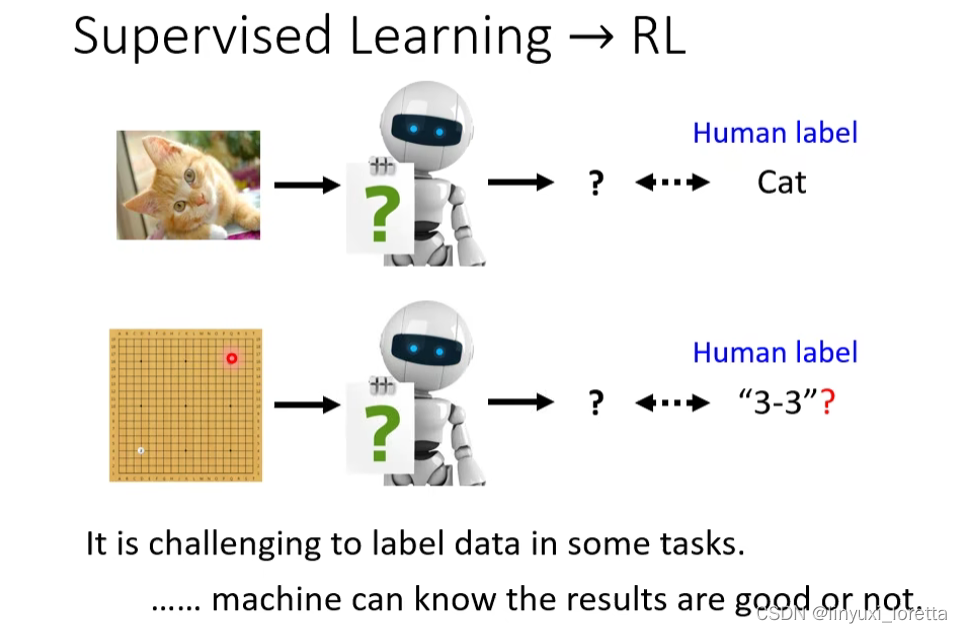
到目前为止,我們講的幾乎都是 Supervised Learning、就算是我們在講 Self Supervised Learning 的時候、其实也是很类似Supervised Learning的方法,只是label不需要特別僱用人力去標記,可以自动产生。或者是我們在講 Auto-encoder 的時候、我們雖然說它是一個 Unsupervised 的方法、没有用到人类的标记,但事实上,还是有一个label,只是这个label不需要耗费人力来产生。
但是 RL 就是另外一個面向的問題了,当人类也不知道正确答案是什么的时候,,也许就是你该考虑RL的时候,
藉由跟環境的互動、机器可以知道 它現在的輸出是好的還是不好的(Reward)
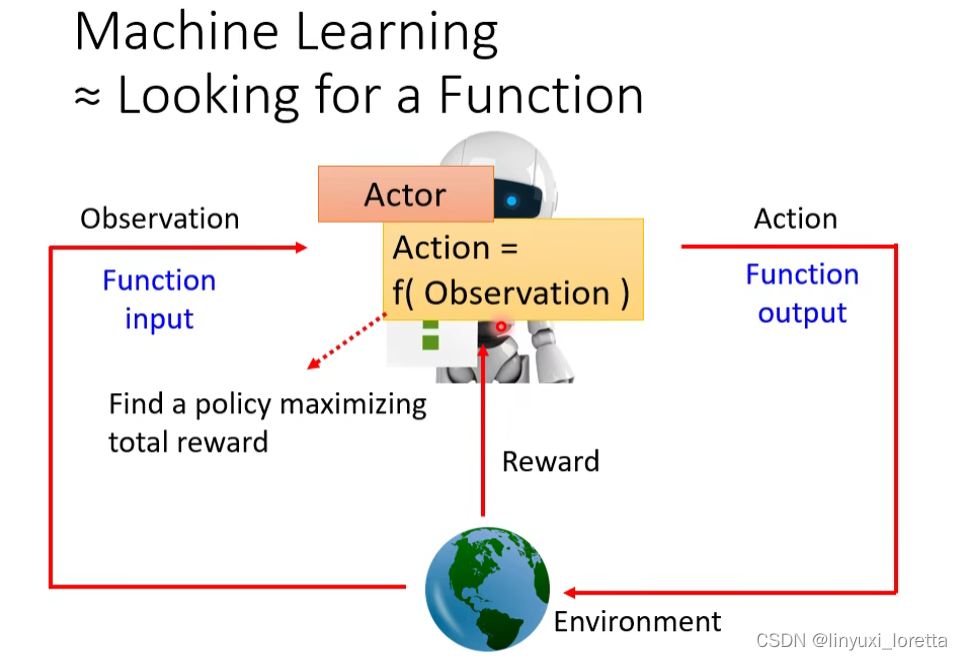
what is RL
介绍RL的基本概念时,有很多不同的切入點、也許你比較常聽過的切入點是從 Markov Decision Process 開始講起、那我們這邊選擇了一個比較不一樣的切入點、我要告诉你 RL 它跟我們這一門課學的 Machine Learning是一樣的框架(三个步骤)
RL最早的几篇论文都是让机器去玩Space Invader这個非常簡單的小遊戲
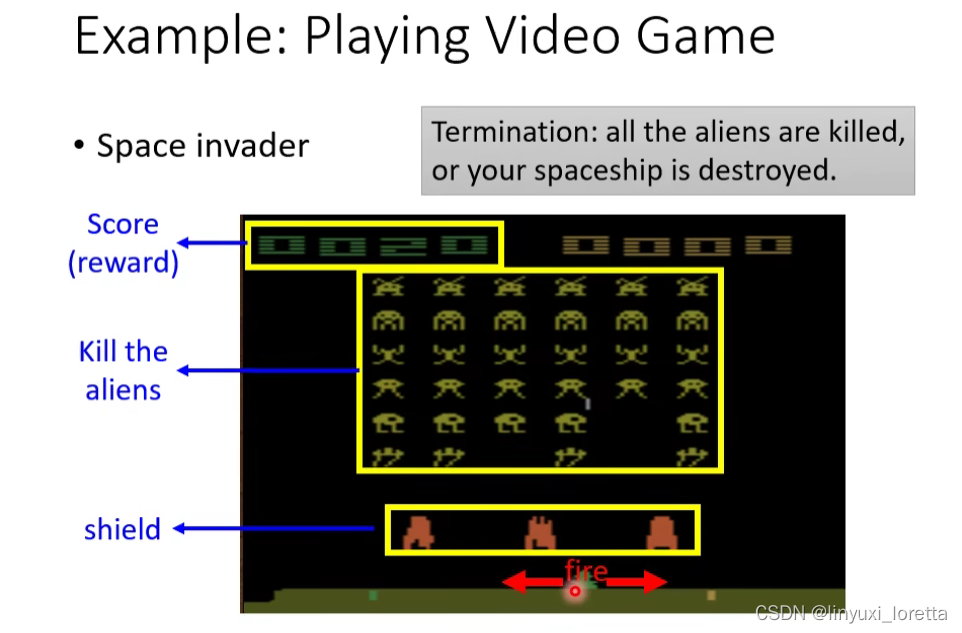
游戏操控者是Actor,Action是三个:向左、向右或者开火。如果杀掉一个外星人Reward=5,左右移动不得分。学习目标是使游戏得分最大。
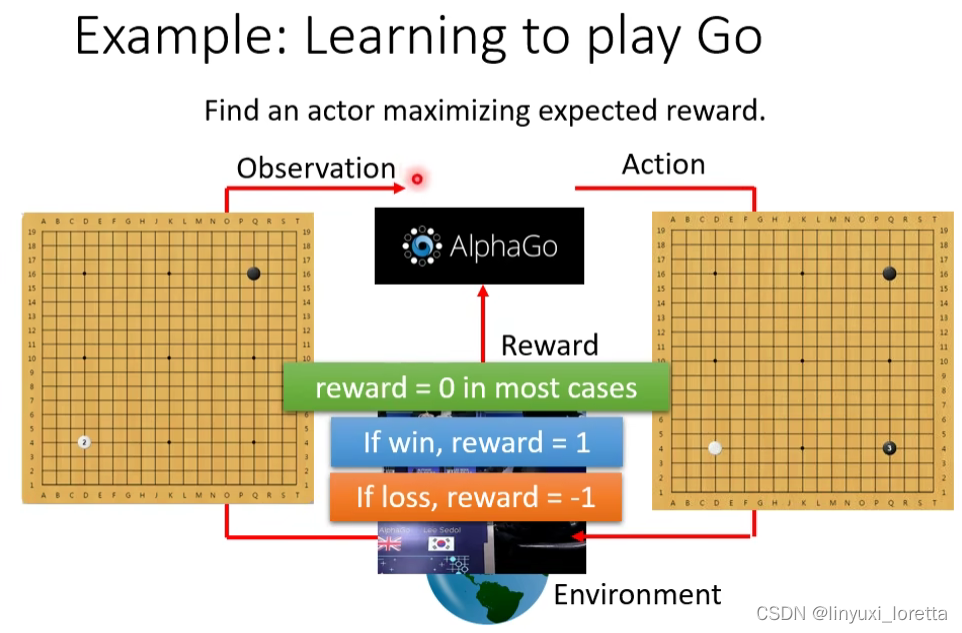
那接下來要告訴你說、RL 跟機器學習的 Framework、它們之間的關係是什麼
RL 其實也是一模一樣的三個步驟
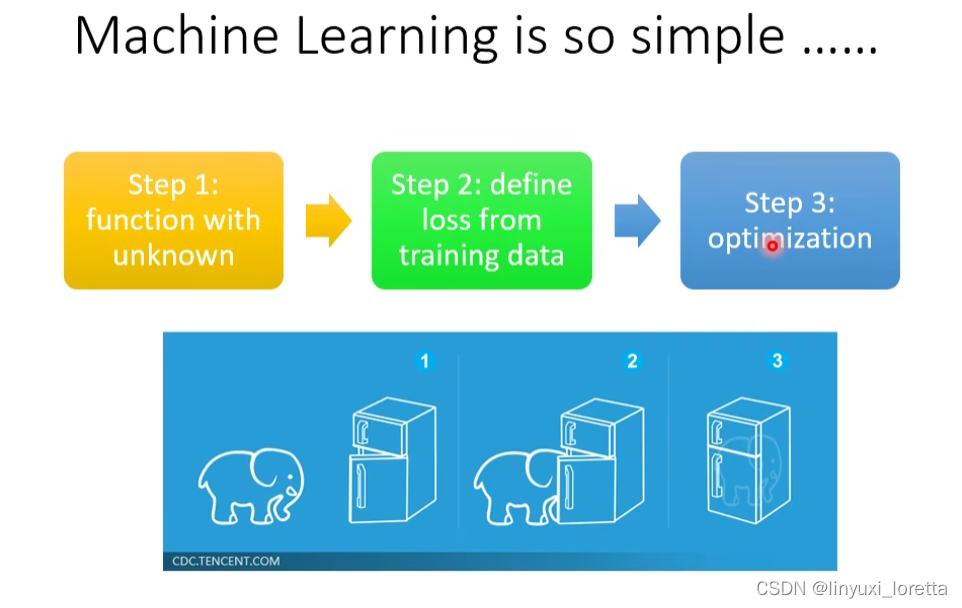
Step1: Function with Unknown
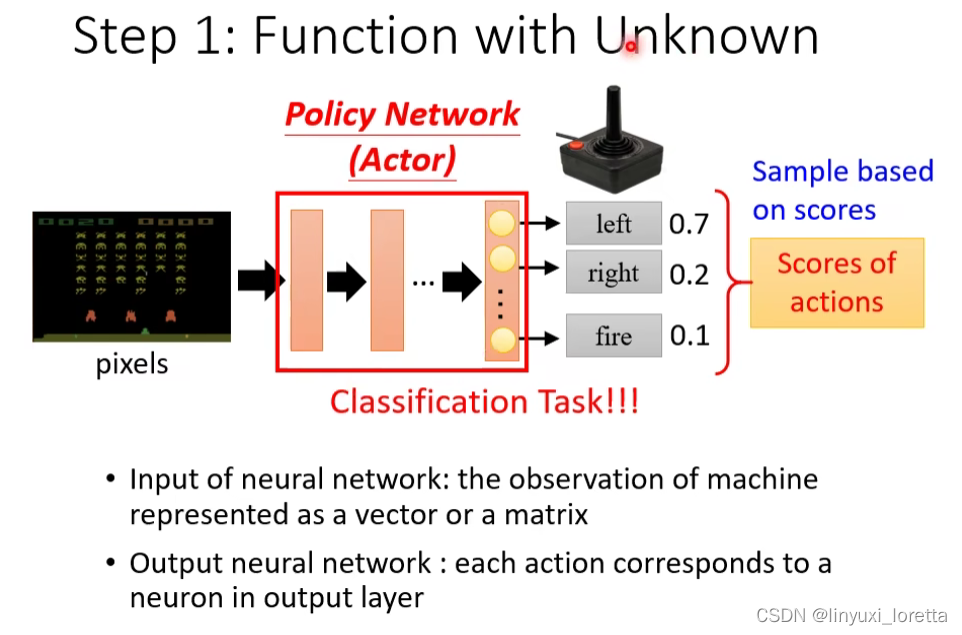
在還沒有把 Deep Learning 用到 RL 的時候、通常你的 Actor 是比較簡單的、不是network,它可能只是一個 Look-Up-Table
Actor叫做Policy Network,其实是一个复杂的function,他的输入是游戏画面,输出是每一个可以采取的行为的分数。其实是一个分类任务。
其实在RL里,你的 Policy Network跟分類的那個 Network其實是一模一樣的。至于这个Network架构,可以自己设计,比如如果输入是画面,network可以是CNN。
在作业里,不是直接讓我們的 Machine 去看遊戲的畫面、讓它直接去看遊戲的比较难做,所以是看跟現在遊戲的狀況有關的一些參數而已。在作业的simple code里还没有用CNN那么复杂,就是一個簡單的 Fully Connected Network
如果要同时考虑整場遊戲到目前為止發生的所有事情,可以用RNN(过去)或者transformer(现在)。
最后机器决定采取哪个action、取決於每一個 Action 取得的分數
常见的做法是,直接把这个分数当做一个机率,然后按照这个机率去sample,去隨機決定要採取哪一個 Action
为什么不直接看哪个分数最高就采取哪个?采取sample的好处是、就算是看到同樣的遊戲畫面,机器每次采取的行为也会略有不同,在很多游戏里这种随机性也许是重要的。还有一个理由等下再讲。
Step2: Define “Loss”
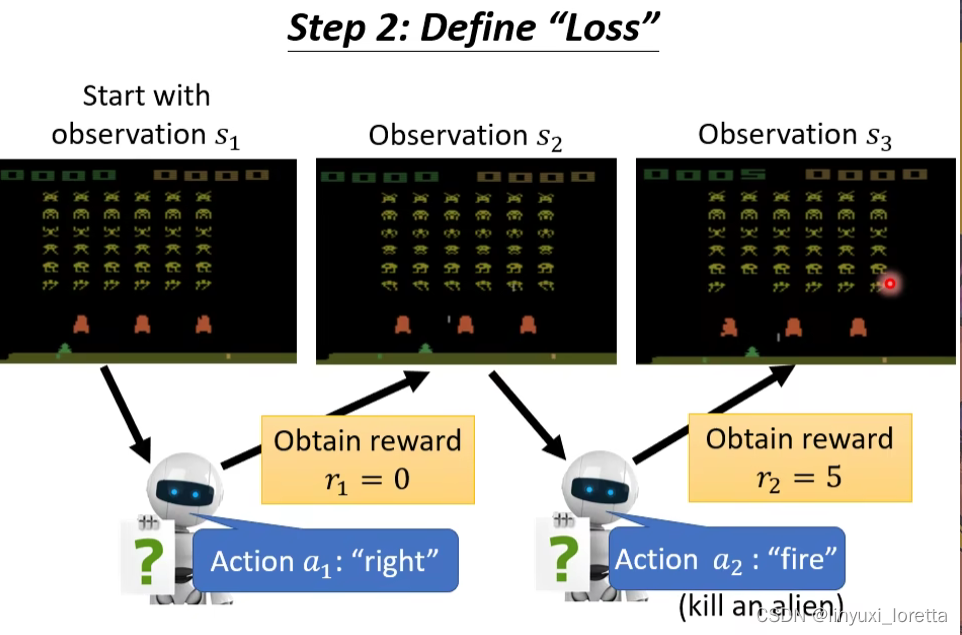
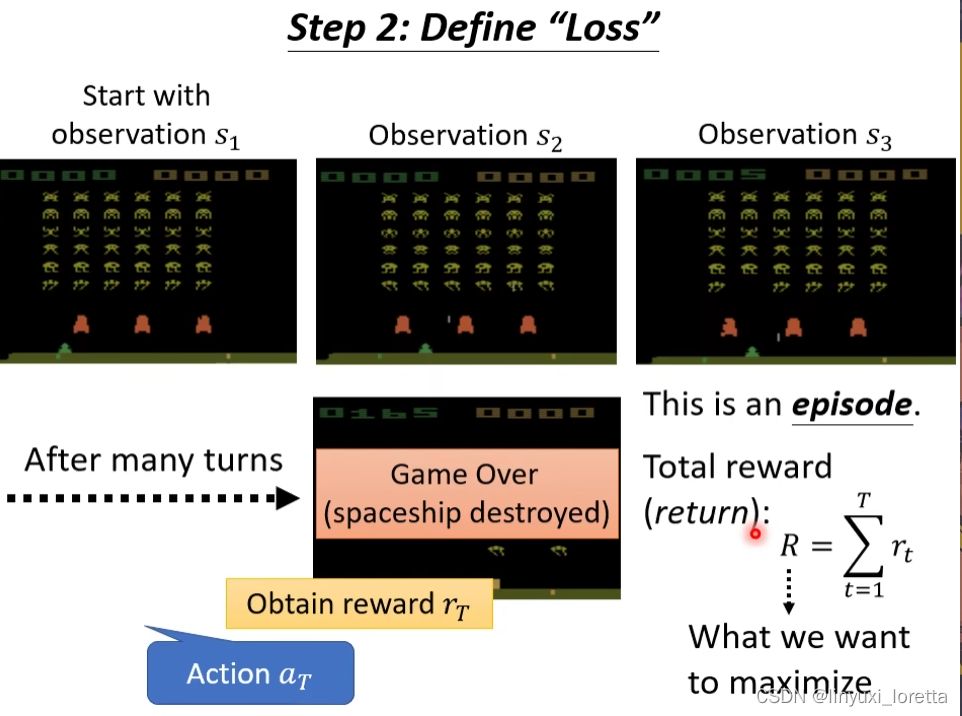
从游戏开始到结束 这一整个过程叫一个episode,
total reward另一个名字叫return,RL的文献上常常同时看到这两个词。
Reward 跟 Return 其實有點不一樣、Reward 指的是你採取某一個行為的時候、立即得到的好處、把整場遊戲裡面所有的 Reward 通通加起來 叫做 Return
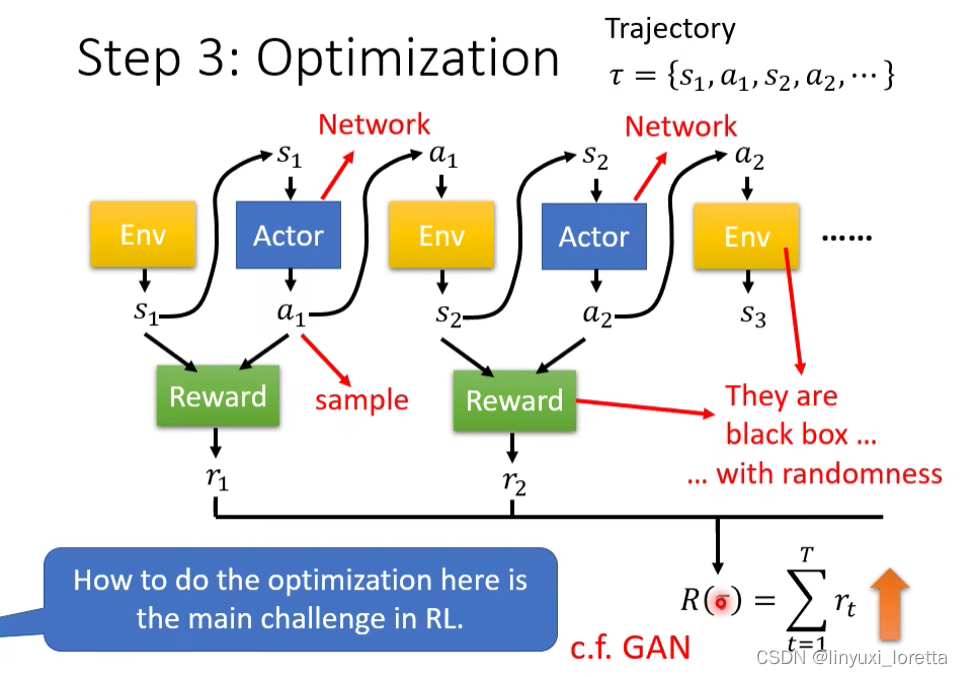
Step3: Optimization
根据互动过程机器会得到Reward,可以把Reward想象成一个function,
Reward Function有不同的表示方法、在有的遊戲裡面、也许reward只需要看你採取哪一個 Action 就可以決定。不過通常決定 Reward 的時候、光看 Action 是不夠的、還要看現在的 Observation 才可以、因為並不是每一次開火都一定會得到分數、要正好有擊到外星人、所以通常 Reward Function 在定義的時候,不仅需要看Action还需要看Observation
目标是 找一个network的参数让R越大越好。
乍看之下,如果Env、actor和reward都是 Network 的話、這個問題其實也沒有什麼難的、它看起來就有點像是一個 Recurrent Network
而RL困难的地方是,這不是一個一般的 Optimization 的問題
1. actor的输出有随机性,因为a1是sample出来的,
所以假設你把 Environment Actor 跟 Reward合起來當做是一個巨大的 Network 來看待、這個 Network 裡面的某一個 Layer 它的輸出每次都是不一樣的
2.
你的 Environment 跟 Reward它根本就不是 Network 啊、是一个黑盒子。遊戲機它裡面發生什麼事情你不知道、你只知道採取一個行為它會有對應的回應、但是到底是怎麼產生這個對應的回應、我們不知道。而Reward也不是一个network 是一个规则。
而且往往Env和Reward也有随机性。
所以 RL 真正的難點就是、我們怎麼解這一個 Optimization 的問題
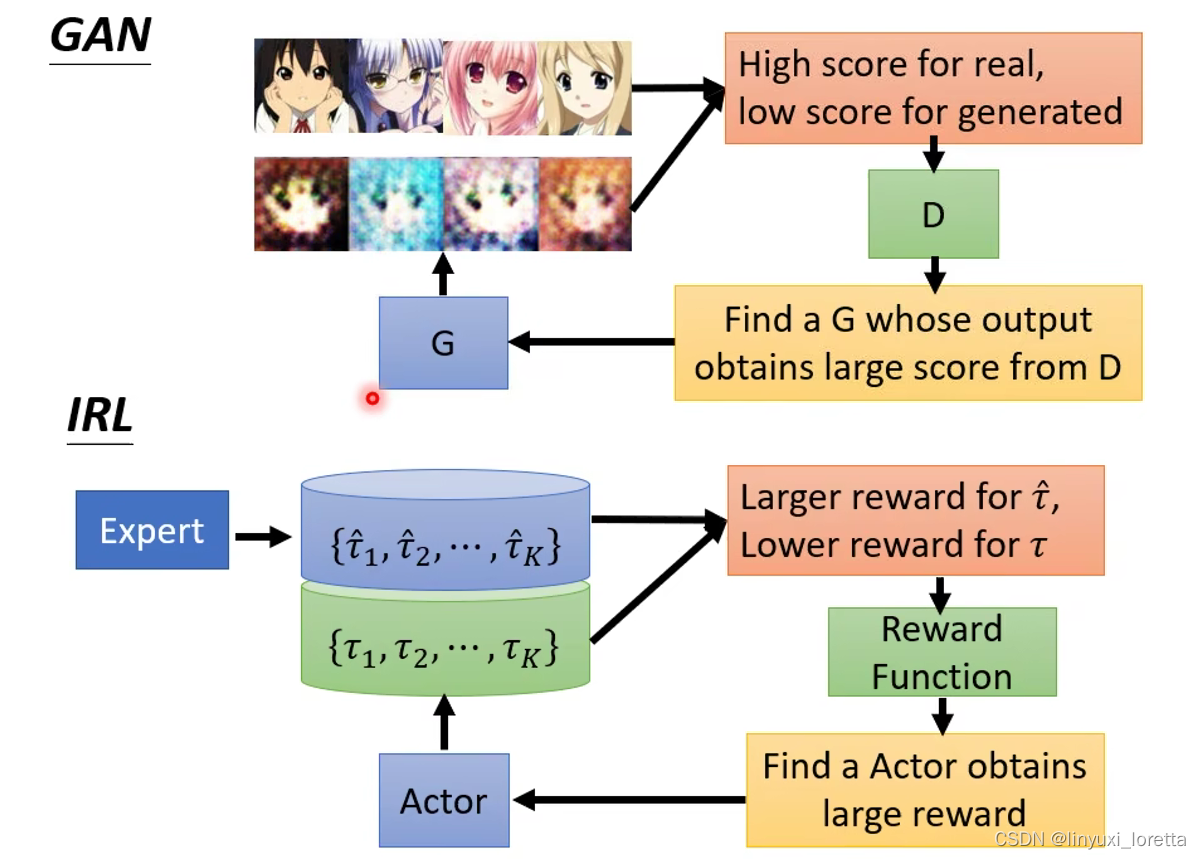
其实,跟GAN有异曲同工之妙,
一样的地方:actor就像generator,Env和Reward就像discriminater。
不一样的地方:discriminater是一个network,可以用gradient desenct的方法train,Env和Reward不是network,是两个黑盒子,没办法用gradient desent训练。
Q&A:
沒有固定 Random Seed、你可能 Initialize 的 Parameter 不一樣、所以你每次訓練出來的結果不一樣
但是 RL 是在 Testing 的時候就有隨機性、就算是同樣的 Network,每次测试时,結果都可以是不一樣
所以 RL 是一個隨機性特別大的問題啦
RL蛮容易找到各式各樣的 GitHub 上的 Code
Policy Gradient
一个RL做optimization 常用的演算法,叫Policy Gradient
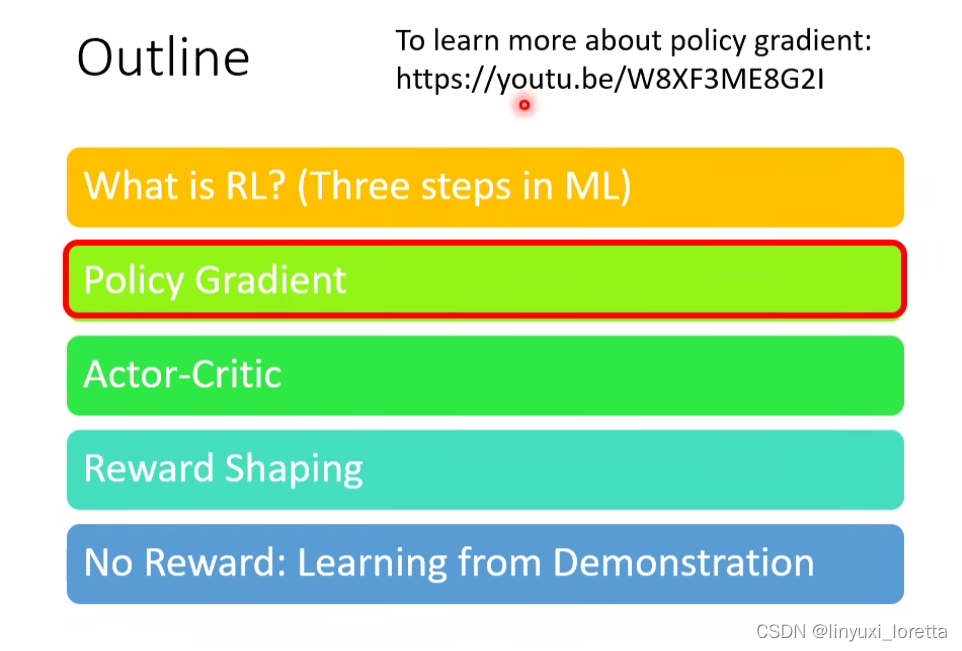
How to control your actor?

Loss等于想要的action的cross-enropy减去不想要的action的cross-enropy。
所以藉由很像是在Train 一個 Classifier 的這種行為、我們可以去控制一個 Actor 的行為、
Q&A:就是如果以 Alien 的遊戲來說的話、因為只有射中 Alien 才會有 Reward、這樣 Model 不是就會一直傾向於射擊嗎?對 這個問題我們等一下會來解決它
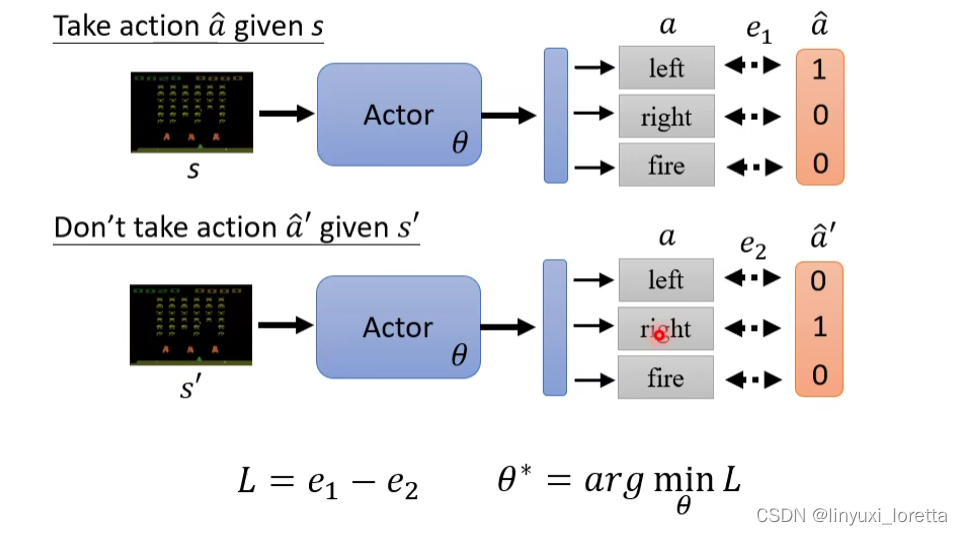
Q&A:這樣不就回到 Supervised Learning 了嘛、這個投影片上看起來、就是在訓練一個 Classifier 而已啊?這個就是跟 Supervised Learning Train Image Classifier 是一模一樣的、等一下我们会看到和一般的监督学习不一样在哪,
接下来,要训练Actor,就需要蒐集一些訓練資料:
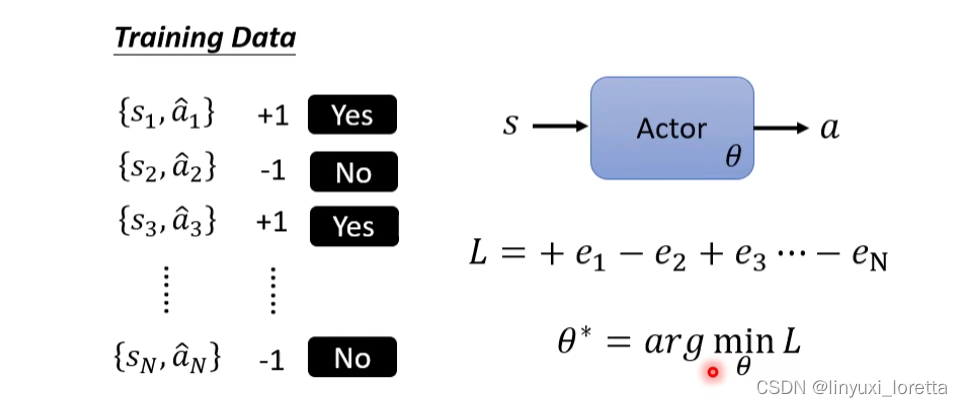
更进一步,action不只判断为好或不好两类,而是有程度差异,本來是 Cross-entropy 前面是±1,
现在通过系数An控制说每个行为 我们有多希望Actor去执行。
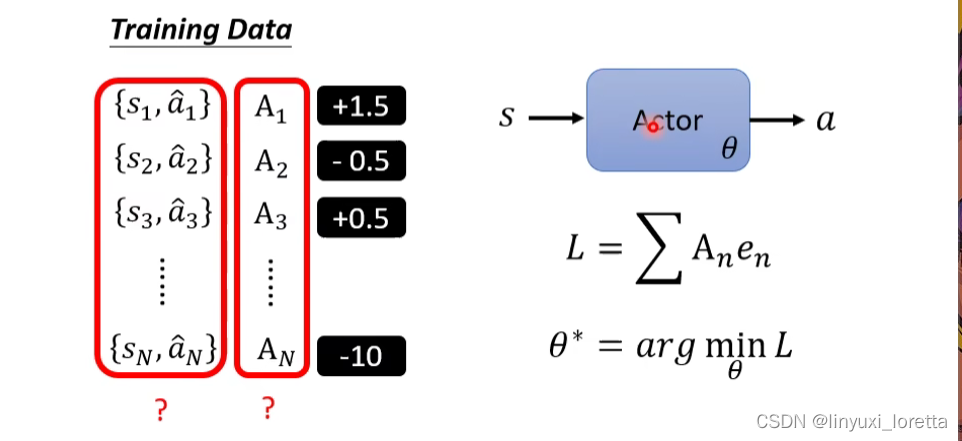
那怎么控制An?怎么产生s和a的pair?
怎么定义A?
Version0
最简单的但其实是不正确的版本,作业simple code的版本,
通常搜集资料时,通常做多个episode, 比如说助教的simple code里跑了5个episode,才搜集到足够的资料。
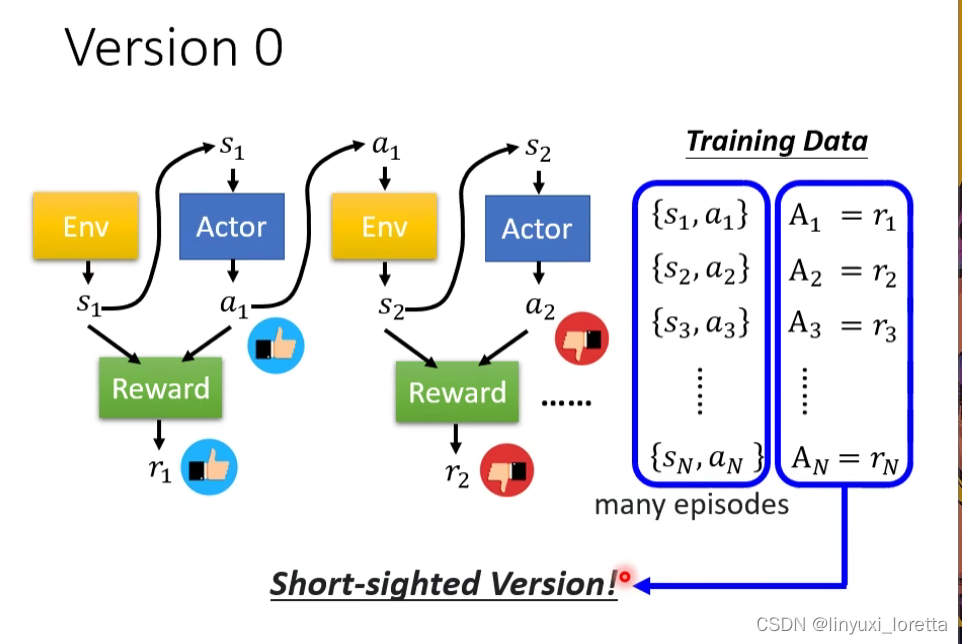
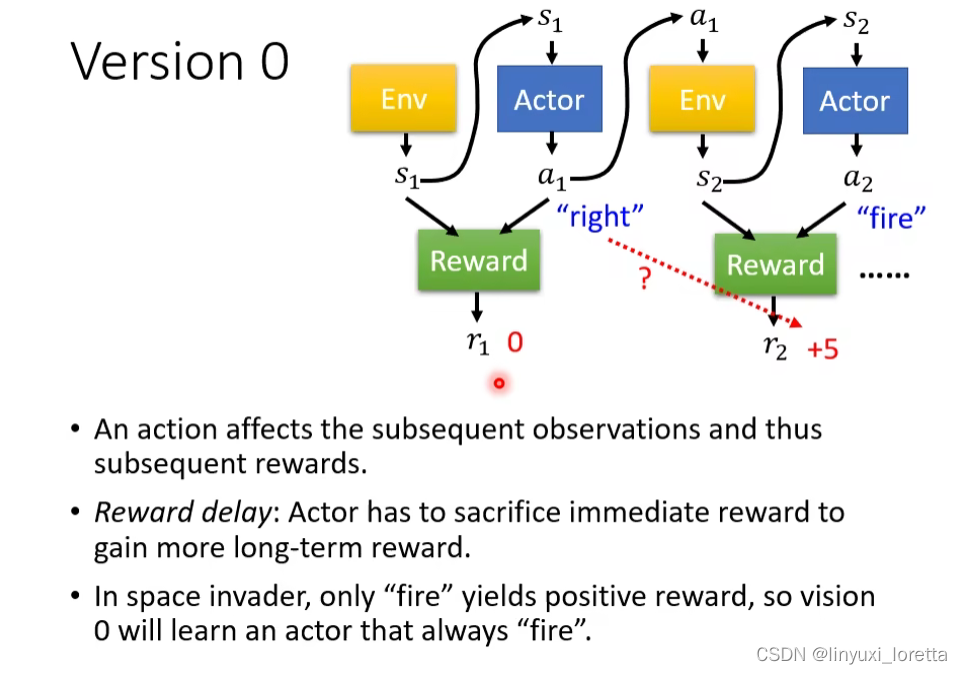
这不是一个好方法,因为学出来的network是一个短视近力的actor,因为每个行为都会影响互动接下来的发展,每个行为并不是独立的。
而且存在Reward delay。“牺牲短期利益”,这个版本机器只会学到疯狂开火 只有这个行为是被鼓励的。
不知道为什么,这个version 0是大家自己在做RL的时候特别容易犯的错误。
怎么办呢?所以接下来,我們開始正式進入RL的領域、真正來看 Policy Gradient 是怎麼做的
Version 1

但是version1 也有点问题,假设游戏很长,把 归功于a1的可能性较低。
Version 2
是一個小於 1 的值、就算你設 0.9、0.9 的比如說 10 次方也很小了,

Q&A:越早的動作就會累積到越多的分數嗎?
在這個設計的情境裡面 ,是的,但是這個其實也是一個合理的情境、因为比較早的那些動作對接下來的影響比較大、到游戏终局,没什么外星人可以杀了,你可能做什麼事對結果影響都不大、所以比较早的observation、它們的動作是我們可能需要特別在意的
不過像這種 A 要怎麼決定、有很多種不同的方法、如果你不想要比較早的動作 Action 比較大、你完全可以改變這個 A 的定義、
事實上不同的RL的方法、其實就是在 A 上面下文章,有不同的定义A的方法,
Q&A:对于结尾才有分数的游戏,只要最后赢了,所采取的一串action都是好的,感觉很难train,但最早版本的alphaGo是这样做的,
假設今天你的 Reward 非常地 Sparse(稀疏),那你可能会需要一个比较好的Heuristic Function、最原始的“深蓝”那篇paper里(下西洋棋)、不是下到结束才得到reward,中間會有蠻多的狀況它都會得到 Reward
G1还需要做标准化之类的动作吗?就有了version3,因为好或坏是相对的,
Version 3

最简单的方法,设定一个baseline让G去减掉作为标准化,让G`有正有负。
那怎么设置b?
Policy Gradient怎么操作?

1.给actor一个随机初始化的参数
2.对于training iteration 1到T:拿actor去跟Env互动,得到一大堆{s,a}的pair,
3.进行评价。用A1,A2,…An,来决定这些action a1,a2,...an到底好不好。定义Loss,update模型。

收集资料这件事发生在iteration内部,所以每组资料只能update参数一次。所以这就是为什么RL的训练过程往往非常花时间,因为每次update要重新收集资料。助教程序update 400次 跑起来很卡。
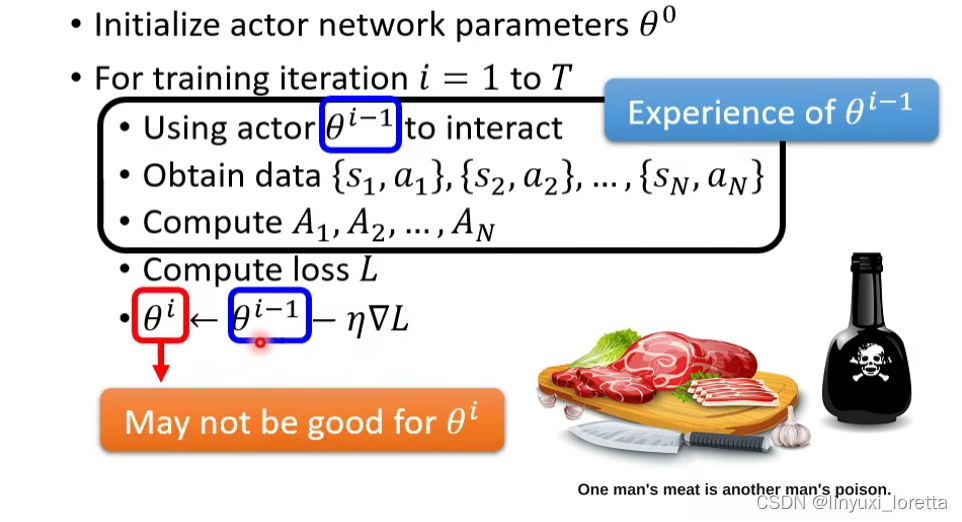
原因: 同一個行為對於不同的 Actor 而言、它的好是不一樣的
那 θi-1 會執行的這個 Trajectory跟 θi 它會採取的行為根本就不一樣、所以你拿著 θi-1 接下來會得到的 Reward、來評估 θi 接下來會得到的 Reward、其實是不合適的
收集资料的actor和被训练的actor最好是同一个。那當 Actor 更新以後、你就最好要重新去蒐集資料 。 On-policy
我們要訓練的 Actor、能不能夠根據其他 Actor 跟環境互動的經驗、來進行學習呢。Off-policy learning可以想办法让θi根据θi-1收集的资料进行学习。优势是可以节省时间。

有一个非常经典的Off-policy方法是Proximal Policy Optimization (PPO),是如今蛮常使用的方法。
Off-policy的重点是:在训练的actor要知道自己和“跟环境互动的actor”之间的差距。
所以 Actor To Interact示范的经验,有些可以采纳、有些不可以采纳。

Exploration
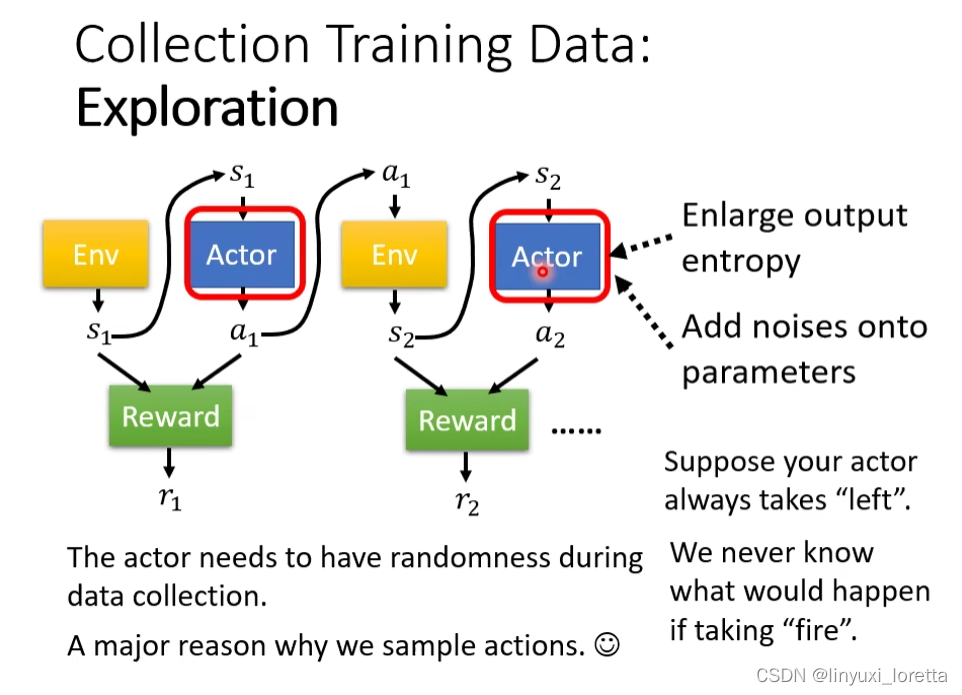
Actor采取行为时是有一些随机性的,这个随机性其实非常重要,很多时候如果随机性不够会train不出好的结果。
随机性大一点,這樣我們才能夠蒐集到、比較多的 比較豐富的資料,才不会有一些状况的 Reward 是從來不知道
为了要随机性大一点,training时会刻意加大随机性,
- 比如说actor的output是distribution,有人会加大distribution 的entropy、那讓它在訓練的時候、比較容易 Sample 到那些機率比較低的行為
- 或者是有人會直接在這個 Actor的參數上面加 Noise、讓它每一次採取的行為都不一樣
Exploration其實也是 RL Training 的過程中、一個非常重要的技巧
PPO例子
DeepMind和OpenAI都同時提出了 PPO 的想法、
DeepMind

用PPO方法 learn蜘蛛型的機器人或人形的機器人做一些动作,
OpenAI

2021 - 概述增强式学习 (三) – Actor-Critic_哔哩哔哩_bilibili
Actor-Critic
Critic
critic是用来评估actor的好坏。
那 Critic 有好多種不同的變形、有的Critic只看游戏画面,有的Critic是又看画面又看action,来看得到多少reward
介绍一个作业里派的上用场的Critic 叫Value function,输入是游戏的画面,上标θ代表观察的对象actor的参数是θ,输出是一个scalar,这个数值的含义是这一个actor θ,如果看到s,它得到的discounted cumulated reward。这个function Vθ(s)需要未卜先知,未玩先猜。
这里要强调:这个Value function是有个上标θ的,所以 Value Function 的數值 是跟觀察的對象有關係的.
Critic怎么训练出来?
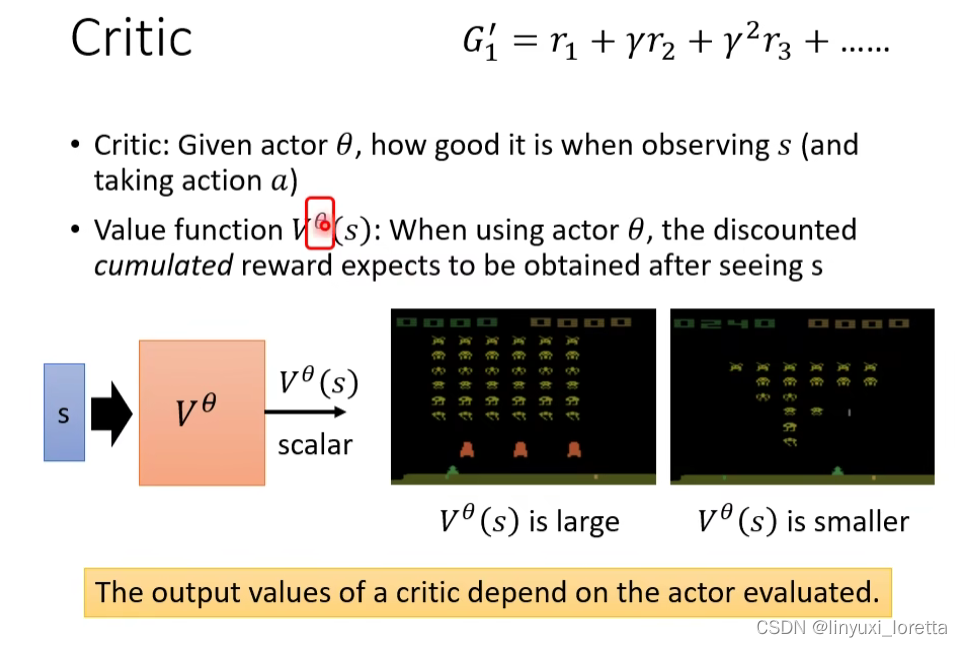
方法1: Monte-Carlo (MC) based approach
Actor先跟Env互动很多次得到训练资料,拿这些资料来训练value function。
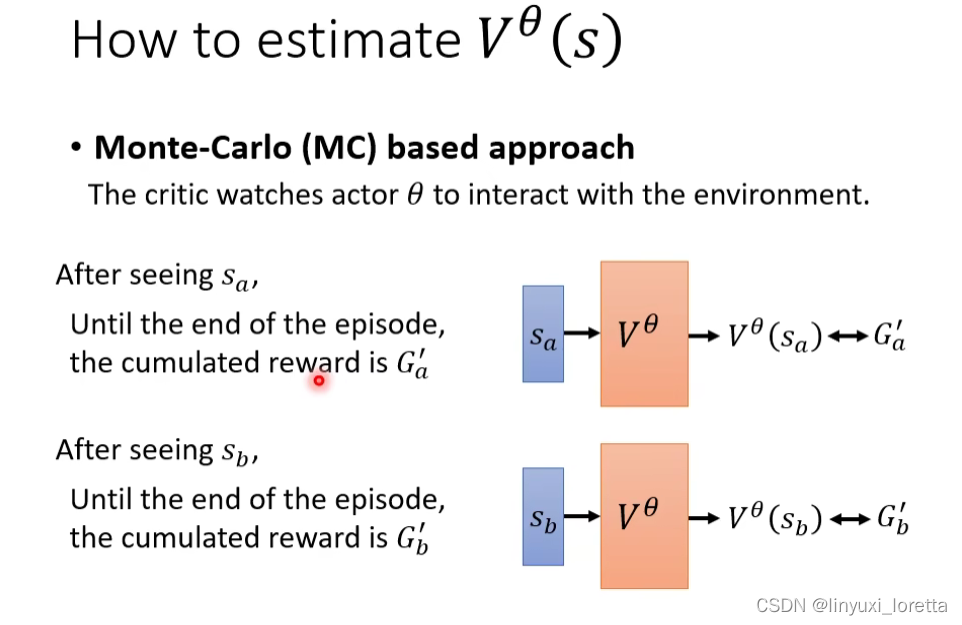
方法2: Temporal-difference (TD) approach
不用玩完整个游戏,看到某一次的...st, at, rt, st+1..,就可以训练Vθ(s)。

MC v.s. TD
MC和TD拿来算同样的observation,算出来的Value function很可能不一样。
都可以说是对的,它們只是背後的假設是不同的
TD背后的假设是Sa 跟 Sb 是沒有關係的,看到Sa 之后再看到Sb,並不會影響看到 Sb 的 Reward
MC觉得Sa 会影响Sb,

Version 3.5
V3.0 说到,怎么设置b?b的一个合理的设法是设成Vθ(st)。
Vθ(st)代表,看到某一個畫面 St 以後(有随机性),会得到不同的 Reward(G‘),这些可能的结果平均起来就是Vθ(st)。


Gt‘是指在st处执行at得到的结果.
At>0表示执行at得到的reward > 隨便執行一個 Action 得到的 Reward
但是还有一个问题,Gt‘只是一次sample的结果,有可能好有可能坏,那有没有可能拿平均减掉平均?
version 4.
本來你會需要玩很多場遊戲,才能夠得到Vθ(St+1)平均值,但假設你訓練出一個好的 Critic,
这样计算st对应的G的时候,只有rt会受sample的影响,rt后面的rt+1 + rt+2 + …的和是个期望。
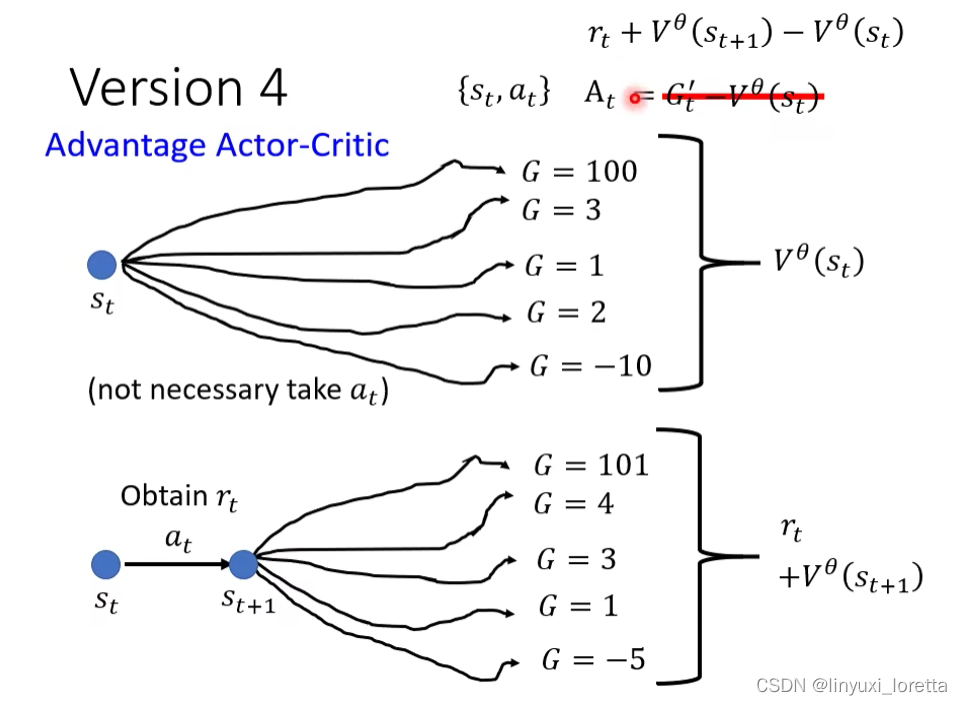
这个方法就是大名鼎鼎的Advantage Actor-Critic。
Tip of Actor-Critic.
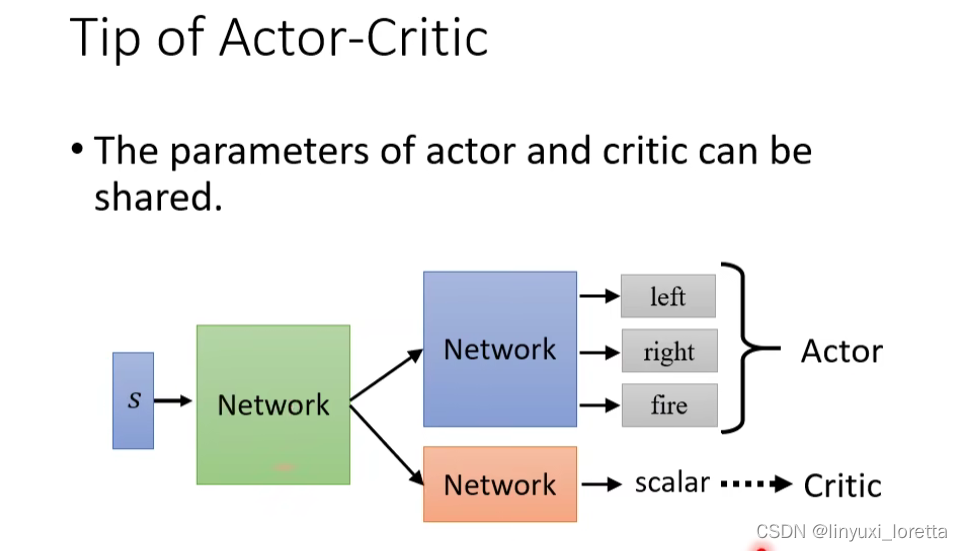
Actor是一个network,Critic也是一个network,他们的输入都是s,所以可以共用前面几个layer。
所以你今天在實作的時候往往呢、你會把Actor-Critic 設計成這個樣子、它們有共用大部分的 Network、只是最后 輸出不同的 Action就是actor、 輸出一個 Scalar就是critic

RL还有一系列做法是直接用Critic就决定用什么action,其中最知名的算法是DQN。
DQN有非常多的变形,
有一篇非常知名的 Paper 叫做 Rainbow,试了7种变形,
Q&A:Sa 後面接的不一定是 Sb 吧,怎么办?
Sa 後面不一定接 Sb,在剛才我們看到的那個例子裡面就没法处理这个问题,因为我們看到那個只有 8 個 Episode 的例子裡面、Sa 後面就只會接 Sb、我們沒有觀察到其它的可能性、所以我們沒辦法處理這個問題、这就告诉我们,做RL时Sample 這件事情是非常重要的、RL 最后learn的好不好跟你在 Sample 的時候 Sample 得好不好,关系非常大,所以RL是一个非常吃人品的方法
Reward Shaping
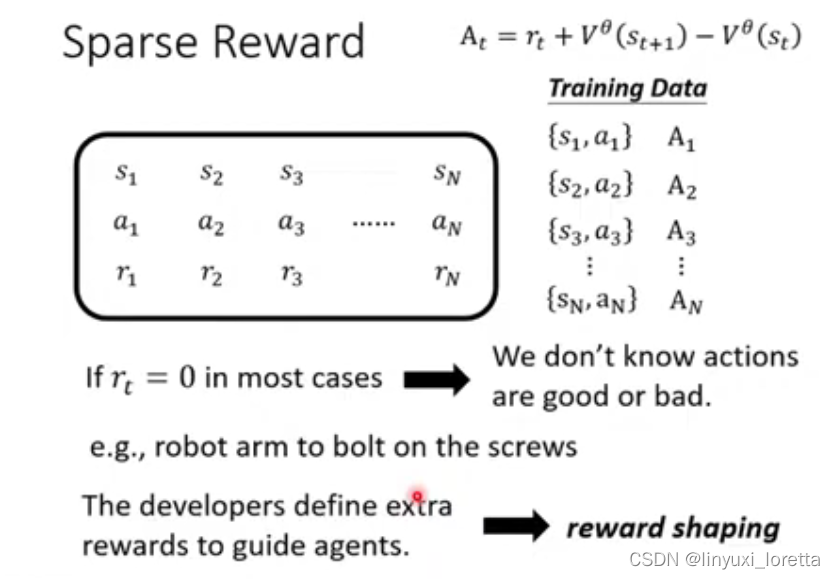
Sparse Reward
在RL里,我们很怕遇到一种情况Reward多数为0怎么办?
比如栓螺丝这种任务,只有栓进去才有reward。
有一种解法是想办法提供另外一种reward来指导agent。这就叫reward shaping。
Reward Shaping
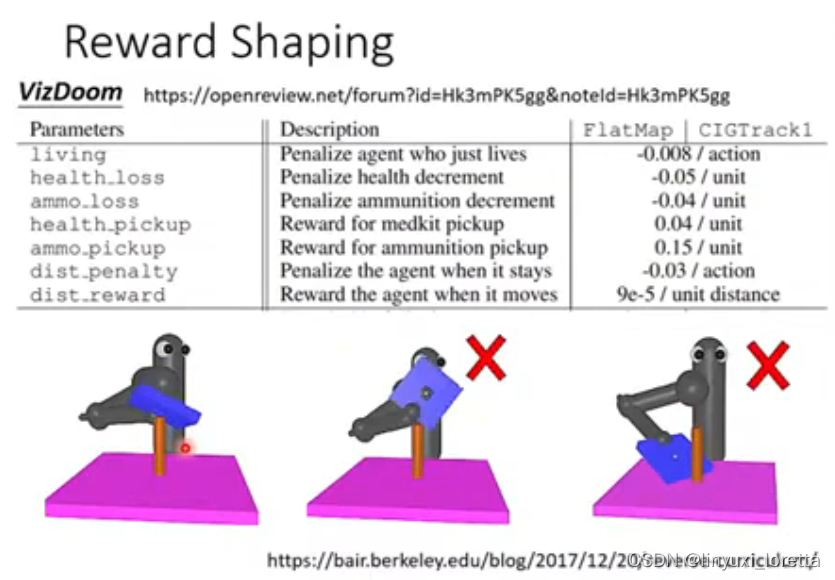
接下来举一个reward shaping 真正實際使用在 RL 裡面的例子,
VizDoom第一任视角射击游戏

真正的reward:被敌人杀掉扣分,杀掉敌人加分
Reward shaping:扣血扣分,损失弹药扣分,捡到医药包或补给包加分,总是呆在原地扣分,如果动一下就给一点点分数(每动一下就给一个很小的分数9*10^(-5)),每次agent活着就要被扣一点点分(防止agent贴着边缘躲避敌人)。
Reward shaping需要Domain knowledge,就是需要人类对游戏的理解。
机器手臂把蓝色板子插到棍子上面。
Reward shaping: 让板子靠近棍子,
(机械专业的来说几句,涉及到装备约束问题:孔轴与柱轴共线,装配面平行且距离为0即可完成)
Reward Shaping-Curiosity
Reward Shaping有一种知名的做法是给机器加curiosity。
Curiosity based RL 來自於 ICML 2017 的這一篇文章
比如有一个例子机器玩玛丽欧游戏,只叫机器尽量碰到新东西就可以让游戏通关。

接下来让机器玩VizDoom,这时候机器遇到杂讯也会当成新的东西,所以需要注意要有意义的新。
Curiosity 那篇论文里有讲要怎么处理无意义的新(e.g.杂讯)这件事。

No Reward: Learning From Demonstration
有时候会连reward也没有。
其實像 Reward 這種東西,往往只在一些比較 artifisial 的環境、比如說遊戲裡面、特別容易被定義出來
真实环境很难定义reward。假如你想用RL的方法学自动驾驶,那到底做什麼樣的事情、會得到什麼樣的 Reward 呢,礼让行人+100?+1000?闯红灯-50?-50000?
而且光定reward有时候机器可能会有一些神逻辑导致意想不到的行为。比如威尔史密斯的机械公敌里,机器人要遵守三条规则:
- 不伤害人类,使人类不受伤害;
- 在保证第1条的前提下遵守人类命令;
- 机器人在保证第1和第2条的前提下保护自己。
最后机器人的决定是把所有人类都关起来,这样可以充分保证人类安全得到最高的reward。

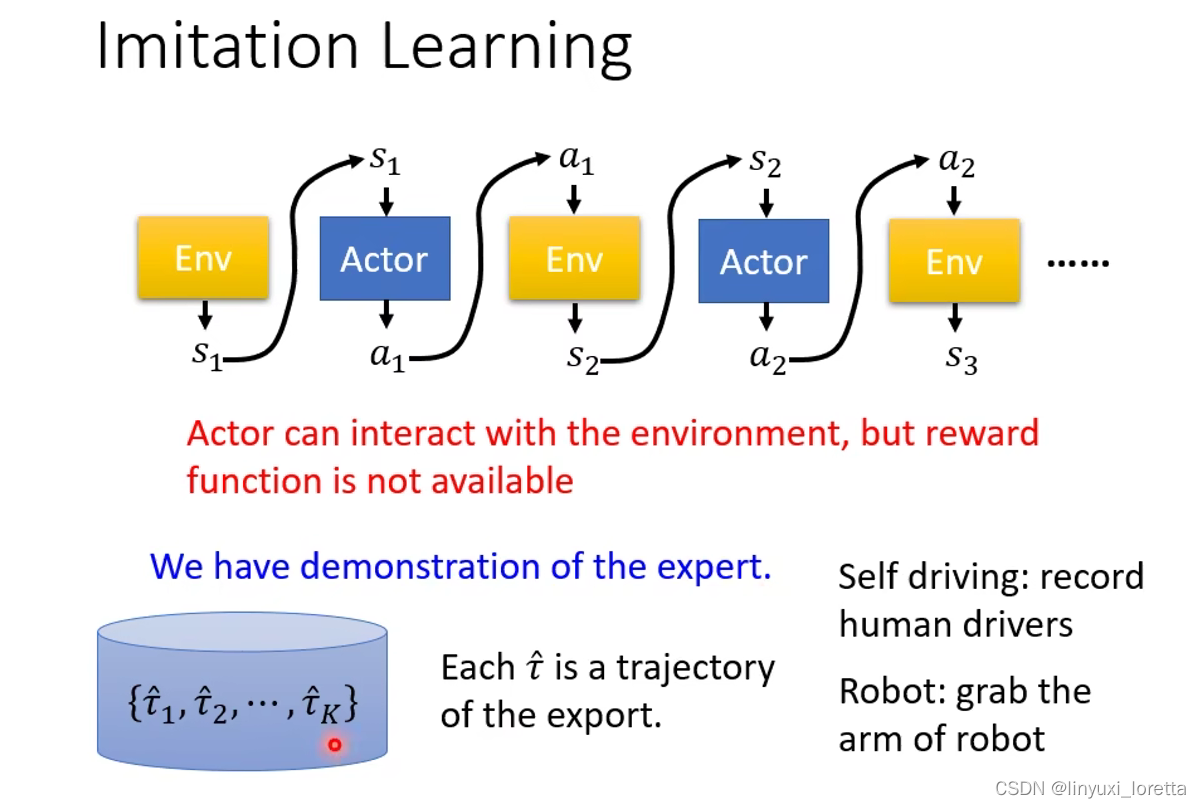
Imitation Learning
没有reward训练的其中一个方法是Imitation Learning。
Actor仍然会跟环境互动,但是没有reward。
记录expert人类跟环境的互动作为示范。
用 hat来表示专家示范。
你想要叫機器做一些指定的動作,你可能會先拉著機械的手臂示範一次
这个不就是supervised learning吗?
没错,有人类示范的时候有类似supervised的做法叫做Behavior Cloning。
但是光复制人类的行为有一个问题,就是人类观察的s和机器观察的s有可能不一样。
如果它從來沒有看過一個車子快要撞牆的狀態、它訓練資料裡面就没有,机器就不知道怎么处理,
第二个可能遇到的问题是有一些行为是人类个人特质的行为,没必要学习,但是机器也会完全复制。
而且,假設機器能力是有限的情況下,Behavior Cloning也許會造成更大的問題

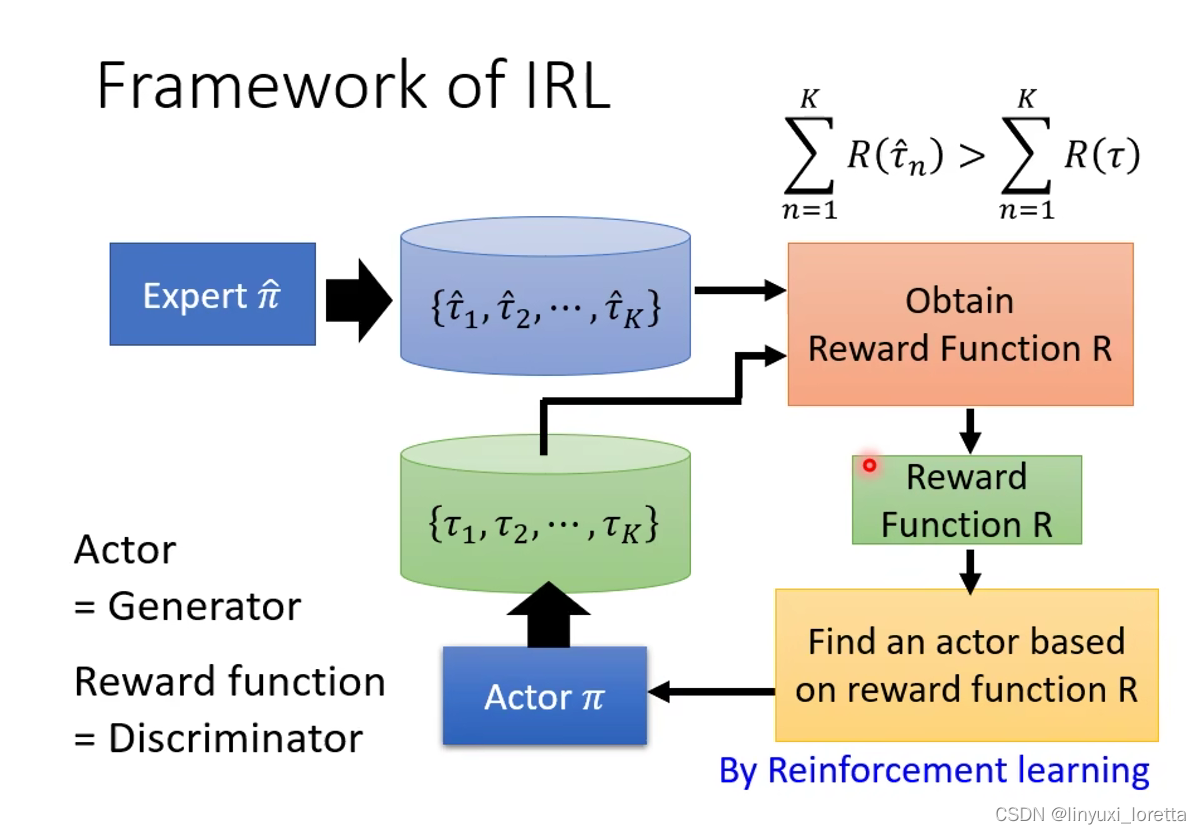
Inverse Reinforcement Learning (IRL)
所以怎么办呢?有另外一种技术叫inverse reinforcement learning,就是让机器自己定reward。
原来的RL,有reward、Env,然后用RL的算法和Env、reward互动,然後你就學出一個 Actor
IRL,从Expert的Demonstration和Env,去反推Reward应该是怎样的,学出Reward function,之后就可以直接用一般的RL来学actor,
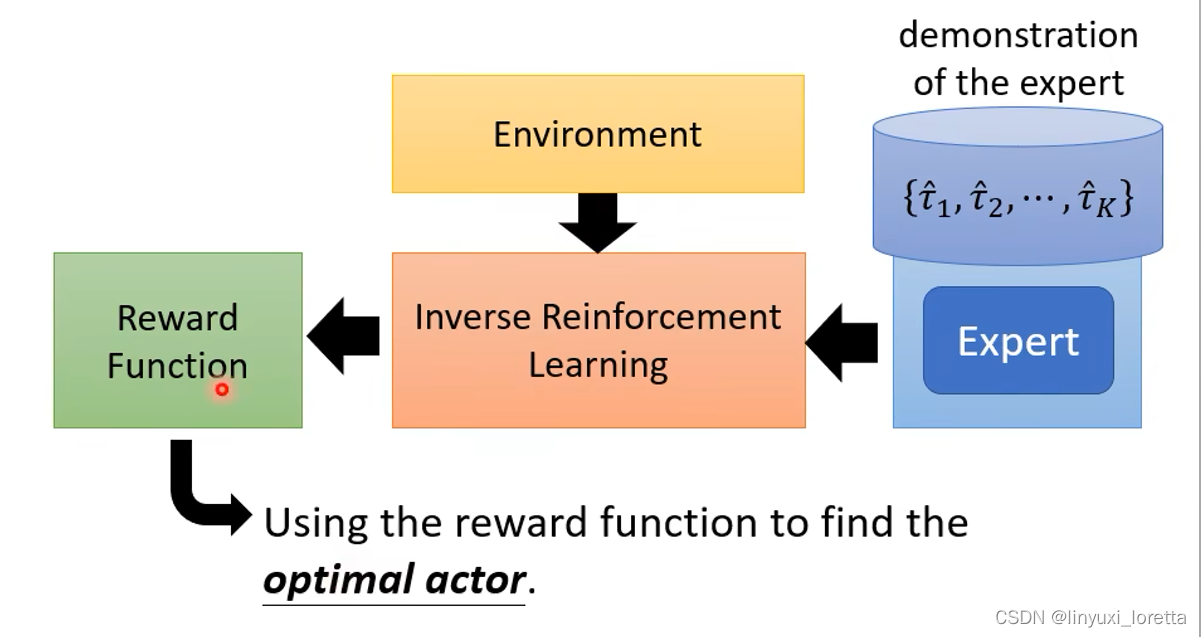
IRL最基本的原则是:The teacher is always the best。
在每个迭代里面:
Step1: actor先跟环境互动得到一些trajectories;
Step2: 定义一个reward function,这个function的条件是老师的行为得到的reward必须要高于actor,就是给老师高分,给actor低分。
Step3: 更新actor的参数让它maximize会得到的reward,通过RL的方法。
可以把actor想成是GAN里的Generator, 把reward function想成是Discriminator。
IRL常用来训练机械手臂
过去 用IRL之前,教机器一个简单的动作也需要很多的代码很费力气。

用了IRL以后:


To Learn More……
还有一个更潮的做法是给机器一个画面让机器做到画面里的事情。
Reinforcement learning with Imagined Goals (RIG)
训练过程很有意思,机器自己创造目标,培养自己达成目标的能力,


](https://img-blog.csdnimg.cn/9f5c50ddedf54825af81b7ef490ff02d.jpeg)