点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文首发极市平台公众号,转载请获得授权并标明出处。
导读
最近一周,ECCV2022陆续放出了更多和GAN,Transformers相关的论文,为了让大家及时获取和学习到计算机视觉前沿技术,极市对最新一批论文进行整理(新增54篇),包括分研究方向的论文及代码汇总。
ECCV 2022 论文分方向整理目前在极市社区持续更新中,已累计更新了108篇,项目地址:https://github.com/extreme-assistant/ECCV2022-Paper-Code-Interpretation
以下是本周更新的 ECCV 2022 论文,包含图像处理,Transformers,人脸,弱监督学习,模型训练泛化等方向。
点击 阅读原文 即可打包下载。
检测
2D目标检测
[1] Multimodal Object Detection via Probabilistic Ensembling (基于概率集成的多模态目标检测) (Oral)
paper:https://arxiv.org/abs/2104.02904
code:https://github.com/Jamie725/RGBT-detection
3D目标检测
[1] Densely Constrained Depth Estimator for Monocular 3D Object Detection (用于单目 3D 目标检测的密集约束深度估计器)
paper:https://arxiv.org/abs/2207.10047
code:https://github.com/bravegroup/dcd

人物交互检测
[1] Discovering Human-Object Interaction Concepts via Self-Compositional Learning (通过自组合学习发现人-物交互概念)
paper:https://arxiv.org/abs/2203.14272
code:https://github.com/zhihou7/scl; https://github.com/zhihou7/HOI-CL
分割
实例分割
[1] In Defense of Online Models for Video Instance Segmentation (为视频实例分割的在线模型辩护) (Oral)
paper:https://arxiv.org/abs/2207.10661
code:https://github.com/wjf5203/vnext
图像处理
超分辨率
[1] Learning Series-Parallel Lookup Tables for Efficient Image Super-Resolution (学习高效图像超分辨率的串并行查找表)
paper:https://arxiv.org/abs/2207.12987
code:https://github.com/zhjy2016/splut
[2] Efficient Meta-Tuning for Content-aware Neural Video Delivery (内容感知神经视频交付的高效元调整)
paper:https://arxiv.org/abs/2207.09691
code:https://github.com/neural-video-delivery/emt-pytorch-eccv2022
图像复原/图像增强/图像重建
[1] Unsupervised Night Image Enhancement: When Layer Decomposition Meets Light-Effects Suppression (无监督夜间图像增强:当层分解遇到光效抑制时)
paper:https://arxiv.org/abs/2207.10564
code:https://github.com/jinyeying/night-enhancement
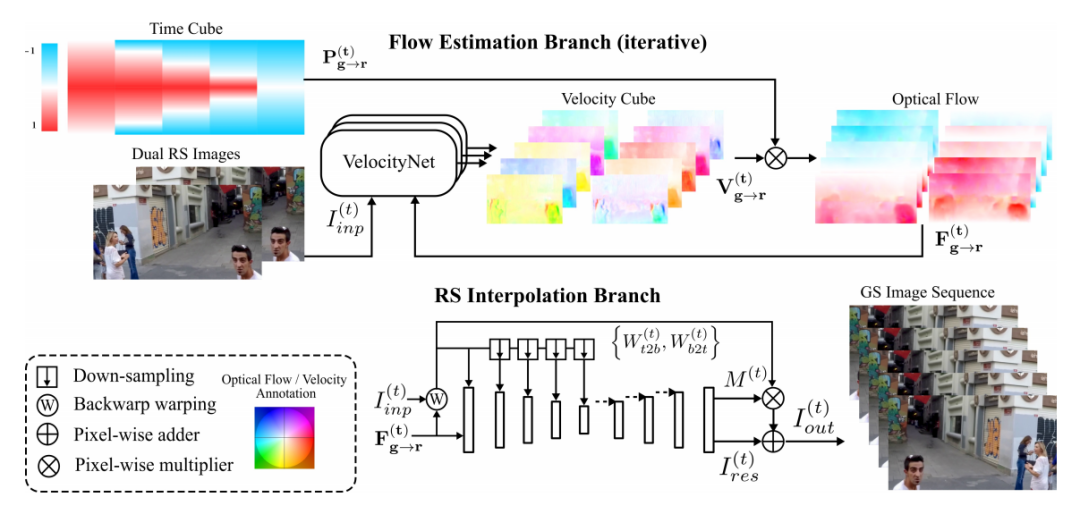
[2] Bringing Rolling Shutter Images Alive with Dual Reversed Distortion(通过双重反转失真使滚动快门图像重现) (Oral)
paper:https://arxiv.org/abs/2203.06451
code:https://github.com/zzh-tech/dual-reversed-rs
[3] Unsupervised Night Image Enhancement: When Layer Decomposition Meets Light-Effects Suppression (无监督夜间图像增强:当层分解遇到光效抑制时)
paper:https://arxiv.org/abs/2207.10564
code:https://github.com/jinyeying/night-enhancement
图像去阴影/去反射
[1] Deep Portrait Delighting (深度人像去光)
paper:https://arxiv.org/abs/2203.12088)

图像去噪
[1] Perceiving and Modeling Density is All You Need for Image Dehazing (感知和建模密度是图像去雾所需的全部) (Oral)
paper:https://arxiv.org/abs/2111.09733
code:https://github.com/Owen718/Perceiving-and-Modeling-Density-is-All-You-Need-for-Image-Dehazing
[2] Animation from Blur: Multi-modal Blur Decomposition with Motion Guidance (来自模糊的动画:具有运动引导的多模态模糊分解)
paper:https://arxiv.org/abs/2207.10123
code:https://github.com/zzh-tech/Animation-from-Blur
视频处理
视频修复
[1] Error Compensation Framework for Flow-Guided Video Inpainting (流引导视频修复的误差补偿框架)
paper:https://arxiv.org/abs/2207.10391

视频去模糊
[1] Event-guided Deblurring of Unknown Exposure Time Videos (未知曝光时间视频的事件引导去模糊) (Oral)
paper:https://arxiv.org/abs/2112.06988
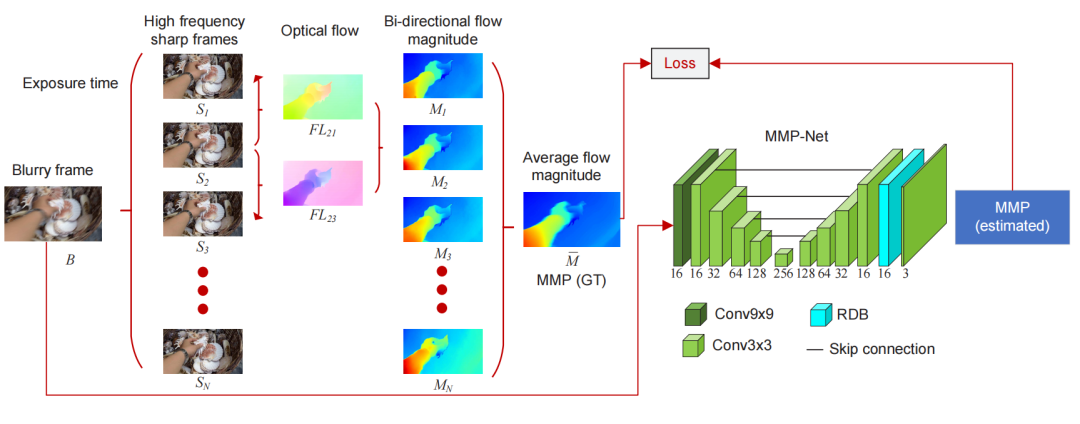
[2] Efficient Video Deblurring Guided by Motion Magnitude (由运动幅度引导的高效视频去模糊)
paper:https://arxiv.org/abs/2207.13374
code:https://github.com/sollynoay/mmp-rnn
图像&视频检索/视频理解
行为识别/行为识别/动作识别/检测/分割
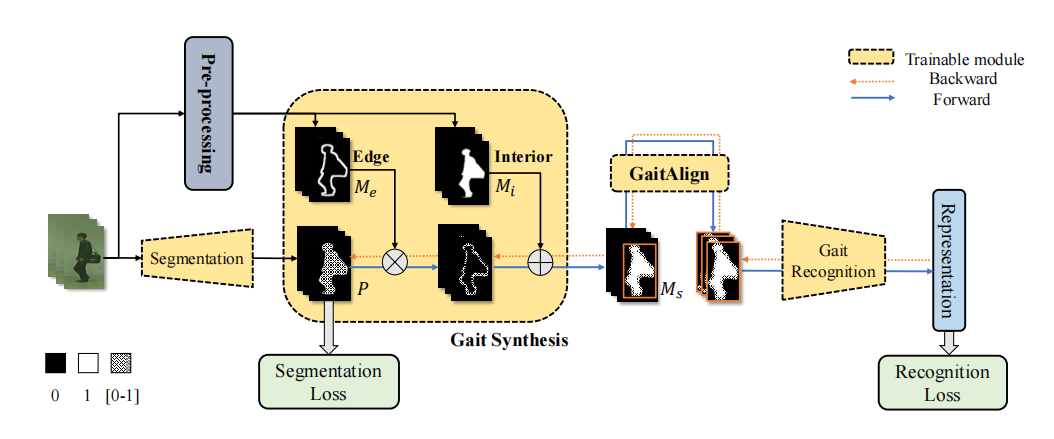
[1] GaitEdge: Beyond Plain End-to-end Gait Recognition for Better Practicality (GaitEdge:超越普通的端到端步态识别,提高实用性)
paper:https://arxiv.org/abs/2203.03972
code:https://github.com/shiqiyu/opengait
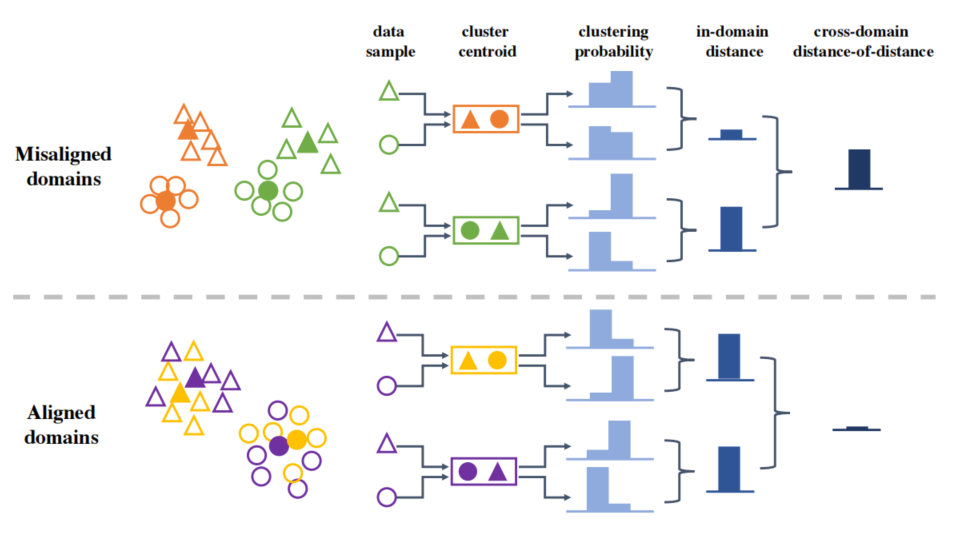
[2] Collaborating Domain-shared and Target-specific Feature Clustering for Cross-domain 3D Action Recognition (用于跨域 3D 动作识别的协作域共享和特定于目标的特征聚类)
paper:https://arxiv.org/abs/2207.09767
code:https://github.com/canbaoburen/CoDT

行人重识别/检测
[1] PASS: Part-Aware Self-Supervised Pre-Training for Person Re-Identification(PASS:用于人员重新识别的部分感知自我监督预训练)
paper:https://arxiv.org/abs/2203.03931
code:https://github.com/casia-iva-lab/pass-reid
图像/视频检索
[1] Feature Representation Learning for Unsupervised Cross-domain Image Retrieval (无监督跨域图像检索的特征表示学习)
paper:https://arxiv.org/abs/2207.09721
code:https://github.com/conghuihu/ucdir
[2] LocVTP: Video-Text Pre-training for Temporal Localization (LocVTP:时间定位的视频文本预训练)
paper:https://arxiv.org/abs/2207.10362
code:https://github.com/mengcaopku/locvtp
估计
视觉定位/位姿估计
[1] 3D Interacting Hand Pose Estimation by Hand De-occlusion and Removal (通过手部去遮挡和移除的 3D 交互手部姿势估计)
paper:https://arxiv.org/abs/2207.11061
code:https://github.com/menghao666/hdr

[2] Weakly Supervised Object Localization via Transformer with Implicit Spatial Calibration (基于隐式空间校准的 Transformer 的弱监督目标定位)
paper:https://arxiv.org/abs/2207.10447
code:https://github.com/164140757/scm
人脸
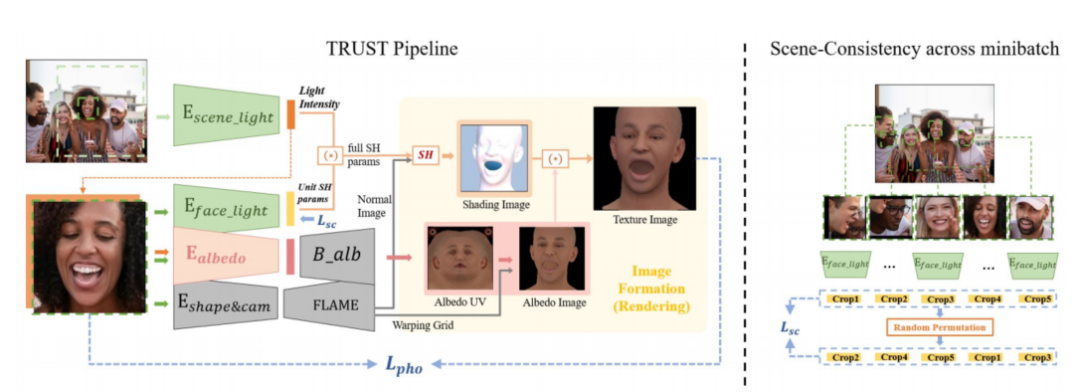
[1] Towards Racially Unbiased Skin Tone Estimation via Scene Disambiguation (通过场景消歧实现种族无偏肤色估计)
paper:https://arxiv.org/abs/2205.03962
code:https://trust.is.tue.mpg.de/
[2] MoFaNeRF: Morphable Facial Neural Radiance Field (MoFaNeRF:可变形面部神经辐射场)
paper:https://arxiv.org/abs/2112.02308
code:https://github.com/zhuhao-nju/mofanerf
三维视觉
三维重建
[1] DiffuStereo: High Quality Human Reconstruction via Diffusion-based Stereo Using Sparse Cameras (DiffuStereo:使用稀疏相机通过基于扩散的立体进行高质量人体重建)
paper:https://arxiv.org/abs/2207.08000
场景重建/视图合成/新视角合成
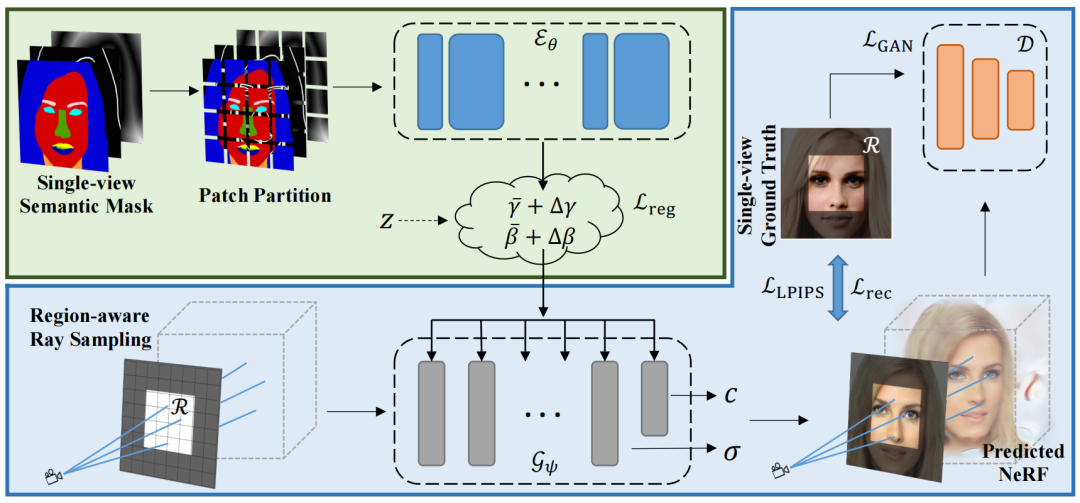
[1] Sem2NeRF: Converting Single-View Semantic Masks to Neural Radiance Fields (Sem2NeRF:将单视图语义掩码转换为神经辐射场)
paper:https://arxiv.org/abs/2203.10821
code:https://github.com/donydchen/sem2nerf
目标跟踪
[1] Tracking Every Thing in the Wild (追踪野外的每一件事)
paper:https://arxiv.org/abs/2207.12978
文本检测/识别/理解
[1] Contextual Text Block Detection towards Scene Text Understanding (面向场景文本理解的上下文文本块检测)
paper:https://arxiv.org/abs/2207.12955

[2] PromptDet: Towards Open-vocabulary Detection using Uncurated Images (PromptDet:使用未经处理的图像进行开放词汇检测)
paper:https://arxiv.org/abs/2203.16513
code:https://github.com/fcjian/PromptDet
[3] End-to-End Video Text Spotting with Transformer (使用 Transformer 的端到端视频文本定位) (Oral)
paper:https://arxiv.org/abs/2203.10539
code:https://github.com/weijiawu/transdetr
GAN/生成式/对抗式
[1] Learning Energy-Based Models With Adversarial Training (通过对抗训练学习基于能量的模型)
paper:https://arxiv.org/abs/2012.06568
code:https://github.com/xuwangyin/AT-EBMs
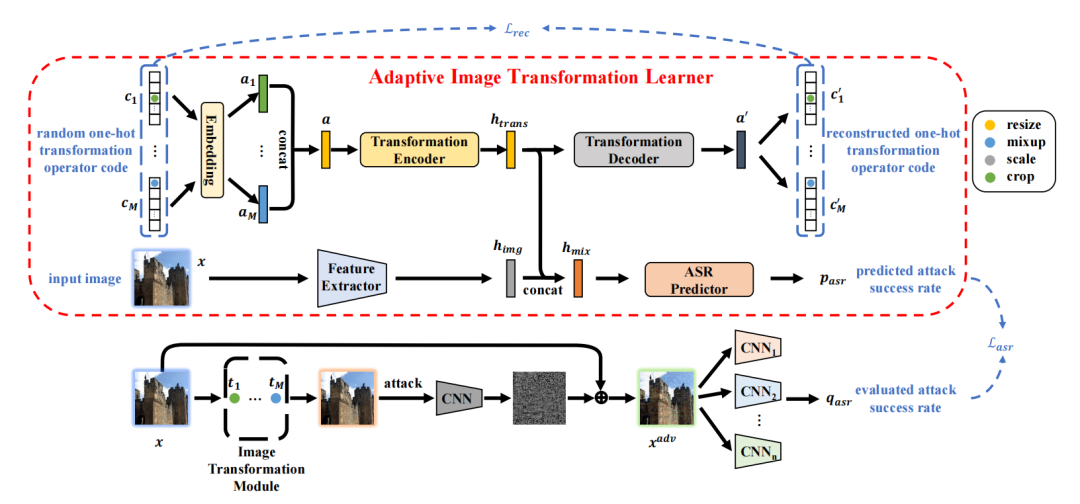
[2] Adaptive Image Transformations for Transfer-based Adversarial Attack (基于传输的对抗性攻击的自适应图像转换)
paper:https://arxiv.org/abs/2111.13844
[3] Generative Multiplane Images: Making a 2D GAN 3D-Aware (生成多平面图像:让一个2D GAN变得3D感知)
paper:https://arxiv.org/abs/2207.10642
code:https://github.com/apple/ml-gmpi
图像生成/图像合成
[1] PixelFolder: An Efficient Progressive Pixel Synthesis Network for Image Generation (PixelFolder:用于图像生成的高效渐进式像素合成网络)
paper:https://arxiv.org/abs/2204.00833
code:https://github.com/blinghe/pixelfolder

视觉预测
[1] D2-TPred: Discontinuous Dependency for Trajectory Prediction under Traffic Lights (D2-TPred:交通灯下轨迹预测的不连续依赖)
paper:https://arxiv.org/abs/2207.10398
code:https://github.com/vtp-tl/d2-tpred
神经网络结构设计
DNN
[1] Hardly Perceptible Trojan Attack against Neural Networks with Bit Flips (使用 Bit Flips 对神经网络进行难以察觉的特洛伊木马攻击)
paper:https://arxiv.org/abs/2207.13417
code:https://github.com/jiawangbai/hpt

Transformer
[1] Improving Vision Transformers by Revisiting High-frequency Components (通过重新审视高频组件来改进视觉变压器)
paper:https://arxiv.org/abs/2204.00993
code:https://github.com/jiawangbai/HAT
[2] Transformer with Implicit Edges for Particle-based Physics Simulation (用于基于粒子的物理模拟的隐式边缘变压器)
paper:https://arxiv.org/abs/2207.10860
code:https://github.com/ftbabi/tie_eccv2022
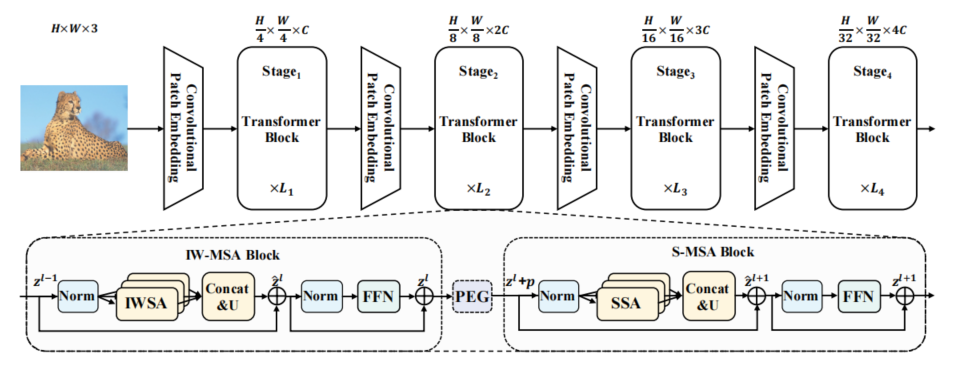
[3] ScalableViT: Rethinking the Context-oriented Generalization of Vision Transformer (ScalableViT:重新思考 Vision Transformer 面向上下文的泛化)
paper:https://arxiv.org/abs/2203.10790
code:https://github.com/yangr116/scalablevit
[4] Visual Prompt Tuning (视觉提示调整)
paper:https://arxiv.org/abs/2203.12119
code:https://github.com/KMnP/vpt

图像特征提取与匹配
[1] Unsupervised Deep Multi-Shape Matching (无监督深度多形状匹配)
paper:https://arxiv.org/abs/2207.09610
视觉表征学习
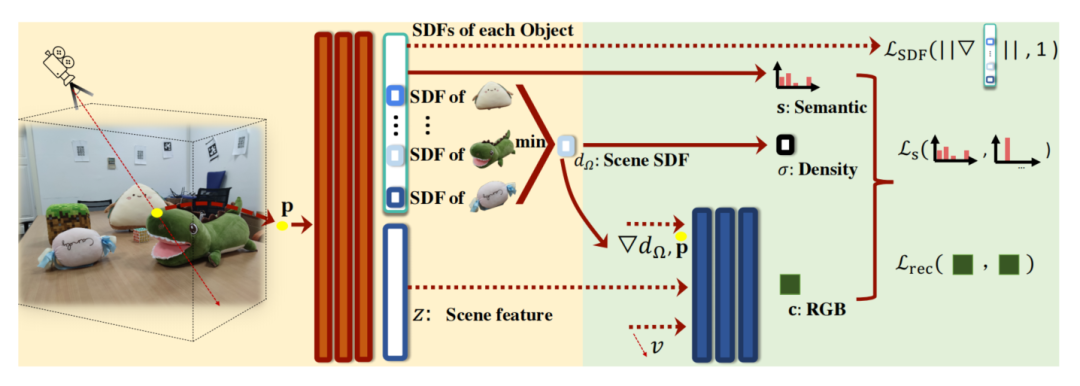
[1] Object-Compositional Neural Implicit Surfaces (对象组合神经隐式曲面)
paper:https://arxiv.org/abs/2207.09686
code:https://github.com/qianyiwu/objsdf
模型训练/泛化
长尾分布
[1] Long-tailed Instance Segmentation using Gumbel Optimized Loss (使用 Gumbel 优化损失的长尾实例分割)
paper:https://arxiv.org/abs/2207.10936
code:https://github.com/kostas1515/gol)
[2] Identifying Hard Noise in Long-Tailed Sample Distribution (识别长尾样本分布中的硬噪声) (Oral)
paper:https://arxiv.org/abs/2207.13378
code:https://github.com/yxymessi/h2e-framework

模型压缩
知识蒸馏
[1] Prune Your Model Before Distill It (在蒸馏之前修剪你的模型)
paper:https://arxiv.org/abs/2109.14960
code:https://github.com/ososos888/prune-then-distill
[2] Efficient One Pass Self-distillation with Zipf's Label Smoothing (使用 Zipf 的标签平滑实现高效的单程自蒸馏)
paper:https://arxiv.org/abs/2207.12980
code:https://github.com/megvii-research/zipfls

半监督学习/弱监督学习/无监督学习/自监督学习
[1] Acknowledging the Unknown for Multi-label Learning with Single Positive Labels (用单个正标签承认未知的多标签学习)
paper:https://arxiv.org/abs/2203.16219
code:https://github.com/correr-zhou/spml-acktheunknown
[2] W2N:Switching From Weak Supervision to Noisy Supervision for Object Detection (W2N:目标检测从弱监督切换到嘈杂监督)
paper:https://arxiv.org/abs/2207.12104
code:https://github.com/1170300714/w2n_wsod
[3] CA-SSL: Class-Agnostic Semi-Supervised Learning for Detection and Segmentation (CA-SSL:用于检测和分割的与类别无关的半监督学习)
paper:https://arxiv.org/abs/2112.04966
code:https://github.com/dvlab-research/Entity

多模态学习/跨模态
视觉-语言
[1] Language Matters: A Weakly Supervised Vision-Language Pre-training Approach for Scene Text Detection and Spotting (语言问题:用于场景文本检测和识别的弱监督视觉语言预训练方法) (Oral)
paper:https://arxiv.org/abs/2203.03911

小样本学习/零样本学习
[1] Worst Case Matters for Few-Shot Recognition (最坏情况对少数镜头识别很重要)
paper:https://arxiv.org/abs/2203.06574
code:https://github.com/heekhero/ACSR
持续学习
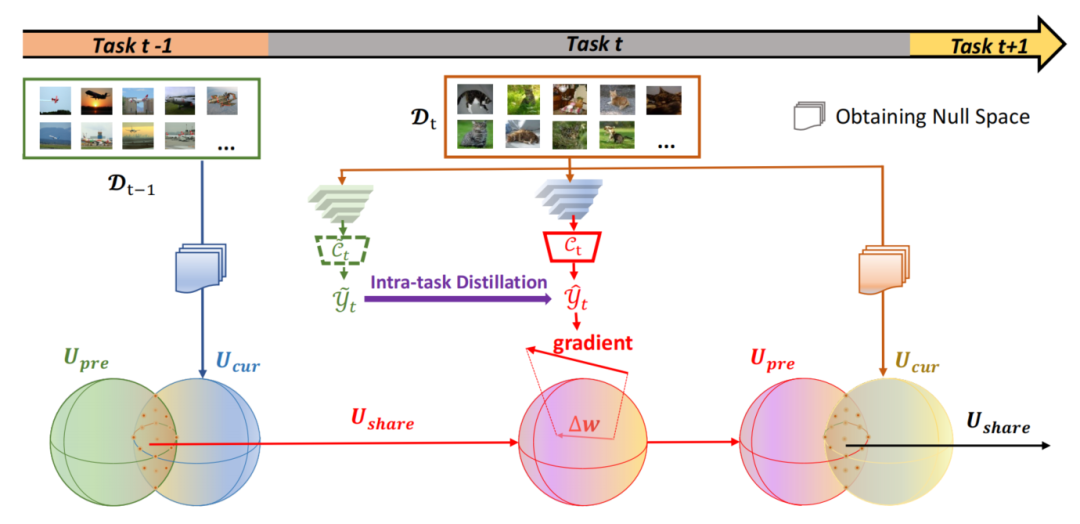
[1] Balancing Stability and Plasticity through Advanced Null Space in Continual Learning (通过持续学习中的高级零空间平衡稳定性和可塑性) (Oral)
paper:https://arxiv.org/abs/2207.12061
[2] Online Continual Learning with Contrastive Vision Transformer (使用对比视觉转换器进行在线持续学习)
paper:https://arxiv.org/abs/2207.13516
模仿学习
[1] Resolving Copycat Problems in Visual Imitation Learning via Residual Action Prediction (通过残差动作预测解决视觉模仿学习中的模仿问题)
paper:https://arxiv.org/abs/2207.09705


点个在看 paper不断!