牛客网算法八股刷题系列——K-Means真题描述
- 题目描述
- 正确答案: A \mathcal A A
- 题目解析
题目描述
两个种子点 A ( − 1 , 1 ) , B ( 2 , 1 ) A(-1,1),B(2,1) A(−1,1),B(2,1),其余样本点为 ( 0 , 0 ) , ( 0 , 2 ) , ( 1 , 1 ) , ( 3 , 2 ) , ( 6 , 0 ) , ( 6 , 2 ) (0,0),(0,2),(1,1),(3,2),(6,0),(6,2) (0,0),(0,2),(1,1),(3,2),(6,0),(6,2)。利用 K-Means \text{K-Means} K-Means算法,点群中心按坐标平均计算。最终:
- 种子点 A A A需要移动的次数;
- 种子点 B B B需要移动的次数;
- 属于种子点 A A A的样本点数(不含 A A A);
- 属于种子点 B B B的样本点数(不含 B B B);
分别是 ( ) (\quad) ()
A
2
,
2
,
3
,
3
\mathcal A \quad 2,2,3,3
A2,2,3,3
B
1
,
1
,
3
,
3
\mathcal B \quad 1,1,3,3
B1,1,3,3
C
1
,
1
,
2
,
4
\mathcal C \quad 1,1,2,4
C1,1,2,4
D
2
,
2
,
2
,
4
\mathcal D \quad 2,2,2,4
D2,2,2,4
正确答案: A \mathcal A A
题目解析
初始状态下,上述样本点(蓝色点)与种子点(橙色点)之间的位置关系表示如下:

针对种子点
A
,
B
\mathcal A,\mathcal B
A,B,分别求出各自对应其他样本点的距离:
这里以‘欧式距离’计算点之间的距离信息,以A A A与样本点a 1 : ( 0 , 0 ) a_1:(0,0) a1:(0,0)之间距离为例,后续同理:
Dist A ⇔ a 1 = ( − 1 − 0 ) 2 + ( 1 − 0 ) 2 = 2 \text{Dist}_{A \Leftrightarrow a_1} = \sqrt{(-1 -0)^2 + (1 - 0)^2} = \sqrt{2} DistA⇔a1=(−1−0)2+(1−0)2=2由于计算过程中不包含A , B A,B A,B点,这里直接将它们视作‘虚拟样本’
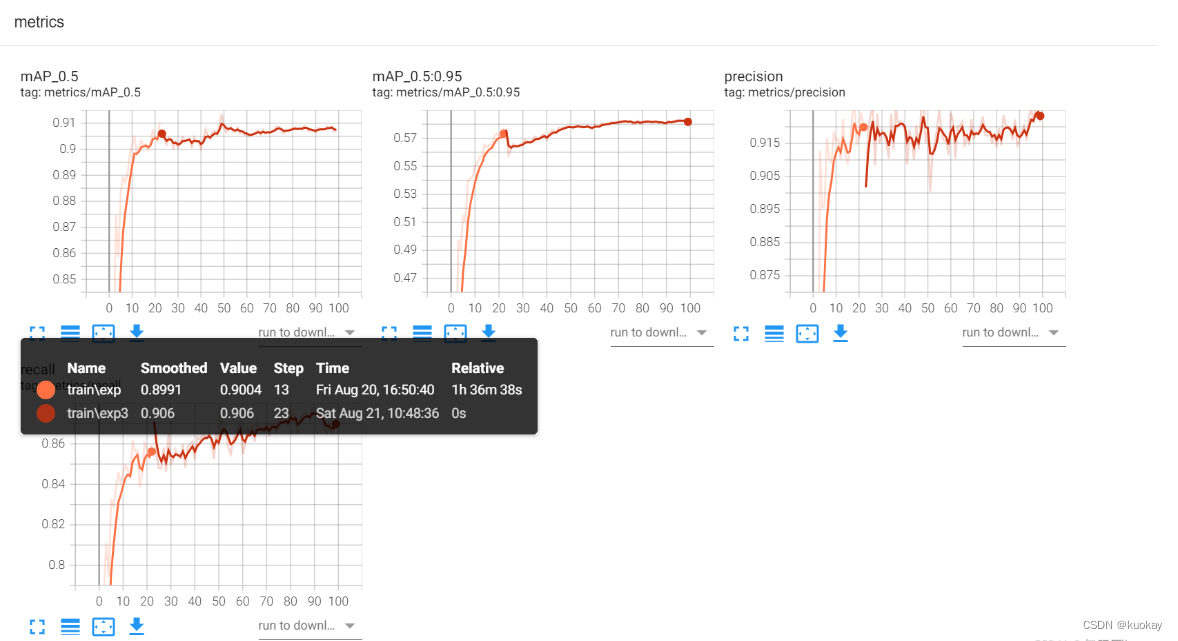
| SamplePoint/InitialCenter \text{SamplePoint/InitialCenter} SamplePoint/InitialCenter | A A A | B B B | ClusterResult \text{ClusterResult} ClusterResult |
|---|---|---|---|
| a 1 : ( 0 , 0 ) a_1:(0,0) a1:(0,0) | 2 \sqrt{2} 2 | 3 \sqrt{3} 3 | A A A |
| a 2 : ( 0 , 2 ) a_2:(0,2) a2:(0,2) | 2 \sqrt{2} 2 | 5 \sqrt{5} 5 | A A A |
| a 3 : ( 1 , 1 ) a_3:(1,1) a3:(1,1) | 2 2 2 | 1 1 1 | B B B |
| a 4 : ( 3 , 2 ) a_4:(3,2) a4:(3,2) | 17 \sqrt{17} 17 | 2 \sqrt{2} 2 | B B B |
| a 5 : ( 6 , 0 ) a_5:(6,0) a5:(6,0) | 50 \sqrt{50} 50 | 17 \sqrt{17} 17 | B B B |
| a 6 : ( 6 , 2 ) a_6:(6,2) a6:(6,2) | 50 \sqrt{50} 50 | 17 \sqrt{17} 17 | B B B |
至此,能够得到距离种子点
A
A
A近的样本点集合
A
n
e
a
r
A_{near}
Anear和距离种子点
B
B
B近的样本点集合
B
n
e
a
r
B_{near}
Bnear:
{
A
n
e
a
r
:
{
a
1
,
a
2
}
B
n
e
a
r
:
{
a
3
,
a
4
,
a
5
,
a
6
}
\begin{cases} A_{near}: \{a_1,a_2\} \\ B_{near}: \{a_3,a_4,a_5,a_6\} \end{cases}
{Anear:{a1,a2}Bnear:{a3,a4,a5,a6}
新的点群中心坐标的计算结果表示如下:
{
a
1.
x
+
a
2.
x
2
=
0
+
0
2
=
0
a
1.
y
+
a
2.
y
2
=
0
+
2
2
=
1
A
1
:
(
0
,
1
)
{
a
3.
x
+
a
4.
x
+
a
5.
x
+
a
6.
x
4
=
1
+
3
+
6
+
6
4
=
4
a
3.
y
+
a
4.
y
+
a
5.
y
+
a
6.
y
4
=
1
+
2
+
0
+
2
4
=
1.25
B
1
:
(
4
,
1.25
)
\begin{aligned} & \begin{cases} \begin{aligned}\frac{a_{1.x} + a_{2.x}}{2} = \frac{0 + 0}{2} = 0\end{aligned} \\ \begin{aligned} \frac{a_{1.y} + a_{2.y}}{2} = \frac{0 + 2}{2} = 1 \end{aligned} \end{cases} \quad A_1:(0,1) \\ & \begin{cases} \begin{aligned}\frac{a_{3.x} + a_{4.x} + a_{5.x} + a_{6.x}} {4} = \frac{1 + 3 + 6 + 6}{4} = 4\end{aligned} \\ \begin{aligned} \frac{a_{3.y} + a_{4.y} + a_{5.y} + a_{6.y}}{4} = \frac{1 + 2 + 0 + 2}{4} = 1.25 \end{aligned} \end{cases} \quad B_1:(4,1.25) \end{aligned}
⎩
⎨
⎧2a1.x+a2.x=20+0=02a1.y+a2.y=20+2=1A1:(0,1)⎩
⎨
⎧4a3.x+a4.x+a5.x+a6.x=41+3+6+6=44a3.y+a4.y+a5.y+a6.y=41+2+0+2=1.25B1:(4,1.25)
此时已经得到新的种子点
A
1
,
B
1
A_1,B_1
A1,B1,新的位置关系表示如下:

重新执行上面的步骤:
针对种子点
A
1
,
B
1
A_1,B_1
A1,B1,分别求出各自对应其他样本点的距离:
| SamplePoint/InitialCenter \text{SamplePoint/InitialCenter} SamplePoint/InitialCenter | A 1 A_1 A1 | B 1 B_1 B1 | ClusterResult \text{ClusterResult} ClusterResult |
|---|---|---|---|
| a 1 : ( 0 , 0 ) a_1:(0,0) a1:(0,0) | 1 1 1 | > 1 >1 >1 | A 1 A_1 A1 |
| a 2 : ( 0 , 2 ) a_2:(0,2) a2:(0,2) | 1 1 1 | > 1 >1 >1 | A 1 A_1 A1 |
| a 3 : ( 1 , 1 ) a_3:(1,1) a3:(1,1) | 1 1 1 | > 1 >1 >1 | A 1 A_1 A1 |
| a 4 : ( 3 , 2 ) a_4:(3,2) a4:(3,2) | > 5 4 \begin{aligned}>\frac{5}{4}\end{aligned} >45 | 5 4 \begin{aligned}\frac{5}{4}\end{aligned} 45 | B 1 B_1 B1 |
| a 5 : ( 6 , 0 ) a_5:(6,0) a5:(6,0) | > 89 4 \begin{aligned}>\frac{\sqrt{89}}{4}\end{aligned} >489 | 89 4 \begin{aligned}\frac{\sqrt{89}}{4}\end{aligned} 489 | B 1 B_1 B1 |
| a 6 : ( 6 , 2 ) a_6:(6,2) a6:(6,2) | > 73 4 \begin{aligned}>\frac{\sqrt{73}}{4}\end{aligned} >473 | 73 4 \begin{aligned}\frac{\sqrt{73}}{4}\end{aligned} 473 | B 1 B_1 B1 |
能够得到距离种子点
A
1
A_1
A1近的样本点集合
A
1
⇒
n
e
a
r
A_{1\Rightarrow near}
A1⇒near和距离种子点
B
1
B1
B1近的样本点集合
B
1
⇒
n
e
a
r
B_{1 \Rightarrow near}
B1⇒near:
{
A
1
⇒
n
e
a
r
:
{
a
1
,
a
2
,
a
3
}
B
1
⇒
n
e
a
r
:
{
a
4
,
a
5
,
a
6
}
\begin{cases} A_{1 \Rightarrow near}: \{a_1,a_2,a_3\} \\ B_{1 \Rightarrow near}: \{a_4,a_5,a_6\} \end{cases}
{A1⇒near:{a1,a2,a3}B1⇒near:{a4,a5,a6}
此时发现新集合
A
1
⇒
n
e
a
r
,
B
1
⇒
n
e
a
r
A_{1 \Rightarrow near},B_{1 \Rightarrow near}
A1⇒near,B1⇒near中的样本点与初始状态的集合
A
n
e
a
r
,
B
n
e
a
r
A_{near},B_{near}
Anear,Bnear样本点存在差异,需要继续计算。新样本点的结果表示为
A
2
:
(
1
3
,
1
)
,
B
2
:
(
5
,
4
3
)
A_2:(\frac{1}{3},1),B_2:(5,\frac{4}{3})
A2:(31,1),B2:(5,34)
对应图像结果表示如下:

继续迭代。针对种子点 A 2 , B 2 A_2,B_2 A2,B2,分别求出各自对应其他样本点的距离:
| SamplePoint/InitialCenter \text{SamplePoint/InitialCenter} SamplePoint/InitialCenter | A 2 A_2 A2 | B 2 B_2 B2 | ClusterResult \text{ClusterResult} ClusterResult |
|---|---|---|---|
| a 1 : ( 0 , 0 ) a_1:(0,0) a1:(0,0) | 10 3 \begin{aligned}\frac{\sqrt{10}}{3}\end{aligned} 310 | > 10 3 \begin{aligned}>\frac{\sqrt{10}}{3}\end{aligned} >310 | A 2 A_2 A2 |
| a 2 : ( 0 , 2 ) a_2:(0,2) a2:(0,2) | 10 3 \begin{aligned}\frac{\sqrt{10}}{3}\end{aligned} 310 | > 10 3 \begin{aligned}>\frac{\sqrt{10}}{3}\end{aligned} >310 | A 2 A_2 A2 |
| a 3 : ( 1 , 1 ) a_3:(1,1) a3:(1,1) | 2 3 \begin{aligned}\frac{2}{3}\end{aligned} 32 | > 2 3 \begin{aligned}>\frac{2}{3}\end{aligned} >32 | A 2 A_2 A2 |
| a 4 : ( 3 , 2 ) a_4:(3,2) a4:(3,2) | > 10 2 3 \begin{aligned}>\frac{10\sqrt{2}}{3}\end{aligned} >3102 | 10 2 3 \begin{aligned}\frac{10\sqrt{2}}{3}\end{aligned} 3102 | B 2 B_2 B2 |
| a 5 : ( 6 , 0 ) a_5:(6,0) a5:(6,0) | > 5 3 \begin{aligned}>\frac{5}{3}\end{aligned} >35 | 5 3 \begin{aligned}\frac{5}{3}\end{aligned} 35 | B 2 B_2 B2 |
| a 6 : ( 6 , 2 ) a_6:(6,2) a6:(6,2) | > 13 3 \begin{aligned}>\frac{\sqrt{13}}{3}\end{aligned} >313 | 13 3 \begin{aligned}\frac{\sqrt{13}}{3}\end{aligned} 313 | B 2 B_2 B2 |
能够得到距离种子点
A
2
A_2
A2近的样本点集合
A
2
⇒
n
e
a
r
A_{2 \Rightarrow near}
A2⇒near和距离种子点
B
2
B_2
B2近的样本点集合
B
2
⇒
n
e
a
r
B_{2 \Rightarrow near}
B2⇒near:
{
A
2
⇒
n
e
a
r
:
{
a
1
,
a
2
,
a
3
}
B
2
⇒
n
e
a
r
:
{
a
4
,
a
5
,
a
6
}
\begin{cases} A_{2 \Rightarrow near}: \{a_1,a_2,a_3\} \\ B_{2 \Rightarrow near}: \{a_4,a_5,a_6\} \end{cases}
{A2⇒near:{a1,a2,a3}B2⇒near:{a4,a5,a6}
此时发现新集合
A
2
⇒
n
e
a
r
,
B
2
⇒
n
e
a
r
A_{2 \Rightarrow near},B_{2 \Rightarrow near}
A2⇒near,B2⇒near中的样本点与第一次迭代的集合
A
1
⇒
n
e
a
r
,
B
1
⇒
n
e
a
r
A_{1 \Rightarrow near},B_{1 \Rightarrow near}
A1⇒near,B1⇒near样本点相同,停止迭代。整个迭代过程中,种子点
A
,
B
A,B
A,B各移动两次,各种子点对应集合均包含
3
3
3个样本点。
A
\mathcal A \quad
A 选项正确。