hive
Hive概述
- Hive是基于Hadoop的一个数据仓库工具。可以将结构化的数据文件映射为一张表,并提供完整的sql查询功能,本质上还是一个文件
- 底层是将sql语句转换为MapReduce任务进行运行
- 本质上是一种大数据离线分析工具
- 学习成本相当低,不用开发复杂的mapreduce应用,十分适合数据仓库的统计分析
- hive可以用来进行 数据提取、转化、加载,这是一种可以存储、查询和分析存储在hadoop上的数据。
数据仓库
-
数据是集成的,数据的来源可能是:MySQL、oracle、网络日志、爬虫数据… 等多种异构数据源。
Hadoop你就可以看成是一个数据仓库,分布式文件系统hdfs就可以存储多种不同的异构数据源 -
数据仓库不仅要存数据,还要管理数据,即:hdfs 和 mapreduce,从这个角度看之前的hadoop其实就是一个数据仓库,hive其实就是在hadoop之外包了一个壳子。
hive是基于hadoop的数据仓库工具,不通过代码操作,通过类sql语言操作数据仓库中的数据。底层其实仍然是分布式文件系统和mapreduce,会把sql命令转为底层的代码 -
数据仓库的特征
- 数据仓库是多个异构数据源集成的
- 数据仓库存储的一般是历史数据,大多数的应用场景是读数据(分析数据)
- 数据库是为捕获数据而设计,而数据仓库是为了分析数据而设计
- 数据仓库是弱事务的,因为数据仓库存的是历史数据,一般都读(分析)数据场景
-
OLTP系统(online transaction processing)
- 数据库属于OLTP系统,联机事务处理,涵盖了企业大部分的日常操作,比如购物、库存、制造、银行、工资、注册、记账等,比如mysql oracle等关系型数据库
- OLTP系统的访问由于要保证原子性,所以有事务机制和恢复机制
-
OLAP系统(online analytical processing)
- 数据仓库属于OLAP系统,联机分析处理系统,hive等
- OLAP系统一般存储的是历史数据,所以大部分都是只读操作,不需要事务
Hive的HQL
- HQL - Hive通过类SQL的语法,来进行分布式的计算
- HQL用起来和SQL非常的类似,Hive在执行的过程中会将HQL转换为MapReduce去执行,所以Hive其实是基于Hadoop的一种分布式计算框架,底层仍然是MapReduce
Hive特点
- Hive优点
- 学习成本低,只要会sql就能用hive
- 开发效率高,不需要编程,只需要写sql
- 模型简单,易于理解
- 针对海量数据的高性能查询和分析
- 与 Hadoop 其他产品完全兼容
- Hive缺点
- 不支持行级别的增删改
- 不支持完整的在线事务处理
Hive适用场景
- Hive 构建在基于静态(离线)批处理的Hadoop 之上,Hadoop通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询因此,Hive并不适合那些需要低延迟的应用
- Hive并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的离线批处理作业,例如,网络日志分析。
Hive安装
下载hive安装包(2.3.7版本)
http://us.mirrors.quenda.co/apache/hive/
[root@vm ~]# tar xf apache-hive-2.3.7-bin.tar.gz -C /usr/local
[root@vm ~]# mv /usr/local/apache-hive-2.3.7-bin /usr/local/hive2.3.7
[root@vm ~]# vim .bashrc
export HIVE_HOME=/usr/local/hive2.3.7
export PATH=.:${HIVE_HOME}/bin:$PATH
[root@vm ~]# source .bashrc
启动mysql,下载并添加连接MySQL数据库的jar包
下载链接: https://downloads.mysql.com/archives/c-j/
[root@vm ~]# docker run -itd --name mysql -e "MYSQL_ROOT_PASSWORD=123456" -p 3306:3306 mysql:5.7.26
[root@vm ~]# mysql -uroot -p123456 -e "show databases;"
[root@vm ~]# cp -p mysql-connector-java-8.0.19.jar /usr/local/hive2.3.7/lib/
# 配置mysql信息,存储hive查询时用的文件相关映射信息
[root@vm ~]# vim /usr/local/hive2.3.7/conf/hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
</configuration>
[root@vm ~]# cd /usr/local/hive2.3.7/conf
[root@vm conf]# cp -p hive-env.sh.template hive-env.sh
[root@vm conf]# vim /usr/local/hive2.3.7/conf/hive-env.sh # 配置
HADOOP_HOME=/usr/local/hadoop2.10
export HIVE_CONF_DIR=/usr/local/hive2.3.7/conf
[root@vm conf]# schematool -dbType mysql -initSchema # 初始化
schemaTool completed
[root@vm conf]# mysql -uroot -p123456 -e "show databases;"|grep hive
hive
[root@vm conf]# hive
hive> show databases;
OK
default
Time taken: 67.226 seconds, Fetched: 1 row(s)
hive> create database test2024;
OK
Time taken: 30.548 seconds
查看
http://192.168.1.11:50070/explorer.html#/user/hive/warehouse/
可以看到 test2024.db 这个库
[root@vm ~]# hadoop fs -ls /user/hive/warehouse/
Found 1 items
drwxr-xr-x - root supergroup 0 2024-03-10 15:26 /user/hive/warehouse/test2024.db
Hive基本操作
文件和表如何映射关系
[root@vm ~]# cat access.log
1,192.168.1.11,Chrome
2,192.168.1.66,Firefox
3,192.168.1.88,IE
[root@vm ~]# hive
hive> use test2024;
hive> create table t1(id int, ip string, browser string);
hive> select * from t1; # 浏览器里能看到/user/hive/warehouse/test2024.db/t1
OK
[root@vm ~]# hadoop fs -put access.log /user/hive/warehouse/test2024.db/t1
# 当hive 删除t1表时,文件也会被删除
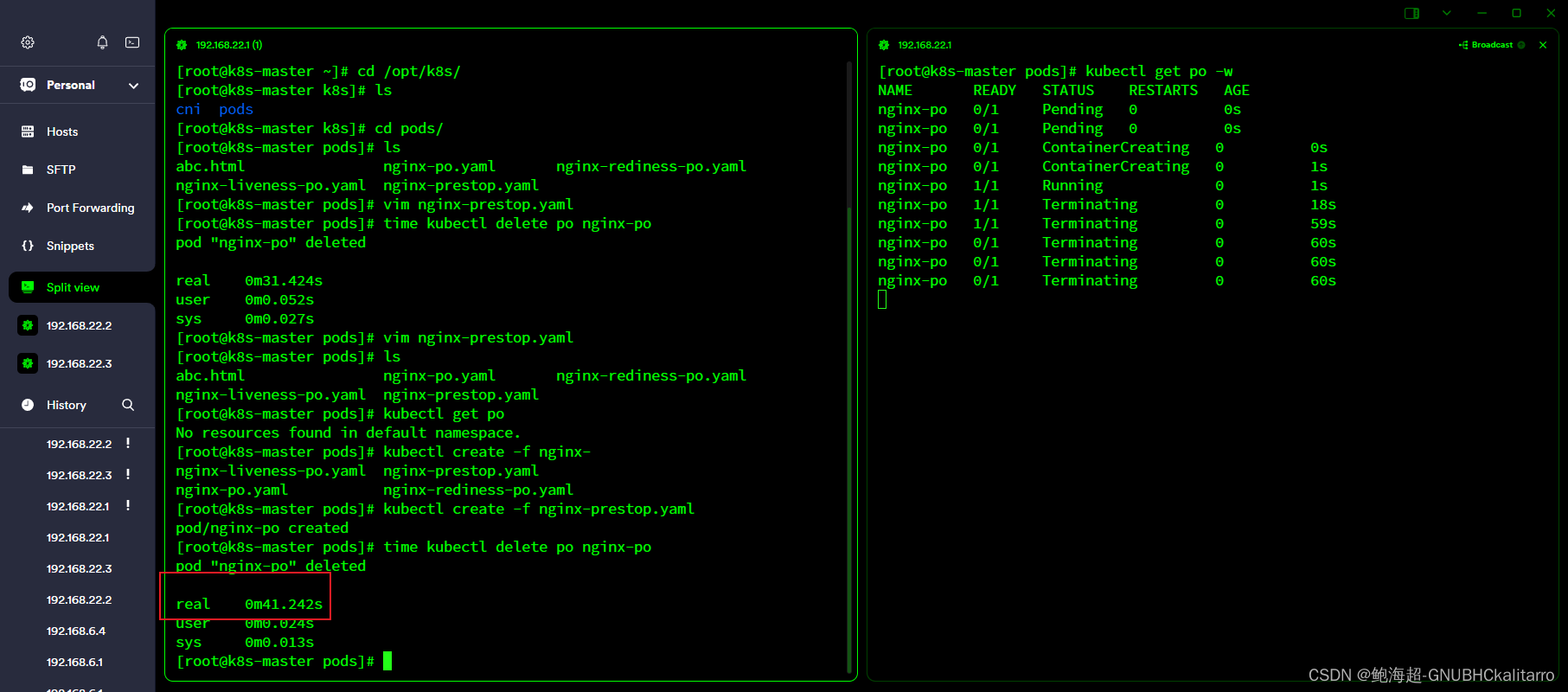
hive> select * from t1;
OK
NULL NULL NULL # 查看到的映射数据,未指定分隔符
NULL NULL NULL
NULL NULL NULL
如何实现文件和表的映射 - 续1
# 指定分隔符
hive> create table t2(id int, ip string, browser string) row format delimited fields terminated by ',';
[root@vm ~]# hadoop fs -put access.log /user/hive/warehouse/test2024.db/t2
hive> select * from t2;
OK
1 192.168.1.11 Chrome
2 192.168.1.66 Firefox
3 192.168.1.88 IE
# 简单的sql不会启用mapreduce,复杂的语句才会启用。
hive> select count(id)from t2 where ip is not null;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = root_20240310160226_b7c42520-ba5b-41e4-a36b-69f98afb7752
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
...
练习
【1】题目:把 /etc/passwd 映射为 stu库中的 t3表 root:x:0:0:root:/root:/bin/bash
cp /etc/passwd /home/tarena/hadoop/
hive> use stu;
hive> create table t3(
username string,
password string,
uid int,
gid int,
comment string,
homedir string,
shell string
)row format delimited fields terminated by ':';
[root@vm ~]# hadoop fs -put /etc/passwd /user/hive/warehouse/test2024.db/t3
hive> select * from t3;
hive基础指令
| 命令 | 作用 | 额外说明 |
|---|---|---|
| show databases; | 查看都有哪些数据库 | |
| create database testdb; | 创建testdb数据库 | 创建的数据库,实际是在Hadoop的HDFS文件系统里创建一个目录节点,统一存在: /user/hive/warehouse 目录下 |
| use testdb; | 进入testdb数据库 | |
| show tables; | 查看当前数据库下所有表 | |
| create table stutab (id int,name string); | 创建stutab表,以及相关的两个字段 | hive里,表示字符串用的是string,不用char和varchar 所创建的表,也是HDFS里的一个目录节点 |
| insert into stutab values(1,‘zhang’); | 向stutab表插入数据 | HDFS不支持数据的修改和删除,因此已经插入的数据不能够再进行任何的改动 在Hadoop2.0版本后支持了数据追加。实际上,insert into 语句执行的是追加操作 hive支持查询,行级别的插入。不支持行级别的删除和修改 hive的操作实际是执行一个job任务,调用的是Hadoop的MR 插入完数据之后,发现HDFS stutab目录节点下多了一个文件,文件里存了插入的数据,因此,hive存储的数据,是通过HDFS的文件来存储的。 |
| select * from stutab | 查看表数据 | 也可以根据字段来查询,比如select id from stutab |
| drop table stutab | 删除表 | hadoop里的对应文件夹及文件也会被删除 |
| select * from stutab | 查询stutab表数据 | |
| load data local inpath ‘/home/tarena/1.txt’ into table stutab; | 加载文件数据到指定的表里 | 在执行完这个指令之后,发现hdfs stu目录下多了一个1.txt文件。由此可见,hive的工作原理实际上就是在管理hdfs上的文件,把文件里数据抽象成二维表结构,然后提供hql语句供程序员查询文件数据 可以做这样的实验:不通过load 指令,而通过插件向stu目录下再上传一个文件,看下hive是否能将数据管理到stu表里。 |
| create table stu1(id int,name string) row format delimited fields terminated by ’ '; | 创建stu1表,并指定分割符 空格。 | |
| desc stu | 查看 stu表结构 | |
| create table stu2 like stu | 创建一张stu2表,表结构和stu表结构相同 | like只复制表结构,不复制数据 |
| insert overwrite table stu2 select * from stu | 把stu表数据插入到stu2表中 | |
| insert overwrite local directory ‘/home/tarena/stu’ row format delimited fields terminated by ’ ’ select * from stu; | 将stu表中查询的数据写到本地的/home/tarena/stu目录下 | |
| insert overwrite directory ‘/stu’ row format delimited fields terminated by ’ ’ select * from stu; | 将stu表中查询的数据写到HDFS的stu目录下 | |
| alter table stu rename to stu2 | 为表stu重命名为stu2 | |
| alter table stu add columns (age int); | 为表stu增加一个列字段age,类型为int | |
| exit | 退出hive |