点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达本文转自:计算机视觉联盟
AI博士笔记系列推荐
周志华《机器学习》手推笔记正式开源!可打印版本附pdf下载链接
[ 摘要 ]在这篇教程中,你将会学到如何用基于图像的对抗攻击来破坏深度学习模型。我们将会利用Keras和TensorFlow深度学习库来实现自己的对抗攻击。

试想下从现在起的二十年后。现在路上所有的车辆都是利用人工智能、深度学习和计算机视觉来驱动的无人驾驶交通工具。每一次转弯、车道转换、加速和刹车都是由深度神经网络来提供技术支持。现在,想象自己在高速路上,你正坐在“驾驶室(当车自主行驶时,驾驶室还能被称为‘驾驶室’吗?)”里,你的妻子坐在副驾上,你的孩子们坐在后座。
朝前看,你看到一张巨大的贴纸正在车辆所行驶的车道上,这看上去对车的前进毫无影响。看上去这像是一张受欢迎的大幅涂鸦艺术版画,可能是几个高中生开玩笑把它放在这里,或者他们只是为了完成某个大冒险游戏。

图一:执行一次对抗攻击需要一张输入图像(左),故意用一个噪声向量来扰乱它(中),迫使神经网络对输入图像进行错误分类,最后得到一个错误的分类结果,很可能会出现一次严重的后果(右)。
一瞬间,你的汽车突然急刹车,然后立即变道,因为放在路上的那张贴画可能印的是行人、动物或者另一辆汽车。你在车里被猛推了一下,感到颈部似乎受了伤。你的妻子尖叫着,孩子们的零食在后座上蹦了起来,弹在挡风玻璃上后洒在中控台上。你和你的家人都很安全,但所经历的这一切看上去不能再糟糕了。
发生了什么?为什么你的自动驾驶车辆会做出这样的反应?是不是车内的某段代码或者某个软件存在奇怪的“bug”?
答案就是,为车辆视觉组件提供技术支持的深度神经网络看到了一张对抗图像。
对抗图像是指:含有蓄意或故意干扰像素来混淆或欺骗模型的图像。
但与此同时,这张图像对于人类来说看上去是无害且无恶意的。
这些图像导致深度神经网络故意做出错误的预测。对抗图像在某种方式上去干扰模型,导致它们无法做出正确的分类。
事实上,人类通过视觉可能无法区分正常图片和对抗攻击的图片——本质上,这两张图片对于肉眼来说是相同的。
这或许不是一个准确(或者说正确)的类比,但我喜欢在图像密码学的背景下来解释对抗进攻。利用密码学算法,我们可以把数据(例如纯文本信息)嵌入到图像中,且不改变图像本身的表象。这幅图像可以纯粹地传送到接收者那里,然后接收者再去提取图像中所隐藏的信息。
同样的,对抗攻击在输入图像中嵌入一条信息,但是这条信息并非是人们可以理解的纯文本信息,因为对抗攻击所嵌入到输入图像的是一个噪声向量。这个噪声向量是用于戏弄或混淆深度学习模型而故意构建的。
对抗攻击是如何起作用的?我们应该如何去进行防御呢?
在这篇教程中,以及这个系列的其他推文中,我们将会准确地去回答这些问题。
想要了解如何用Keras/TensorFlow在对抗攻击和图像中来破坏深度学习模型,请继续往下读。
利用Keras和TensorFlow来实现对抗图像和攻击
在这篇教程中的第一部分,会讨论下对抗攻击是什么以及它们是如何影响深度学习模型的。
在那之后,我们会实现三段独立的Python脚本:
第一段Python脚本是加载ImageNet数据集并解析类别标签的使用助手。
第二段Python脚本是利用在ImageNet数据集上预训练好的ResNet模型来实现基本的图像分类(由此来演示“标准”的图像分类)。
最后一段Python脚本用于执行一次对抗攻击,并且组成一张故意混淆我们的ResNet模型的对抗图像,而这两张图像对于肉眼来说看上去是一样的。
让我们开始吧!
什么是对抗对象和对抗攻击呢?它们是如何影响深度学习模型的呢?

图二:当执行对抗攻击时,给予神经网络一张图像(左),然后利用梯度下降来构建一个噪声向量(中)。这个噪声向量被加入到输入图像中,生成一个误分类(右)。
在2014年,古德费洛等人发表了一篇名为《Explaining and HarnessingAdversarial Examples(解释并驯服对抗样本)》的论文,展示了深度神经网络吸引人的属性——有可能故意扰乱一张输入图像,导致神经网络对其进行错误的分类。这种扰乱就被称为对抗攻击。
经典的对抗攻击示例就像上面图二所展示的一样。在左边,我们的输入图像在神经网络中被分在“熊猫”类别,置信度为57.7%。
在中间有一个噪音向量,在人类眼中看上去是随机的,但事实上绝非如此。
恰恰相反,这一噪声向量中的像素“等于输入图像的损失函数的梯度元素符号”(Goodfellow et al.)。
把这个噪声向量嵌入到输入图像中,产出了图二中的输出(右)。对于我们来说,这副新图像看起来与输入图像完全一样,但我们的神经网络却会将这站图像分到“长臂猿”类别,置信度高达99.7%。很奇怪吧!
一段对抗攻击和对抗图像的简短历史
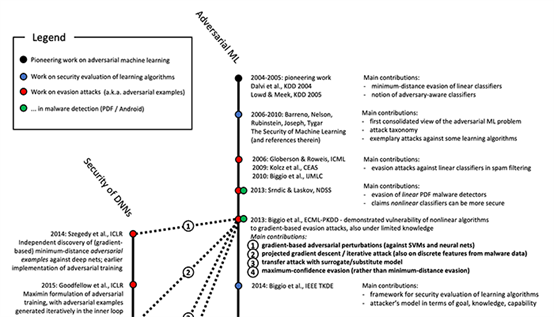
图三:一个关于对抗机器学习和深度神经网络安全性出版物的时间轴(图片来源:CanMachine Learning Be Secure?图8)
对抗机器学习并不是一个新兴领域,这些攻击也不是针对深度神经网络。在2006年,巴雷诺等人发表了一篇名为《CanMachine Learning Be Secure?》的论文。论文讨论了对抗攻击,包括提出了一些对抗攻击的防御方式。
回到2006年,最先进的机器学习模型包括支持向量机(SVMs)和随机森林(RFs),这两种类型的模型均易受对抗攻击的影响。
随着2012年深度神经网络的普及度开始升高,曾寄希望于这些非线性的模型不会轻易受到这种攻击的影响,然而古德费洛等人打破了这一幻想。
他们发现深度神经网络和“前辈们”一样,都很容易受到对抗攻击的影响。
想要了解更多关于对抗攻击的历史,我建议你们去看下比格奥(Biggio)和罗利(Roli)在2017年发表的论文《Wild Patterns: Ten Years Afterthe Rise of Adversarial Machine Learning.》
为什么对抗攻击和对抗图像会成为一个麻烦呢?
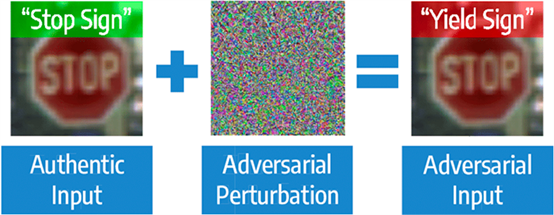
图四:为什么对抗攻击会是一种麻烦?为什么我们应该关注它?(图片来源imagesource)
本篇教程顶部所谈到的示例中概述了为什么对抗攻击会给我们的健康、生活和财产带来严重损失。
另外一些后果没有那么严重的示例,例如一群黑客识别了一个谷歌用于给Gmail过滤垃圾邮件的模型,或者识别了一个Facebook自动检测色情内容的NSFW(不适合上班时间浏览)过滤器模型。
如果这些黑客想要绕过Gmail垃圾邮件过滤器来让用户受到资源过载攻击,或者绕过Facebook的NSFW过滤器来上传大量的色情内容,理论上讲他们是可以做到的。
这些都是对抗攻击中造成轻微后果的示例。
关于到对抗攻击带有严重后果的剧本可以包括黑客恐怖分子识别了全世界自动驾驶汽车所使用的深度神经网络(试想一下如果特斯拉垄断了市场,成为世界唯一自动驾驶汽车生产商)。
对抗图片有可能被有战略性地摆放在车道或公路上,造成连环车祸、财产损失或车内乘客的受伤甚至死亡。
只有你的想象力,对已知模型的了解程度以及对模型的使用程度是对抗攻击的天花板。
我们能够抵御对抗攻击吗?
好消息是我们可以降低对抗攻击所造成的影响(但无法将它们完全消除)。
这方面的话题将不会在今天的教程中展开,可能会在未来的教程中进行讨论。
配置你的开发环境
在这篇教程中配置你的系统,我建议你跟随这两篇教程:
如何在Ubuntu系统下配置TensorFlow2.0 ?(How to installTensorFlow 2.0 on Ubuntu)
如何在macOS系统下配置TensorFlow2.0 ?How to install TensorFlow 2.0 on macOS
这两篇教程都会协助你在便捷的Python虚拟环境中利用必要的软件来配置系统。
项目结构:
$ tree --dirsfirst
.
├── pyimagesearch
│ ├── __init__.py
│ ├── imagenet_class_index.json
│ └── utils.py
├── adversarial.png
├── generate_basic_adversary.py
├── pig.jpg
└── predict_normal.py
1 directory, 7 files
在pyimagesearch模块中,有两个文件:
imagenet_class_index.json: 一个JSON文件,将ImageNet类别标签标记为可读的字符串。我们将会利用这个JSON文件来决定这样一组特殊标签的整数值索引,在构建对抗图像攻击时,这个索引将会给予我们帮助。
utils.py: 包含简单的Python辅助函数,用于载入和解析imagenet_class_index.json
这里面还有两个我们今天需要检验的Python脚本:
predict_normal.py: 接收一张输入图像(pig.jpg),载入ResNet50模型,对输入图像进行分类。这个脚本的输出会是预测类别标签在ImageNet的类别标签索引。
generate_basic_adversary.py:利用predict_normal.py脚本中的输出,我们将构建一次对抗攻击来欺骗ResNet,这个脚本的输出(adversarial.png)将会存储在硬盘中。
做好准备来实现你的第一个Keras和TensorFlow中的对抗攻击了吗?让我们开始吧。
ImageNet 类别标签/索引帮助实用程序
在我们开始执行正常的图像分类或者对抗攻击使用的混淆图像分类之前,首先需要创建一个Python辅助函数来载入和解析ImageNet数据集的类别标签。
我们提供了一个JSON文件包含所有的类别标签索引、标识符和可读的字符串,全都包含在项目目录结构中pyimagesearch模块的imagenet_class_index.json文件里。
在这里展示JSON文件的前几行:
{
"0": [
"n01440764",
"tench"
],
"1": [
"n01443537",
"goldfish"
],
"2": [
"n01484850",
"great_white_shark"
],
"3": [
"n01491361",
"tiger_shark"
],
...
"106": [
"n01883070",
"wombat"
],
...
在这里可以看到这个文件是一个字典格式的。字典的关键字是类别标签的整数值索引,而值由二元元组组成:
ImageNet标签的唯一标识符;
有可读性的类别标签。
我们的目标是实现一个Python函数可以解析JSON文件:
接收一个输入标签;
转化成其对应标签的类别标签整数值索引。
实际上,我们就是转换imagenet_class_index.json文件中的键与值(key/value)的关系。
让我们来实现这个辅助函数吧。
打开pyimagesearch模块的utils.py文件,插入下列代码:
# importnecessary packages
import json
import os
defget_class_idx(label):
# build the path to theImageNet class label mappings file
labelPath = os.path.join(os.path.dirname(__file__),
"imagenet_class_index.json")
第2行和第3行引入我们所需要的Python包。我们要用到json Python模块来载入JSON文件,而os包用于构建文件路径,这与你使用的是什么操作系统并无关系。
接下来我们去定义get_class_idx辅助函数。这个函数的目标是接收一个输入类别标签,然后获得预测(即在ImageNet上所训练出的模型在1000个标签类别中做出的预测)的标签类别的整数值索引。
第7行是组成能够载入 pyimagesearch模块中的imagenet_class_index.json的路径。
现在载入JSON文件中的内容:
# open theImageNet class mappings file and load the mappings as
# a dictionary with the human-readable class label as the keyand
# the integerindex as the value
withopen(labelPath)as f:
imageNetClasses = {labels[1]: int(idx)for(idx, labels)in
json.load(f).items()}
# check to see if the inputclass label has a corresponding
# integer index value, and if so return it; otherwise return
# a None-type value
return imageNetClasses.get(label, None)
第4-6行,打开labelPath文件,然后将键值对的关系进行转换,这样键才是可读的标签字符串,而值是那个标签的整数值索引。
为了获得输入标签的整数值索引,可以调用imageNetClasses字典中的.get方法(最后一行),会返回:
如果在字典中存在改标签的话,则返回该标签的整数值索引;
否则返回None。
这个值返回到调用函数。
让我们在下一章节来构建get_class_idx辅助函数。
利用Keras和TensorFlow在没有对抗攻击的情况下进行图片分类
在实现了ImageNet 类标签/索引辅助函数后,让我们构造一个图像分类脚本,在没有对抗攻击的情况下实现基本分类的图像分类脚本。
这个脚本可以证明我们的ResNet模型表现正常(做出正确地预测)。在这篇教程的后半部分,你们将会发现如何构建一张对抗图像用于混淆ResNet。
让我们开始基本的图像分类脚本——在你的工程文件结构中打开predict_normal.py文件,并插入以下代码:
# import necessarypackages
from pyimagesearch.utils import get_class_idx
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.applications.resnet50 import decode_predictions
from tensorflow.keras.applications.resnet50 import preprocess_input
import numpy as np
import argparse
import imutils
import cv2
在第2-9行,我们引入了所需的Python包。如果你之前使用过Keras,TensorFlow和OpenCV的话,这些对你来说都是常规操作。
如果你是Keras和TensorFlow的新手,我强烈建议你去看一下我的这篇《KerasTutorial: How to get started with Keras, Deep Learning, and Python》教程。另外,你或许想要读一读我的书《DeepLearning for Computer Vision with Python》加深你对训练自定义神经网络的理解。
在第2行,我们引入了在上一章节中定义的get_class_idx函数,这个函数可以获得ResNet50模型中最高预测标签的整数索引值。
让我们定义下 preprocess_image辅助函数:
defpreprocess_image(image):
# swap color channels,preprocess the image, and add in a batch
# dimension
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
image = preprocess_input(image)
image = cv2.resize(image, (224, 224))
image = np.expand_dims(image, axis=0)
# return the preprocessed image
return image
preprocess_image 方法接收一个单一的必需参数,那就是我们想要预处理的图片。
对这张图片进行预处理有以下几步:
将图片的BGR通道组合转化为RGB;
执行preprocess_input函数,用于完成ResNet50中特别的预处理和比例缩放过程;
将图片大小调整为224×224;
增加一个批次维度。
这张预处理好的图像会被返回到调用函数中。
接下来,让我们解析下指令参数:
# construct the argument parser and parsethe arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image",required=True,
help="pathto input image")
args = vars(ap.parse_args())
我们在这里只需要一个命令行参数,--image,即输入图像存放在硬盘上的路径。
如果你从来没有处理过命令行参数和argparse ,我建议你看一下这篇教程。
接下来让载入输入图像并进行预处理:
# load image fromdisk and make a clone for annotation
print("[INFO] loadingimage...")
image = cv2.imread(args["image"])
output = image.copy()
# preprocess the input image
output = imutils.resize(output, width=400)
preprocessedImage = preprocess_image(image)
通过调用cv2.imread来载入输入图片。在第4行对这张图片进行了复制,以便后期在输出结果上面画框并标注上预测结果类别标签。
我们调整下输出图片的尺寸,让它的宽变为400像素,这样可以适配我们的电脑屏幕。在这里同样使用preprocess_image函数将其处理为可用于ResNet进行分类的输入图片。
加上我们预处理好的图片,接着载入ResNet并对图片进行分类:
# load thepre-trained ResNet50 model
print("[INFO] loadingpre-trained ResNet50 model...")
model = ResNet50(weights="imagenet")
# makepredictions on the input image and parse the top-3 predictions
print("[INFO] makingpredictions...")
predictions =model.predict(preprocessedImage)
predictions = decode_predictions(predictions, top=3)[0]
第3行,载入ResNet和该模型用ImageNet数据集预训练好的权重。
第6和7行,针对预处理好的图片进行预测,然后再用 Keras/TensorFlow 中的decode_predictions辅助函数对图片进行解码。
现在让我们看看神经网络预测的Top 3 (置信度前三)类别以及所展示的类别标签:
# loop over thetop three predictions
for(i, (imagenetID, label,prob))inenumerate(predictions):
# print the ImageNet class label ID of the top prediction to our
# terminal (we'll need thislabel for our next script which will
# perform the actual adversarial attack)
if i == 0:
print("[INFO] {} => {}".format(label, get_class_idx(label)))
# display the prediction to our screen
print("[INFO] {}.{}: {:.2f}%".format(i + 1, label, prob * 100))
第2行开始循环Top-3预测结果。
如果这是第一个预测结果(即Top-1预测结果),在输出终端显示可读的标签,然后利用 get_class_idx函数找出该标签对应的ImageNet的整数值索引。
还可以在终端上展示Top-3的标签和对应的概率值。
最终一步就是将Top-1预测结果标注在输出图片中:
# draw thetop-most predicted label on the image along with the
# confidence score
text = "{}:{:.2f}%".format(predictions[0][1],
predictions[0][2] * 100)
cv2.putText(output, text, (3, 20),cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 255, 0), 2)
# show the output image
cv2.imshow("Output", output)
cv2.waitKey(0)
输出图像在终端显示,如果你单击OpenCV窗口或按下任意键,输出图像将会关闭。
非对抗图像的分类结果
现在可以用ResNet来执行基本的图像分类(非对抗攻击)了。
首先在“下载“页获取源代码和图像范例。
从这开始,打开一个终端并执行以下命令:
$ pythonpredict_normal.py --image pig.jpg
[INFO] loading image...
[INFO] loadingpre-trained ResNet50 model...
[INFO] making predictions...
[INFO] hog => 341
[INFO] 1. hog: 99.97%
[INFO] 2.wild_boar: 0.03%
[INFO] 3. piggy_bank: 0.00%

图五:预训练好的ResNet模型可以正确地将这张图片分类为“猪(hog)”。
在这里你可以看到我们将一张猪的图片进行了分类,置信度为99.97%。
另外,这里还加上了hog标签的ID(341)。我们将会在下一章用到这个标签ID,我们会针对这张猪的输入图片进行一次对抗攻击。
在Keras和TensorFlow上实现对抗图像和对抗攻击
接下来就要学习如何在Keras和TensorFlow上实现对抗图像和对抗攻击。
打开generate_basic_adversary.py文件,插入以下代码:
# import necessary packages
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.losses importSparseCategoricalCrossentropy
from tensorflow.keras.applications.resnet50 import decode_predictions
from tensorflow.keras.applications.resnet50 import preprocess_input
import tensorflow as tf
import numpy as np
import argparse
import cv2
在第2-10行中引入我们所需的Python包。你会注意到我们再次用到了ResNet50 架构,以及对应的preprocess_input函数(用于预处理/缩放输入图像)和 decode_predictions用于解码预测输出和显示可读的ImageNet标签。
SparseCategoricalCrossentropy 用于计算标签和预测值之间的分类交叉熵损失。利用稀疏版本的分类交叉熵,我们不需要像使用scikit-learn的LabelBinarizer或者Keras/TensorFlow的to_categorical功能一样用one-hot对类标签编码。
例如在predict_normal.py脚本中有preprocess_image 功能,我们在这个脚本上同样需要:
defpreprocess_image(image):
# swap color channels, resizethe input image, and add a batch
# dimension
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (224, 224))
image = np.expand_dims(image, axis=0)
# return the preprocessedimage
return image
除了省略了调用preprocess_input函数,这一段代码与上一段代码相同,当我们开始创建对抗图像时,你们马上就会明白为什么省去调用这一函数。
接下来,我们有一个简单的辅助程序,clip_eps:
defclip_eps(tensor, eps):
# clip the values of thetensor to a given range and return it
return tf.clip_by_value(tensor,clip_value_min=-eps,
clip_value_max=eps)
这个函数的目的就是接受一个输入张量tensor,然后在范围值 [-eps, eps]内对输入进行截取。
被截取后的tensor会被返回到调用函数。
接下来看看generate_adversaries 函数,这是对抗攻击的灵魂:
defgenerate_adversaries(model, baseImage,delta, classIdx, steps=50):
# iterate over the number ofsteps
for step inrange(0, steps):
# record our gradients
with tf.GradientTape()as tape:
# explicitly indicate thatour perturbation vector should
# be tracked for gradient updates
tape.watch(delta)
generate_adversaries 方法是整个脚本的核心。这个函数接收四个必需的参数,以及第五个可选参数:
model:ResNet50模型(如果你愿意,你可以换成其他预训练好的模型,例如VGG16,MobileNet等等);
baseImage:原本没有被干扰的输入图像,我们有意针对这张图像创建对抗攻击,导致model参数对它进行错误的分类。
delta:噪声向量,将会被加入到baseImage中,最终导致错误分类。我们将会用梯度下降均值来更新这个delta 向量。
classIdx:通过predict_normal.py脚本所获得的类别标签整数值索引。
steps:梯度下降执行的步数(默认为50步)。
第3行开始循环设定好的步数。
接下来用GradientTape来记录梯度。在tape上调用 .watch方法指出扰动向量是可以用来追踪更新的。
现在可以建造对抗图像了:
# add our perturbation vector to the base image and
# preprocess the resulting image
adversary = preprocess_input(baseImage + delta)
# run this newly constructed image tensor through our
# model and calculate theloss with respect to the
# *original* class index
predictions = model(adversary,training=False)
loss = -sccLoss(tf.convert_to_tensor([classIdx]),
predictions)
# check to see if we arelogging the loss value, and if
# so, display it to our terminal
if step % 5 == 0:
print("step: {},loss: {}...".format(step,
loss.numpy()))
# calculate the gradients ofloss with respect to the
# perturbation vector
gradients = tape.gradient(loss, delta)
# update the weights, clipthe perturbation vector, and
# update its value
optimizer.apply_gradients([(gradients, delta)])
delta.assign_add(clip_eps(delta, eps=EPS))
# return the perturbationvector
return delta
第3行将delta扰动向量加入至baseImage的方式来组建对抗图片,所得到的结果将放入ResNet50的preprocess_input函数中来进行比例缩放和结果对抗图像进行归一化。
接下来几行的意义是:
第7行用model参数导入的模型对新创建的对抗图像进行预测。
第8和9行针对原有的classIdx(通过运行predict_normal.py得到的top-1 ImageNet类别标签整数值索引)计算损失。
第12-14行表示每5步就显示一次损失值。
第17行,在with声明外根据扰动向量计算梯度损失。
接着,可以更新delta向量,截取掉超出 [-EPS,EPS] 范围外的值。
最终,把得到的扰动向量返回至调用函数——即最终的delta值,该值能让我们建立用来欺骗模型的对抗攻击。
在对抗脚本的核心实现后,接下来就是解析命令行参数:
# construct the argumentparser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path tooriginal input image")
ap.add_argument("-o", "--output", required=True,
help="path tooutput adversarial image")
ap.add_argument("-c", "--class-idx", type=int,required=True,
help="ImageNetclass ID of the predicted label")
args = vars(ap.parse_args())
我们的对抗攻击Python脚本需要三个指令行参数:
--input: 输入图像的磁盘路径(例如pig.jpg);
--output: 在构建进攻后的对抗图像输出(例如adversarial.png);
--class-idex:ImageNet数据集中的类别标签整数值索引。我们可以通过执行在“非对抗图像的分类结果”章节中提到的predict_normal.py来获得这一索引。
接下来是几个变量的初始化,以及加载/预处理--input图像:
# define theepsilon and learning rate constants
EPS = 2 / 255.0
LR = 0.1
# load the inputimage from disk and preprocess it
print("[INFO] loadingimage...")
image = cv2.imread(args["input"])
image = preprocess_image(image)
第2行定义了用于在构建对抗图像时来裁剪tensor的epsilon值(EPS)。2 / 255.0 是EPS的一个用于对抗类刊物或教程的标准值和指导值(如果你想要了解更多的默认值,你可以参考这份指导)。
在第3行定义了学习速率。经验之谈,LR的初始值一般设为0.1,在创建你自己的对抗图像时可能需要调整这个值。
最后两行载入输入图像,利用preprocess_image辅助函数来对其进行预处理。
接下来,可以载入ResNet模型:
# load thepre-trained ResNet50 model for running inference
print("[INFO] loadingpre-trained ResNet50 model...")
model = ResNet50(weights="imagenet")
# initializeoptimizer and loss function
optimizer = Adam(learning_rate=LR)
sccLoss = SparseCategoricalCrossentropy()
第3行载入在ImageNet数据集上训练好的ResNet50模型。
我们将会用到Adam优化器,以及稀疏的分类损失用于更新我们的扰动向量。
让我们来构建对抗图像:
# create a tensorbased off the input image and initialize the
# perturbation vector (we will update this vector via training)
baseImage = tf.constant(image,dtype=tf.float32)
delta = tf.Variable(tf.zeros_like(baseImage), trainable=True)
# generate the perturbation vector to create an adversarialexample
print("[INFO]generating perturbation...")
deltaUpdated = generate_adversaries(model, baseImage,delta,
args["class_idx"])
# create theadversarial example, swap color channels, and save the
# output image to disk
print("[INFO]creating adversarial example...")
adverImage = (baseImage +deltaUpdated).numpy().squeeze()
adverImage = np.clip(adverImage, 0, 255).astype("uint8")
adverImage = cv2.cvtColor(adverImage,cv2.COLOR_RGB2BGR)
cv2.imwrite(args["output"], adverImage)
第3行根据输入图像构建了一个tensor,第4行初始化扰动向量delta。
我们可以把ResNet50、输入图像、初始化后的扰动向量、及类标签整数值索引作为参数,用来调用generate_adversaries并更新delta向量。
在 generate_adversaries函数执行时,会一直更新delta扰动向量,生成最终的噪声向量deltaUpdated。
在倒数第4行,在baseImage上加入deltaUpdated 向量,就生成了最终的对抗图像(adverImage)。
然后,对生成的对抗图像进行以下三步后处理:
将超出[0,255] 范围的值裁剪掉;
将图片转化成一个无符号8-bit(unsigned 8-bit)整数(这样OpenCV才能对图片进行处理);
将通道顺序从RGB转换成BGR。
在经过这些处理步骤后,就可以把对抗图像写入到硬盘里了。
真正的问题来了,我们新创建的对抗图像能够欺骗我们的ResNet模型吗?
下一段代码就可以回答这一问题:
# run inferencewith this adversarial example, parse the results,
# and display the top-1 predicted result
print("[INFO]running inference on the adversarial example...")
preprocessedImage = preprocess_input(baseImage +deltaUpdated)
predictions =model.predict(preprocessedImage)
predictions = decode_predictions(predictions, top=3)[0]
label = predictions[0][1]
confidence = predictions[0][2] * 100
print("[INFO] label:{} confidence: {:.2f}%".format(label,
confidence))
# draw the top-most predicted label on the adversarial imagealong
# with theconfidence score
text = "{}: {:.2f}%".format(label, confidence)
cv2.putText(adverImage, text, (3, 20),cv2.FONT_HERSHEY_SIMPLEX, 0.5,
(0, 255, 0), 2)
# show the output image
cv2.imshow("Output", adverImage)
cv2.waitKey(0)
在第4行又一次创建了一个对抗图像,方式还是在原始输入图像中加入delta噪声向量,但这次我们利用ResNet的preprocess_input功能来处理。
生成的预处理图像进入到ResNet,然后会得到top-3预测结果并对他们进行解码(第5和6行)。
接着我们获取到top-1标签和对应的概率/置信度,并将这些值显示在终端上(第7-10行)。
最后一步就是把最高的预测值标在输出的对抗图像上,并展示在屏幕上。
对抗图像和攻击的结果
准备好见证一次对抗攻击了吗?
从这里开始,你就可以打开终端并执行下列代码了:
$ python generate_basic_adversary.py --inputpig.jpg --output adversarial.png --class-idx 341
[INFO] loading image...
[INFO] loading pre-trained ResNet50 model...
[INFO] generatingperturbation...
step: 0, loss:-0.0004124982515349984...
step: 5, loss:-0.0010656398953869939...
step: 10, loss:-0.005332294851541519...
step: 15, loss: -0.06327803432941437...
step: 20, loss: -0.7707189321517944...
step: 25, loss: -3.4659299850463867...
step: 30, loss: -7.515471935272217...
step: 35, loss: -13.503922462463379...
step: 40, loss: -16.118188858032227...
step: 45, loss: -16.118192672729492...
[INFO] creating adversarial example...
[INFO] running inference on theadversarial example...
[INFO] label: wombat confidence: 100.00%
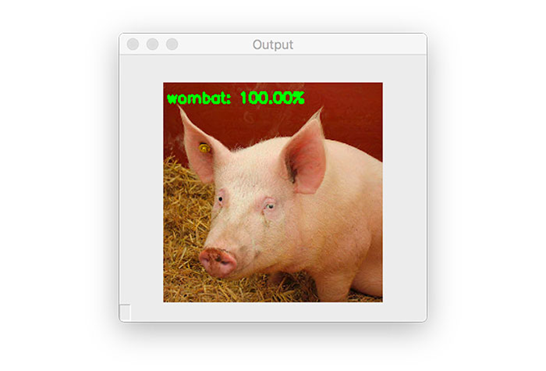
图六:之前,这张输入图片被正确地分在了“猪(hog)”类别中,但现在因为对抗攻击而被分在了“袋熊(wombat)”类别里!
我们的输入图片 pig.jpg 之前被正确地分在了“猪(hog)”类别中,但现在它的标签却成为了“袋熊(wombat)”!
将原始图片和用generate_basic_adversary.py脚本生成的对抗图片放在一起进行对比:
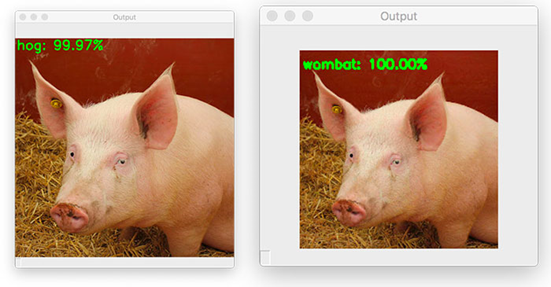
图七:在左边是原始图片,分类结果正确。右边将是对抗图片,被错误地分在了“袋熊(wombat)”类别中。而对于人类的眼睛来看完全分辨不出两张图片的有什么区别。
左边是最初猪的图像,在右边是输出的对抗图像,这张图像被错误的分在了“袋熊(wombat)”类别。
就像你看到的一样,这两张图片没有任何可感知的差别,我们人类的眼睛看不出任何区别,但对于ResNet来说确实完全不同的。
这很好,但我们无法清晰地掌控对抗图像被最终识别的类别标签。这会引起以下问题:
我们有可能掌控输入图片的最终类别标签吗?答案是肯定的,这会成为我下一篇教程的主题。
总结来说,对抗图像和对抗攻击真的是令人细思极恐。但如果等我们看到下一篇教程,就可以提前防御这种类型的进攻。稍后再详细说明下。
致谢
如果没有Goodfellow, Szegedy和其他深度学习的研究者的工作,这篇教程就无法完成。
另外,这篇教程所用到的实现代码灵感来自于TensorFlow官方实现的《Fast Gradient Signed Method》。我强烈建议你去看看其他的示例,每一段代码都比这篇教程中的在理论和数学上更加明确。
总结
在这篇教程中,你学到关于对抗攻击的知识,关于他们是怎样工作的,以及随着人工智能和深度神经网络与这个世界的关联越来越高,对抗攻击就会构成更大的威胁。
接着我们利用深度学习库Keras 和TensorFlow实现了基本的对抗攻击算法。
利用对抗攻击,我们可以蓄意扰乱一张输入图片,例如:
这张输入图片会被错误分类。
然而,肉眼看上去被扰乱的图片还是和之前一样。
利用这篇教程所使用的方法,我们并不能控制图片最终被判别的类别标签——我们所做的只是创造一个噪声向量,并将其嵌入到输入图像中,导致深度神经网络对其错误分类。
如果我们能够控制最终的类别标签会怎样呢?比如说,我们拿一张“狗”的图片,然后制造一次对抗攻击,让卷积神经网络认为这是一张“猫”的图片,这有没有可能呢?
答案是肯定的——我们会在下一篇教程中来谈论这一话题。
原文链接:
https://www.pyimagesearch.com/2020/10/19/adversarial-images-and-attacks-with-keras-and-tensorflow/
原文标题:
Adversarial images andattacks with Keras and TensorFlow
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~