梯度下降是模型优化常用方法,原理也比较简单,简言之就是参数沿负梯度方向更新,参数更新公式如下。
我们将使用pytorch来试验下这个方法。
首先先生成模拟数据。
x1 目标模型表达式,需要优化的参数为
初始化需要优化的参数
w1 损失函数使用平方损失
平方损失的梯度计算比较简单,根据链式法则,容易计算
因此梯度更新函数如下,
def 使用随机梯度下降法,对每一个样本计算梯度,并更新参数
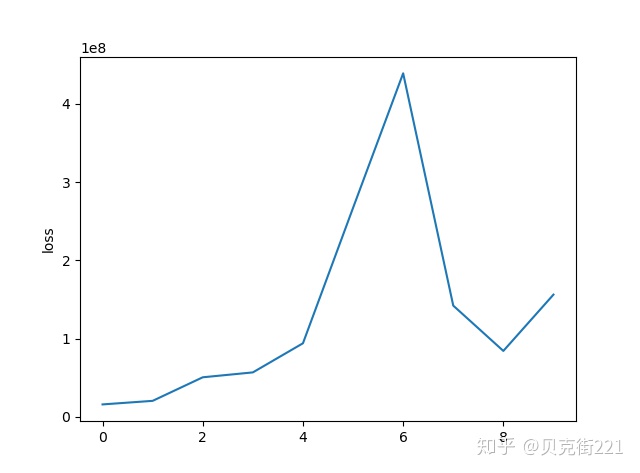
def 初始使用lr = 0.001发现,w1和w2并没有拟合到预期的值。做出的图显示,loss没有拟合的趋势,提示我们选择的学习率过大,导致难以拟合。
调整学习率到0.0001之后,结果拟合的很好,w1和w2的值也和预期一致。
以上就是使用SGD的基本流程,不过上述步骤pytorch都帮我们封装好了,不需要这么麻烦,下面是pytorch的自动求导版本。
首先是几个概念。
optim(优化器)
pytorch已经封装好了很多常用的优化器,可调用step成员函数来对参数进行更新。
常用优化器的包括:SGD, Adam, Adagrad, Rprop。
backward(方向传播)
自动梯度计算,省了很大麻烦!
backward函数会根据Variable的成员变量requires_grad来觉得是否需要对该变量计算梯度。
计算完的梯度保存在成员变量grad中。
注意: backward计算的梯度不会自动清零,而是累加到上一次的梯度中,所以每次更新参数,都需要对梯度清零一次。
有两种方式:
- 调用optim的zero_grad函数
- 手动对变量梯度清零. 例:w1.grad.data.zero_()
以下就是简易版本。
def 下篇文章介绍下常用的优化器~