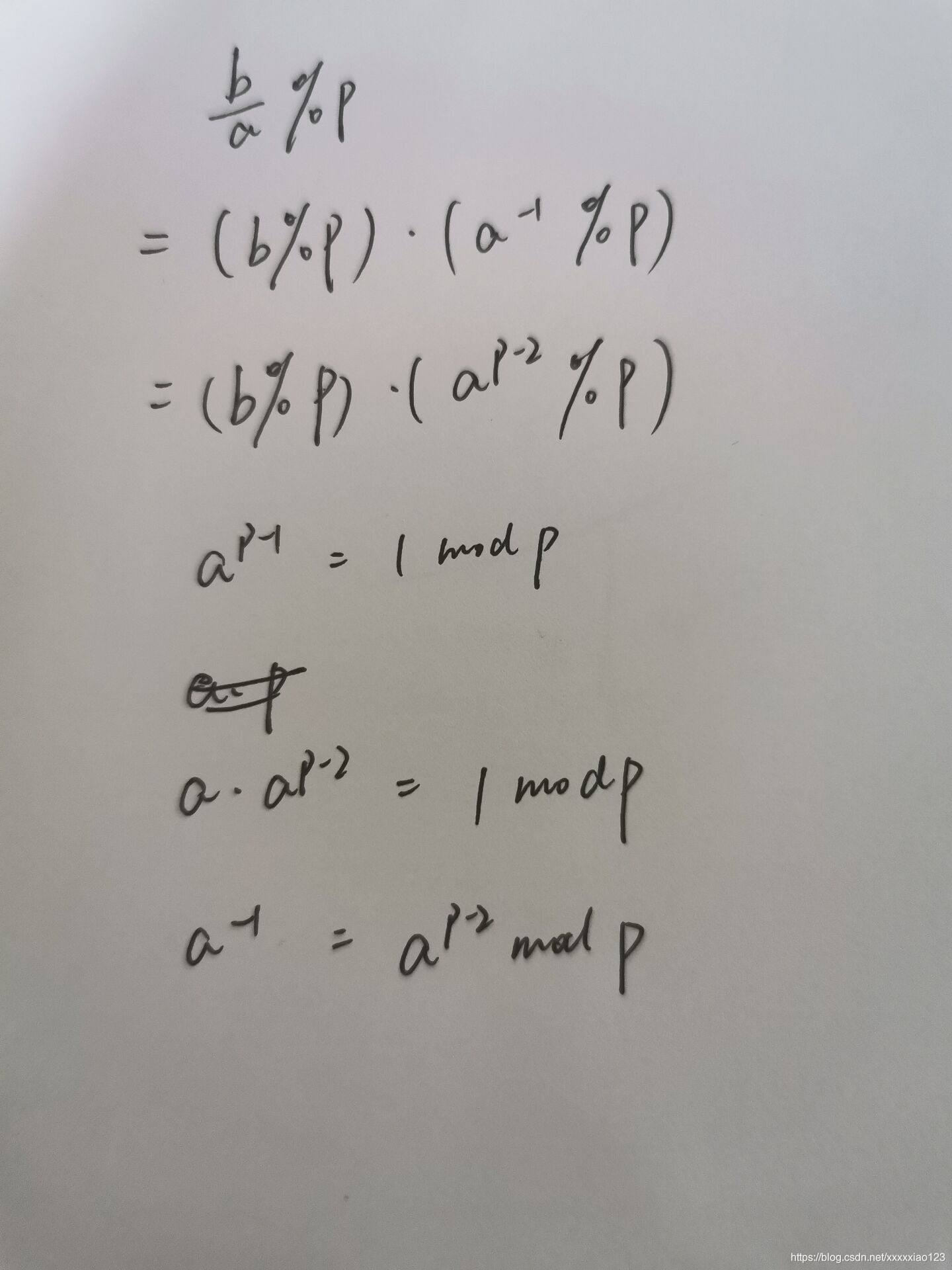作者 | shadow chi
本文经授权转载自 无界社区mixlab(ID:mix-lab)
网上大量教程都是教如何训练模型,
往往我们只学会了训练模型,
而实际应用的环节是缺失的。
def AIFullstack( ):
本文从「全栈」的角度,通过训练模型、部署成后端服务、前端页面开发等内容的介绍,帮大家更快地把深度学习的模型应用到实际场景中。
用到的技术:
keras+tensorflow+flask
web开发相关
指南分为5篇。
第一篇
介绍开发环境--训练模型--保存至本地;
第二篇
介绍导入训练好的模型--识别任意的手写数字图片;
第三篇
介绍用Flask整合keras训练好的模型,并开发后端服务;
第四篇
介绍前端web单页应用的开发。
第五篇
介绍图像处理相关知识。
return 学以致用
第一篇
介绍开发环境--训练模型--保存至本地
为了方便入门,下面采用docker的方式进行实验。
01/01
采用docker部署开发环境
首先安装好docker,本指南使用的是mac系统,window用户请查阅官方安装教程,运行docker,终端输入:
docker pull floydhub/dl-docker:cpu
在本地电脑新建一个目录,我这边是kerasStudy,路径是
/Users/shadow/Documents/02-coding/kerasStudy
大家可以改成自己本机对应的路径。
终端运行:
docker run -it -p 6006:6006 -p 8888:8888 -v /Users/shadow/Documents/02-coding/kerasStudy:/root/kerasStudy floydhub/dl-docker:cpu bash
-p 6006:6006,表示将Docker主机的6006端口与容器的6006接口绑定;
-v 参数中,冒号":"前面的目录是宿主机目录,后面的目录是容器内目录。
记得,还需要在docker中配置宿主机的与镜像共享的目录地址
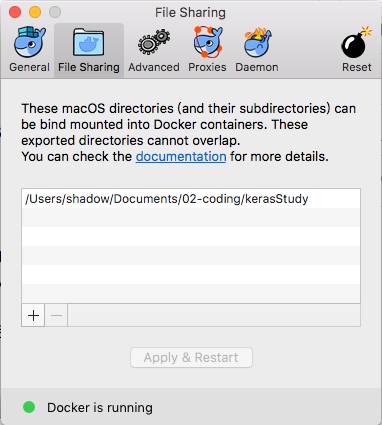
将新建一个容器,并在容器中开启一个交互模式的终端,结果如下:

01/02
启动jupyter notebook
终端输入:
mkdir $HOME/.keras/
cd $HOME/.keras/
vim keras.json
键盘按 i ,按回车及方向键控制光标,把floydhub/dl-docker:cpu镜像默认的使用Theano作为后端,改为如下:
{
"image_data_format": "channels_last",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "tensorflow"
}
按下esc键;输入:wq,保存修改结果。
终端输入:
jupyter notebook
显示jupyter notebook已经运行成功,如下图:
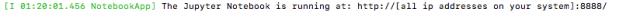
打开浏览器,在地址栏中输入:
localhost:8888
即可访问jupyter,如下图:
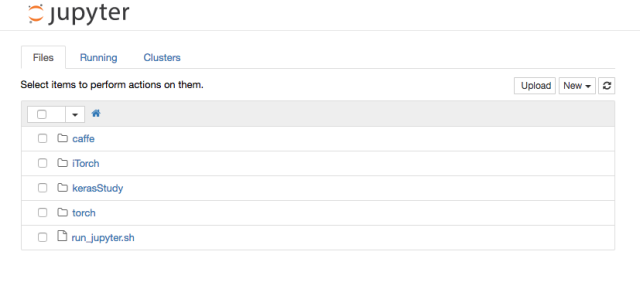
01/03
Hello Jupyter Notebook
上文提到的jupyter notebook到底是什么东西?
Jupyter Notebook 是一款集编程和写作于一体的效率工具,优点:
分享便捷
远程运行
交互式展现
在浏览器可以访问Jupyter Notebook,也就是说,我可以部署成web应用的形式,用户可以分享,通过域名访问,并且可以利用web的任何交互方式。
继续我们的教程,在浏览器打开Jupyter Notebook后,找到我们与本地共享的项目目录kerasStudy,点击进入,然后点击jupyter右上角的new,选择python2,如下图所示:
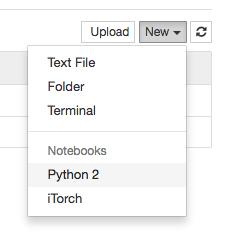
新建一个notebook。
先来做个小实验:
输入:
import numpy as np
np.random.seed(1337)
np.random.rand(5)
然后在菜单中,选择Cell--Run Cells,运行代码:
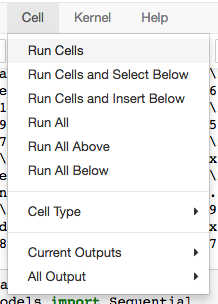
如下图所示,输出了一些结果:

第一行代码:
import numpy as np
引入 numpy ,一个用python实现的科学计算包。提供了许多高级的数值编程工具,如:矩阵数据类型、矢量处理,以及精密的运算库。专为进行严格的数字处理而产生。numpy的教程可以参看官网http://www.numpy.org/
np.random.seed()
使得随机数据可预测。相当于给随机数赋了个id,下次调用随机数的时候,只要再次取这个id,再调用随机数,即可产生相同的随机数
可以做下这个练习:
练习1
np.random.seed(0)
np.random.rand(5)
#控制台输出结果(随机生成,每次生成的都不一样)
array([ 0.5488135 , 0.71518937, 0.60276338, 0.54488318, 0.4236548 ])
练习2
np.random.seed(1676)
np.random.rand(5)
#控制台输出结果
array([ 0.39983389, 0.29426895, 0.89541728, 0.71807369, 0.3531823 ])
练习3
np.random.seed(1676)
np.random.rand(5)
#控制台输出结果
array([ 0.39983389, 0.29426895, 0.89541728, 0.71807369, 0.3531823 ])
01/04
Keras训练模型
这里结合keras的官方案例,训练一个多层感知器。
步骤1
重新建一个notebook,
输入:
from __future__ import print_function
'''
Python 3.x引入了一些与Python 2不兼容的关键字和特性,在Python 2中,
可以通过内置的__future__模块导入这些新内容。
如果你希望在Python 2环境下写的代码也可以在Python 3.x中运行,那么建议使用__future__模块。
import print_function 这里使用3.x的 print方法
在Python 3中必须用括号将需要输出的对象括起来。
在Python 2中使用额外的括号也是可以的。
但反过来在Python 3中想以Python2的形式不带括号调用print函数时,
会触发SyntaxError。
'''
import numpy as np
步骤2
from keras.datasets import mnist
# 导入mnist数据库, mnist是常用的手写数字库
from keras.models import Sequential
#导入序贯模型,Sequential是多个网络层的线性堆叠,也就是“一条路走到黑”。
from keras.layers.core import Dense, Dropout, Activation
#导入全连接层Dense,激活层Activation 以及 Dropout层
from keras.optimizers import SGD, Adam, RMSprop
#导入优化器 SGD, Adam, RMSprop
from keras.utils import np_utils
#导入numpy工具,主要是用to_categorical来转换类别向量
步骤3
#变量初始化
batch_size = 128
#设置batch的大小
nb_classes = 10
#设置类别的个数
nb_epoch = 20
#设置迭代的次数
步骤4
#准备数据
(X_train, y_train), (X_test, y_test) = mnist.load_data()
print(X_test.shape,X_test[0])
#keras中的mnist数据集已经被划分成了60,000个训练集,10,000个测试集的形式,按以上格式调用即可
X_train = X_train.reshape(60000, 784)
#X_train原本是一个60000*28*28的三维向量,将其转换为60000*784的二维向量
X_test = X_test.reshape(10000, 784)
print(X_test.shape)
#X_test原本是一个10000*28*28的三维向量,将其转换为10000*784的二维向量
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
#将X_train, X_test的数据格式转为float32存储
X_train /= 255
X_test /= 255
#归一化
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
步骤5
# 转换类标号 convert class vectors to binary class matrices
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
步骤6
#建立模型 使用Sequential()
'''
模型需要知道输入数据的shape,
因此,Sequential的第一层需要接受一个关于输入数据shape的参数,
后面的各个层则可以自动推导出中间数据的shape,
因此不需要为每个层都指定这个参数
'''
model = Sequential()
model.add(Dense(512, input_shape=(784,)))
model.add(Activation('relu'))
model.add(Dropout(0.2))
# 输入层有784个神经元
# 第一个隐层有512个神经元,激活函数为ReLu,Dropout比例为0.2
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.2))
# 第二个隐层有512个神经元,激活函数为ReLu,Dropout比例为0.2
model.add(Dense(10))
model.add(Activation('softmax'))
# 输出层有10个神经元,激活函数为SoftMax,得到分类结果
# 输出模型的整体信息
# 总共参数数量为784*512+512 + 512*512+512 + 512*10+10 = 669706
model.summary()
步骤7
#打印模型
model.summary()
步骤8
#配置模型的学习过程
'''
compile接收三个参数:
1.优化器optimizer:参数可指定为已预定义的优化器名,如rmsprop、adagrad,
或一个Optimizer类对象,如此处的RMSprop()
2.损失函数loss:参数为模型试图最小化的目标函数,可为预定义的损失函数,
如categorical_crossentropy、mse,也可以为一个损失函数
3.指标列表:对于分类问题,一般将该列表设置为metrics=['accuracy']
'''
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
步骤9
#训练模型
'''
batch_size:指定梯度下降时每个batch包含的样本数
nb_epoch:训练的轮数,nb指number of
verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为epoch输出一行记录
validation_data:指定验证集
fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况,
如果有验证集的话,也包含了验证集的这些指标变化情况
'''
history = model.fit(X_train, Y_train,
batch_size=batch_size, nb_epoch=nb_epoch,
verbose=2, validation_data=(X_test, Y_test))
这个时候,可以点击菜单栏 Cell--Run All 一下,可以看到训练过程,如下图:

步骤10
#模型评估
score = model.evaluate(X_test, Y_test, verbose=0)
print('Test score:', score[0])
print('Test accuracy:', score[1])
步骤11
#保存神经网络的结构与训练好的参数
json_string = model.to_json()
open('my_model_architecture.json','w').write(json_string)
model.save_weights('my_model_weights.h5')
第二篇
介绍导入训练好的模型--识别任意的手写数字图片
02/01
再次进入docker容器
接着上一篇,我们继续使用上次新建好的容器,可以终端输入 :
docker ps -a
显示如下图,找到上次run的容器:

我这边是容器名(NAMES)为suspicious_cori,启动它,可以终端输入:
docker start suspicious_cori
然后,终端再输入:
docker exec -i -t suspicious_cori bash
即可在容器中开启一个交互模式的终端。
然后终端输入
jupyter notebook
新建一个notebook
02/02
加载训练好的模型
加载上一篇训练好的模型,在新建的notebook里输入:
from keras.models import model_from_json
model=model_from_json(open('my_model_architecture.json').read())
model.load_weights('my_model_weights.h5')
02/03
读取需要识别的手写字图片
引入用于读取图片的库:
import matplotlib.image as mpimg
读取位于kerasStudy目录下的图片:
img = mpimg.imread('test.png')
matplotlib只支持PNG图像,读取和代码处于同一目录下的 test.png ,注意,读取后的img 就已经是一个 np.array 了,并且已经归一化处理。
上文的png图片是单通道图片(灰度),如果test.png是rgb通道的图片,可以rgb2gray进行转化,代码如下:
def rgb2gray(rgb):
return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])
img = rgb2gray(img)
关于图片的通道,我们可以在photoshop里直观的查看:
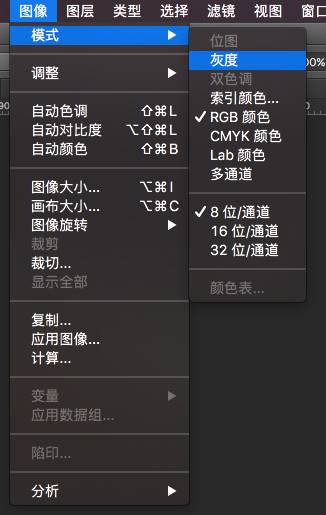
先查看下读取的图片数组维度:
print(img.shape)
输出是(28, 28)
转化成正确的输入格式:
img = img.reshape(1, 784)
打印出来看看:
print(img.shape)
输出是(1, 784)
02/04
识别的手写字图片
输入:
pre=model.predict_classes(img)
打印出来即可:
print(pre)
识别出来是6:
1/1 [==========================] - 0s
[6]
至此,你已经学会了从训练模型到使用模型进行识别任务的全过程啦。
有兴趣可以试着替换其他的手写字图片进行识别看看。
当然也可以写个后端服务,部署成web应用。
第三篇
介绍用Flask整合keras训练好的模型,并开发后端服务
03/01
目录结构
新建一个web全栈项目的文件夹,我在kerasStudy下建了个app的文件夹,app下的文件构成如下:
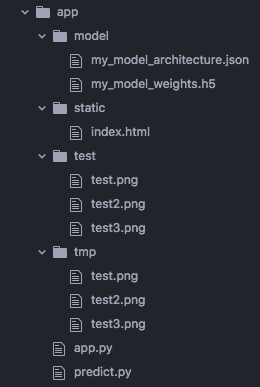
app.py是项目的主入口,主要是用flask写的一些路由;
predict.py是识别手写字的python模块;
static是放置前端页面的目录;
model存放训练好的模型;
test是一些测试图片;
tmp是前端上传到服务器的图片存放地址。
03/02
前端代码
新建一个简单的index.html文件,放置于static目录下,写一个form表单:
<form
action="./predict"
method="post"
enctype="multipart/form-data">
upload:
<input
type="file"
name="predictImg">
<input
type="submit"
name="upload">
</form>
这里的前端代码比较简单,只是一个把手写字图片提交到服务器的表单,下一篇文章将实现一个手写字的输入工具。
03/03
后端代码
app.py里,用flask设置路由,返回静态html页面:
def hello_world():
return app.send_static_file('index.html')
其余flask的相关配置代码可以参考往期文章:
用Flask写后端接口
这个时候,我们启动docker,把镜像启动,并进入docker镜像的终端中(查看第2篇),找到app目录,终端输入:
python app.py
等终端提示相关的启动信息后,在浏览器里试下,输入:
http://localhost:8888/
成功打开index.html页面:
再次编辑app.py文件,写一个predict的接口,接受前端提交的图片,并返回识别结果给前端:
def predictFromImg():
if request.method=="POST":
predictImg=request.files["predictImg"]
predictImg.save(
os.path.join(
app.config["UPLOAD_FOLDER"],
predictImg.filename))
imgurl='./tmp/'+predictImg.filename
result=predict.img2class(imgurl)
print(result)
return '<h1>Hello~~~:%s</h1>' % result
其中predict.img2class(imgurl)是一个python模块。
接下来,我们编写识别手写字的python模块。
03/04
编写识别手写字的python模块
在Python中,每个Python文件都可以作为一个模块,模块的名字就是文件的名字。比如有这样一个文件test.py,在test.py中定义了函数add:
#test.py
def add(a,b):
return a+b
那么在其他文件中就可以先import test,然后通过test.add(a,b)来调用了,当然也可以通过from test import add来引入。
回到本篇的例子,我们在第2篇中已经写过识别手写字的代码了,现在只需稍微调整下就可以形成一个python模块,供其他文件调用了。
如本篇中,在app.py中通过:
import predict
引入predict.py模块,使用的时候调用:
predict.img2class(imgurl)
#predict.py文件
详情可以参考第2篇内容
这边把上次实现过的代码,书写出一个python模块,以供其他文件调用:
import matplotlib.image as mpimg
import numpy as np
from keras.models import model_from_json
model=model_from_json(open('./model/my_model_architecture.json').read())
model.load_weights('./model/my_model_weights.h5')
def rgb2gray(rgb):
return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])
def img2class(imgFile):
img = mpimg.imread(imgFile)
print(img.shape)
img = rgb2gray(img)
print(img.shape)
img = img.reshape(1, 784)
pre=model.predict_classes(img)
result=pre[0]
return result
在docker镜像中启动伪终端,进入app目录,输入:
python app.py
上传测试图片试试:
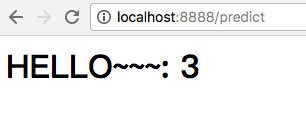
成功返回识别结果,至此,一个迷你的识别手写字web全栈应用已经完成。
第四篇
介绍前端web单页应用的开发
如果你练习里前面三篇,相信你已经熟悉了Docker和Keras,以及Flask了,接下来我们实现一个提供给用户输入手写字的前端web页面。
前端画板我们可以自己用最基本的canvas写,也可以选择封装好的开源库:
下面介绍2个比较好的模拟手写效果的画板库:
signature_pad
https://github.com/szimek/signature_pad/
drawingboard.js
https://github.com/Leimi/drawingboard.js
这边我选择的是signature_pad。
HTML代码:
<!doctype html>
<html lang="zh"><head>
<meta charset="utf-8">
<title>mnist demo</title>
<meta name="viewport" content="width=device-width,initial-scale=1, minimum-scale=1, maximum-scale=1, user-scalable=no">
<link rel="stylesheet" href="./static/css/main.css"></head>
<body onselectstart="return false">
<div id="mnist-pad">
<div class="mnist-pad-body"><canvas></canvas>
</div>
<div class="mnist-pad-footer">
<div class="mnist-pad-result"> <h5>识别结果:</h5> <h5 id="mnist-pad-result"></h5></div>
<div class="mnist-pad-actions"> <button type="button" id="mnist-pad-clear">清除</button> <button type="button" id="mnist-pad-save">识别</button>
</div>
</div></div>
<script src="./static/js/signature_pad.js"></script>
<script src="./static/js/mnist.js"></script>
<script src="./static/js/app.js"></script>
</body>
</html>
移动端注意要写这句标签,把屏幕缩放设为no,比例设为1:
<meta name="viewport" content="width=device-width,initial-scale=1, minimum-scale=1, maximum-scale=1, user-scalable=no">
CSS代码:
body { display: flex; justify-content: center; align-items: center; height: 100vh; width: 100%; user-select: none; margin: 0; padding: 0; }
h5 { margin: 0; padding: 0
}
#mnist-pad { position: relative; display: flex; flex-direction: column; font-size: 1em; width: 100%; height: 100%; background-color: #fff; box-shadow: 0 1px 5px rgba(0, 0, 0, 0.27), 0 0 40px rgba(0, 0, 0, 0.08) inset; padding: 16px; }
.mnist-pad-body { position: relative; flex: 1; border: 1px solid #f4f4f4; }
.mnist-pad-body canvas { position: absolute; left: 0; top: 0; width: 100%; height: 100%; border-radius: 4px; box-shadow: 0 0 5px rgba(0, 0, 0, 0.02) inset; }
.mnist-pad-footer { color: #C3C3C3; font-size: 1.2em; margin-top: 8px; margin-bottom: 8px; }
.mnist-pad-result { display: flex; justify-content: center; align-items: center; margin-bottom: 8px; }
.mnist-pad-actions { display: flex; justify-content: space-between; margin-bottom: 8px; }
#mnist-pad-clear { height: 44px; background-color: #eeeeee; width: 98px; border: none; font-size: 16px; color: #4a4a4a; }
#mnist-pad-save { height: 44px; background-color: #3b3b3b; width: 98px; border: none; font-size: 16px; color: #ffffff; }
CSS样式都是一些常用的,有兴趣可以自己实现个简单的UI。
JS代码,有3个文件:
signature_pad.js 这是引用的开源库;
mnist.js 这是我们给开源库写的一些扩展,下文会介绍;
app.js主要是一些初始化,事件绑定,请求后端接口的处理。
先来看看app.js:
步骤1
初始化画板,绑定按钮事件;
var clearBtn = document.getElementById("mnist-pad-clear");
var saveBtn = document.getElementById("mnist-pad-save");
var canvas = document.querySelector("canvas");
var mnistPad = new SignaturePad(canvas, {
backgroundColor: 'transparent',
minWidth: 6,
maxWidth: 8
});
clearBtn.addEventListener("click", function (event) { mnistPad.clear(); });
saveBtn.addEventListener("click", function (event) {
if (mnistPad.isEmpty()) { alert("请书写一个数字"); } else { mnistPad.getMNISTGridBySize(true,28,img2text); } });
注意minWidth及MaxWidth的设置,我试验下来,比较好的数值是6跟8,识别效果较好,也可以自行试验修改。
ministPad的方法,getMNISTGridBySize将把截取画板上的手写数字,并缩放成28x28的尺寸,然后调用img2text函数。
img2text主要是把28x28的图片传给后端,获取识别结果,这边由于canvas的数据是base64,需要用到转化为blob的函数,dataURItoBlob(github上有写好的),转化后通过构造一个表单,注意文件名predictImg一定要与后端flask接受函数里的写的一致。调用XMLHttpRequest请求后端接口即可。
步骤2
这一步“如何把canvas生成的图片上传至后端”是个很典型的问题。
function img2text(b64img){
var formData = new FormData();
var blob = dataURItoBlob(b64img);
formData.append("predictImg", blob);
var request = new XMLHttpRequest();
request.onreadystatechange = function () {
if (request.readyState == 4) {
if ((request.status >= 200 && request.status < 300) || request.status == 304) {
console.log(request.response)
document.querySelector('#mnist-pad-result').innerHTML=request.response; }; } }; request.open("POST", "./predict"); request.send(formData); };
步骤3
还有一个比较重要的函数:
画板根据屏幕尺寸自适应的代码(尤其是PC端,记得加):
function resizeCanvas() {
var ratio = Math.max(window.devicePixelRatio || 1, 1); canvas.width = canvas.offsetWidth; canvas.height = canvas.offsetHeight;
// canvas.getContext("2d").scale(ratio, ratio); mnistPad.clear(); };
window.onresize = resizeCanvas; resizeCanvas();
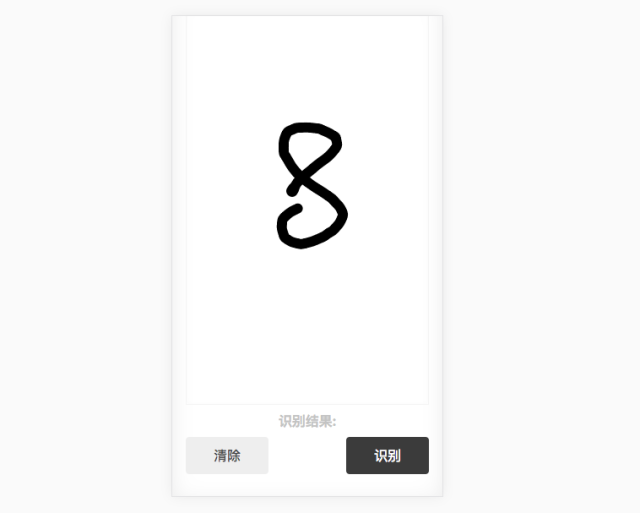
到这一步可以试一下前端的输入效果先:
接下来完成mnist.js
步骤4
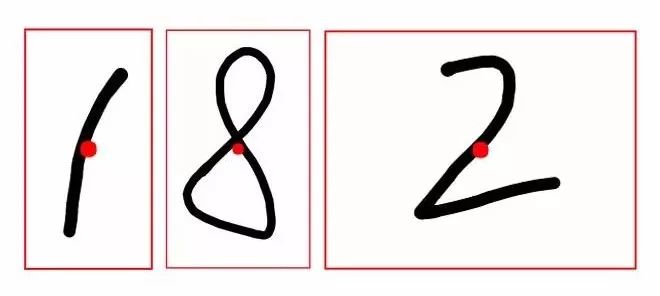
signature_pad有个方法是toData,可以获取所有手写输入的坐标点。
var ps=mnistPad.toData()[0];
mnistPad._ctx.strokeStyle='red';
ps.forEach((p,i)=>{ mnistPad._ctx.beginPath(); mnistPad._ctx.arc(p.x, p.y, 4, 0, 2 * Math.PI); mnistPad._ctx.stroke(); })
我们可以在chrome的控制台直接试验。
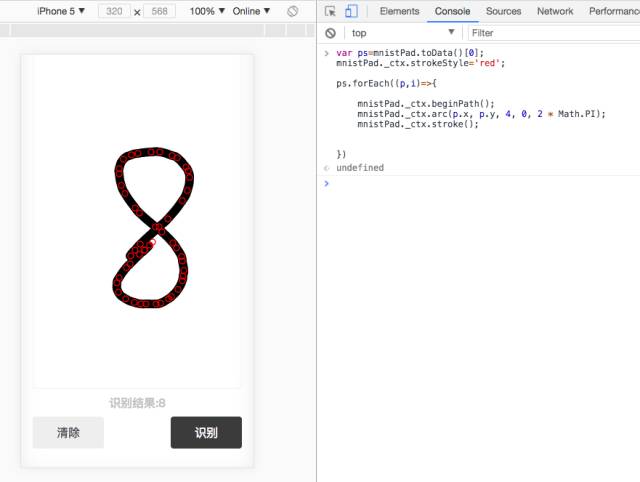
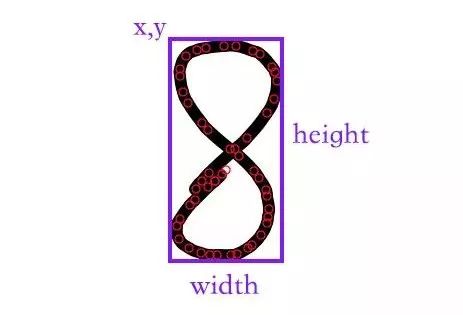
红色的圈圈就是所有的坐标点,只要求出如下图所示的紫色框,第一步也就完成了。
步骤5
给signature_pad扩展个getArea方法:
SignaturePad.prototype.getArea = function() {
var xs = [], ys = [];
var orign = this.toData();
for (var i = 0; i < orign.length; i++) {
var orignChild = orign[i];
for (var j = 0; j < orignChild.length; j++) { xs.push(orignChild[j].x); ys.push(orignChild[j].y); } };
var paddingNum = 30;
var min_x = Math.min.apply(null, xs) - paddingNum;
var min_y = Math.min.apply(null, ys) - paddingNum;
var max_x = Math.max.apply(null, xs) + paddingNum;
var max_y = Math.max.apply(null, ys) + paddingNum;
var width = max_x - min_x, height = max_y - min_y;
var grid = { x: min_x, y: min_y, w: width, h: height };
return grid;
};
测试下:
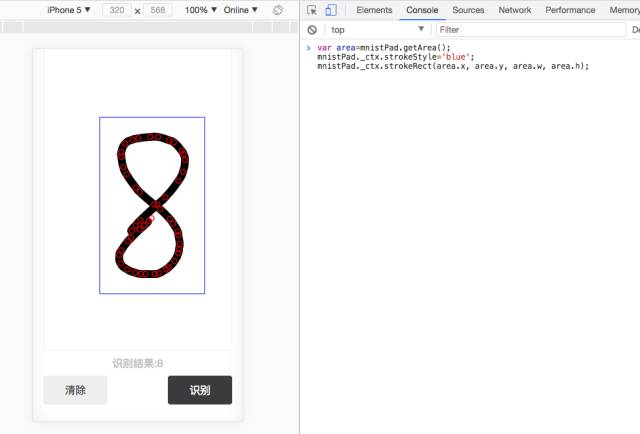
注意paddingNum,我设置了个30的值,把边框稍微放大了下,原因见mnist手写字训练集的图片就知道啦。
到这一步,我们的手写字数据集是下图这样的:

步骤6
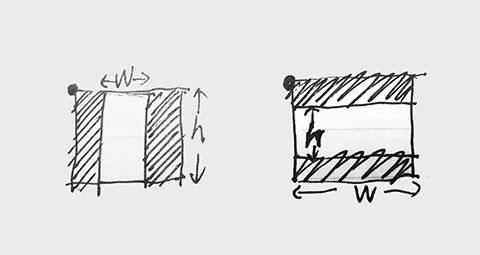
我们还需要把边框变成方形。
再写个转换函数:
SignaturePad.prototype.change2grid = function(area) {
var w = area.w, h = area.h, x = area.x, y = area.y;
var xc = x, yc = y, wc = w, hc = h;
if (h >= w) { xc = x - (h - w) * 0.5; wc = h; } else { yc = y - (w - h) * 0.5; hc = w; };
return { x: xc, y: yc, w: wc, h: hc } }
原理如下图,判断下长边是哪个,然后计算出x,y,width,height即可。
写好代码后,试一下:
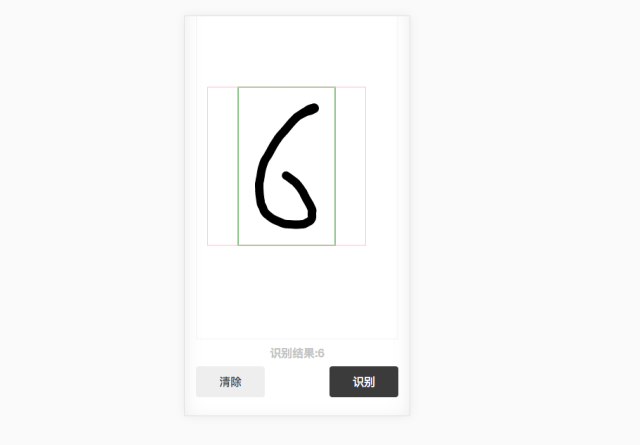
红框是最后要提交的范围。
这个时候,还要处理下,把图片变成黑底白字的图片,因为MNIST数据集是这样的。
步骤7
主要代码如下:
ctx.fillStyle = "white"; ctx.fillRect(0, 0, grid.w, grid.h);
ctx.drawImage(img, grid.x, grid.y, grid.w, grid.h, 0, 0, size, size);
var imgData = ctx.getImageData(0, 0, size, size);
for (var i = 0; i < imgData.data.length; i += 4) { imgData.data[i] = 255 - imgData.data[i]; imgData.data[i + 1] = 255 - imgData.data[i + 1]; imgData.data[i + 2] = 255 - imgData.data[i + 2]; imgData.data[i + 3] = 255; }
ctx.putImageData(imgData, 0, 0);
画上背景,遍历像素,把颜色反色下就ok啦。
最后都测试下:

最后,注意下MNIST数据集里的数据,对应的是灰度图,28x28的尺寸,黑底白字,并且数字是像素的重心居中处理的。本文没有介绍如何把web前端的手写字根据重心居中处理这一内容,将会挑选合适时机介绍,用上了可以提高识别率哦!
第五篇
图像处理
再回顾下MNIST手写字数据集的特点:每个数据经过归一化处理,对应一张灰度图片,图片以像素的重心居中处理,28x28的尺寸。
上一篇中,对canvas手写对数字仅做了简单对居中处理,严格来说,应该做一个重心居中的处理。
本篇主要介绍:
如何实现前端的手写数字按重心居中处理成28x28的图片格式。
我们先把前端canvas中的手写数字处理成二值图,求重心主要运用了二值图的一阶矩,先来看下零阶矩:

二值图在某点上的灰度值只有0或者1两个值,因此零阶矩为二值图的白色面积总和。

只要把上文的公式转为JS代码,即可求出重心坐标:
SignaturePad.prototype.getGravityCenter = function() {
var w = this._ctx.canvas.width, h = this._ctx.canvas.height;
var mM = 0, mX = 0, mY = 0;
var imgData = this._ctx.getImageData(0, 0, w, h);
for (var i = 0; i < imgData.data.length; i += 4) {
var t = imgData.data[i + 3] / 255;
var pos = this.pixel2Pos(i);
mM = mM + t; mX = pos.x * t + mX; mY = pos.y * t + mY;
};
var center = { x: mX / mM, y: mY / mM }
return center
};
pixel2Pos是我另外写的根据i求出点坐标的函数:
SignaturePad.prototype.pixel2Pos = function(p) {
var w = this._ctx.canvas.width, h = this._ctx.canvas.height;
var y = Math.ceil((p + 1) / 4 / w);
var x = Math.ceil((p + 1) / 4 - (y - 1) * w);
return { x: x, y: y }
}
这里要注意下:
getImageData() 方法返回 ImageData 对象,该对象拷贝了画布指定矩形的像素数据。
对于 ImageData 对象中的每个像素,都存在着四方面的信息,即 RGBA 值:
R - 红色 (0-255)
G - 绿色 (0-255)
B - 蓝色 (0-255)
A - alpha 通道 (0-255; 0 是透明的,255 是完全可见的)
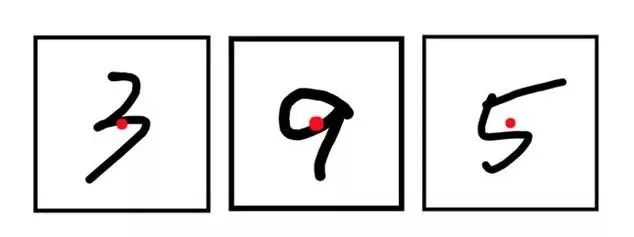
根据以上的代码就可以找出重心,如下图红点所示位置:
以重心为中心,把数字放置于28x28的正方形中,剪切出来,传给后端即可。
以上为指南全文。
本文整理自往期 MixLab无界社区文章。
(本文为AI科技大本营转载文章,转载请联系作者。)
征稿
推荐阅读:
给Chrome“捉虫”16000个,Google开源bug自检工具
2019全球AI 100强,中国占独角兽半壁江山,但忧患暗存
“百练”成钢:NumPy 100练
赵本山:我的时代还没有结束 | Python告诉你
“不厚道”的程序员:年后第一天上班就提辞职
微信帝国进化史:一个通讯工具如何在八年内制霸互联网?
Facebook神秘区块链部门首次收购,开放这些职位,你的技能符合吗?
写给程序员的裁员防身指南
这4门AI网课极具人气,逆天好评!(附代码+答疑)

点击“阅读原文”,打开CSDN APP 阅读更贴心!