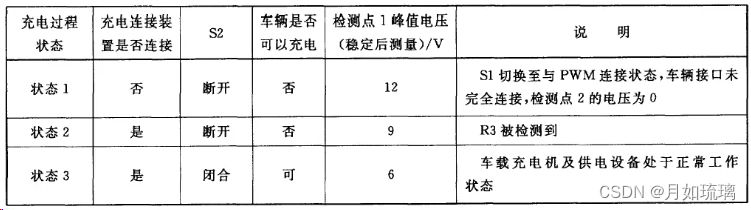
一、并行算法
在STL的算法中,对于大多数程序员的应用,都是普通的单线程的库。同时,很多开发者也都注意到,在STL的库中很多都是非多线程安全的。而且随着硬件和软件技术的不段的发展,许多库面临着在多核和多线程环境下执行的需求。
因此,在c++新的标准库中,特别是从c++17开始,支持了很多的并行算法库,使得其运行效率得到极大的提升,有的相差甚至可以达到量级的水平。
二、STL常用的并行算法
STL常用的并行算法库主要在和两个头文件中,其中具体的实现在头文件中。在使用并行算法库时,需要指定相关的执行策略,即:
详细说明见下面英文说明
std::execution::sequenced_policy
std::execution::parallel_policy
std::execution::parallel_unsequenced_policy
std::execution::unsequenced_policy (c++20)
未来还可能包含“未来额外策略包含 std::parallel::cuda 和 std::parallel::opencl ”。
其意义为:
1、 The execution policy type used as a unique type to disambiguate parallel algorithm overloading and require that a parallel algorithm's execution may not be parallelized. The invocations of element access functions in parallel algorithms invoked with this policy (usually specified as std::execution::seq) are indeterminately sequenced in the calling thread.
2、 The execution policy type used as a unique type to disambiguate parallel algorithm overloading and indicate that a parallel algorithm's execution may be parallelized. The invocations of element access functions in parallel algorithms invoked with this policy (usually specified as std::execution::par) are permitted to execute in either the invoking thread or in a thread implicitly created by the library to support parallel algorithm execution. Any such invocations executing in the same thread are indeterminately sequenced with respect to each other.
3、 The execution policy type used as a unique type to disambiguate parallel algorithm overloading and indicate that a parallel algorithm's execution may be parallelized, vectorized, or migrated across threads (such as by a parent-stealing scheduler). The invocations of element access functions in parallel algorithms invoked with this policy are permitted to execute in an unordered fashion in unspecified threads, and unsequenced with respect to one another within each thread.
4、 The execution policy type used as a unique type to disambiguate parallel algorithm overloading and indicate that a parallel algorithm's execution may be vectorized, e.g., executed on a single thread using instructions that operate on multiple data items.
During the execution of a parallel algorithm with any of these execution policies, if the invocation of an element access function exits via an uncaught exception, std::terminate is called, but the implementations may define additional execution policies that handle exceptions differently.
它们对应的库中的指示方式为:
std::execution::seq
std::execution::par
std::execution::par_unseq
std::execution::unseq
在上面的英文说明中也已经有所体现。
其实可以简单理解为:
1、执行可不并行化,数据调用访问即函数访问在调用线程中非顺序
2、执行可以并行,数据调用函数可以并行线程中进行,同一线程中这种调用彼此无顺序相关
3、执行可并行、向量化并允许线程窃取(迁移),线程间和函数调用间均无顺序
4、执行可向量化,单个线程上允许操作多个指令
也就是说,无顺序的执行是允许穿插进行的。而其它情况均不可以。所以在使用这种策略时,要注意不能进行内存分配和释放及相关锁的操作。否则其自动回归到串行执行。
那么使用并行算法和非并行算法有什么不同呢:
首先,处理元素的函数未捕获异常时并行算法会调用std::terminate(),而非并行算法则不会。但并行算法本身一般来说除了std::bad_alloc异常不会抛出其它异常。但非并行算法可以。
其次,非并行算法可以输入和输出迭代器,而并行算法不可以。
再次,非并行算法可以避免意外的副作用和一些额外的辅助功能,但并行算法就不要想了。
在这些算法库中,支持并行的(有的可能需要简单完善)主要有:
none_of,for_each,for_each_n,find,find_if,find_end,find_first_of,adjacent_find,
count,count_if,mismatch,equal,search,search_n,copy,copy_n,copy_if,move,
swap_ranges,transform,replace,replace_if,replace_copy,replace_copy_if,fill,
fill_n,generate,generate_n,remove,remove_if,remove_copy,remove_copy_if,unique,
unique_copy,reverse,reverse_copy,rotate,rotate_copy,is_partitioned,partition,
stable_partition,partition_copy,sort,stable_sort,partial_sort,partial_sort_copy,
is_sorted,is_sorted_until,nth_element,merge,inplace_merge,includes,set_union,
set_intersection,set_difference,set_symmetric_difference,is_heap,is_heap_until,
min_element,max_element,minmax_element,lexicographical_compare,reduce,
transform_reduce,exclusive_scan,inclusive_scan,transform_exclusive_scan,
transform_inclusive_scan和adjacent_difference
不支持并行的:
accumulate,partial_sum,inner_product,search,copy_backward, move_backward,sample, shuffle,partition_point
,lower_bound, upper_bound(), equal_range,binary_search,is_permutation,next_permutation, prev_permutation,push_heap, pop_heap, make_heap,sort_heap
其中reduce是作为accumulate的并行版本引入的,在并行的算法过程中,也是分类似于交换和结合的操作并行的。这个如果对这些细节有要求,一定要小心,特别是一些浮点类型,看上去可能是允许交换和结合的,但实际在应用中是不可确定的,这才是真正的危险所在。
三、例程
下面看一个例子:
#include <algorithm>
#include <chrono>
#include <cstdint>
#include <iostream>
#include <random>
#include <vector>
//#define PARALLEL
#ifdef PARALLEL
#include <execution>
namespace execution = std::execution;
#else
enum class execution { seq, unseq, par_unseq, par };
#endif
void measure([[maybe_unused]] auto policy, std::vector<std::uint64_t> v)
{
const auto start = std::chrono::steady_clock::now();
#ifdef PARALLEL
std::sort(policy, v.begin(), v.end());
#else
std::sort(v.begin(), v.end());
#endif
const auto finish = std::chrono::steady_clock::now();
std::cout << std::chrono::duration_cast<std::chrono::milliseconds>(finish - start)
<< '\n';
};
int main()
{
std::vector<std::uint64_t> v(1'000'000); //设置一个百万大小的容器
std::mt19937 gen{ std::random_device{}() };//std::random_device是均匀分布整数随机数生成器,创建随机种子
std::ranges::generate(v, gen);//数字填充到容器
measure(execution::seq, v);
measure(execution::unseq, v);
measure(execution::par_unseq, v);
measure(execution::par, v);
}
运行结果是:
// not #define PARALLEL
78ms
72ms
88ms
76ms
//#define PARALLEL
74ms
85ms
27ms
19ms
这个结果在不同的平台和不同的编译环境下运行产生的效果可能有所不同,大家不要计较。
这个例程使用的是std::sort函数,另外还有不少的算法函数可以使用并行算法。比如常见的for_each,count_if等等。可以参见上一节的说明。
四、发展
在未来的发展中,相信STL库会更多的融入和使用并行库,特别是很有可能把一些优秀的并行框架集成到STL中,这个在前面又不是没有先例。如果一个普通的STL的库函数,可以轻松的使用并行框架并且能够达到一个很优秀的效率的话,估计c++的编程难度会降低不少。
但是目前一个并行框架加入到STL都一直在坎坷的推进着,所以要到库函数级别的轻松应用,估计还得需要一大段时间。毕竟c++的标准是以三年一个迭代周期,这个版本没有,下一个版本就得三年后,再加上编译器的支持,一般来说没个四五年搞不定。且看且行吧。
五、总结
最近工程上可能会优化一些代码用到这些并行的库函数,所以提前分析整理一下,到时候儿看用到哪个就用哪个。“不打无准备之仗”这句话非常有道理,与诸君共勉。