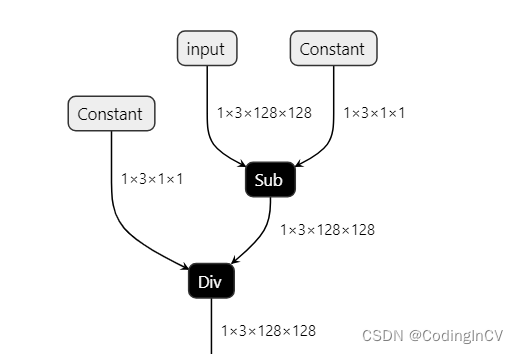
训练模型时,一般都会对原始数据进行归一化再送入网络,即减均值和除方差。在部署时,我们也要进行同样的操作。有些推理框架会提供对应的接口,我们只需要设置均值和方差即可,如MNN.也有一些框架不提供这样的功能,如Tensorrt,这时,我们就需要自己去逐像素进行这个操作,不仅繁琐,还可能比较耗时。还有一种方式是将这个操作放到模型中,一个方法是在我们的原始pytorch模型中增加一个固定参数的Batchnorm层,另一种方式就是本文要讲的在导出的onnx模型中插入Sub和Div节点来完成。
插入节点
主要步骤:
1.创建2个常量节点,分别是均值和方差向量
2.分别插入一个Sub和Div节点,Sub节点输入是模型的输入和均值节点,Div节点输入是Sub节点输出和方差向量
3.将输入层后的第一层的输入修改为Div节点的输出。
代码如下:
import onnx
from onnx import numpy_helper
import numpy as np
# 加载ONNX模型
model_path = "xx.onnx"
model = onnx.load(model_path)
# 创建均值和方差张量
mean_value = [0.485*255, 0.456*255, 0.406*255]
variance_value = [0.229*255, 0.224*255, 0.225*255]
mean_tensor = numpy_helper.from_array(np.array(mean_value, dtype=np.float32).reshape(1,3,1,1), "mean")
variance_tensor = numpy_helper.from_array(np.array(variance_value, dtype=np.float32).reshape(1,3,1,1), "variance")
# 插入均值和方差节点
mean_node = onnx.helper.make_node("Constant", [], ["mean"], value=mean_tensor)
variance_node = onnx.helper.make_node("Constant", [], ["variance"], value=variance_tensor)
model.graph.node.insert(0, mean_node)
model.graph.node.insert(1, variance_node)
# 插入归一化节点
input_name = model.graph.input[0].name
normalize_node = onnx.helper.make_node("Sub", [input_name, "mean"], ["sub_output"])
scale_node = onnx.helper.make_node("Div", ["sub_output", "variance"], ["input_norm"])
# 插入节点到模型中
model.graph.node.insert(2, normalize_node)
model.graph.node.insert(3, scale_node)
# 更新模型
model.graph.node[4].input[0] = "input_norm"
# 保存修改后的ONNX模型
modified_model_path = "xx_norm.onnx"
# shape inference
model = onnx.shape_inference.infer_shapes(model)
# check model
onnx.checker.check_model(model)
onnx.save(model, modified_model_path)
验证模型结果
比对修改前和修改后的模型输出
import onnxruntime as ort
import numpy as np
# 加载原始模型
origin_ort = ort.InferenceSession(model_path, providers=["CPUExecutionProvider"])
origin_input_name = origin_ort.get_inputs()[0].name
origin_output_name = origin_ort.get_outputs()[0].name
input = np.random.randn(1, 3, 128, 128).astype(np.float32)
input_norm = (input - np.array(mean_value,np.float32).reshape(1, 3, 1, 1)) / np.array(variance_value,np.float32).reshape(1, 3, 1, 1)
origin_output = origin_ort.run([origin_output_name], {origin_input_name: input_norm})[0]
# 加载修改后的模型
modified_ort = ort.InferenceSession(modified_model_path, providers=["CPUExecutionProvider"])
modified_input_name = modified_ort.get_inputs()[0].name
modified_output_name = modified_ort.get_outputs()[0].name
modified_output = modified_ort.run([modified_output_name], {modified_input_name: input})[0]
# 比较两个模型的输出
print(np.allclose(origin_output, modified_output, atol=1e-3))
输出为True证明添加节点后的模型正确,后续使用使,不再需要在外部进行均值和方差操作。