0. 简介
最近作者希望系统性的去学习一下CUDA加速的相关知识,正好看到深蓝学院有这一门课程。所以这里作者以此课程来作为主线来进行记录分享,方便能给CUDA网络加速学习的萌新们去提供一定的帮助。
1. GPU与CPU区别
处理器指标一般主要分为两大类,第一块主要是延迟,另一块是吞吐量。
1.1 CPU概念
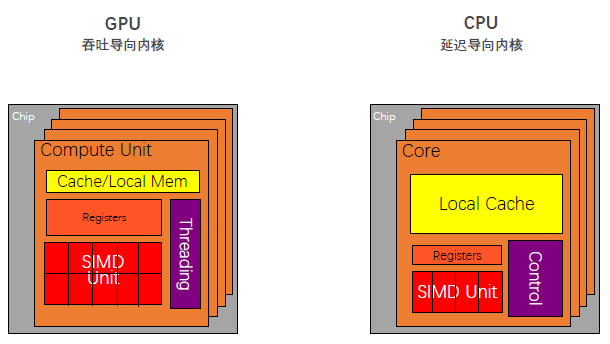
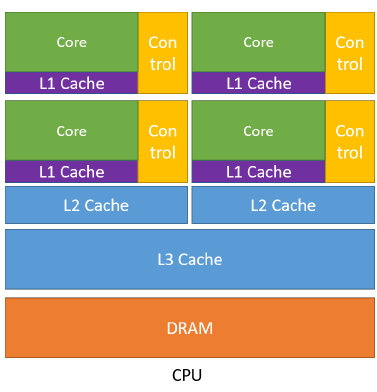
对于CPU而言,首先是拥有较大的内存,其具有L1,L2,L3三级的存储。通过多级缓存结构提高访存速度,将经常访问的内容放在低级缓存中,不常访问的内容会被放在高级缓存中。其次是控制比较复杂(Control),控制单元中有两个非常重要的机制,分别为:分支预测机制(if else 这类分支预测操作)和流水线数据前送机制(cpu是流水线机制,不是完全线行的)。最后一个特点是运算单元(Core)强大。对整型浮点型这类的复杂运算速度快,便于实时输出。
1.2 GPU概念
对于GPU而言,我们可以看到GPU虽然也有缓存,但是缓存很小只有L1和L2级别缓存,其次控制单元相对于CPU而言简单,没有分支预测,也没有没有数据转发。剩下的我们可以看到绿色的运算单元数量是很多的,所以可以使用多长延时流水线以实现高吞吐量,同时由于长延时导致我们需要大量线程来容忍延迟
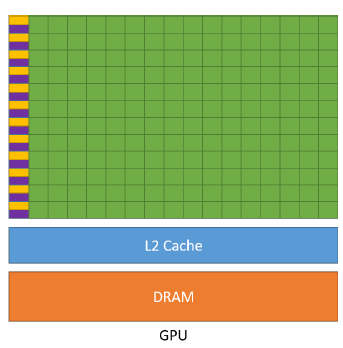
1.3 GPU编程:什么样的问题适合GPU
计算密集:数值计算的比例要远大于内存操作,因此内存访问的延时可以被计算掩盖。
数据并行:大任务可以拆解为执行相同指令的小任务,因此对复杂流程控制的需求较低。
1.4 GPU编程与CUDA
CUDA(Compute Unified Device Architecture),由英伟达公司2007年开始推出,初衷是为GPU增加一个易用的编程接口,让开发者无需学习复杂的着色语言或者图形处理原语。
OpenCL(Open Computing Languge)是2008年发布的异构平台并行编程的开放标准,也是一个编程框架。OpenCL相比CUDA,支持的平台更多,除了GPU还支持CPU、DSP、FPGA等设备。
下面我们来看一下整个CPU与GPU的流程
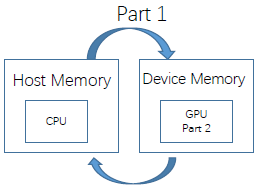
其中Device=GPU,Host=CPU,Kernel=GPU上运行的函数
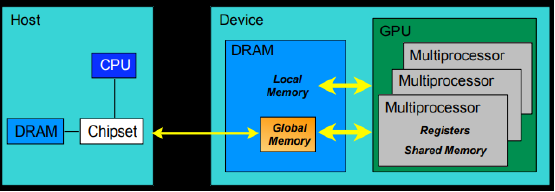
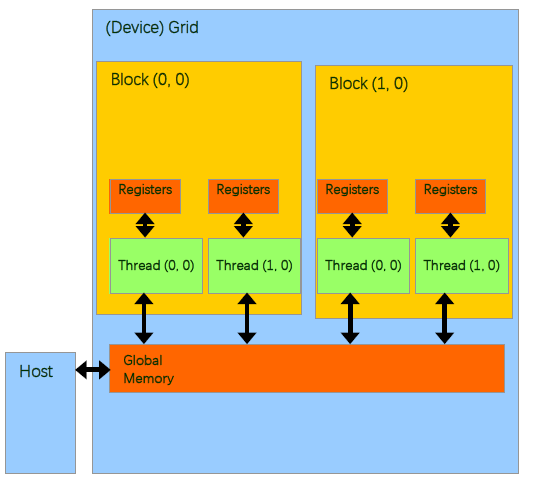
对于GPU的内存模型,我们从上图可以了解到:
- 每个线程处理器(SP)都用自己的registers(寄存器);
- 每个SP都有自己的local memory(局部内存),register和local memory只能被线程自己访问
- 每个多核处理器(SM)内都有自己的shared memory(共享内存),shared memory 可以被线程块内所有线程访问
- 一个GPU的所有SM共有一块global memory(全局内存),不同线程块的线程都可使用
CUDA中的内存模型中,线程处理器(SP)对应线程(thread);多核处理器(SM)对应线程块(thread block);设备端(device)对应线程块组合体(grid)。一个kernel其实由一个grid来执行的,同时一个kernel一次只能在一个GPU上执行
2. 线程块、网格和线程束
2.1 线程块
线程块会将线程数组分成多个块。每个块内的线程通过共享内存、原子操作和屏障同步进行协作(shared memory, atomic operations and barrier synchronization )。同时不同块中的线程不能相互协作。如下图所示,通过并行的形式可以得到一个结果作为输出。
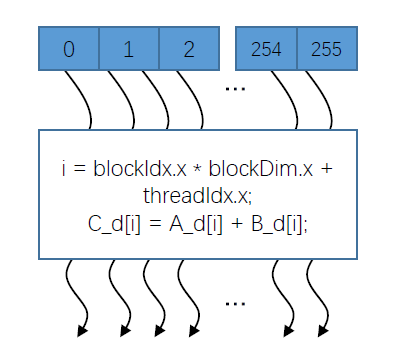
2.2 网格
网格内的线程块也是相互独立的,且互不影响的,网格中的全局内存可以由所有线程块进行访问的,最后一点就是可以用一个共有的时钟同步所有的网格块
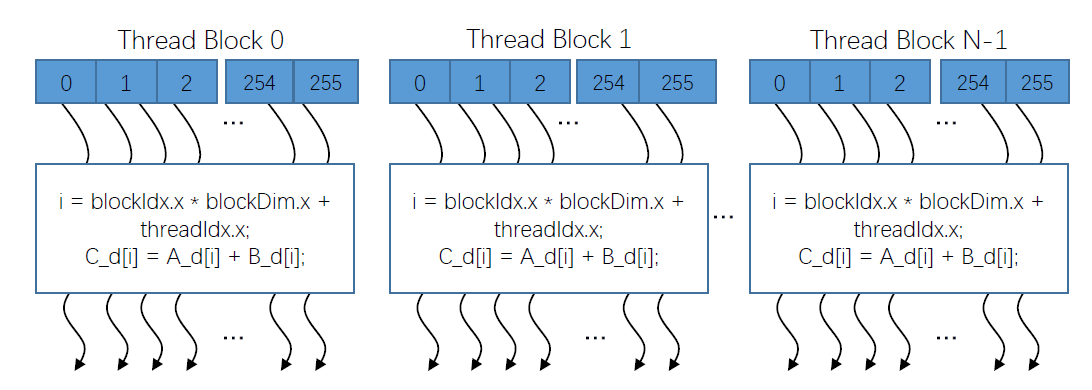
整体的示意图如下,每个线程使用索引来决定要处理的数据
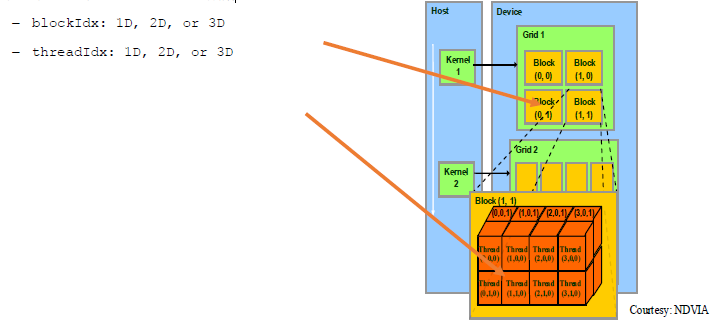
dim3 dimGrid(M, N);
dim3 dimBlock(P, Q, S);
threadId.x= blockIdx.x*blockDim.x+threadIdx.x;
threadId.y= blockIdx.y*blockDim.y+threadIdx.y;
2.3 线程束(Warp)
SM采用的SIMT(Single-Instruction, Multiple-Thread,单指令多线程)架构,warp(线程束)是最基本的执行单元,一个warp包含32个并行thread,这些thread以不同数据资源执行相同的指令。warp本质上是线程在GPU上运行的最小单元。
当一个kernel被执行时,grid中的线程块被分配到SM上,一个线程块的thread只能在一个SM上调度,SM一般可以调度多个线程块,大量的thread可能被分到不同的SM上。由于warp的大小为32,所以block所含的thread的大小一般要设置为32的倍数。

3. 进入CUDA
对于CUDA加速而言,主要的流程分为设备端(GPU)以及主机端(CPU)
设备端代码:
- 读写线程寄存器
- 读写Grid中全局内存
- 读写block中共享内存
主机端代码:
- Grid中全局内存拷贝转移
![[附源码]计算机毕业设计勤工助学管理系统Springboot程序](https://img-blog.csdnimg.cn/7456fd0e8e6e41d1b3c0b49f650067ac.png)