上一章我们分析了ConfigurationClassParser,配置类的解析源码分析。在ComponentScans和ComponentScan注解修饰的候选配置类的解析过程中,我们需要深入的了解一下ComponentScanAnnotationParser的parse执行流程,SpringBoot启动类为什么这么写,为什么可以不写ComponentScan注解也不需要配置扫描路径等,这些问题都将在本章中被一一分析出来。
回顾
ConfigurationClassParser的doProcessConfigurationClass方法中,涉及到对@ComponentScan的解析,之前我说过在这里Spring将会接管我们自定义的这些bean的定义信息。具体怎么接管的我们接下来就开始分析。
protected final SourceClass doProcessConfigurationClass(
ConfigurationClass configClass, SourceClass sourceClass, Predicate<String> filter)
throws IOException {
//省略部分代码
// Process any @ComponentScan annotations
// 我们的AopConfig候选配置类就会走到下面这个逻辑
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
// componentScans不为空,第一个条件满足
// sourceClass.getMetadata()不为null;通过Conditional注解来控制bean是否需要注册,控制被@Configuration标注的配置类是否需要被解析 第二个条件false,取反。
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
for (AnnotationAttributes componentScan : componentScans) {
// The config class is annotated with @ComponentScan -> perform the scan immediately
// 使用this.componentScanParser ComponentScanAnnotationParser来解析
// 这里面将会注册我们自己写的一些将被spring接管的类的BeanDefinition信息
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// Check the set of scanned definitions for any further config classes and parse recursively if needed
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
本次源码分析的入口就在上述方法中的this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName())方法。
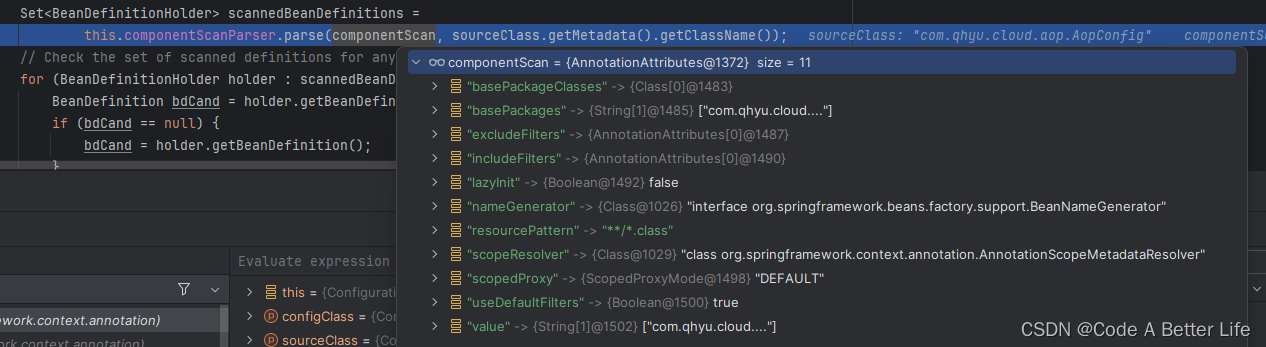
componentScan:第一个参数是注解的描述信息
sourceClass.getMetadata().getClassName():第二个参数候选配置类的名称
@ComponentScan
下面是该注解的所有属性,我们一般只是使用到value,或者Springboot写久了,这个注解都没再看过了。
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@Repeatable(ComponentScans.class)
public @interface ComponentScan {
@AliasFor("basePackages")
String[] value() default {};
@AliasFor("value")
String[] basePackages() default {};
Class<?>[] basePackageClasses() default {};
Class<? extends BeanNameGenerator> nameGenerator() default BeanNameGenerator.class;
Class<? extends ScopeMetadataResolver> scopeResolver() default AnnotationScopeMetadataResolver.class;
ScopedProxyMode scopedProxy() default ScopedProxyMode.DEFAULT;
String resourcePattern() default ClassPathScanningCandidateComponentProvider.DEFAULT_RESOURCE_PATTERN;
boolean useDefaultFilters() default true;
Filter[] includeFilters() default {};
Filter[] excludeFilters() default {};
boolean lazyInit() default false;
@Retention(RetentionPolicy.RUNTIME)
@Target({})
@interface Filter {
FilterType type() default FilterType.ANNOTATION;
@AliasFor("classes")
Class<?>[] value() default {};
@AliasFor("value")
Class<?>[] classes() default {};
String[] pattern() default {};
}
}
-
以下是该注解中定义的各个属性的含义:
value()和basePackages():- 用于指定要扫描的基础包路径,以查找组件类。可以使用这两个属性中的任何一个,它们是互为别名的。
- 默认为空数组,表示不指定基础包路径。
basePackageClasses():- 用于指定一组类,从这些类所在的包路径开始扫描组件。
- 默认为空数组。
nameGenerator():- 指定用于生成Bean名称的类,通常是一个
BeanNameGenerator接口的实现类。 - 默认值为
BeanNameGenerator.class,表示使用Spring默认的Bean名称生成器。
- 指定用于生成Bean名称的类,通常是一个
scopeResolver():- 指定用于解析组件的作用域范围的类,通常是一个
ScopeMetadataResolver接口的实现类。 - 默认值为
AnnotationScopeMetadataResolver.class,表示使用Spring默认的作用域解析器。
- 指定用于解析组件的作用域范围的类,通常是一个
scopedProxy():- 指定Scoped Proxy的模式。可以使用枚举值
ScopedProxyMode中的选项。 - 默认值为
ScopedProxyMode.DEFAULT,表示使用默认的Scoped Proxy模式。
- 指定Scoped Proxy的模式。可以使用枚举值
resourcePattern():- 用于指定用于扫描组件的资源模式。默认是
ClassPathScanningCandidateComponentProvider.DEFAULT_RESOURCE_PATTERN,通常用于指示扫描类路径下的所有类文件。
- 用于指定用于扫描组件的资源模式。默认是
useDefaultFilters():- 一个布尔值,用于确定是否使用默认的过滤器。如果设置为
true,则会应用默认的包含过滤器,通常用于扫描带有特定注解的类。 - 默认值为
true。
- 一个布尔值,用于确定是否使用默认的过滤器。如果设置为
includeFilters():- 一个数组,用于指定自定义的包含过滤器。这些过滤器可以根据需要自定义以确定要包含的类。
- 默认为空数组。
excludeFilters():- 一个数组,用于指定自定义的排除过滤器。这些过滤器可以根据需要自定义以确定要排除的类。
- 默认为空数组。
lazyInit():- 一个布尔值,用于确定是否懒加载扫描到的组件类。
- 默认值为
false,表示不懒加载。
此外,
@ComponentScan注解还支持@Repeatable(ComponentScans.class),允许多次使用该注解,以指定多个组件扫描配置。总之,
@ComponentScan注解用于配置Spring组件扫描的各种属性,以便在应用程序中自动发现和注册组件类。不同的属性允许您以不同的方式自定义扫描的行为。
ComponentScanAnnotationParse
从这个类名就能猜到是处理ComponentScan注解的。进入到parse方法进行源码解析
public Set<BeanDefinitionHolder> parse(AnnotationAttributes componentScan, String declaringClass) {
// 创建ClassPathBeanDefinitionScanner对象,通过componentScan参数中的属性构建了一个对象
// useDefaultFilters default true
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry,
componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader);
// 设置Bean名称生成器
// 从componentScan属性中获取Bean名称生成器的类,并根据需要创建实例。
// 如果没有指定Bean名称生成器,将使用默认的Bean名称生成器
Class<? extends BeanNameGenerator> generatorClass = componentScan.getClass("nameGenerator");
boolean useInheritedGenerator = (BeanNameGenerator.class == generatorClass);
// 这里利用反射可以生成出来你自定义的,AnnotationBeanNameGenerator,用于生成bean名称的
scanner.setBeanNameGenerator(useInheritedGenerator ? this.beanNameGenerator :
BeanUtils.instantiateClass(generatorClass));
// 设置Scoped proxy模式
// 从属性中获取Scoped proxy模式,将其设置未扫描器的Scoped proxy模式
ScopedProxyMode scopedProxyMode = componentScan.getEnum("scopedProxy");
if (scopedProxyMode != ScopedProxyMode.DEFAULT) {
scanner.setScopedProxyMode(scopedProxyMode);
}
else {
// AnnotationScopeMetadataResolver
Class<? extends ScopeMetadataResolver> resolverClass = componentScan.getClass("scopeResolver");
scanner.setScopeMetadataResolver(BeanUtils.instantiateClass(resolverClass));
}
// 设置资源模式,从属性中获取资源模式,并将其设置为扫描器的资源模式
// **/**.class
scanner.setResourcePattern(componentScan.getString("resourcePattern"));
// 添加包含过滤器和排除过滤器:
// 遍历componentScan属性中的包含过滤器和排除过滤器,并将它们添加到扫描器中。
// 这些过滤器用于确定哪些类会被扫描并注册为Bean定义,哪些类会被排除。
// 这里默认就是没有
for (AnnotationAttributes includeFilterAttributes : componentScan.getAnnotationArray("includeFilters")) {
List<TypeFilter> typeFilters = TypeFilterUtils.createTypeFiltersFor(includeFilterAttributes, this.environment,
this.resourceLoader, this.registry);
for (TypeFilter typeFilter : typeFilters) {
scanner.addIncludeFilter(typeFilter);
}
}
// 默认没有
for (AnnotationAttributes excludeFilterAttributes : componentScan.getAnnotationArray("excludeFilters")) {
List<TypeFilter> typeFilters = TypeFilterUtils.createTypeFiltersFor(excludeFilterAttributes, this.environment,
this.resourceLoader, this.registry);
for (TypeFilter typeFilter : typeFilters) {
scanner.addExcludeFilter(typeFilter);
}
}
// 设置Lazy Initialization(懒加载):
// 从componentScan属性中获取懒加载的配置,并根据需要将其设置为Bean定义的默认值。
boolean lazyInit = componentScan.getBoolean("lazyInit");
if (lazyInit) {
scanner.getBeanDefinitionDefaults().setLazyInit(true);
}
// 解析基础包路径:
//从componentScan属性中获取基础包路径的配置。
//如果未指定基础包路径,将使用declaringClass的包路径作为默认值。
Set<String> basePackages = new LinkedHashSet<>();
String[] basePackagesArray = componentScan.getStringArray("basePackages");
for (String pkg : basePackagesArray) {
String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg),
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
Collections.addAll(basePackages, tokenized);
}
for (Class<?> clazz : componentScan.getClassArray("basePackageClasses")) {
basePackages.add(ClassUtils.getPackageName(clazz));
}
// 如果没有写,将使用declaringClass,也就是AopConfig这个类的路径。这也是spring里面不写basePackages的原因,直接约定大于配置。
if (basePackages.isEmpty()) {
basePackages.add(ClassUtils.getPackageName(declaringClass));
}
// 添加排除过滤器:
//添加一个排除过滤器,该过滤器用于排除与declaringClass相同的类,以避免将其注册为Bean定义。
scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {
@Override
protected boolean matchClassName(String className) {
return declaringClass.equals(className);
}
});
// 实际做事的地方就是去doScan
// 最终,调用scanner.doScan方法来扫描指定的基础包路径,并返回扫描结果作为Set<BeanDefinitionHolder>。
return scanner.doScan(StringUtils.toStringArray(basePackages));
}
@ComponentScan(value = {“com.qhyu.cloud.**”},这个是我的AopConfig类的注解信息,此类只写了一个注解用于启动扫描。
ClassPathBeanDefinitionScanner
首先创建了一个ClassPathBeanDefinitionScanner对象,通过componentScan参数中的属性构建了一个ClassPathBeanDefinitionScanner对象。这个扫描器用于扫描类路径中的Bean定义,并将它们注册到Spring的Bean注册表中。为了后续的观察方便我在ClassPathBeanDefinitionScanner的doScan方法中加入两个打印。
@ComponentScan中的所有属性都是为这个Bean定义信息扫描器做准备。
这个方法本章不做分析,将在下一章进行详细分析。
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
AtomicInteger index = new AtomicInteger();
for (String basePackage : basePackages) {
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
// 在这里就把我们需要spring管理的类组装BeanDefinition,放到了(BeanDefinitionRegistry)BeanFactory中
System.out.println("当前加载的beanName:"+beanName);
index.addAndGet(1);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
System.out.println("当前加载的所有beanName的个数为:"+ index);
return beanDefinitions;
}
useDefaultFilters
useDefaultFilters是个布尔类型,默认是true,这边先直接进行默认启动,打印出我们自定义的beanName。
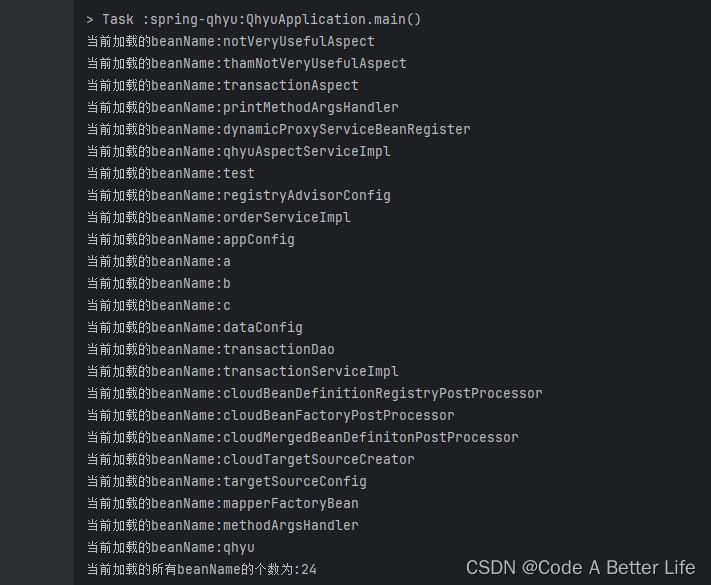
然后我开始修改useDefaultFilters的值为false。我们自定义的bean就不会被加载了。
@ComponentScan(value = {“com.qhyu.cloud.**”},useDefaultFilters = false)

进入ClassPathBeanDefinitionScanner类的构造函数,发现如果useDefaultFilters为true的时候会注册默认的过滤器。registerDefaultFilters(),源码如下
/**
* Register the default filter for {@link Component @Component}.
* <p>This will implicitly register all annotations that have the
* {@link Component @Component} meta-annotation including the
* {@link Repository @Repository}, {@link Service @Service}, and
* {@link Controller @Controller} stereotype annotations.
* <p>Also supports Java EE 6's {@link javax.annotation.ManagedBean} and
* JSR-330's {@link javax.inject.Named} annotations, if available.
*
*/
protected void registerDefaultFilters() {
// 包含过滤器,Component注解
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();
// @ManagedBean
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.annotation.ManagedBean", cl)), false));
logger.trace("JSR-250 'javax.annotation.ManagedBean' found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-250 1.1 API (as included in Java EE 6) not available - simply skip.
}
// @Named
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.inject.Named", cl)), false));
logger.trace("JSR-330 'javax.inject.Named' annotation found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}
从源码中可以得值,次方法在includeFilters中加了至少一个Component的注解类型过滤器,如果有的话还会添加javax.annotation.ManagedBean和javax.inject.Named注解类型的解析器。
从注释中可以得知,包含过滤器中加入了@Component之后其实隐士的加入了@Repository、@Service、 @Controller,因为这些注解中都包含了@Component。
至于这个包含过滤器在哪里使用,就是在ClassPathBeanDefinitionScanner的doScan方法中的findCandidateComponents(basePackage)中。将在下一章节进行详细分析。
nameGenerator
从componentScan属性中获取Bean名称生成器的类,并根据需要创建实例,如果没有指定Bean名称生成器,将使用默认的Bean名称生成器。这里好像没啥好说的,就是一个名称生成器,使用的是AnnotationBeanNameGenerator。
Class<? extends BeanNameGenerator> generatorClass = componentScan.getClass("nameGenerator");
boolean useInheritedGenerator = (BeanNameGenerator.class == generatorClass);
// 这里利用反射可以生成出来你自定义的,AnnotationBeanNameGenerator,用于生成bean名称的
scanner.setBeanNameGenerator(useInheritedGenerator ? this.beanNameGenerator :
BeanUtils.instantiateClass(generatorClass));
scopedProxy和scopeResolver
设置Scoped proxy模式,从属性中获取Scoped proxy模式,将其设置为扫描器的Scoped proxy模式。在不自定义的情况下,使用的是AnnotationScopeMetadataResolver。
ScopedProxyMode scopedProxyMode = componentScan.getEnum("scopedProxy");
if (scopedProxyMode != ScopedProxyMode.DEFAULT) {
scanner.setScopedProxyMode(scopedProxyMode);
}
else {
// AnnotationScopeMetadataResolver
Class<? extends ScopeMetadataResolver> resolverClass = componentScan.getClass("scopeResolver");
scanner.setScopeMetadataResolver(BeanUtils.instantiateClass(resolverClass));
}
resourcePattern
设置资源模式,从属性中获取资源模式,并将其设置为扫描器的资源模式。默认是**/**.class,通常用于指示扫描类路径下的所有类文件。
scanner.setResourcePattern(componentScan.getString("resourcePattern"));
includeFilters和excludeFilters
默认的时候这两个都为空,但是excludeFilters一定会有一个,在后面手动加上的。这些过滤器主要用于确定哪些类会被扫描并注册为bean定义,哪些类会被排除掉。而后面手动添加了一个排除过滤器用于排除与declaringClass相同的类,以避免将其注册为Bean定义。一般情况下我们都不去新增这些内容,除非你有自定义的一些注解也需要被扫描起来获取一些类需要被排除的时候可以尝试这么做。
// 这里默认就是没有
for (AnnotationAttributes includeFilterAttributes : componentScan.getAnnotationArray("includeFilters")) {
List<TypeFilter> typeFilters = TypeFilterUtils.createTypeFiltersFor(includeFilterAttributes, this.environment,
this.resourceLoader, this.registry);
for (TypeFilter typeFilter : typeFilters) {
scanner.addIncludeFilter(typeFilter);
}
}
// 默认没有
for (AnnotationAttributes excludeFilterAttributes : componentScan.getAnnotationArray("excludeFilters")) {
List<TypeFilter> typeFilters = TypeFilterUtils.createTypeFiltersFor(excludeFilterAttributes, this.environment,
this.resourceLoader, this.registry);
for (TypeFilter typeFilter : typeFilters) {
scanner.addExcludeFilter(typeFilter);
}
}
scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {
@Override
protected boolean matchClassName(String className) {
return declaringClass.equals(className);
}
});
lazyInit
设置Lazy Initialization(懒加载),从componentScan属性中获取懒加载的配置,并根据需要将其设置为Bean定义的默认值。
boolean lazyInit = componentScan.getBoolean("lazyInit");
if (lazyInit) {
scanner.getBeanDefinitionDefaults().setLazyInit(true);
}
basePackages和basePackageClasses
这段逻辑的主要目的是解析基础包路径,用于配置组件扫描。让我详细解释这段逻辑的步骤:
- 首先,创建一个空的
LinkedHashSet集合basePackages,用于存储基础包路径。 - 获取
componentScan注解中的basePackages属性的值,该值是一个字符串数组,可能包含一个或多个基础包路径。 - 对
basePackagesArray中的每个包路径进行处理:- 使用
environment.resolvePlaceholders(pkg)方法,将包路径中的占位符解析为实际的值。这是为了支持在配置中使用占位符来动态设置基础包路径。 - 使用
StringUtils.tokenizeToStringArray方法,将解析后的包路径字符串按照ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS分隔符进行拆分,得到一个字符串数组tokenized。 - 最后,使用
Collections.addAll方法将tokenized中的每个拆分后的包路径添加到basePackages集合中。
- 使用
- 接下来,处理
componentScan注解中的basePackageClasses属性,该属性是一个类数组,用于指定基础包路径。这通常用于从特定的类所在的包开始扫描组件。- 对于每个类
clazz,使用ClassUtils.getPackageName(clazz)方法获取其所在包的包名,并将包名添加到basePackages集合中。
- 对于每个类
- 最后,如果
basePackages集合为空,表示没有明确指定要扫描的基础包路径,那么将使用declaringClass参数所表示的类的包路径作为默认基础包路径。- 这是一种常见的约定大于配置的方式,在Spring中,如果不显式指定基础包路径,通常会默认使用配置类(
declaringClass)所在的包路径作为基础包路径。
- 这是一种常见的约定大于配置的方式,在Spring中,如果不显式指定基础包路径,通常会默认使用配置类(
Set<String> basePackages = new LinkedHashSet<>();
String[] basePackagesArray = componentScan.getStringArray("basePackages");
for (String pkg : basePackagesArray) {
String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg),
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
Collections.addAll(basePackages, tokenized);
}
for (Class<?> clazz : componentScan.getClassArray("basePackageClasses")) {
basePackages.add(ClassUtils.getPackageName(clazz));
}
// 如果没有写,将使用declaringClass,也就是AopConfig这个类的路径。这也是spring里面不写basePackages的原因,直接约定大于配置。
if (basePackages.isEmpty()) {
basePackages.add(ClassUtils.getPackageName(declaringClass));
}
总结
本章主要对ComponentScanAnnotationParser的parse方法的整体流程进行了分析,这个类是对@ComponentScan注解进行解析,并且将这些属性值设置到扫描器中,主要的使用还是在解析器,也就是ClassPathBeanDefinitionScanner的doScan方法,下一章节将进行详细分析。