目录
一、分析目标:
二、代码实现
目标1:对于捕获的URL内嵌发包
目标2:找到电话和邮箱的位置
目标3:提取电话和邮箱
三、完整代码
四、网络安全小圈子
(注:需要带上登录成功后的cookie发包)
一、分析目标:
点击进去爬取每个企业里面的电话、邮箱
(我们是来投简历的,切勿干非法的事情)
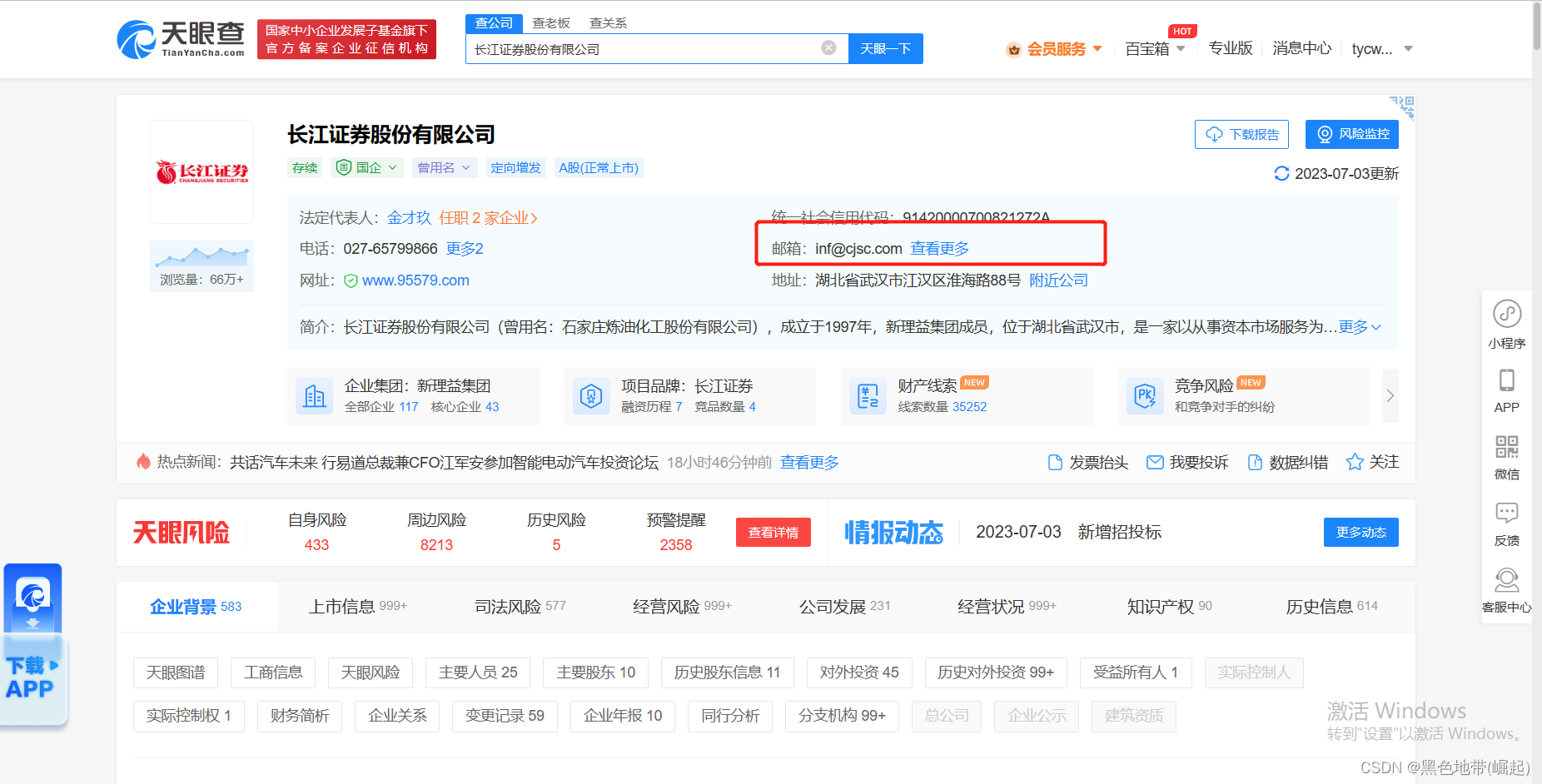
每个单位的URL记下来
(一定是在前一个页面能找到的,不然只能跳转进来是吧)

我们可以看到这个URL就是他跳转的URL
其实我们前面已经提前爬取了每个单位的这个URL
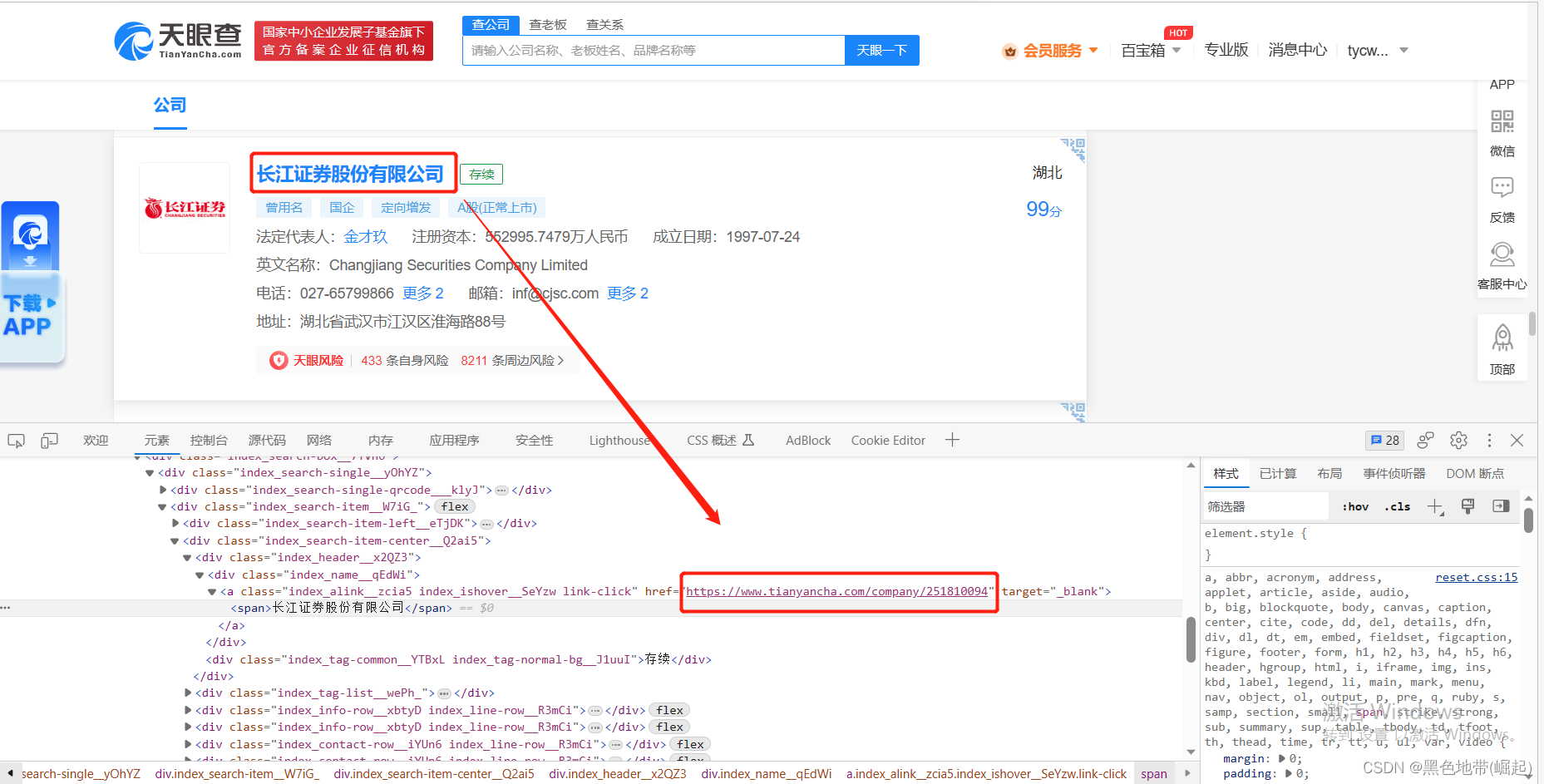
思路:
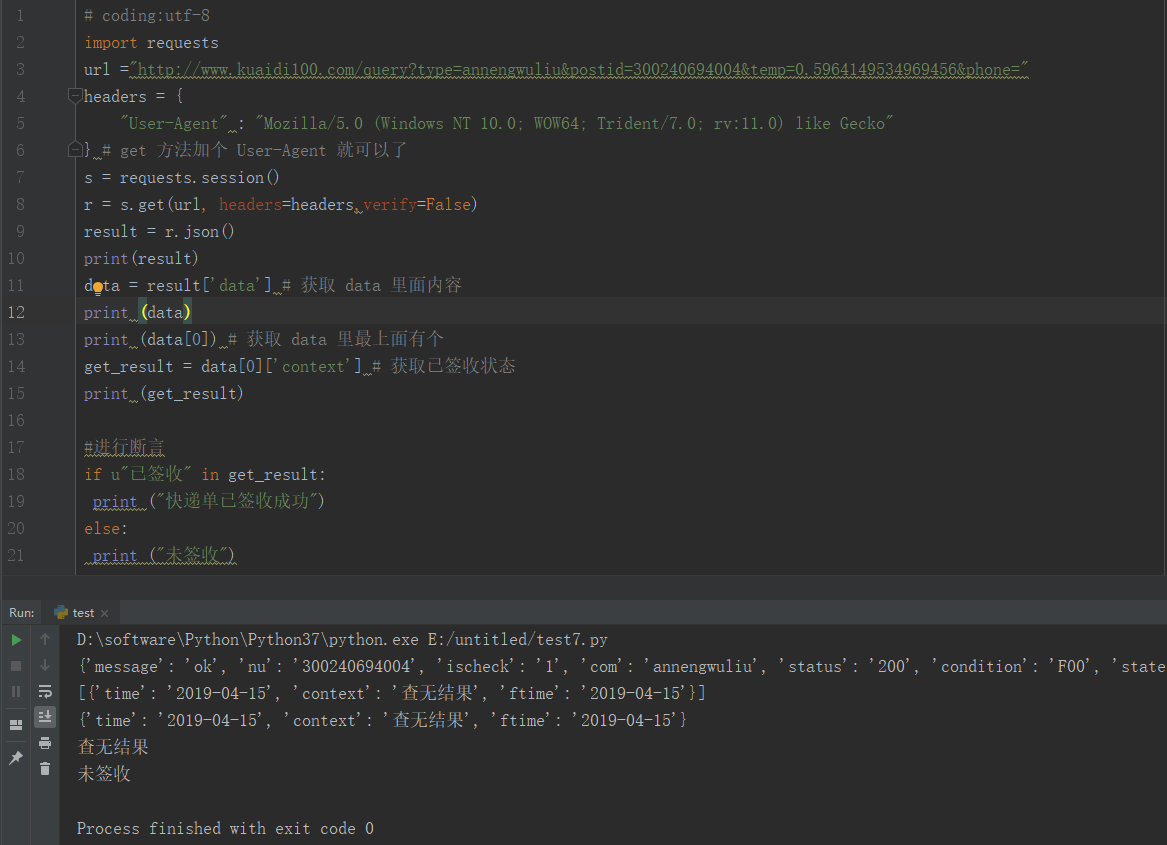
对我们爬取的URL发包,并对数据包进行处理,提取我们需要的数据
二、代码实现
目标1:对于捕获的URL内嵌发包
for u in [link]:
html2 = get_page(u)
soup2 = BeautifulSoup(html2, 'lxml')
email_phone_div = soup2.find('div', attrs={'class': 'index_detail__JSmQM'})目标2:找到电话和邮箱的位置
(1)找到他的上一级(也就是都包含他们的)

for u in [link]:
html2 = get_page(u)
soup2 = BeautifulSoup(html2, 'lxml')
email_phone_div = soup2.find('div', attrs={'class': 'index_detail__JSmQM'})目标3:提取电话和邮箱
(1)首先加一个if判空
把phone和email的上一级进行判空,不为空再继续

if email_phone_div is not None:
phone_div = email_phone_div.find('div', attrs={'class': 'index_first__3b_pm'})
email_div = email_phone_div.find('div', attrs={'class': 'index_second__rX915'})
#中间为提取email和phone代码
else:
phone = ''
email = ''
#遍历一遍就写入一个数据
csv_w.writerow((title.strip(), link, type_texts, money, email, phone))
(2)对phone进行提取
首先也是对上一级标签判空,不为空才继续

if phone_div is not None:
phone_element = phone_div.find('span', attrs={'class': 'link-hover-click'})
if phone_element is not None:
phone = phone_element.find('span',attrs={'class':'index_detail-tel__fgpsE'}).text
else:
phone = ''
else:
phone = ''(3)对email提取
和phone一样先对上一级判空,不为空再继续提取

if email_div is not None:
email_element = email_div.find('span', attrs={'class': 'index_detail-email__B_1Tq'})
if email_element is not None:
email = email_element.text
else:
email = ''
else:
email = ''(3)对内嵌请求处理的完整代码
for u in [link]:
html2 = get_page(u)
soup2 = BeautifulSoup(html2, 'lxml')
email_phone_div = soup2.find('div', attrs={'class': 'index_detail__JSmQM'})
if email_phone_div is not None:
phone_div = email_phone_div.find('div', attrs={'class': 'index_first__3b_pm'})
email_div = email_phone_div.find('div', attrs={'class': 'index_second__rX915'})
if phone_div is not None:
phone_element = phone_div.find('span', attrs={'class': 'link-hover-click'})
if phone_element is not None:
phone = phone_element.find('span',attrs={'class':'index_detail-tel__fgpsE'}).text
else:
phone = ''
else:
phone = ''
if email_div is not None:
email_element = email_div.find('span', attrs={'class': 'index_detail-email__B_1Tq'})
if email_element is not None:
email = email_element.text
else:
email = ''
else:
email = ''
else:
phone = ''
email = ''
csv_w.writerow((title.strip(), link, type_texts, money, email, phone))三、完整代码
运行结果
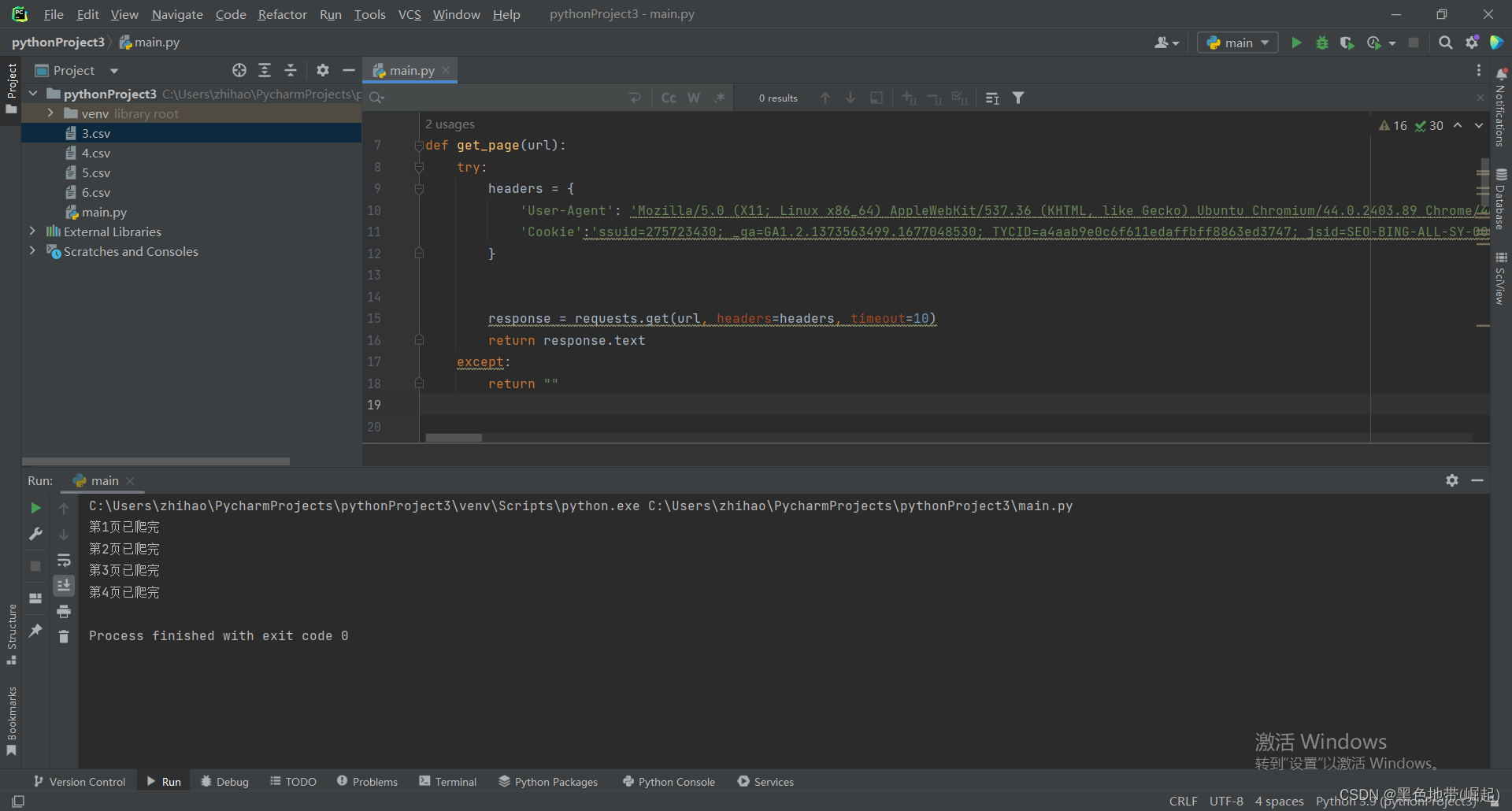
爬取写入的数据

(cookie需要填上自己的)
import time
import requests
import csv
from bs4 import BeautifulSoup
def get_page(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/44.0.2403.89 Chrome/44.0.2403.89 Safari/537.36',
'Cookie':'!!!!!!!!!'
}
response = requests.get(url, headers=headers, timeout=10)
return response.text
except:
return ""
def get_TYC_info(page):
TYC_url = f"https://www.tianyancha.com/search?key=&sessionNo=1688538554.71584711&base=hub&cacheCode=00420100V2020&city=wuhan&pageNum={page}"
html = get_page(TYC_url)
soup = BeautifulSoup(html, 'lxml')
GS_list = soup.find('div', attrs={'class': 'index_list-wrap___axcs'})
GS_items = GS_list.find_all('div', attrs={'class': 'index_search-box__7YVh6'})
for item in GS_items:
title = item.find('div', attrs={'class': 'index_name__qEdWi'}).a.span.text
link = item.a['href']
company_type_div = item.find('div', attrs={'class': 'index_tag-list__wePh_'})
if company_type_div is not None:
company_type = company_type_div.find_all('div', attrs={'class': 'index_tag-common__edIee'})
type_texts = [element.text for element in company_type]
else:
type_texts = ''
money = item.find('div', attrs={'class': 'index_info-col__UVcZb index_narrow__QeZfV'}).span.text
for u in [link]:
html2 = get_page(u)
soup2 = BeautifulSoup(html2, 'lxml')
email_phone_div = soup2.find('div', attrs={'class': 'index_detail__JSmQM'})
if email_phone_div is not None:
phone_div = email_phone_div.find('div', attrs={'class': 'index_first__3b_pm'})
email_div = email_phone_div.find('div', attrs={'class': 'index_second__rX915'})
if phone_div is not None:
phone_element = phone_div.find('span', attrs={'class': 'link-hover-click'})
if phone_element is not None:
phone = phone_element.find('span',attrs={'class':'index_detail-tel__fgpsE'}).text
else:
phone = ''
else:
phone = ''
if email_div is not None:
email_element = email_div.find('span', attrs={'class': 'index_detail-email__B_1Tq'})
if email_element is not None:
email = email_element.text
else:
email = ''
else:
email = ''
else:
phone = ''
email = ''
csv_w.writerow((title.strip(), link, type_texts, money, email, phone))
if __name__ == '__main__':
with open('5.csv', 'a', encoding='utf-8', newline='') as f:
csv_w = csv.writer(f)
csv_w.writerow(('公司名', 'URL', '类型', '资金', '电子邮件', '电话号码'))
for page in range(1, 5):
get_TYC_info(page)
print(f'第{page}页已爬完')
time.sleep(2)
四、网络安全小圈子
README.md · 书半生/网络安全知识体系-实战中心 - 码云 - 开源中国 (gitee.com)![]() https://gitee.com/shubansheng/Treasure_knowledge/blob/master/README.md
https://gitee.com/shubansheng/Treasure_knowledge/blob/master/README.md
GitHub - BLACKxZONE/Treasure_knowledge![]() https://github.com/BLACKxZONE/Treasure_knowledge
https://github.com/BLACKxZONE/Treasure_knowledge


![[NISACTF 2022]babyserialize(pop链构造与脚本编写详细教学)](https://img-blog.csdnimg.cn/7e6dd74221c64fc8bc4ee615897ba358.png)