文章目录
- 前言
- 一、需求
- 二、分析
- 三、处理
- 四、运行效果
前言
为了更好的掌握数据处理的能力,因而开启Python网络爬虫系列小项目文章。
- 小项目小需求驱动,每篇文章会使用两种以上的方式(Xpath、Bs4、PyQuery、正则等)获取想要的数据。
- 博客系列完结后,将会总结各种方式。
一、需求
-
获取高校数据
- 高校排行(软科综合、校友会综合、武书连)
- 基本信息(博士点、硕士点、创建时间、占地面积、学校地址)
-
多种数据存储方式
-
本地文件存储
-
redis
-
MongoDB
-
二、分析
F12 打开抓包工具,刷新https://www.gaokao.cn/school/search接口页面
name.json 接口包含所有的高校id
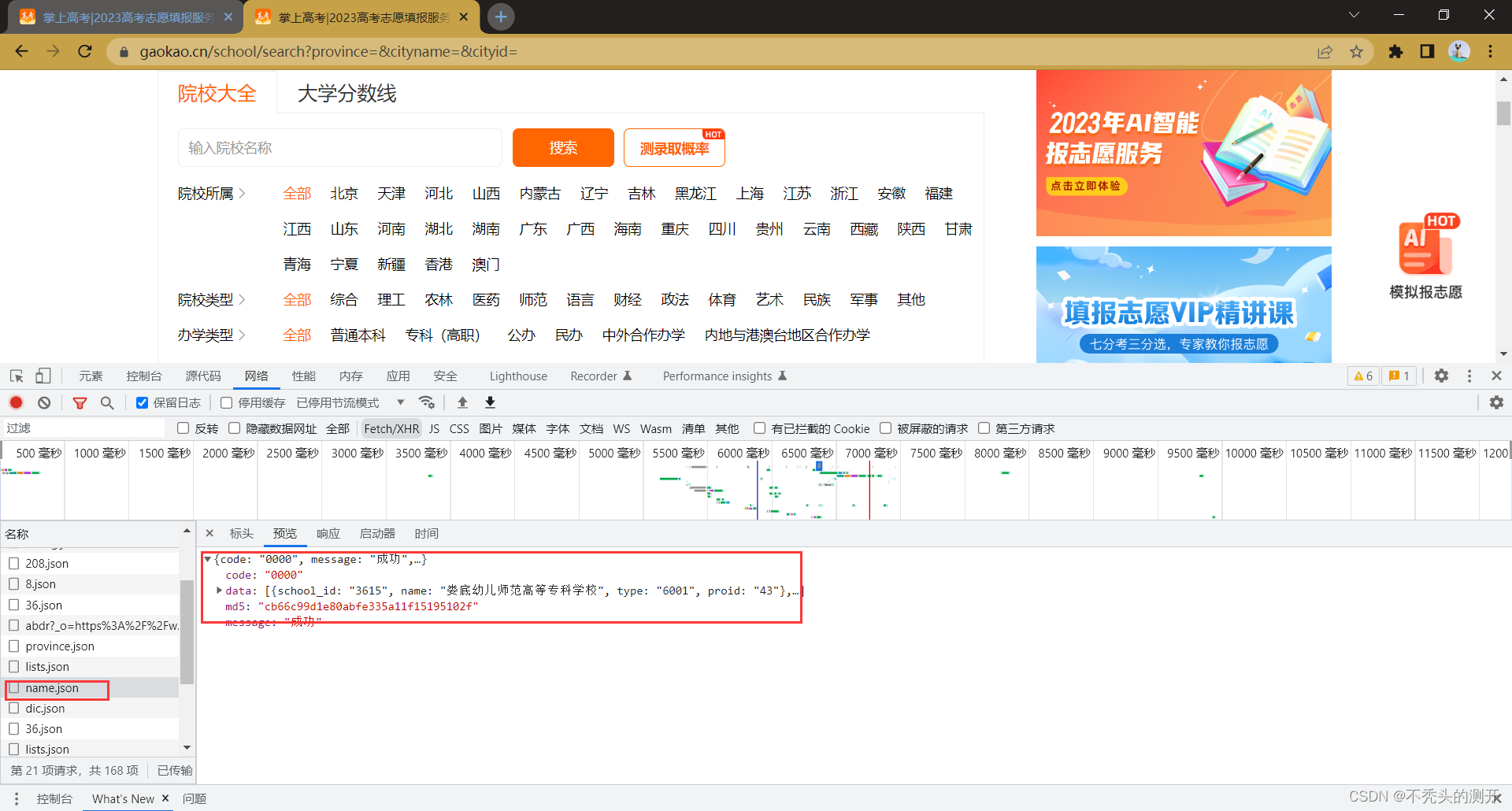
进入学校详情页,获取到info.json接口信息

数据可以直接通过请求接口即可返回
已获取学校id(一共2820个数据,可以用上协程异步访问提高获取的数据的速度)
已获取学校信息的接口https://static-gkcx.gaokao.cn/www/2.0/json/live/v2/school/102/info.json(只需要修改下学校id即可访问其它学校信息)
三、处理
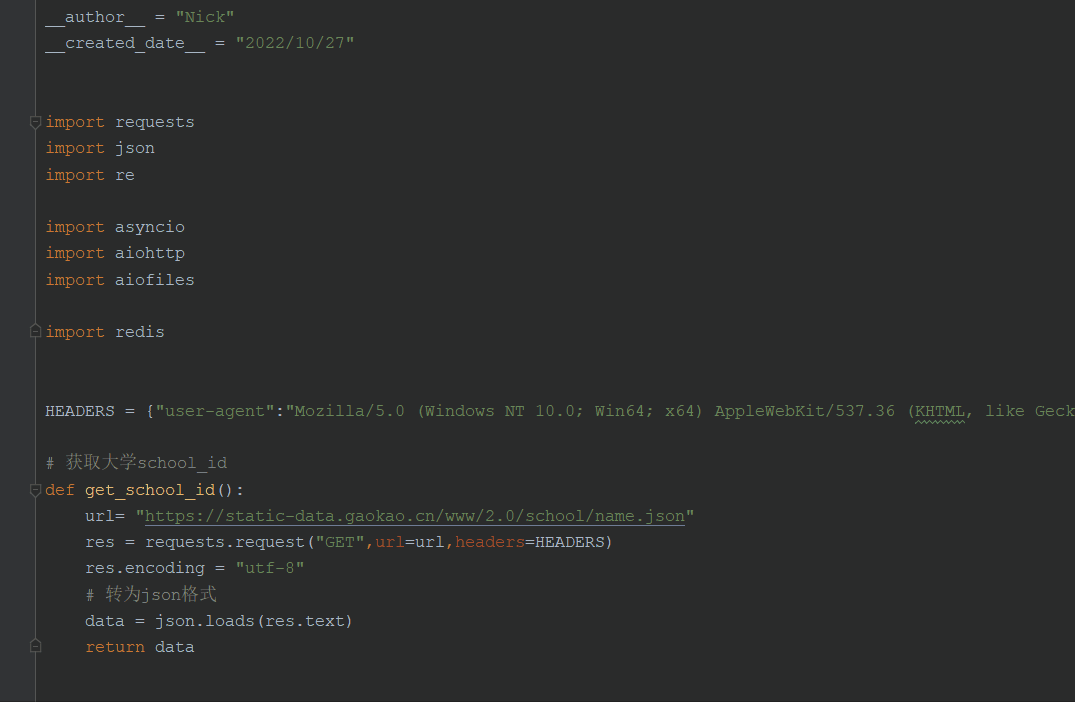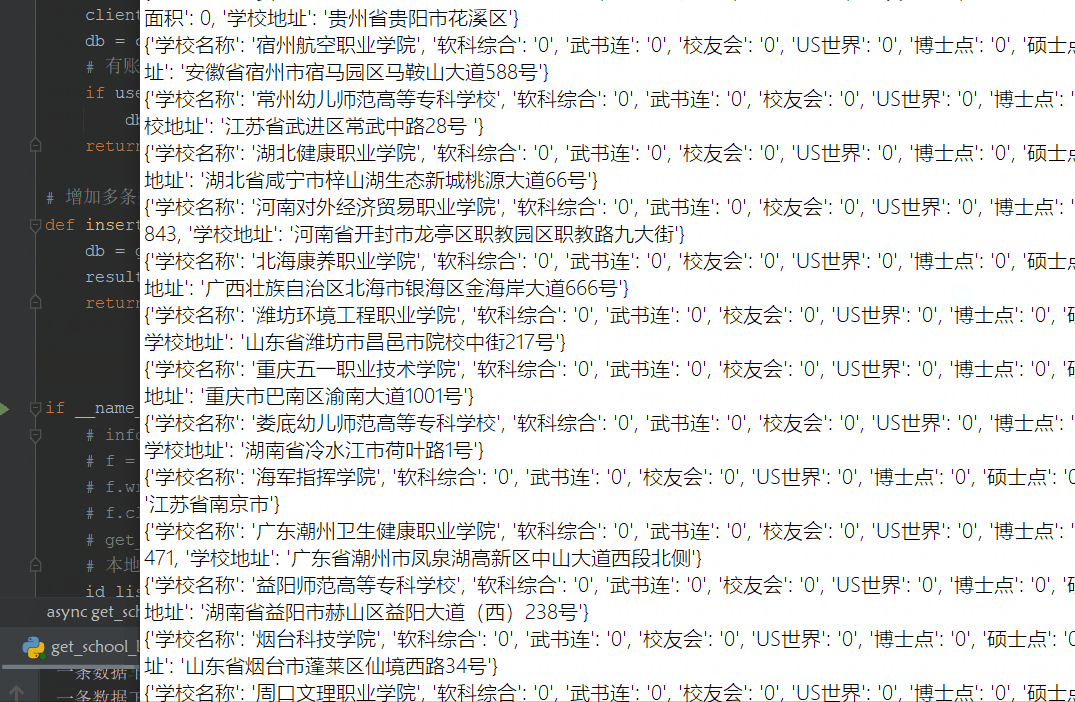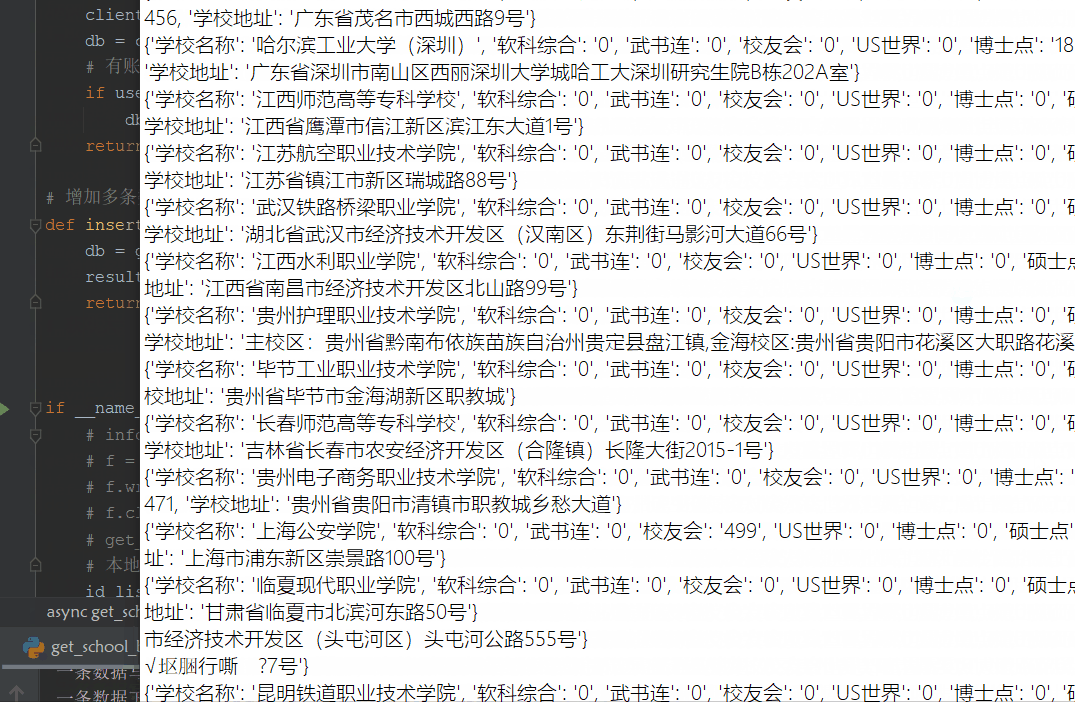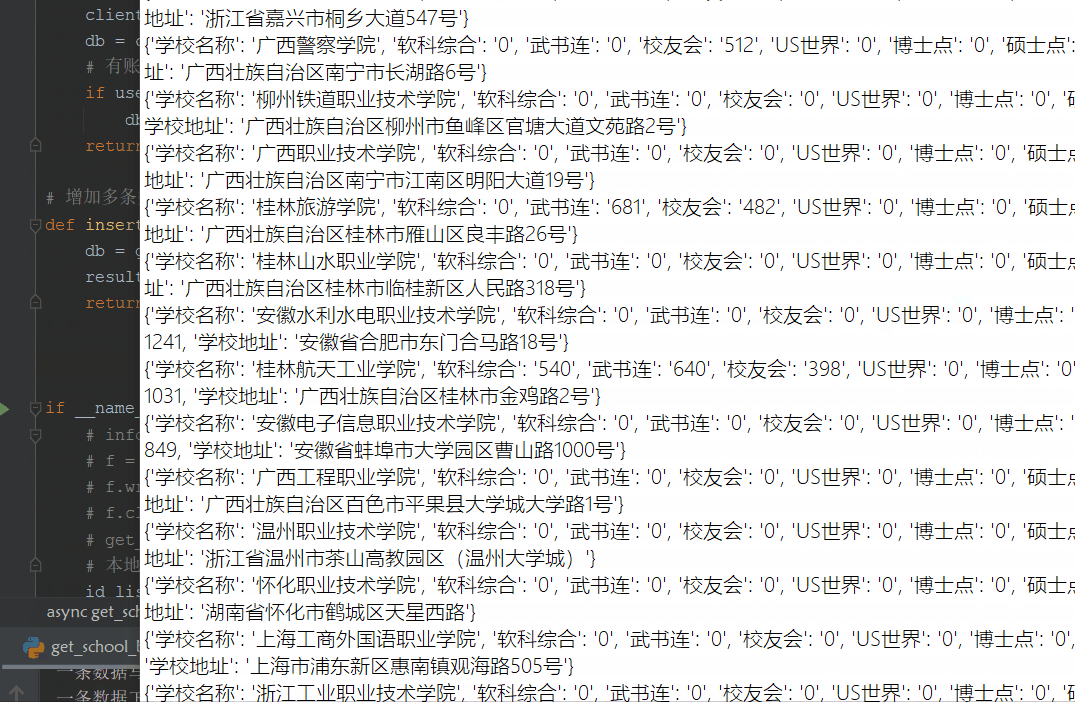
编写获取大学id的接口
import requests
import json
HEADERS = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"}
# 获取大学school_id
def get_school_id():
url= "https://static-data.gaokao.cn/www/2.0/school/name.json"
res = requests.request("GET",url=url,headers=HEADERS)
res.encoding = "utf-8"
# 转为json格式
data = json.loads(res.text)
return data
获取一次以后,本地可以进行处理提取学校id
import re
def get_id():
f = open("name.txt", "r", encoding="utf-8")
f1 = f.read()
deal = re.compile(r"'school_id': '(?P<id>.*?)'",re.S)
result = deal.findall(f1)
# print(len(result))
f.close()
return result
编写访问学校信息的接口请求
def get_school_info_1():
url = "https://static-data.gaokao.cn/www/2.0/school/3419/info.json"
res = requests.request("GET",url=url,headers=HEADERS)
res.encoding = "utf-8"
# 转为json格式
data = json.loads(res.text)
return data
协程异步访问接口请求(本地文件存储)
import asyncio
import aiohttp
import aiofiles
# 获取学校详细信息
async def get_school_info(url,sem):
try:
async with sem:
async with aiohttp.ClientSession() as session:
# 发送请求
async with session.get(url) as res:
# 读取数据
content = await res.text(encoding="utf-8")
data = json.loads(content)
# 高校排行- 软科综合/校友会排名/武书连/US世界
school_info = {}
school_info["学校名称"] = data["data"]["name"]
school_info["软科综合"] = data["data"]["ruanke_rank"]
school_info["武书连"] = data["data"]["wsl_rank"]
school_info["校友会"] = data["data"]["xyh_rank"]
school_info["US世界"] = data["data"]["us_rank"]
# 博士点/硕士点/国家重点学科
school_info["博士点"] = data["data"]["num_doctor"]
school_info["硕士点"] = data["data"]["num_master"]
school_info["国家重点学科"] = data["data"]["num_subject"]
# 创建时间/占地面积/学校地址
school_info["创建时间"] = data["data"]["create_date"]
school_info["占地面积"] = data["data"]["area"]
school_info["学校地址"] = data["data"]["address"]
# 写入文件
async with aiofiles.open("school_info.txt",mode="a") as f:
await f.write(f"{str(school_info)}\n")
print("一条数据下载完毕!")
except Exception as e:
print(e)
async def main(list_id):
# 添加信号量控制速度
sem = asyncio.Semaphore(100)
tasks = []
for i in list_id:
# https://static-data.gaokao.cn/www/2.0/school/3419/info.json
url = f"https://static-data.gaokao.cn/www/2.0/school/{i}/info.json"
# 创建任务
task = asyncio.create_task(get_school_info(url,sem))
tasks.append(task)
await asyncio.wait(tasks)
if __name__ == '__main__':
# 本地获取id
id_list = get_id()
asyncio.run(main(id_list))
写入Redis数据库,
如有报错DataError: Invalid input of type: ‘NoneType’. Convert to a byte, string or number first.
解决方法,降低redis版本 pip install redis==2.10.6
# 获取学校详细信息
async def get_school_info(url,sem):
try:
async with sem:
async with aiohttp.ClientSession() as session:
# 发送请求
async with session.get(url) as res:
# 读取数据
content = await res.text(encoding="utf-8")
data = json.loads(content,encoding="utf-8")
# 高校排行- 软科综合/校友会排名/武书连/US世界
school_info = {}
school_name = data["data"]["name"]
school_info["软科综合"] = data["data"]["ruanke_rank"]
school_info["武书连"] = data["data"]["wsl_rank"]
school_info["校友会"] = data["data"]["xyh_rank"]
school_info["US世界"] = data["data"]["us_rank"]
# 博士点/硕士点/国家重点学科
school_info["博士点"] = data["data"]["num_doctor"]
school_info["硕士点"] = data["data"]["num_master"]
school_info["国家重点学科"] = data["data"]["num_subject"]
# 创建时间/占地面积/学校地址
school_info["创建时间"] = data["data"]["create_date"]
school_info["占地面积"] = data["data"]["area"]
school_info["学校地址"] = data["data"]["address"]
# 写入redis文件中
r = connect_redis()
r.hset("school",school_name,json.dumps(school_info))
print("一条数据写入成功")
except Exception as e:
print(e)
# 连接Redis数据库
def connect_redis():
pool = redis.ConnectionPool(host="127.0.0.1", port=6379,db=3)
r = redis.Redis(connection_pool=pool)
return r
写入MongoDB数据库
import pymongo
from pymongo import MongoClient
# MongoDB数据库初始化
def get_db(database,user=None,pwd=None):
client = MongoClient(host="localhost",port=27017)
db = client[database]
# 有账号密码即验证
if user:
db.authenticate(user,pwd)
return db
# 增加多条数据
def insert_data_many(collection, data):
db = get_db("school")
result = db[collection].insert_many(data)
return result
async def get_s
chool_info(url,sem):
try:
async with sem:
async with aiohttp.ClientSession() as session:
# 发送请求
async with session.get(url) as res:
# 读取数据
content = await res.text(encoding="utf-8")
data = json.loads(content,encoding="utf-8")
# 高校排行- 软科综合/校友会排名/武书连/US世界
school_info = {}
school_info["学校名称"] = data["data"]["name"]
school_info["软科综合"] = data["data"]["ruanke_rank"]
school_info["武书连"] = data["data"]["wsl_rank"]
school_info["校友会"] = data["data"]["xyh_rank"]
school_info["US世界"] = data["data"]["us_rank"]
# 博士点/硕士点/国家重点学科
school_info["博士点"] = data["data"]["num_doctor"]
school_info["硕士点"] = data["data"]["num_master"]
school_info["国家重点学科"] = data["data"]["num_subject"]
# 创建时间/占地面积/学校地址
school_info["创建时间"] = data["data"]["create_date"]
school_info["占地面积"] = data["data"]["area"]
school_info["学校地址"] = data["data"]["address"]
insert_data_many("school",[school_info])
print("一条数据写入成功")
except Exception as e:
print(e)
四、运行效果
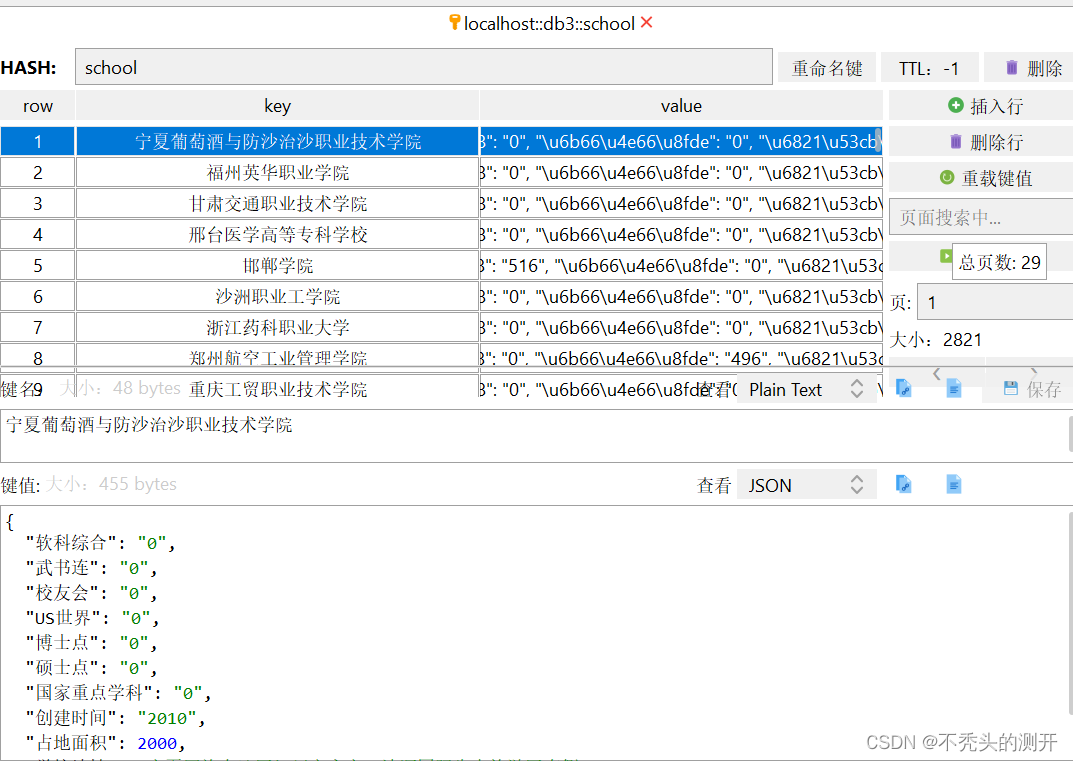
通过Redis可视化工具查看写入的2821条数据
MongoDB可视化工具查询数据
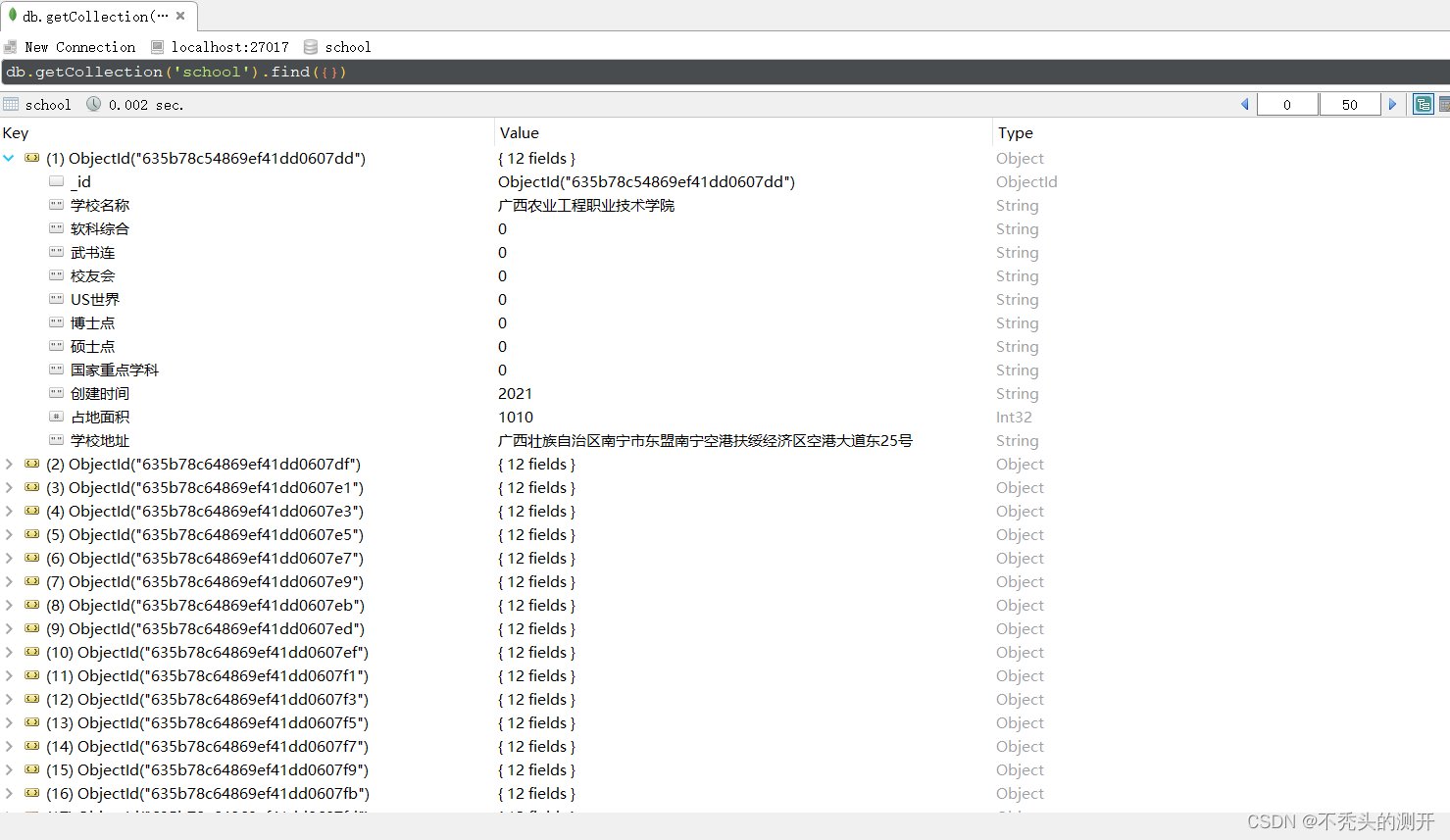
本地读取数据
完整源码文件附在在知识星球
我正在「Python^self-study」和朋友们讨论有趣的话题,你⼀起来吧?
https://t.zsxq.com/076uG3kOn


![git cherry-pick 报错 fatal: bad object [commitID]](https://img-blog.csdnimg.cn/cf0d8bf3ccdc4acf8c7625eefac4be82.png)
![[ Linux ] 一篇带你搞懂进程控制(看完可实现一个简易的shell)](https://img-blog.csdnimg.cn/img_convert/f8f45cd6960636c6ee9852d81635c1a1.png)