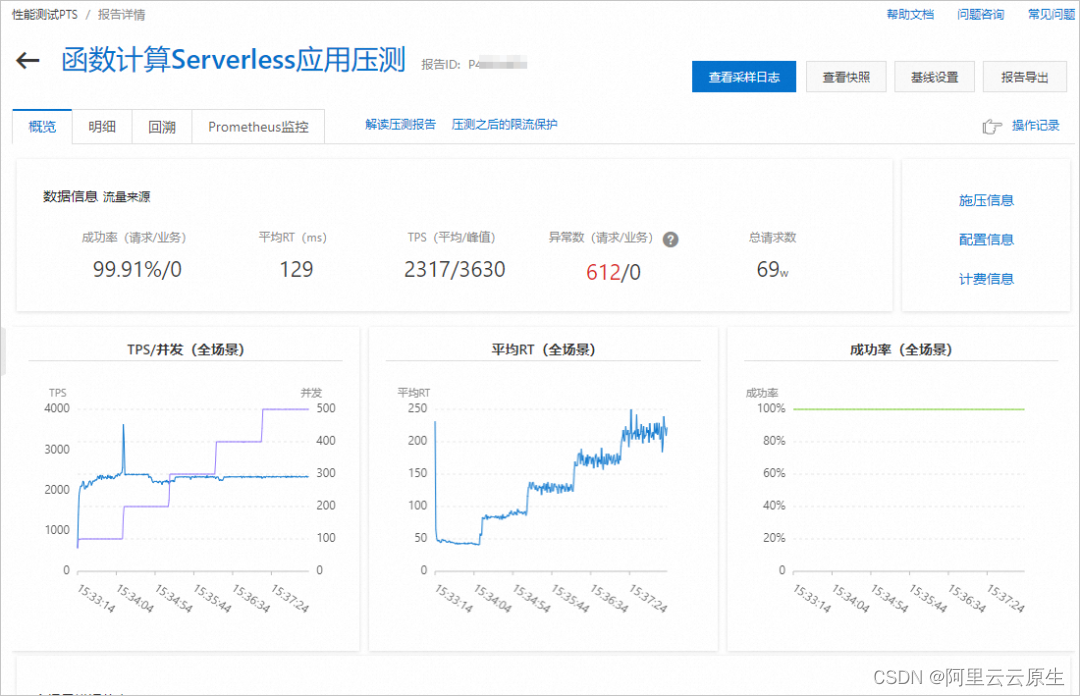
什么是索引?
索引是一种用于快速查询和检索数据的数据结构,常见的索引结构有:B树,B+树和Hash。
索引的作用就相当于目录。打个比方,我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢,如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
mysql 有哪些索引?
可以按照四个角度来分类索引。
-
按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
-
按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
-
按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
-
按「字段个数」分类:单列索引、联合索引。
索引的优缺点分析
优点:
可以大大加快数据的检索速度,大大减少检索的数据量,这也是创建索引的主要原因,毕竟大部分系统的读请求总是大于写请求的。另外,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
缺点:
- 创建索引和维护索引需要耗费许多时间:当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低SQL的执行效率
- 占用物理存储空间:索引需要使用物理文件存储,也会耗费一定空间
B树和B+树区别:
- B树的所有节点既存放键(Key),也存放数据(data);而B+树只有叶子节点存放key和data,其他节点内只存放key。
- B树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
- B树检索的过程相当于对范围内每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而B+树的检索效率就很稳定,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
hash索引优缺点
优点:
定位快:hash索引指的就是hash表,最大的优点就是能够在很短的时间内,根据hash函数定位到数据所在位置。
缺点:
- 存在hash冲突问题
- hash索引不支持顺序和范围查询。比如我们想查询 id<500 的所有用户,因为hash索引是根据hash算法来定位的,这样每次都需要一次hash计算,这就是hash最大的缺点。而如果使用B+树,我们只需要遍历比500小的叶子节点就够了
为什么索引数据结构不用hash?
虽然哈希可以在O1 时间复杂度查询到数据,但是哈希表的元素都是无须存放的,没办法进行范围查询。
mysql为什么使用b+树索引?
B+Tree 是一种多叉树,叶子节点才存放数据,非叶子节点只存放索引,每个节点里的数据是按主键顺序存放的。在叶子节点中,包括了所有的索引值信息,并且每一个叶子节点都指向下一个叶子节点,形成一个链表。B+Tree 存储千万级的数据只需要 3-4 层高度就可以满足,千万级的表查询目标数据最多需要 3-4 次磁盘 I/O。
前面已经介绍过B树与B+树的区别,这里不再进行讲解
优势:
-
单点查询:B 树进行单个索引查询时,最快可以在 O(1) 的时间代价内就查到。从平均时间代价来看,会比 B+ 树稍快一些。但是 B 树的查询波动会比较大,因为每个节点即存索引又存记录,所以有时候访问到了非叶子节点就可以找到索引,而有时需要访问到叶子节点才能找到索引。B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,数据量相同的情况下,B+树的非叶子节点可以存放更多的索引,查询底层节点的磁盘 I/O次数会更少。
-
插入和删除效率:B+ 树有大量的冗余节点,删除一个节点的时候,可以直接从叶子节点中删除,甚至可以不动非叶子节点,删除非常快。B+ 树的插入也是一样,有冗余节点,插入可能存在节点的分裂(如果节点饱和),但是最多只涉及树的一条路径。B 树没有冗余节点,删除节点的时候非常复杂,可能涉及复杂的树的变形。
-
范围查询:B+ 树所有叶子节点间有一个链表进行连接,而 B 树没有将所有叶子节点用链表串联起来的结构,因此只能通过树的遍历来完成范围查询,范围查询效率不如 B+ 树。B+ 树的插入和删除效率更高。存在大量范围检索的场景,适合使用 B+树,比如数据库。而对于大量的单个索引查询的场景,可以考虑 B 树,比如nosql的MongoDB。
组合索引是什么?优点?
通过将多个字段组合成一个索引,该索引就被称为联合索引。
比如,将商品表中的 product_no 和 name 字段组合成联合索引(product_no, name),创建联合索引的方式如下:
CREATE INDEX index_product_no_name ON product(product_no, name);
联合索引(product_no, name) 的 B+Tree 示意图如下
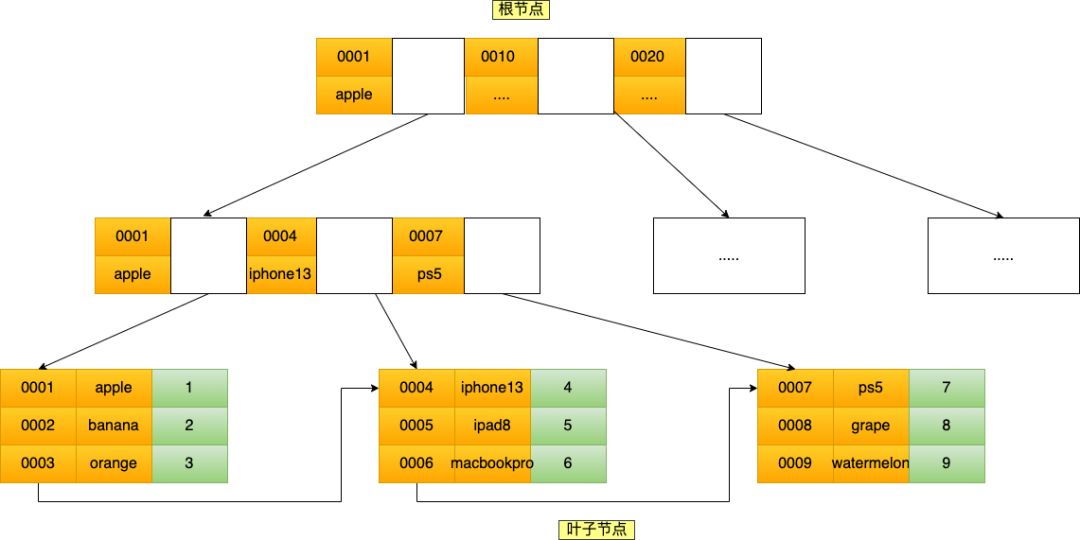
可以看到,联合索引的非叶子节点用两个字段的值作为 B+Tree 的 key 值。当在联合索引查询数据时,先按 product_no 字段比较,在 product_no 相同的情况下再按 name 字段比较。
也就是说,联合索引查询的 B+Tree 是先按 product_no 进行排序,然后再 product_no 相同的情况再按 name 字段排序。
因此,使用联合索引时,存在最左匹配原则,也就是按照最左优先的方式进行索引的匹配。在使用联合索引进行查询的时候,如果不遵循「最左匹配原则」,联合索引会失效,这样就无法利用到索引快速查询的特性了。
当查询的数据是能在二级索引的 B+Tree 的叶子节点里查询到,这时就不用再查主键索引查,比如下面这条查询语句:
select id from product where product_no = '0002';
这种在二级索引的 B+Tree 就能查询到结果的过程就叫作「覆盖索引」,也就是只需要查一个 B+Tree 就能找到数据。