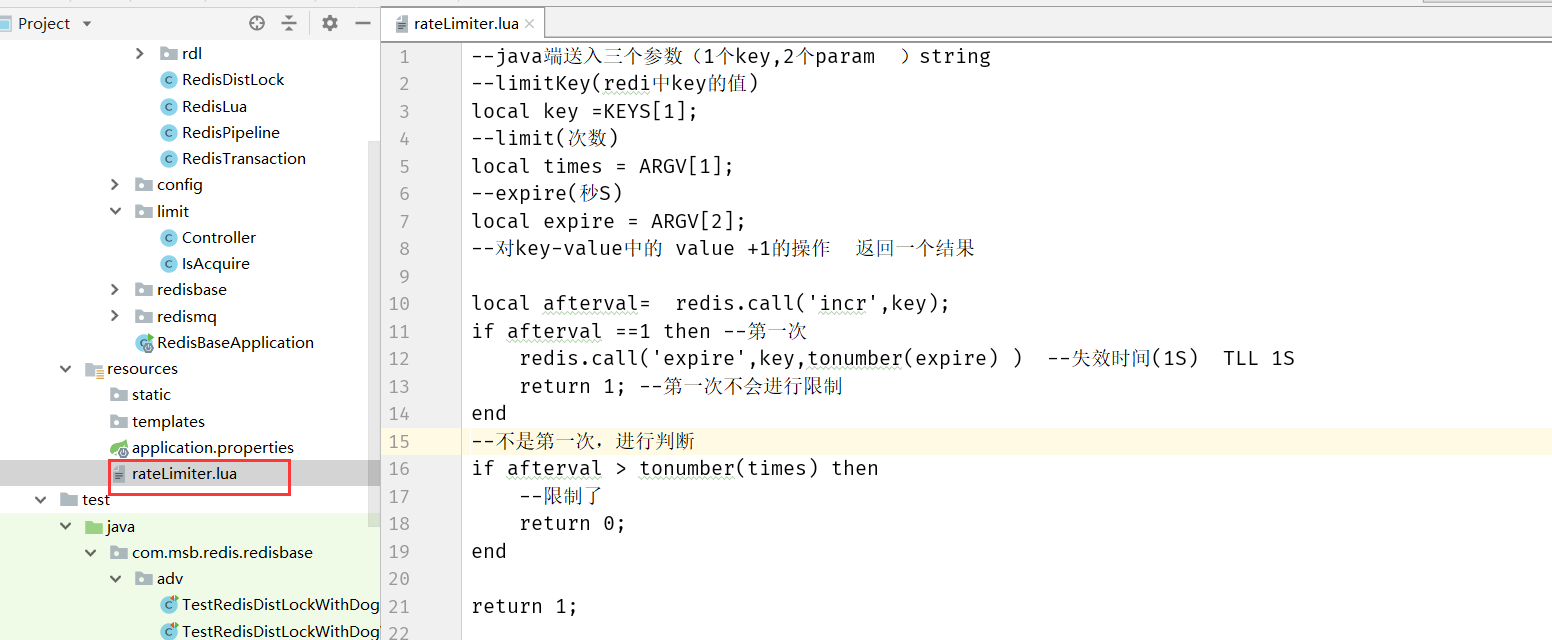
使用Redis+Lua语言实现限流
项目代码



方案好处:
支持分布式
使用lua脚本的好处:
减少网络开销
原子操作
复用
限流算法
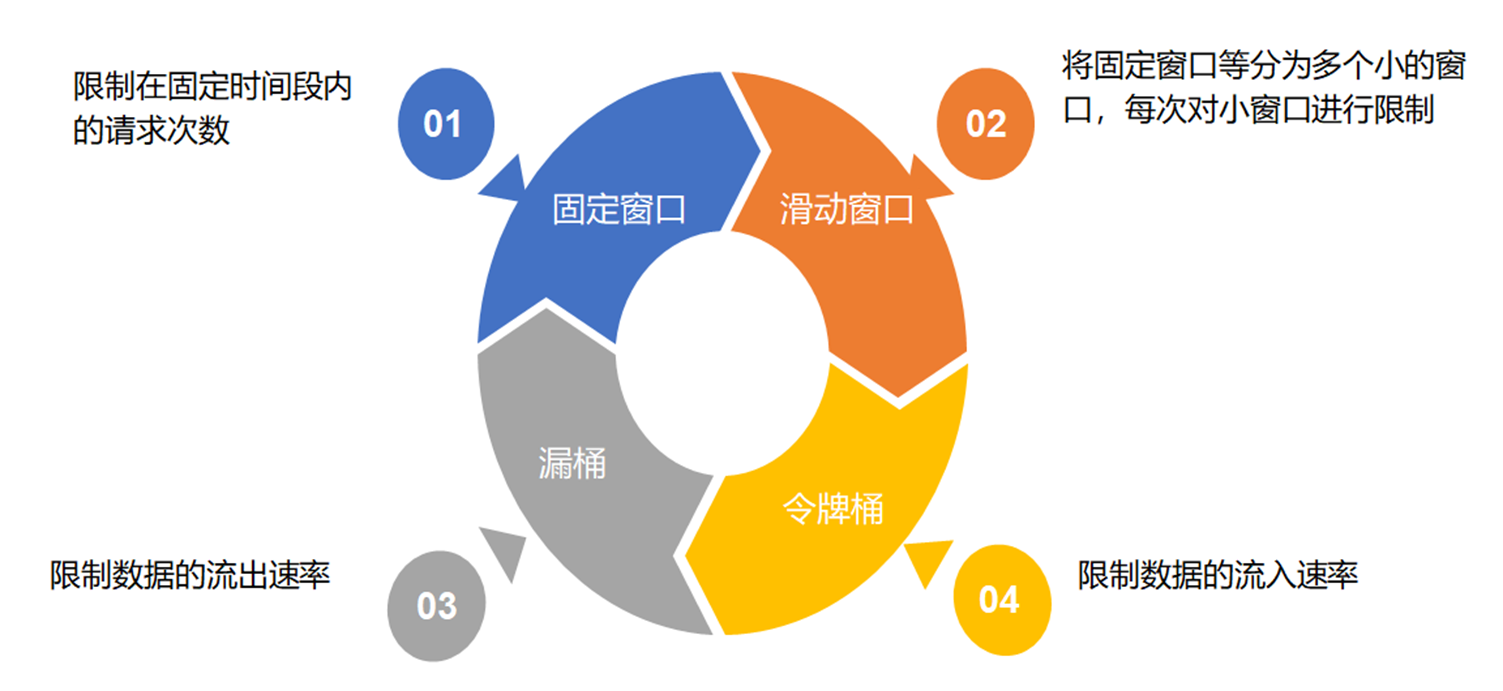
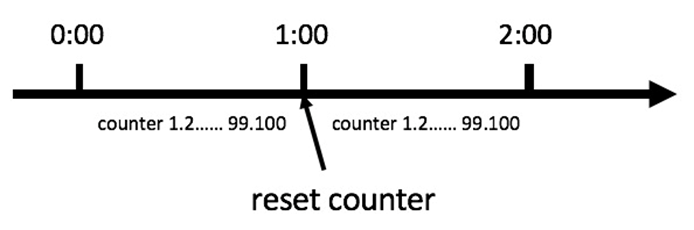
固定窗口算法
简单粗暴,但是有临界问题
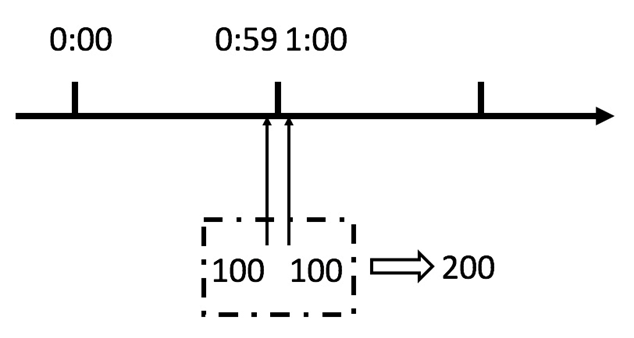
滑动窗口算法
在线演示滑动窗口:
https://media.pearsoncmg.com/aw/ecs_kurose_compnetwork_7/cw/content/interactiveanimations/selective-repeat-protocol/index.html

滑动窗口通俗来讲就是一种流量控制技术。
它本质上是描述接收方的TCP数据报缓冲区大小的数据,发送方根据这个数据来计算自己最多能发送多长的数据,如果发送方收到接收方的窗口大小为0的TCP数据报,那么发送方将停止发送数据,等到接收方发送窗口大小不为0的数据报的到来。
首先是第一次发送数据这个时候的窗口大小是根据链路带宽的大小来决定的。我们假设这个时候窗口的大小是3。这个时候接受方收到数据以后会对数据进行确认告诉发送方我下次希望手到的是数据是多少。这里我们看到接收方发送的ACK=3(这是发送方发送序列2的回答确认,下一次接收方期望接收到的是3序列信号)。这个时候发送方收到这个数据以后就知道我第一次发送的3个数据对方只收到了2个。就知道第3个数据对方没有收到。下次在发送的时候就从第3个数据开始发。
此时窗口大小变成了2 。
于是发送方发送2个数据。看到接收方发送的ACK是5就表示他下一次希望收到的数据是5,发送方就知道我刚才发送的2个数据对方收了这个时候开始发送第5个数据。
这就是滑动窗口的工作机制,当链路变好了或者变差了这个窗口还会发生变话,并不是第一次协商好了以后就永远不变了。
所以滑动窗口协议,是TCP使用的一种流量控制方法。该协议允许发送方在停止并等待确认前可以连续发送多个分组。由于发送方不必每发一个分组就停下来等待确认,因此该协议可以加速数据的传输。
只有在接收窗口向前滑动时(与此同时也发送了确认),发送窗口才有可能向前滑动。
收发两端的窗口按照以上规律不断地向前滑动,因此这种协议又称为滑动窗口协议。
TCP中的滑动窗口
发送方和接收方都会维护一个数据帧的序列,这个序列被称作窗口。发送方的窗口大小由接收方确认,目的是控制发送速度,以免接收方的缓存不够大导致溢出,同时控制流量也可以避免网络拥塞。
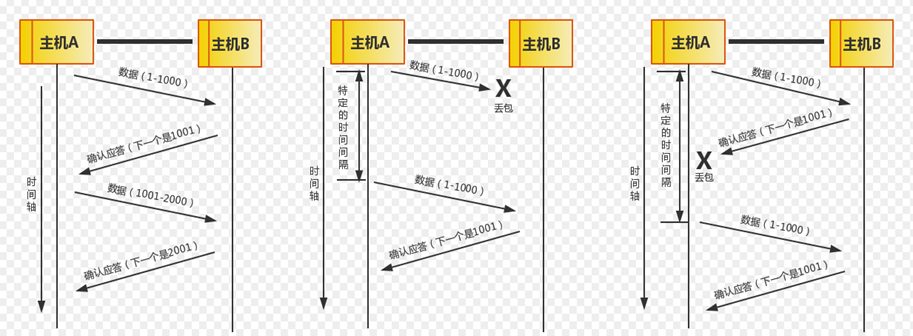
在TCP 的可靠性的图中,我们可以看到,发送方每发送一个数据接收方就要给发送方一个ACK对这个数据进行确认。只有接收了这个确认数据以后发送方才能传输下个数据。
存在的问题:如果窗口过小,当传输比较大的数据的时候需要不停的对数据进行确认,这个时候就会造成很大的延迟。
如果窗口过大,我们假设发送方一次发送100个数据,但接收方只能处理50个数据,这样每次都只对这50个数据进行确认。发送方下一次还是发送100个数据,但接受方还是只能处理50个数据。这样就避免了不必要的数据来拥塞我们的链路。
因此,我们引入了滑动窗口。
漏洞算法

定义
先有一个桶,桶的容量是固定的。
以任意速率向桶流入水滴,如果桶满了则溢出(被丢弃)。
桶底下有个洞,按照固定的速率从桶中流出水滴。
特点
漏桶核心是:请求来了以后,直接进桶,然后桶根据自己的漏洞大小慢慢往外面漏。
具体实现的时候要考虑性能(比如Redis实现的时候数据结构的操作是不是会导致性能问题)
令牌算法
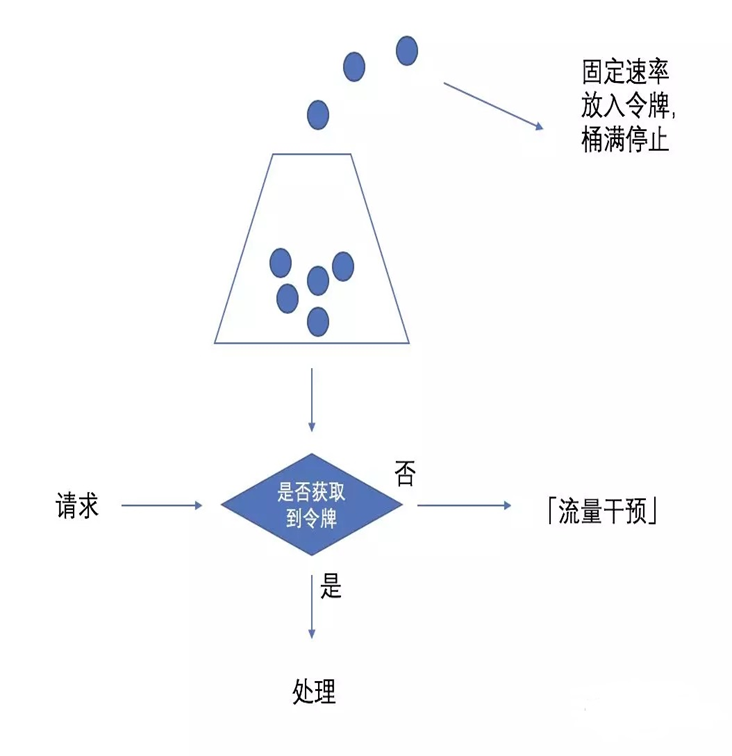
定义
先有一个桶,容量是固定的,是用来放令牌的。
以固定速率向桶放令牌,如果桶满了就不放令牌了。
Ø处理请求是先从桶拿令牌,先拿到令牌再处理请求,拿不到令牌同样也被限流了。
特点
突发情况下可以一次拿多个令牌进行处理。
具体实现的时候要考虑性能(比如Redis实现的时候数据结构的操作是不是会导致性能问题)