目录
一、二叉树的前序遍历
递归解法
非递归解法
二、二叉树的中序遍历
递归解法
非递归解法
三、二叉树的后序遍历
递归解法
非递归解法
默认情况下,一个线程的栈空间大小为8MB,当递归的深度太深,我们的程序就容易崩溃
如果递归的深度太深,栈空间不大,那么程序容易崩溃
#include <iostream>
using namespace std;
int f(int N)
{
if (N == 1)
return N;
return N + f(N - 1);
}
int main()
{
cout << f(1000000) << endl;
return 0;
}改成非递归
1.改成循环(比方说斐波那契)
2.通过栈改成循环
为什么递归会空间溢出,非递归不会空间溢出?
1.如果是循环的话,形成迭代,消耗的空间很可能是0(1)
2.如果使用的是通过栈来改成循环的话,我们栈的开辟的空间在内存的堆区
(内存中栈的空间不大,但是堆的空间很大,几乎不存在空间溢出的问题)
所以这里我们将递归的遍历改成非递归
一、二叉树的前序遍历
力扣
递归解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void preorderTraversal1(TreeNode* root){
if(root==nullptr)
{
return;
}
tmp.push_back(root->val);
preorderTraversal1(root->left);
preorderTraversal1(root->right);
}
vector<int> preorderTraversal(TreeNode* root) {
if(root==nullptr)
{
return tmp;
}
preorderTraversal1(root);
return tmp;
}
vector<int> tmp;
};非递归解法
二叉树的前序的顺序(根,左子树,右子树)
1.先访问左路结点
2.左路结点右子树
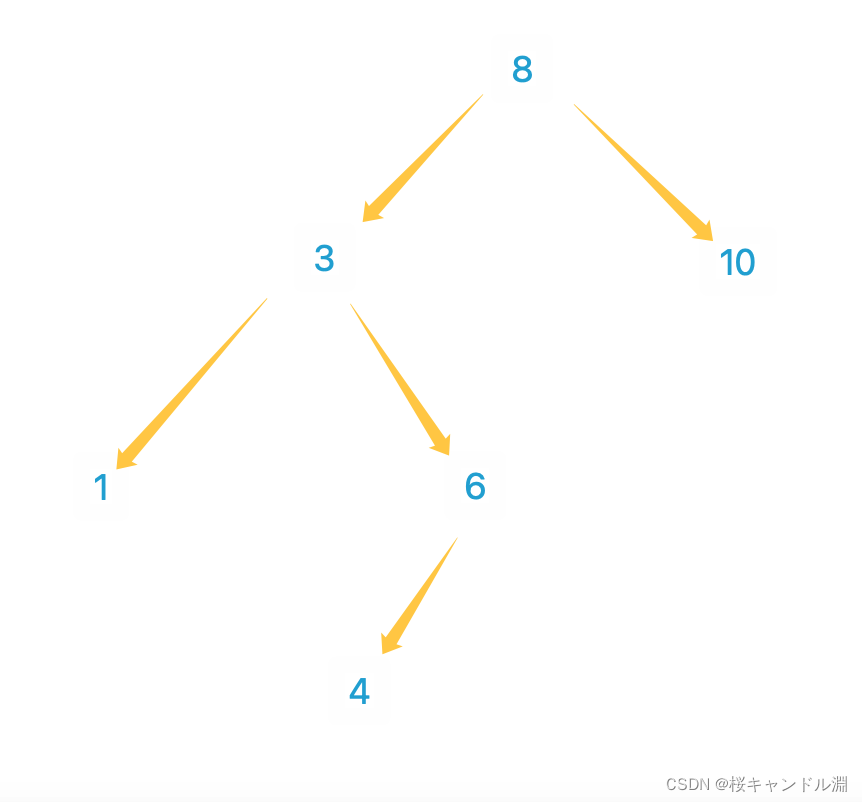
我们先访问左子树,然后我们按照顺序将8,3,1依次压入栈中,8位栈底,1为栈顶
那我们1没有左右子树,直接弹出,然后我们访问到3的时候,我们如何访问3的右树?
我们如何访问8的,我们就如何访问3
再拆成左路结点和右路节点,按照我们上面的说明的顺序进行访问。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
//创建一个辅助栈
stack<TreeNode*> st;
//创建一个容器v
vector<int> v;
//将cur指向我们的节点
//cur指向结点所代表的树
TreeNode* cur=root;
//cur不为空表示当前cur指向的树还没有访问
//栈不为空表示当前树的右子树还没有访问(栈中的结点的右子树都没有访问)
//所以这两个条件只要有一个没有满足就要继续进行循环
while(cur||!st.empty())
{
//开始访问一棵树
//1.左路结点
while(cur)
{
//将前序遍历的结果压入我们的容器中
v.push_back(cur->val);
//将左路结点放入栈中
st.push(cur);
//不断想左路进行遍历
cur=cur->left;
}
//左路结点的右子树需要访问
//所以我们从栈顶取出我们的栈顶元素,访问其右子树
TreeNode* top=st.top();
st.pop();
cur=top->right;//子问题访问右子树
}
return v;
}
};一个结点从栈里面出来,代表着这个结点以及它的左子树访问完了,还剩右节点

二、二叉树的中序遍历
力扣
递归解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void inorderTraversal1(TreeNode*root){
if(root==nullptr)
{
return;
}
inorderTraversal(root->left);
tmp.push_back(root->val);
inorderTraversal(root->right);
}
vector<int> inorderTraversal(TreeNode* root) {
if(root==nullptr)
{
return tmp;
}
inorderTraversal1(root);
return tmp;
}
vector <int> tmp;
};非递归解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
//创建一个辅助栈
stack<TreeNode*> st;
//创建一个容器v
vector<int> v;
//将cur指向我们的根节点
TreeNode* cur=root;
//cur不为空表示当前cur指向的树还没有访问
//栈不为空表示当前树的右子树还没有访问(栈中的结点的右子树都没有访问)
//所以这两个条件只要有一个没有满足就要继续进行循环
while(cur||!st.empty())
{
//开始访问一棵树
//1.左路结点
while(cur)
{
//不断向左路进行遍历
st.push(cur);
cur=cur->left;
}
//左路结点的右子树需要访问
//所以我们从栈顶取出我们的栈顶元素,访问其右子树
TreeNode* top=st.top();
//中序相较于前序就是将结点的数据压入vector的时候放在这个位置
//也就是先将左子树遍历完,全部入栈之后,在出栈的时候,将取出的结点的值追加到我们的vector中
v.push_back(top->val);
st.pop();
cur=top->right;//子问题访问右子树
}
return v;
}
};
前序遍历和中序遍历仅仅是访问根节点的时机不同,代码上也就仅仅是下面的区别
当左路结点从栈中出来,表示左子树已经访问过了,应该访问这个结点和他的右子树了。

三、二叉树的后序遍历
力扣
递归解法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void postorderTraversal1(TreeNode* root) {
if(root==nullptr)
{
return;
}
postorderTraversal1(root->left);
postorderTraversal1(root->right);
tmp.push_back(root->val);
}
vector<int> postorderTraversal(TreeNode* root) {
if(root==nullptr)
{
return tmp;
}
postorderTraversal1(root);
return tmp;
}
vector<int> tmp;
};非递归解法
后序遍历是先左子树,然后右子树,然后才是根结点
我们栈中的结点元素仅仅是能保证这个元素的左子树已经被访问过了,所以我们在取出栈顶元素的时候,只有这个结点的右子树也被访问过了,才能从栈中弹出
比方说我们上面这张图中,依次将8,3,1入栈,1的右子树为空,所以1可以出栈,
栈变成8->3
但是哦我们这里的的3,也就是我们的栈顶元素的右子树不是空,并且没有被访问过,所以不能直接弹出,也就是我们的3不能访问
此时我们将我们的指针指向3的右节点,然后将cur入栈
此时我们的栈变成了8->3->6->
然后6有左节点,所以左节点也入栈
8->3->6->4
4因为没有右节点,所以4可以出栈,代表我们的4这个结点可以访问了。
然后我们看此时栈顶的6,6的左已经被访问过了,6的右节点为空,可以弹出了
然后此时栈顶的元素为3,3的右节点已经被访问过了,所以我们的3也可以被弹出了!也就是我们的3也可以被访问了!
但是我们这里的3第一次访问的时候右节点没有被访问,我们需要去访问,然后我们第二次去访问3的时候,我们的3的右子树已经被访问过了,我们应该如何区分这两次不同的访问呢?
我们可以设置标志位,来标记我们已经访问过这个节点了,但是我们并不知道这样有右子树的结点有多少个,我们如果真的要记录的话,就需要为每一个这样有右树的结点都设置一个标记位。
也就是可以使用一个map,来标记这个结点,map<TreeNode*,int>,来记录访问的次数
但是我们这样为了一个二叉树还要调用另外一个数据结构,就非常麻烦,有没有别的方法呢?
一个结点的右不为空的情况下:
1.如果右子树没有访问,访问右子树
2.如果右子树已经访问过了,访问根节点
第一次到3的时候,上一个访问的结点是1
但是我们第二次访问到3的时候,上一个访问的是6
其实我们可以设置一个前置的标记。
如果我们的访问的当前结点的前置结点就是我们当前结点的右子树,
那么救说明我们当前结点的右子树已经被访问过了!
这样的话,上面的两种情况就可以靠这个前置指针来区分开来了!
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
//创建一个辅助栈
stack<TreeNode*> st;
//将我们的当前访问的结点的前置结点初始化为空
TreeNode* prev=nullptr;
//创建一个容器v
vector<int> v;
//将cur指向我们的根节点
TreeNode* cur=root;
//cur不为空表示当前cur指向的树还没有访问
//栈不为空表示当前树的右子树还没有访问(栈中的结点的右子树都没有访问)
//所以这两个条件只要有一个没有满足就要继续进行循环
while(cur||!st.empty())
{
//开始访问一棵树
//1.左路结点
while(cur)
{
//将左路结点放入栈中
st.push(cur);
//不断想左路进行遍历
cur=cur->left;
}
//2.左路结点的右子树需要访问
//所以我们从栈顶取出我们的栈顶元素,访问其右子树
TreeNode* top=st.top();
//如果我们没有右子树
//或者我们上一个访问的结点是我们右子树的根(也就是说我们当前结点的右子树已经访问过了)
//按照我们上面的分析,也就是说我们当前的这个结点的左右子树都已经被访问过了,可以将这个点的输入加入我们的容器,然后出栈了
//栈顶结点右子树为空,或者上一节访问结点是有字数的根,说明右子树已经访问过了,可以访问这个栈顶结点
//否则 子问题访问top的右子树
if(top->right==nullptr||top->right==prev)
{
v.push_back(top->val);
//在我们访问下一个界定之前,让我们的前置指针先指向我们当前访问过的元素
prev=top;
cur=nullptr;
st.pop();
}
else
{
//
cur=top->right;//如果右边不为空,就访问右树
}
}
return v;
}
};
我们按照上面的说法,先依次将8->3->1入栈,1没有左右子树,直接弹出栈,然后我们当前的prev就是指向1的结点
然后我们判断3这个结点的有右子树,3有右子树,并且3的前置结点是1结点,并不是我们的6结点,所以我们3的右节点并没有访问过!
然后我们朝着右子树访问,将6入栈,
然后再将4入栈
这时我们的4已经没有左右子树了,我们的4将被弹出栈,然后我们的prev就指向我们的4
然后对于6,6的右节点为空,所以6即将被弹出,我们的prev就指向我们的6
然后对于我们的3结点,此刻我们的prev结点指向的是6,也就是我们的3的右节点!!!
也就是说,我们当前的3结点的右子树已经被访问过了,可以将3弹出了!
所以我们将3弹出,prev指针指向3
然后对于8,8有右子树,然后cur指向我们的10
10没有右子树,然后我们的10就出栈了,
此时我们的prev指向了10这个结点
然后我们栈中还剩下8这个结点,此时的prev指针为10,也就是我们8的右子树的结点,所以我们的8这个结点的左右子树都已经完成了访问,所以我们的8也可以出栈了!


![git cherry-pick 报错 fatal: bad object [commitID]](https://img-blog.csdnimg.cn/cf0d8bf3ccdc4acf8c7625eefac4be82.png)
![[ Linux ] 一篇带你搞懂进程控制(看完可实现一个简易的shell)](https://img-blog.csdnimg.cn/img_convert/f8f45cd6960636c6ee9852d81635c1a1.png)