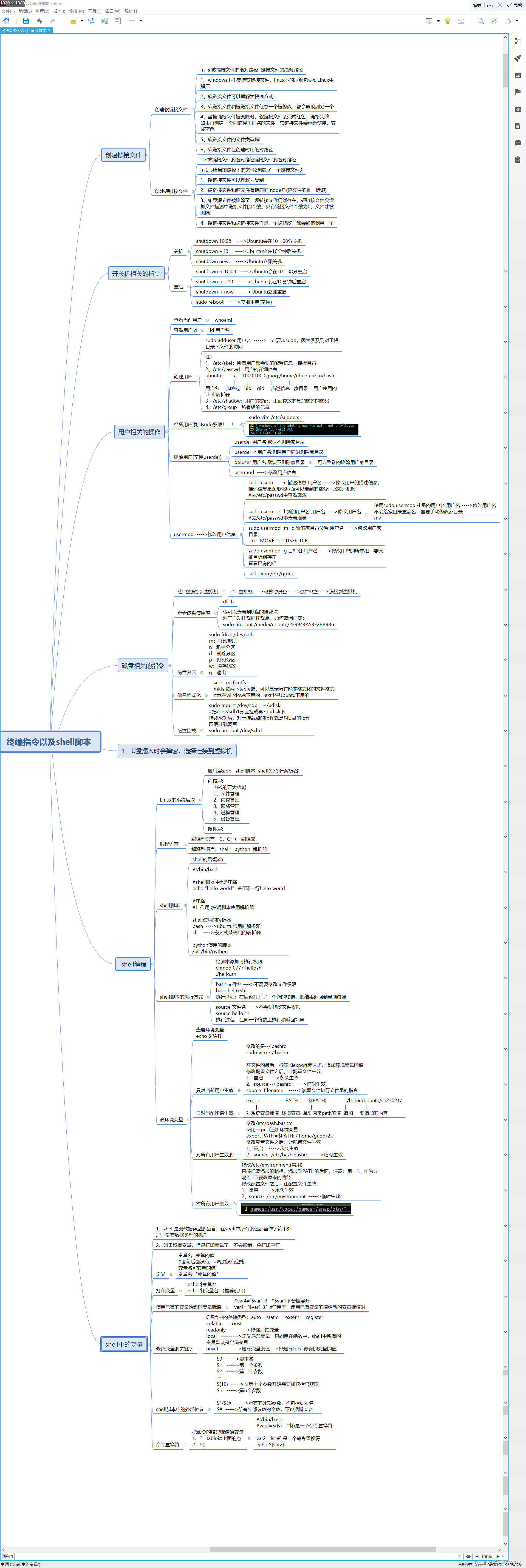
文章目录
- 1. 使用 LevelDB 作为索引的存储
- 2. 预先分配volume file的磁盘空间
- 3. 提高写并发
- 4. 提供读并发
- 5. 增加更多的硬盘驱动器
- 6. 提高用户打开文件的限制数
- 7. 内存消耗
- 7.1 内存中的索引
- 7.2 并发读
- 8. 当网络不稳定时
1. 使用 LevelDB 作为索引的存储
在启动Volume server时可以选择索引的存储类型,默认是内存。内存使得文件的访问非常快,但是在Volume server启动时需要花费很长的时间把索引从文件加载到内存。
可以通过weed volume -index=leveldb命令把索引的存储类型修改为leveldb,这使得Volume server可以快速的启动起来,当然访问文件的速度会比使用内存时稍慢,但是与网络传输的速度相比,使用leveldb造成的额外开销不足一提。
leveldb作为索引的存储有三种选项:
leveldb: 小内存占用(4MB total, 1 write buffer, 2 block buffers)leveldbMedium: 中等内存占用(8MB total, 2 write buffers, 4 block buffers)leveldbLarge: 大内存占用(12MB total, 4 write buffers, 8 block buffers)
2. 预先分配volume file的磁盘空间
预先分配磁盘空间,可以使得volume file的数据分布在邻近的block,当volume file很大时可以起到改善性能的作用。 可以支持预分配的Linux文件系统, e.g., XFS, ext4, Btrfs。
要开启磁盘空间预分配的功能,需要在Master 启动时指定以下参数
-volumePreallocate
Preallocate disk space for volumes.
-volumeSizeLimitMB uint
Master stops directing writes to oversized volumes. (default 30000)
3. 提高写并发
增加Volume的数量可以提高写并发,如:
curl http://localhost:9333/vol/grow?count=12&replication=001
4. 提供读并发
增加Volume的数量可以提高读并发,另外增加副本的数量以提高读并发。
5. 增加更多的硬盘驱动器
增加硬盘驱动器可以获得更高读写吞吐能力。
6. 提高用户打开文件的限制数
默认的用户打开文件的限制数是1024。来自网络的文件请求很容易就超过了这个限制。在生产环境使用时,建议用root账户把该限制数修改为更高的数值,例如:ulimit -n 10240。
7. 内存消耗
对于每个Volume server,以下两个方面会有内存有影响。
7.1 内存中的索引
默认情况下,Volume server使用内存来存储索引以实现复杂度为O(1) 的磁盘读取。每个文件大概会占用20 bytes的空间。如果1个30GB的Volume存储百万个平均30KB大小的文件,则需要消耗20MB的内存空间来存储索引。可以使用leveldb来存储索引以减少内存的消耗以及加快启动的速度。
7.2 并发读
1000并发读100KB大小的文件需要100MB的内存。
8. 当网络不稳定时
因网络原因造成读取缓慢时会阻塞其他的请求,例如写请求。
把volume.hasSlowRead 设置为true可以避免慢读取引起的阻塞问题,但是会增加大文件读取时的P99延迟问题。
提高volume.readBufferSizeMB可以减少读请求的锁次数,修复volume.hasSlowRead 引起的P99延迟问题。