前言:同事问我,你写运维平台最先写哪一部分?好吧,还真把我问倒了,因为这是在问最应该放在放在第一位的东西~作为一个工作不足两年,运维不足一年的新手来说,还真不敢妄下评论,其实按照我的思路,觉得最重要的部分肯定是故障处理,报警,但是这一块怎么写?怎么说?肯定不能重复造轮子了,不过我最想写的是报表系统,思路是有的,但是一直耽搁了,详情参考http://youerning.blog.51cto.com/10513771/1708925。
好吧,在回到那个问题,应该先写哪个部分。我没回答,反问他了。
他说,应该是运维气象图,这张图上有各个节点的位置,并且标注出流量情况,如果我们在服务器发生故障的时候发现其中一个节点流量过高或者过低,或者一些其他指标,我们在一定程度上可以快速的地位故障的位置。注:cacti,zabbix似乎是有这个插件的,不过不是那么好看,或者有一定局限性,我也没调查过,反正不想用。
然后,我被上了一课, 那么为毛类似这样的应用或者框架之类的(除了上面说的两个插件,本人暂时没有Google或百度到,如果你知道抨击一下我呗,当然,最好是Python开发的,我好自定义一下),他说,收费的软件有~~~
首先瞧瞧我花了几天鼓捣出来的Beta版本吧:

现在,正题~~~
如果你不会python就收藏着以后看吧,当下就看看思路吧。
如果你会python就在涉猎一下JS吧,比如AngularJS,D3JS什么的,不过可以
如果你什么都不会,希望能激发你的兴趣。
如果你是大神,还执意要看就忽略我代码中的一些写的不优雅,不好看的地方吧T_T
题外话:话说,有什么觉得比较实用的功能是需要收费的,或者一些想法需要实现的可以Q我,我们把它实现了(仅限于大概一周以内能写完的,特别有意思的来说)
授人以鱼不如授人以渔嘛,主要两部分,一部分思路,一部分代码讲解
(一)
思路
Q:数据来源,通过写客户端?
A:当然不,nagios,cacti,zabbix什么的不是有一大堆么,为毛还要自己写,而且还不一定写的比别人好,美其名曰不愿重复造轮子~~~根据自己情况选择吧,这里就选的通过zabbix的API作为数据来源。
Q:用什么web框架?
A:用Flask,很喜欢一句从网上看来的评论django的话,上它的人很多,喜欢它的很少,再者,我实在不想去配置什么配置文件,以及帮我创建一大堆文件(当然也可以不需要),再再者,我的功能不需要太多,再再再者,flask的官方文档写得太棒了~~~
然后瞧瞧我们写什么,完成什么~
代码实现:
web框架flask
功能页面:
页面一:展示页面(bootstrap提供样式效果,AngularJS实时数据查询并刷新,为毛不用jQuery?因为jQuery我不会T_T)
页面二:数据查询接口
代码文件:
一:用于查询数据的py模块 x 1
二:用于提供web界面的py文件 x 1
三:html模板文件 x 3
四:js文件 x 2
注:其实个人不建议用模板渲染直接把数据渲染到展示页面上去,虽然这样不用写js了,但是写到后面,你就难过了,所以前台后台分离吧,这里也是前台后台分离,前台bootstrap加AngularJS~~~
(二)
代码
zabbix数据获取
获取zabbix数据可参考:http://youerning.blog.51cto.com/10513771/1740152第三部分~~
所以直接放代码吧~~
#coding=utf-8
import json
import requests
from pprint import pprint
from os import path
###zabbix api 访问地址
zabbix_pre = "http://10.10.102.88/zabbix/"
zabbix_url = zabbix_pre + "/api_jsonrpc.php"
###用户名密码
user = ""
passwd = ""
###这里只查询进出口流量,所以只有下面两个关键字,后面可能会查询一些其他的~~~
net_in = "net.if.in[eth0]"
net_out = "net.if.out[eth0]"
###构造post请求提交的数据
auth_data = json.dumps(
{"jsonrpc": "2.0","method": "user.login","params": {"user": "%s" %user,"password": "%s" %passwd
},
"id": 0
})
###http头部信息,zabbix要求的
headers = {'content-type': 'application/json',
}
###构造一个返回查询hostid的json数据,函数是一等公民~~~
def host_data(auth):data = json.dumps({"jsonrpc":"2.0","method":"host.get","params":{"output":["hostid","host"],"search":{"host":""}},"auth":"%s" %auth,"id":1,})return data
###如上,查询hostid
def host_data_search(auth,search):data = json.dumps({"jsonrpc":"2.0","method":"host.get","params":{"output":["hostid","name"],"search":{"host":search}},"auth":"%s" %auth,"id":1,})
###如上,查询itemid
def item_data_filter1(auth,hostid,filters):data = json.dumps({"jsonrpc":"2.0","method":"item.get","params":{"output":["itemid"],"hostids":"%s" %hostid,"search":{"key_":filters}},"auth":"%s" %auth,"id":1,})return data
###如上,查询item的所有信息,hostname,itemid一大堆
def item_data_filter2(auth,hostid,filters):data = json.dumps({"jsonrpc": "2.0","method": "item.get","params": {"output":"extend","hostids":"%s" %hostid,"filter": {"name": filters},"sortfield": "name"},"auth":"%s" %auth,"id": 1})return data
###如上,获取最新监控值
def history_data(auth,itemid,limit,his=0):data = json.dumps({"jsonrpc":"2.0","method":"history.get","params":{"output":"extend","history":his,"sortfield": "clock","sortorder": "DESC","itemids":"%s" %itemid,"limit":limit},"auth":"%s" %auth,"id":1,})return data
###构造获取zabbix验证id,为了反复操作,当然封装成函数
def getauth(zabbix_url,auth_data,headers):auth_ret = requests.post(zabbix_url, data=auth_data, headers=headers)auth_id = auth_ret.json()["result"]return auth_id
###将所有结果保存成本地之间,结果包括,主机名(这里指zabbix上的命名),hostid,出入口的itemid
def savefile():host_ret = requests.post(zabbix_url, data=host_data(auth_id), headers=headers)host_ret = host_ret.json()["result"]###这里请根据实际情况设定,比如包括nginx集群,mysql集群,tomcat集群,如下json_all = {}json_all["nginx_cluster"] = {}json_all["tomcat_cluster"] = {}json_all["mysql_cluster"] = {}for host in host_ret:hostid = host["hostid"]hostname = host["host"]item_ret = requests.post(zabbix_url, data=item_data_filter1(auth_id,hostid,"net.if"), \headers=headers)item_ret = item_ret.json()["result"]#pprint(item_ret)item_in = item_ret[0]["itemid"]item_out = item_ret[1]["itemid"]""""这里如上,根据实际情况设定if "nginx" in hostname:json_all["nginx_cluster"][hostname] = [hostid,item_in,item_out]elif "tomcat" in hostname:json_all["tomcat_cluster"][hostname] = [hostid,item_in,item_out]elif "mysql" in hostname:json_all["mysql_cluster"][hostname] = [hostid,item_in,item_out]else:pass"""#pprint(json_all)fp = open("clusters.json","w")fp.write(json.dumps(json_all))fp.close()
###然后通过itemid获取最新的监控值
def gethist(auth_id,itemid,limit,outtype=3):while not path.isfile("clusters.json"):savefile() history_ret = requests.post(zabbix_url, data=history_data(auth_id,itemid,limit,outtype),\headers=headers)#print history_ret.json()if len(history_ret.json()["result"]) == 0:return 0else:history_ret = history_ret.json()["result"][0]#pprint(history_ret["value"])return history_ret["value"]
###然后通过集群名获取整个集群的总和监控值
def gethist_cluster(auth_id,cluster_name,opt):clsname = cluster_nameopt = optauth_id = getauth(zabbix_url,auth_data,headers)while not path.isfile("clusters.json"):savefile() cluster_file = json.load(open("clusters.json","r"))net_list = {"in":1,"out":2}if clsname in cluster_file.keys() and opt in net_list.keys():sum = 0 cls = cluster_file[clsname]inf = net_list[opt]for host in cls:itemid = cls[host][inf]his_ret = int(gethist(auth_id,itemid,1,3))sum = sum + his_ret#print float(sum)/float(1024)return float(sum)/float(1024)
auth_id = getauth(zabbix_url,auth_data,headers)
#gethist(auth_id,25919,1,3)
print gethist_cluster(auth_id,"mysql_cluster","in")然后将上面的代码保存为getsource.py文件用作模块导入,之所以不将所有py代码不写在一起也是为了更好看,更容易反复使用。
注:如果主机多的话会很慢吧~~~因为我没有写并发
然后是flask部分的web代码
#coding: utf-8
from flask import Flask,jsonify,render_template
###flask的插件,用的restful作为提供api
from flask.ext import restful
###从上面的那个py文件导入我们需要的函数
from getsource import gethist,getauth,gethist_cluster,savefile
import json
from os import path
app = Flask(__name__)
api = restful.Api(app)
###zabix url
zabbix_pre = "http://10.10.102.88/zabbix/"
zabbix_url = zabbix_pre + "/api_jsonrpc.php"
###username and passwd
user = ""
passwd = ""
###auth data
auth_data = json.dumps(
{ "jsonrpc": "2.0","method": "user.login","params": {"user": "%s" %user,"password": "%s" %passwd
},
"id": 0
})
###headers
headers = {'content-type': 'application/json',
}
###根据实际情况设定,这里给每个集群加了个id,用于排序,实际集群参考上面代码,这里也以nginx_cluser,tomcat_cluster,mysql_cluster为例
cluster_id = {"nginx_cluster":1,"tomcat_cluster":2,"mysql_cluster":7}
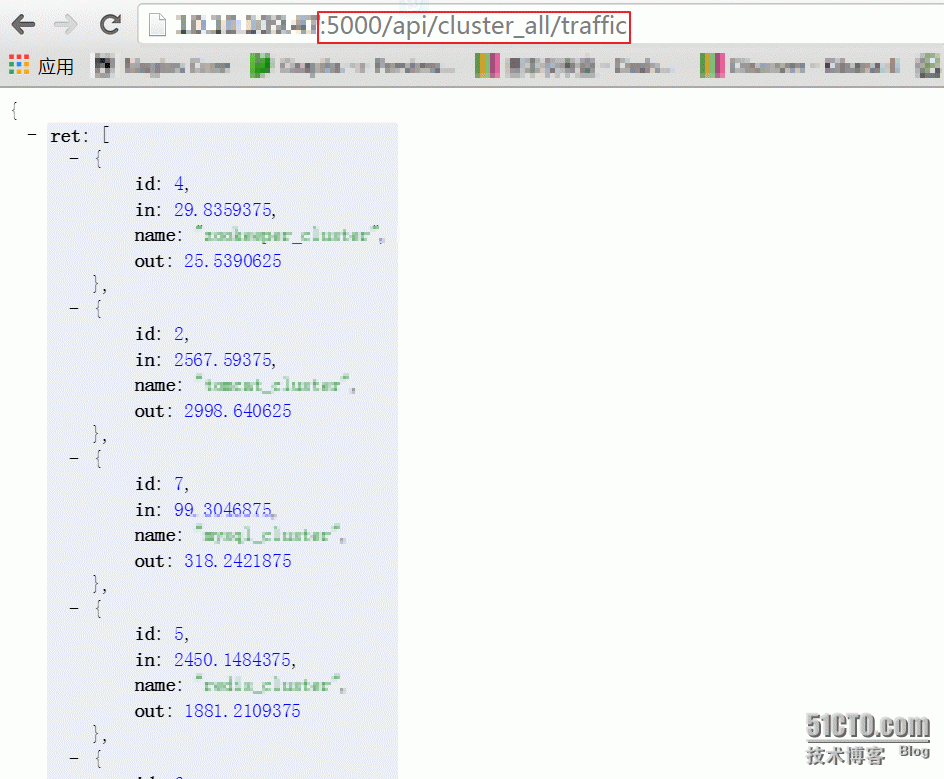
class MyApi(restful.Resource):def get(self,name,opt):cls = nameopt = optauth_id = getauth(zabbix_url,auth_data,headers)while not path.isfile("clusters.json"):savefile()cluster_file = json.load(open("clusters.json","r"))net_list = {"in":1,"out":2}if cls in cluster_file.keys() and opt in net_list.keys():sum = 0cls = cluster_file[cls]inf = net_list[opt]for host in cls:itemid = cls[host][inf]his_ret = int(gethist(auth_id,itemid,1,3))sum = sum + his_retreturn float(sum)/float(1024)elif cls == "cluster_all" and opt == "traffic" :keys = cluster_file.keys()cls_ret = {}cls_lis = []for key in keys:dic = {} dic["name"] = keydic["id"] = cluster_id[key]dic["in"] = gethist_cluster(auth_id,key,"in")dic["out"] = gethist_cluster(auth_id,key,"out")cls_lis.append(dic)cls_ret["ret"] = cls_lisreturn jsonify(cls_ret)elif cls == "cluster_all" and opt == "list":return jsonify(cluster_file)elif cls in cluster_id.keys() and opt == "list":ret = cluster_file[cls]return jsonify(ret)else:return "None"
api.add_resource(MyApi,"/api/<string:name>/<string:opt>")
@app.route("/")
def hello():return "Hello world 你好"
@app.route("/weathermap")
@app.route("/weathermap/<string:name>")
def weathermap(name=None):name = nameif name == "all":return render_template("weathermap_all.html")elif name == "list":return render_template("weathermap_list.html")elif name == "plot":return render_template("weathermap_plot.html")else:return render_template("weathermap_all.html")
app.debug = True
app.run(host="0.0.0.0")再是html模板文件
layout.html
<!DOCTYPE html>
<html lang="zh-CN"><head><meta charset="utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1"><!-- 上述3个meta标签*必须*放在最前面,任何其他内容都*必须*跟随其后! --><title>Weather Map</title><!-- Bootstrap --><link href="/static/css/bootstrap.min.css" rel="stylesheet"><link rel="shortcut icon" href="static/img/flask.ico"><script src="/static/js/angular.min.js"></script><script src="/static/js/d3.v3.min.js"></script></head><body><nav class="navbar navbar-default navbar-static-top"><span class="label label-primary text-center">Beta</span><h1>运维流量表</h1></nav>{% block body %}{% endblock %}</body>
</html>weathermap_all.hml
{% extends "layout.html" %}
{% block body %}<h3>集群流量一览表</h3><div ng-app="myApp" ng-controller="myCtrl" class="col-md-10 col-md-offset-1"><table id="myTable" class="table table-hover"><thead><tr><th>ID</th><th>集群名</th><th>出口流量(KB/s)</th><th>入口流量(KB/s)</th></tr></thead><tbody><tr ng-repeat="x in names | orderBy:'id'"><td ng-bind="x.id"></td><td ng-bind="x.name"></td><td ng-bind="x.out"></td><td ng-bind="x.in"></td></tr></tbody></table></div></div></div><script src="/static/js/jquery-1.11.3.min.js"></script><script src="/static/js/bootstrap.min.js"></script><script src="/static/js/netdata.js"></script><script src="/static/js/cls_svg.js"></script>
{% endblock %}
</html>weathermap_list.html
{% extends "layout.html" %}
{% block body %}<h3>集群流量一览表</h3><div ng-app="myApp" ng-controller="myCtrl" class="col-md-10 col-md-offset-1"><table id="myTable" class="table table-hover"><thead><tr><th>ID</th><th>集群名</th><th>出口流量(KB/s)</th><th>入口流量(KB/s)</th></tr></thead><tbody><tr ng-repeat="x in names | orderBy:'id'"><td ng-bind="x.id"></td><td ng-bind="x.name"></td><td ng-bind="x.out"></td><td ng-bind="x.in"></td></tr></tbody></table></div></div></div><script src="/static/js/jquery-1.11.3.min.js"></script><script src="/static/js/bootstrap.min.js"></script><script src="/static/js/netdata.js"></script>
{% endblock %}
</html>weathermap_plot.html
{% block body %}
<h3>集群拓扑图</h3><script src="/static/js/jquery-1.11.3.min.js"></script><script src="/static/js/bootstrap.min.js"></script><script src="/static/js/cls_svg.js"></script>
{% endblock %}
</html>最后js文件
netdata.js
var app = angular.module('myApp', []);
app.controller('myCtrl', function($scope, $http) {$http.get("/api/cluster_all/traffic").success(function(response) {$scope.names = response.ret;});
});cls_svg.js
###假如是nginx_cluster,tomcat_cluster,mysql_cluster
var nodes = [ { name: "nginx_cluster" }, { name: "tomcat_cluster" },{ name: "mysql_cluster" },{ name: "Internet" }];var edges = [ { source : 0 , target: 1 } , { source : 0 , target: 2 } ,{ source : 1 , target: 3 } , { source : 3 , target: 0}];
###上面是0到1,0到2,1到3,3到0的连线,数字分别对应上面的nodes里的name顺序
var width = 500;
var height = 500;
var svg = d3.select("body").append("svg").attr("width",width).attr("height",height);
var force = d3.layout.force().nodes(nodes) //指定节点数组.links(edges) //指定连线数组.size([width,height]) //指定范围.linkDistance(200) //指定连线长度.charge([-400]); //相互之间的作用力
force.start(); //开始作用
console.log(nodes);
console.log(edges);
//添加连线
var svg_edges = svg.selectAll("line").data(edges).enter().append("line").style("stroke","#ccc").style("stroke-width",1);
var color = d3.scale.category20();
//添加节点
var svg_nodes = svg.selectAll("circle").data(nodes).enter().append("circle").attr("r",20).style("fill",function(d,i){return color(i);}).call(force.drag); //使得节点能够拖动
//添加描述节点的文字
var svg_texts = svg.selectAll("text").data(nodes).enter().append("text").style("fill", "black").attr("dx", 20).attr("dy", 8).text(function(d){return d.name;});
force.on("tick", function(){ //对于每一个时间间隔//更新连线坐标svg_edges.attr("x1",function(d){ return d.source.x; }).attr("y1",function(d){ return d.source.y; }).attr("x2",function(d){ return d.target.x; }).attr("y2",function(d){ return d.target.y; });//更新节点坐标svg_nodes.attr("cx",function(d){ return d.x; }).attr("cy",function(d){ return d.y; });//更新文字坐标svg_texts.attr("x", function(d){ return d.x; }).attr("y", function(d){ return d.y; });
});注:我会告诉你我直接去copy来的么,d3js还在钻研ing,所以仅作demo用
然后是目录结构
├── clusters.json
├── getsource.py
├── myapp.py
├── static
│ ├── css
│ │ └── bootstrap.min.css
│ └── js
│ ├── angular.min.js
│ ├── bootstrap.min.js
│ ├── cls_svg.js
│ ├── d3.v3.min.js
│ ├── jquery-1.11.3.min.js
│ └── netdata.js
└── templates
├── layout.html
├── weathermap_all.html
├── weathermap_list.html
└── weathermap_plot.html
如果都完成了,整个项目是下面这样的
注:bootstrap,jquery,angularjs这些css,js文件百度Google下载吧
API:
查询jjjr2集群列表 http://IP:5000/api/cluster_all/list
查询jjjr2集群流量进出口情况 http://IP:5000/api/cluster_all/traffic
查询单个集群列表(如tomcat集群) http://IP:5000/api/tomcat_cluster/list
查询单个集群流量进出口情况 http://IP:5000/api/tomcat_cluster/in 其中in,out分别代表入口,出口流量
查询单个主机流量进出口情况(暂不能提供)
比如

访问:http//IP:5000/weathermap/list,仅访问列表
访问:http//IP:5000/weathermap/plot,仅访问拓扑图
访问:http//IP:5000/weathermap或者http//IP:5000/weathermap/all 查看列表与拓扑图在同一个页面
比如


存在问题:
1:mysql集群中包括了poms-mysql(后面更新)
2:拓扑图并不理想
3:页面不能实时刷新,通过在html页面加入<meta http-equiv="refresh" content="20">可页面自动刷新,可是不优雅,所以并未添加
4:并未设置阈值已区别各个集群健康情况
5:并没有考虑中间件之类,总而言之,现在很粗糙~~
总结:我们将获取zabbix数据的代码部分抽离出来做成一个模块,这样就能分工明确,也为了让代码显得不是那么庞大很难看,然后web方面主要提供功能,API以及数据展示,通过API我们可以将数据反复利用,并且有很好的兼容性,web的展示当然不能少了bootstrap,一个多漂亮的样式库,不用自己设置css,然后数据操作通过AngularJS,前台通过AngularJS去调用自身提供的API以获取数据,然后填充,最后拓扑图用强大的D3JS,这是做前端的同事推荐的~~
后记:我一直想写个项目,不是很大的项目,因为这样很快的就能写完,太大的项目要写太久太久~基于的工作阅历还不够感受到的痛点并不多,所以想到的点子并不多,并且也找到了很好的工具了,如果谁来俩点子,我帮你写出来呗~当然了,希望盈利的就算了,我想写的项目都是能直接放到github上~~大家一起爽的那种,哈哈。
在一定意义上也是为了练手。
话说,我的从无到有写一个运维APP系列如果这个月前,写不完,也就也写不完了~~~因为拖太长了,热情要没了~


![DT时代下[个推3.0]遵循的四个法则](https://image-static.segmentfault.com/367/933/3679339951-56dcf89a93fa6_articlex)

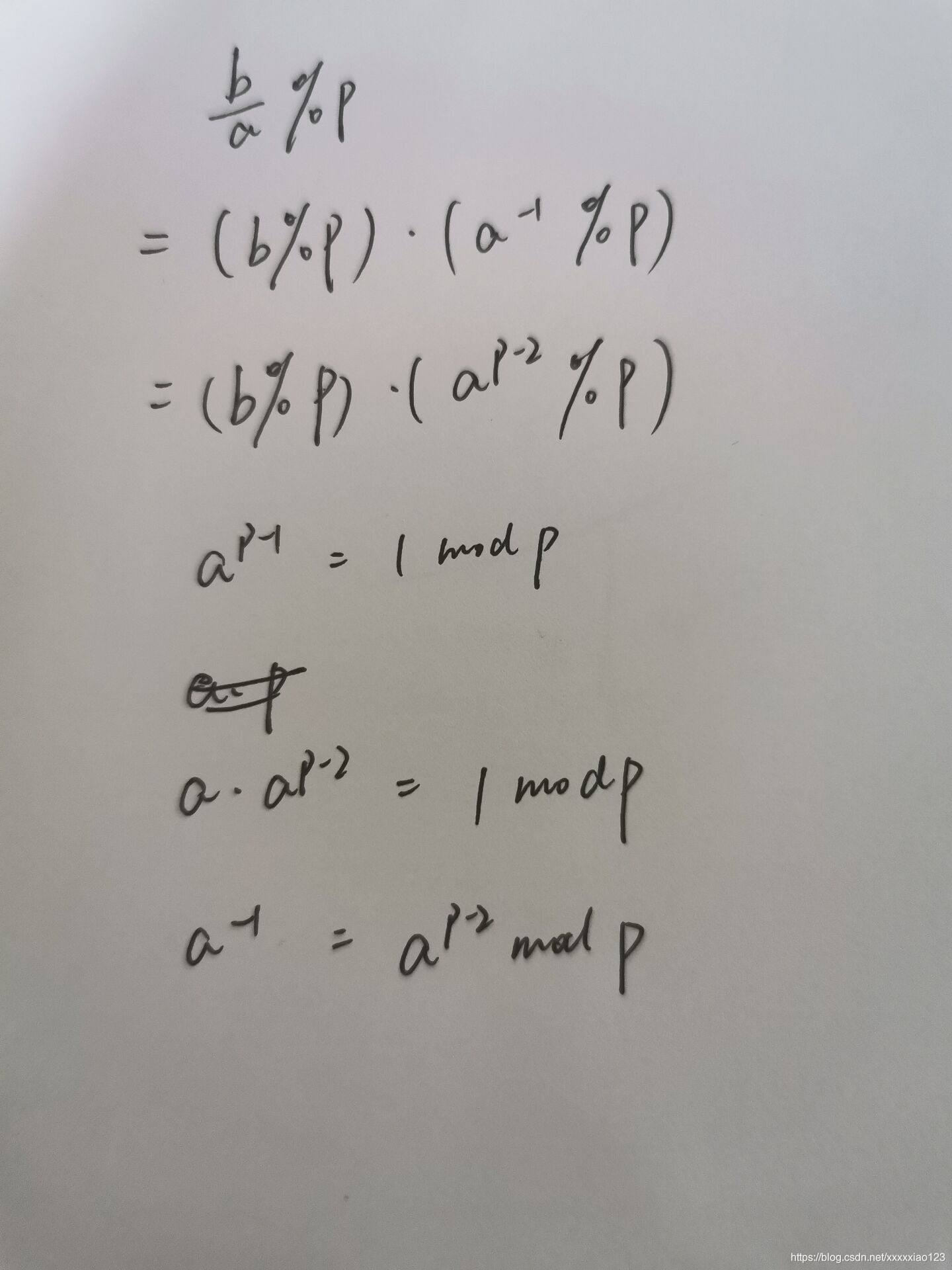
{kind=link}