卷积神经网络架构
图像识别
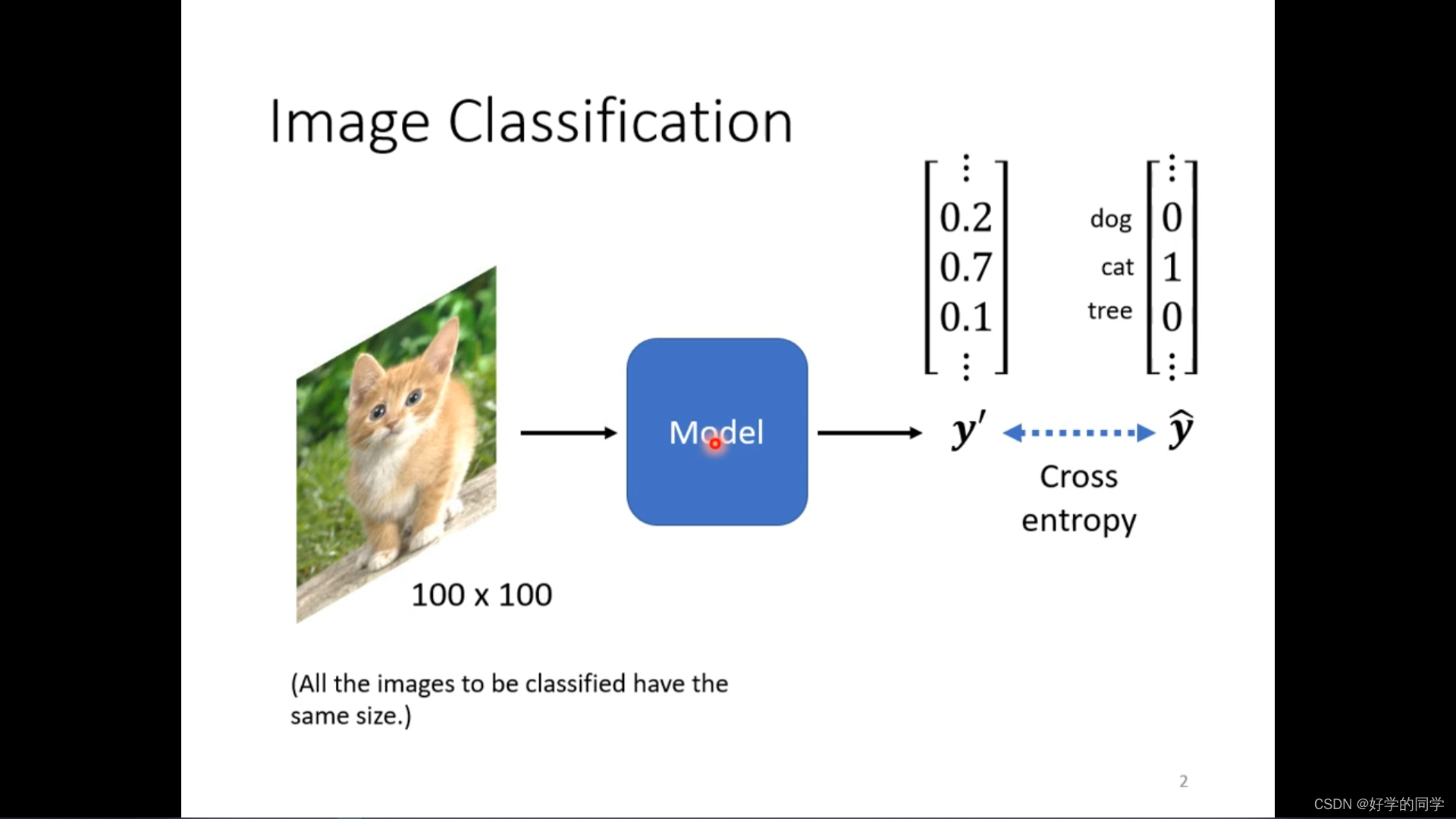
将图片拉直放入神经网络中进行训练。
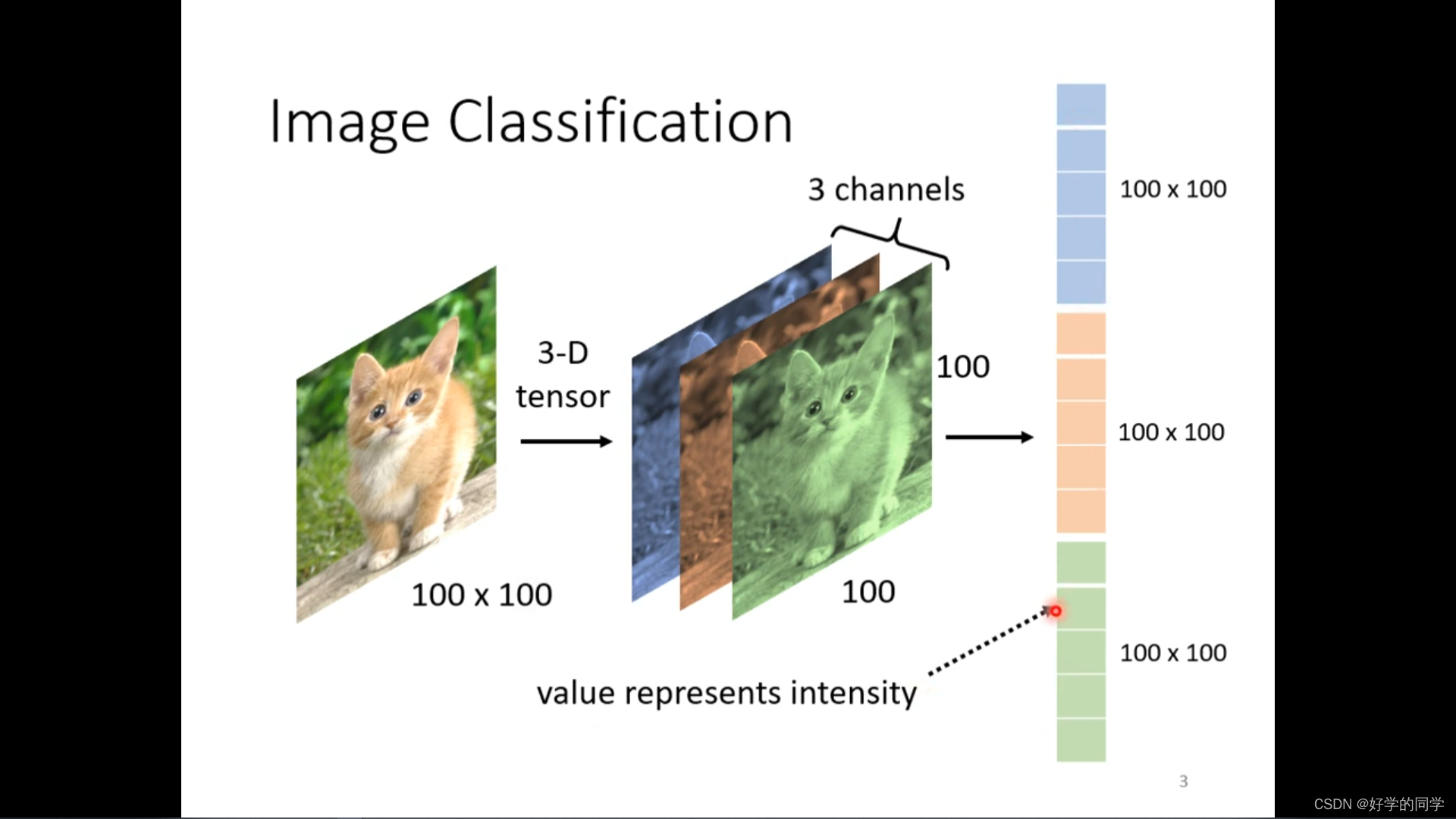
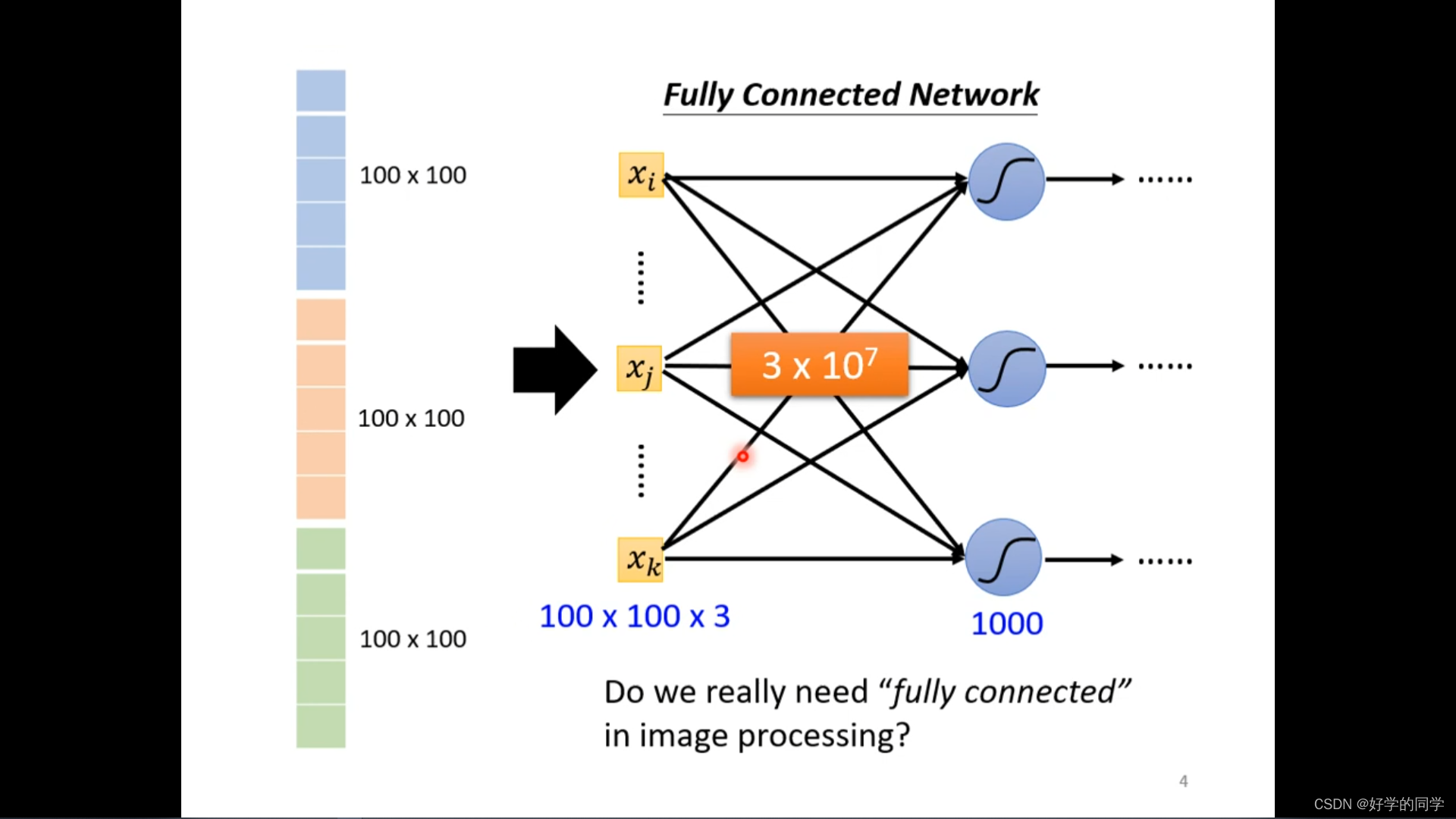
网络通过对图像中的存在的特征进行分析,判断当前属于何种类别。
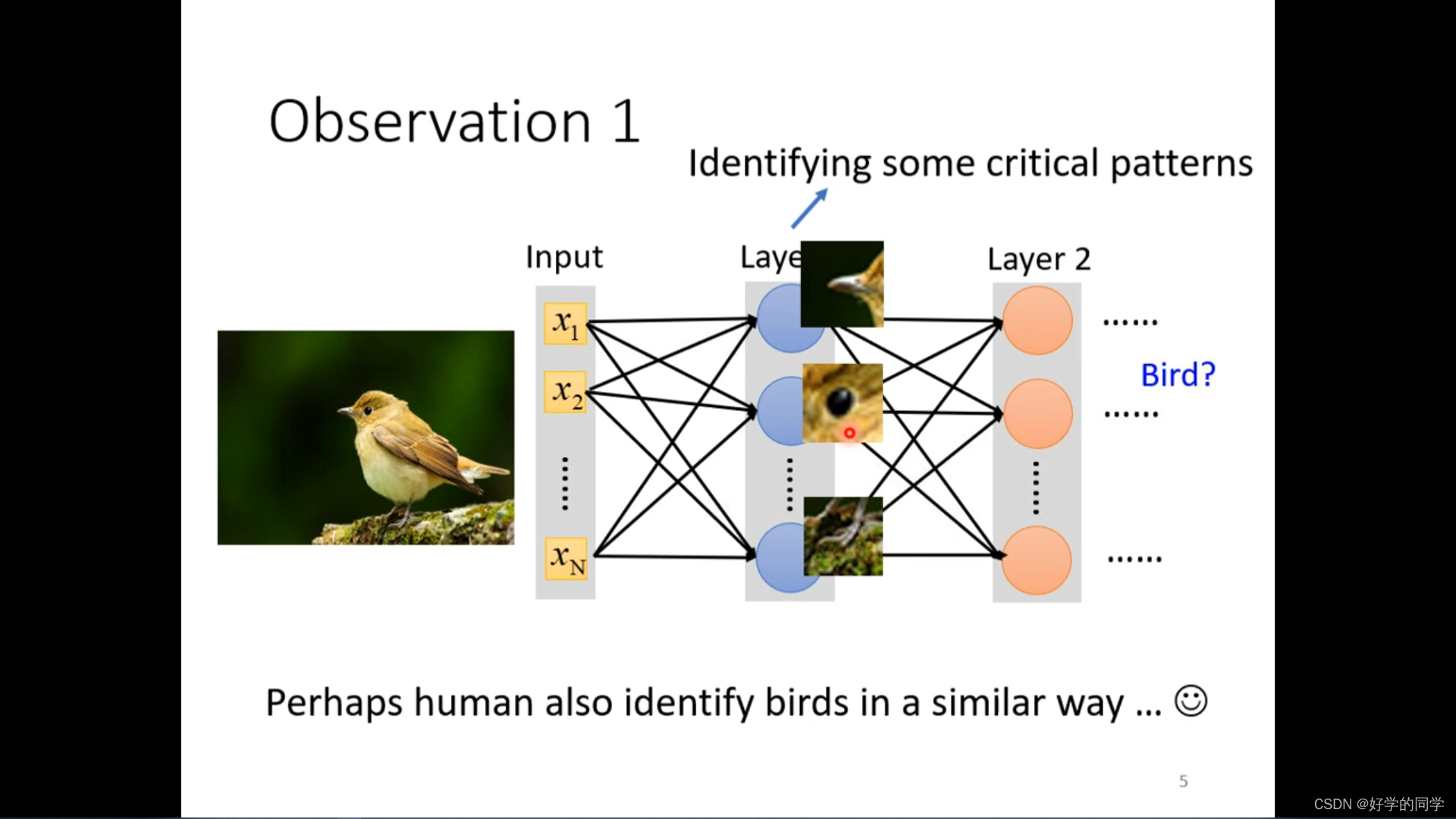

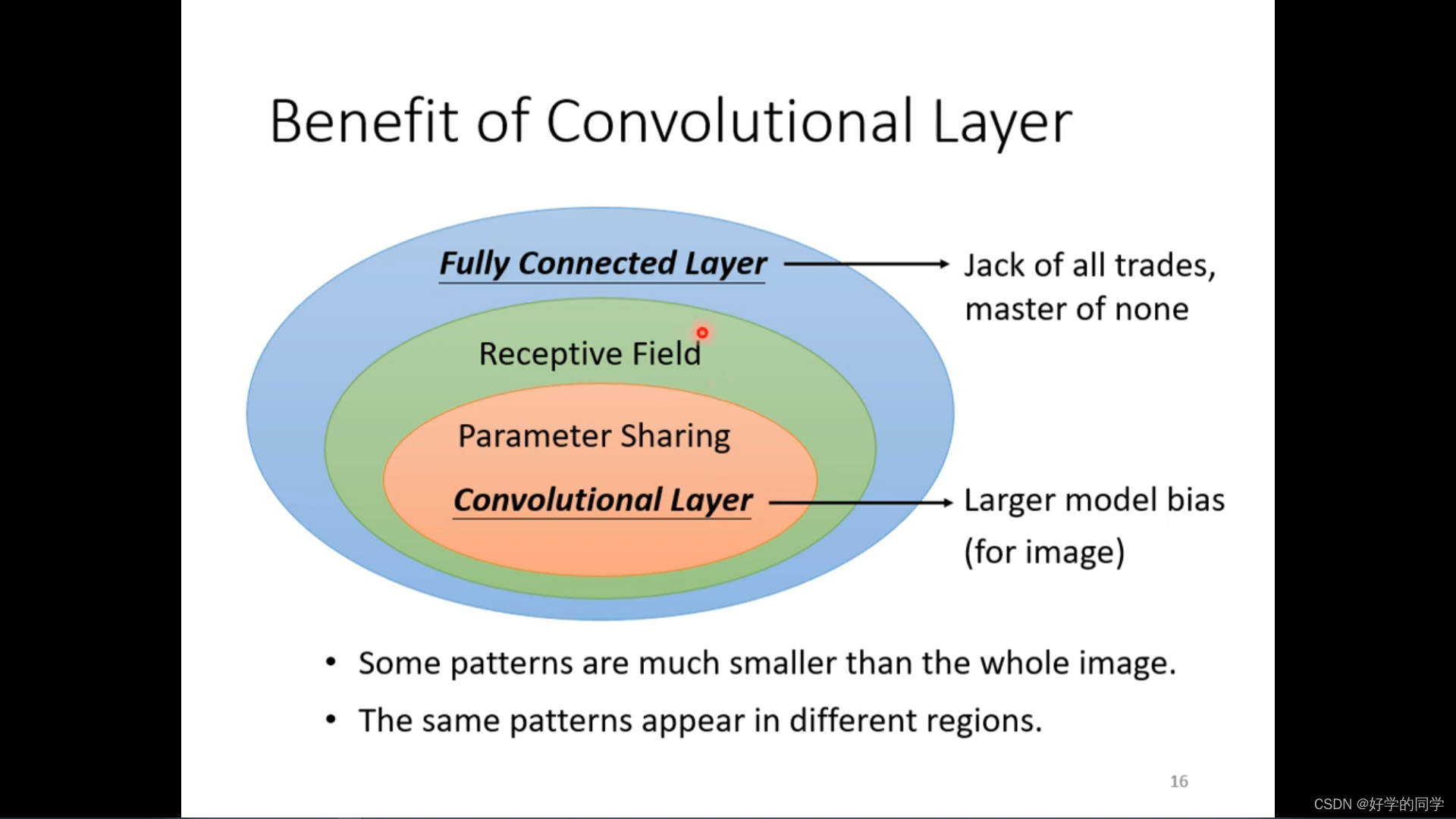
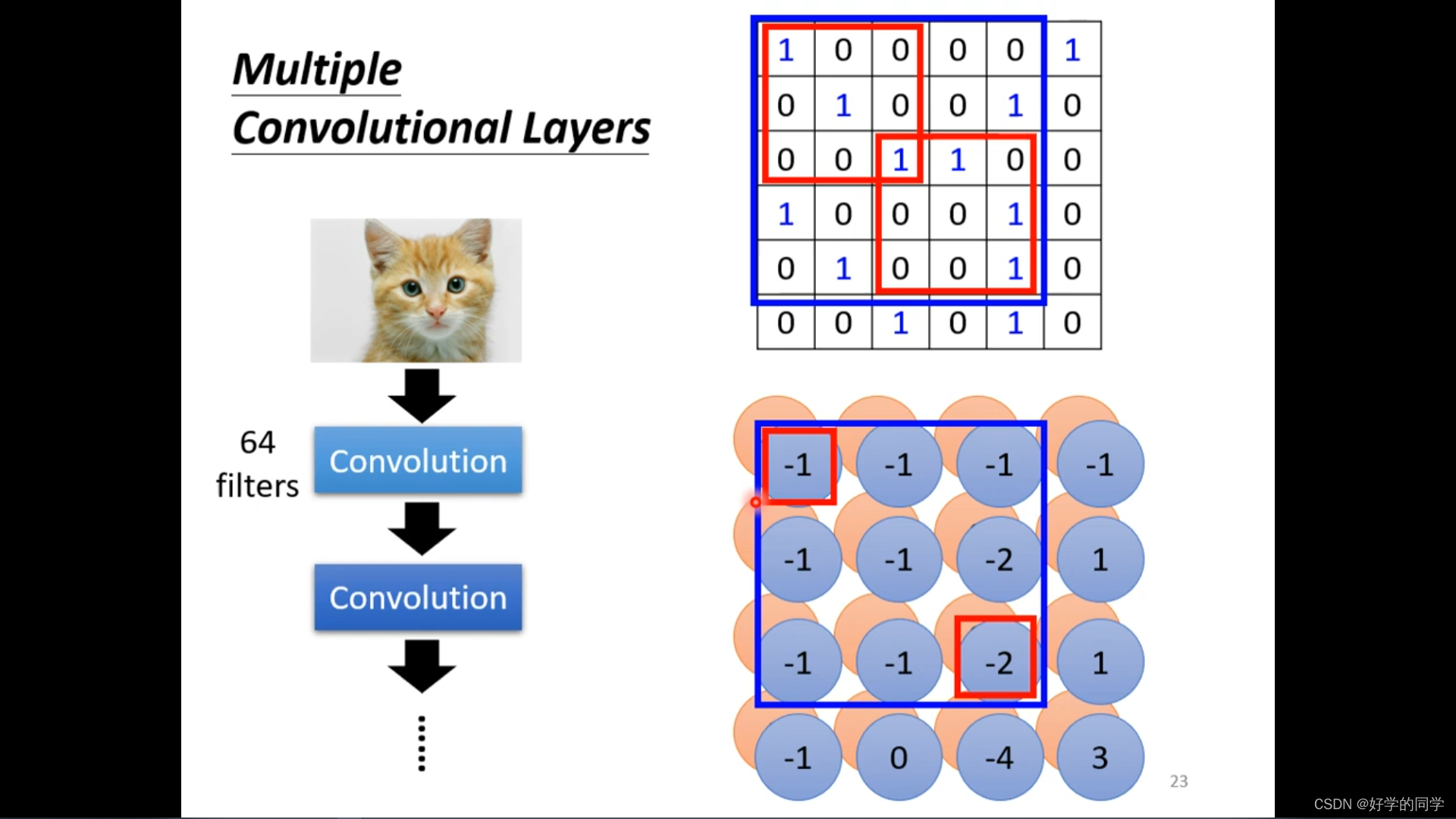
神经网络其实不需要对整个图片进行分析,只需要对一些特殊的信息进行分析就可以得知当前图片所属的类别,基于此就可以对模型进行优化。
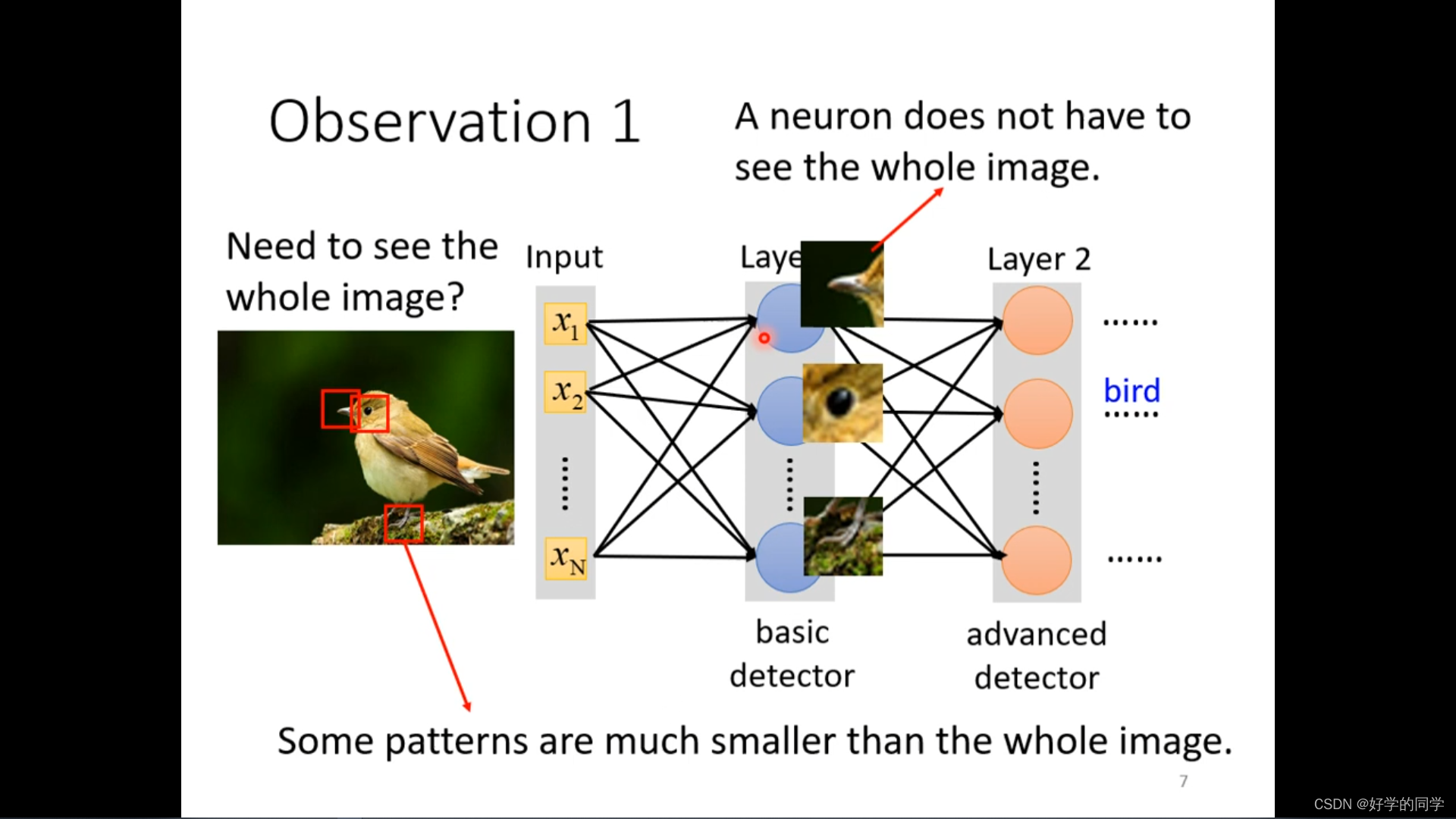
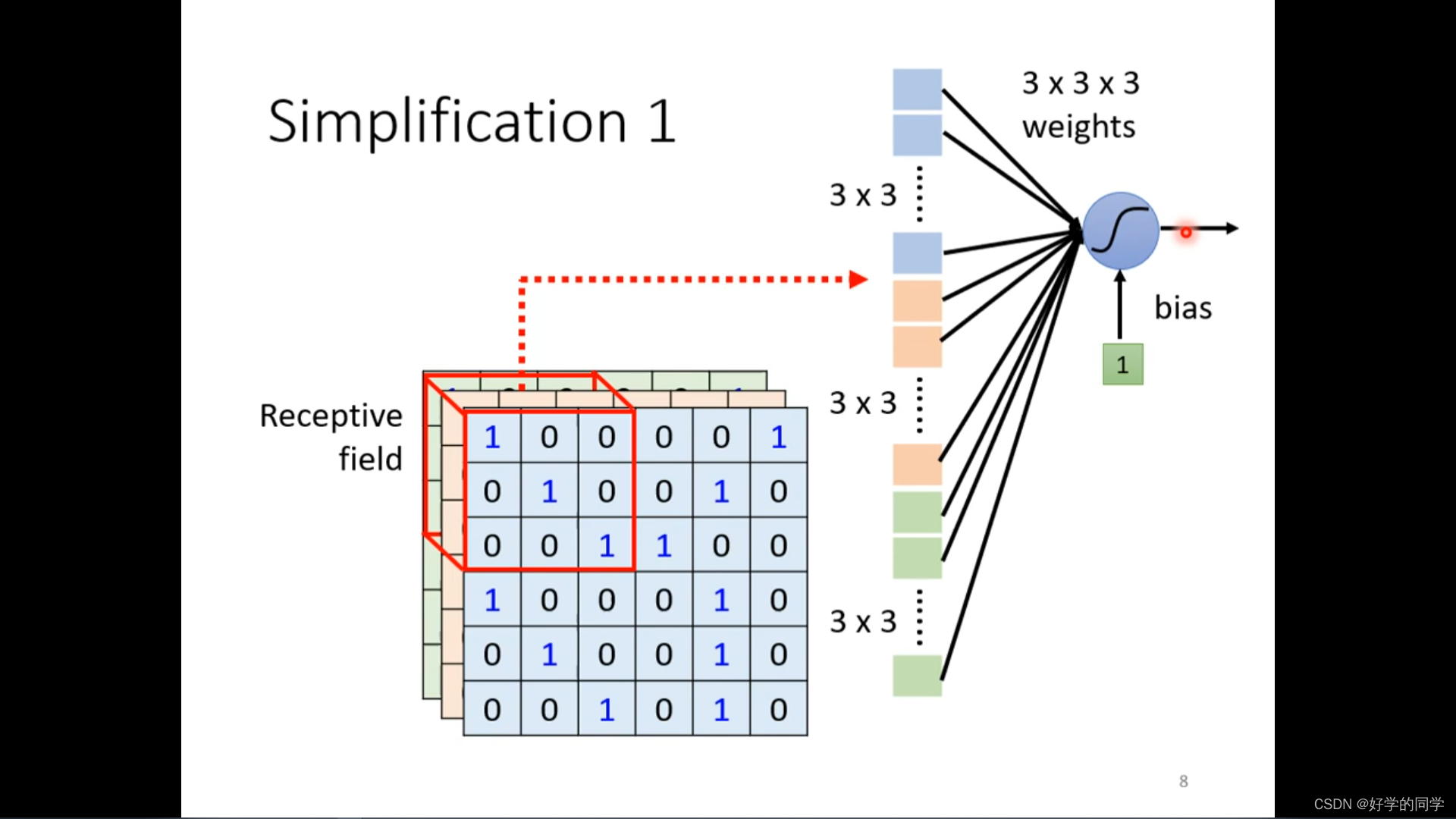
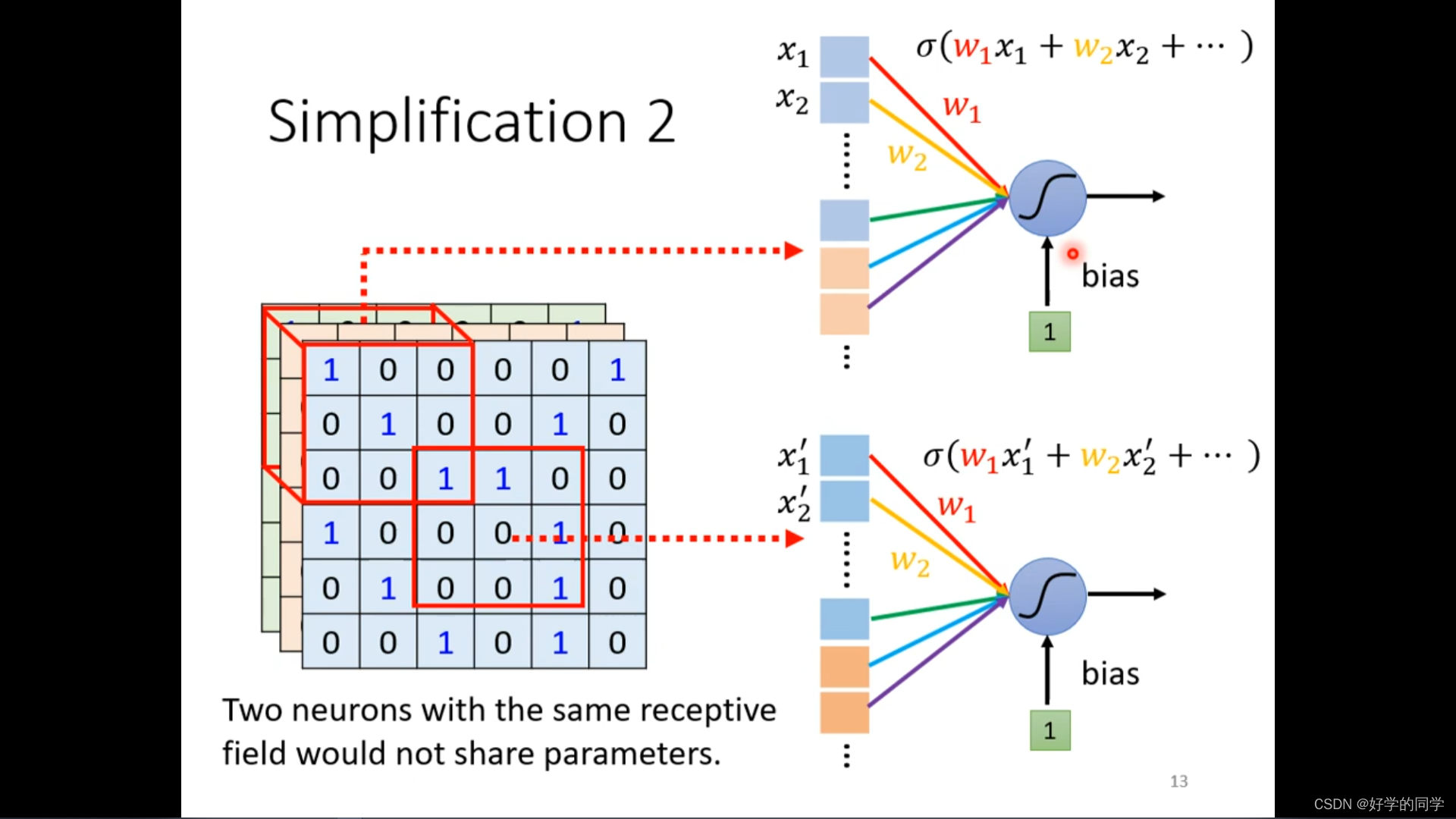
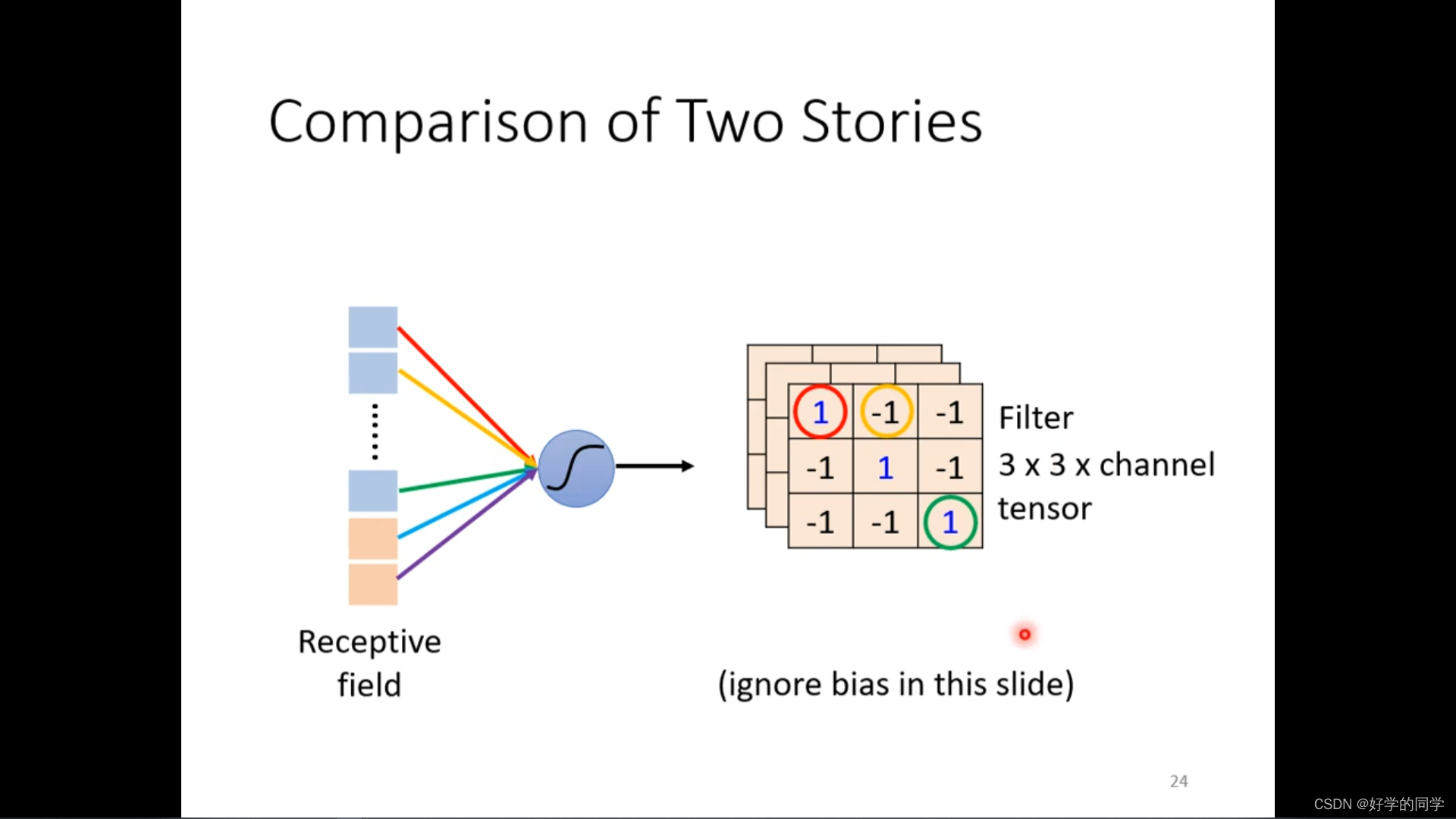
不同的感知视野之间是可以重叠的,同一个receptive field可以有多个神经网络。
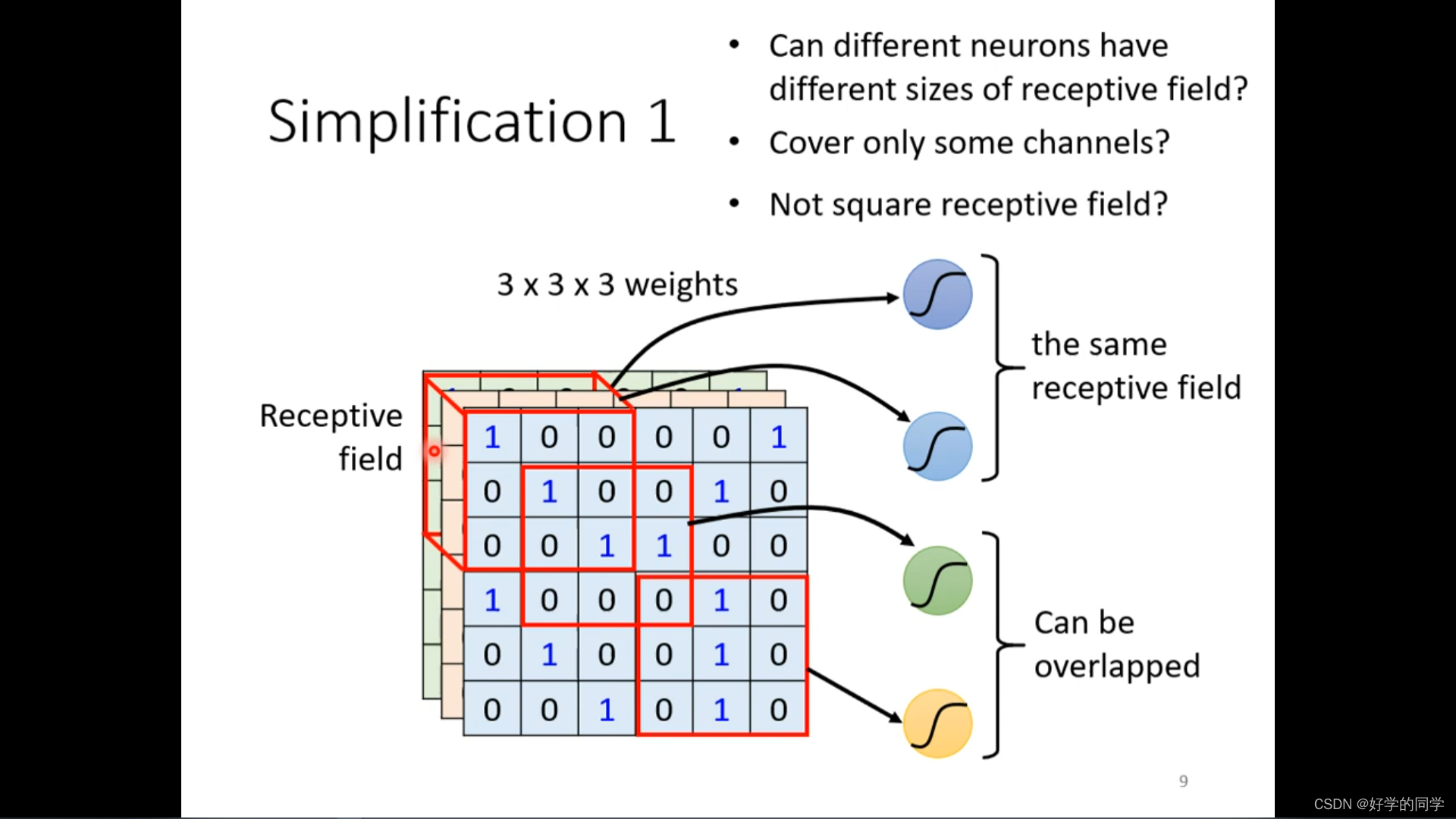
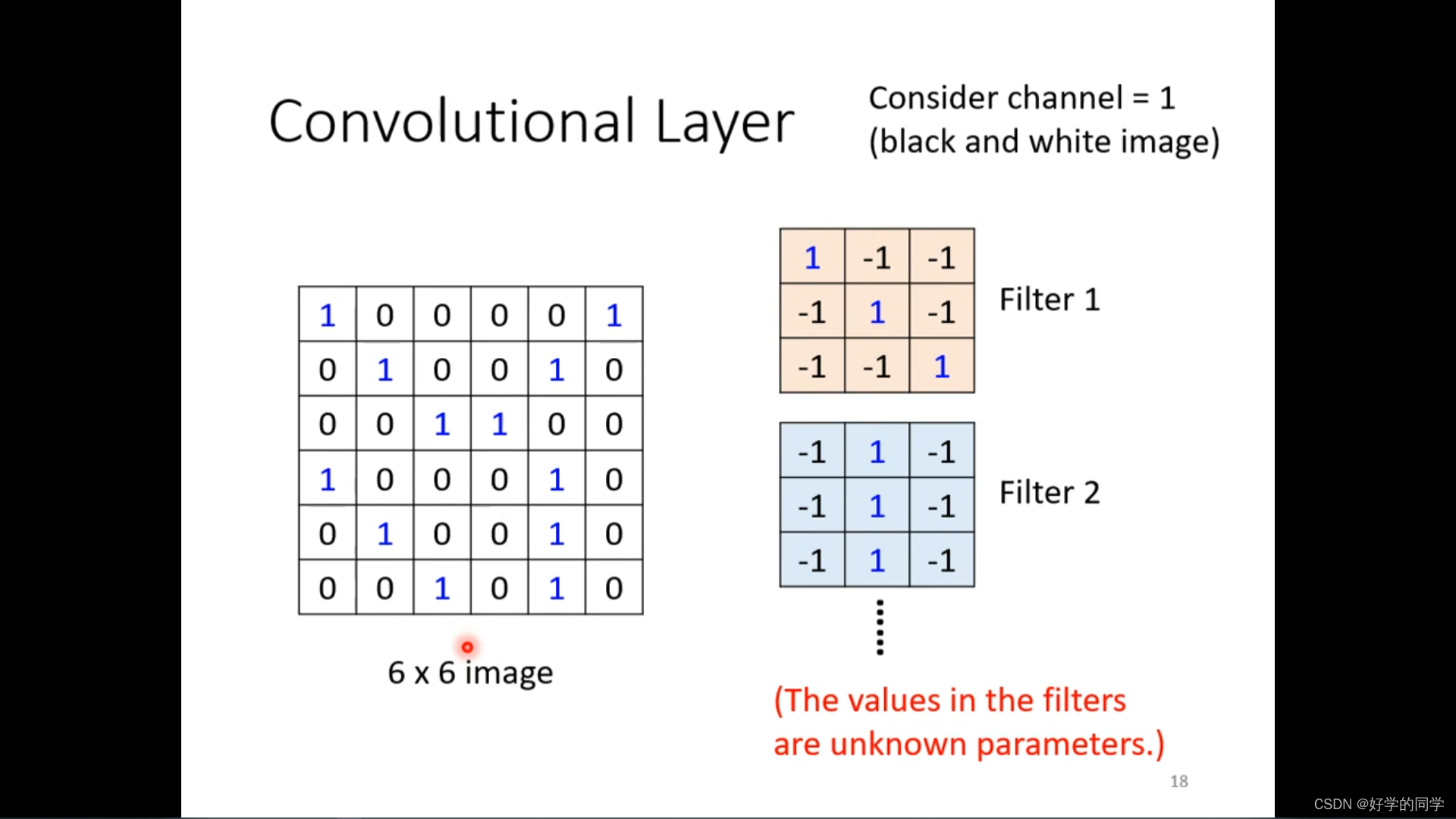
卷积神经网络在图像识别中一般会考虑全部的channel

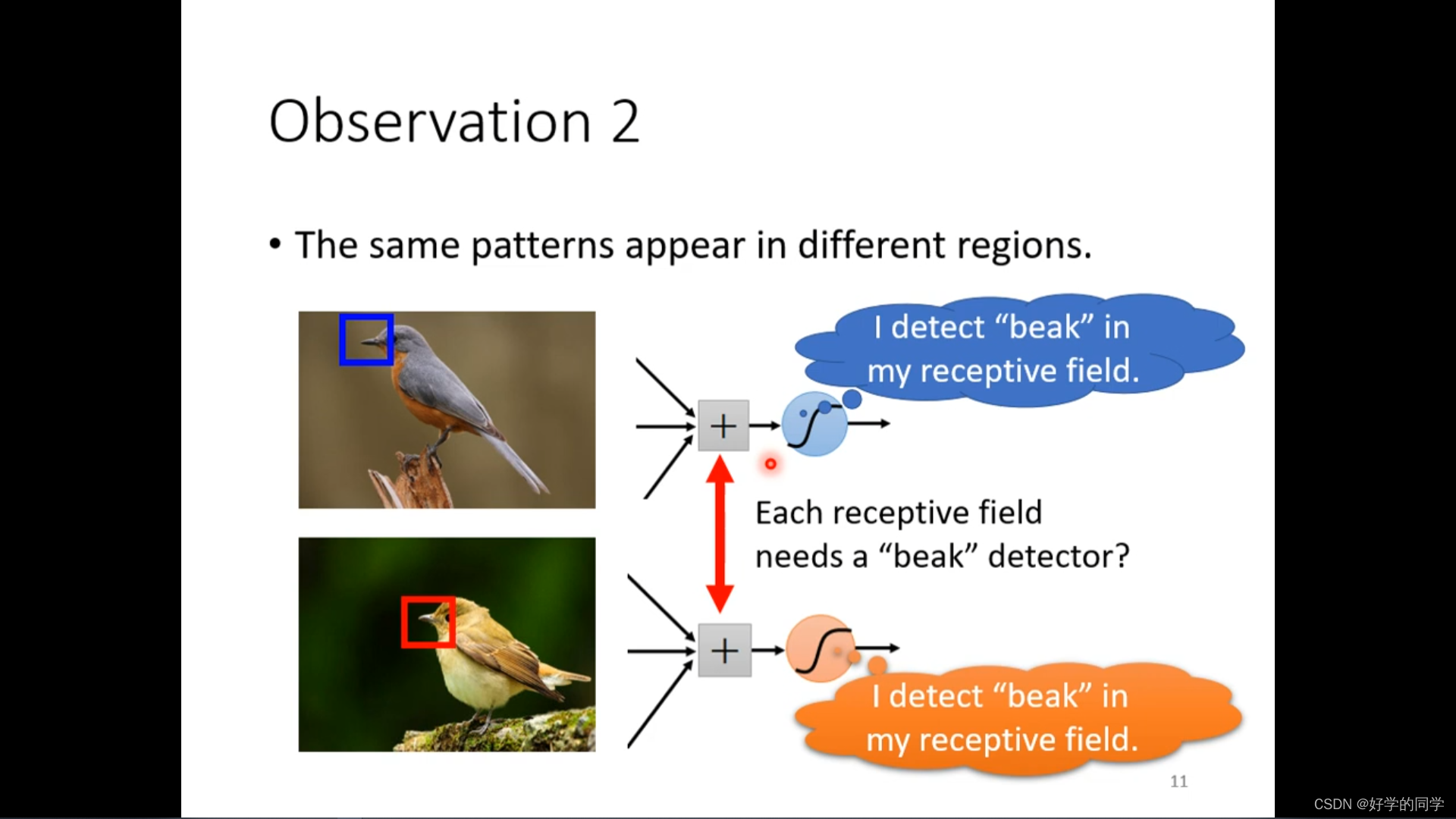
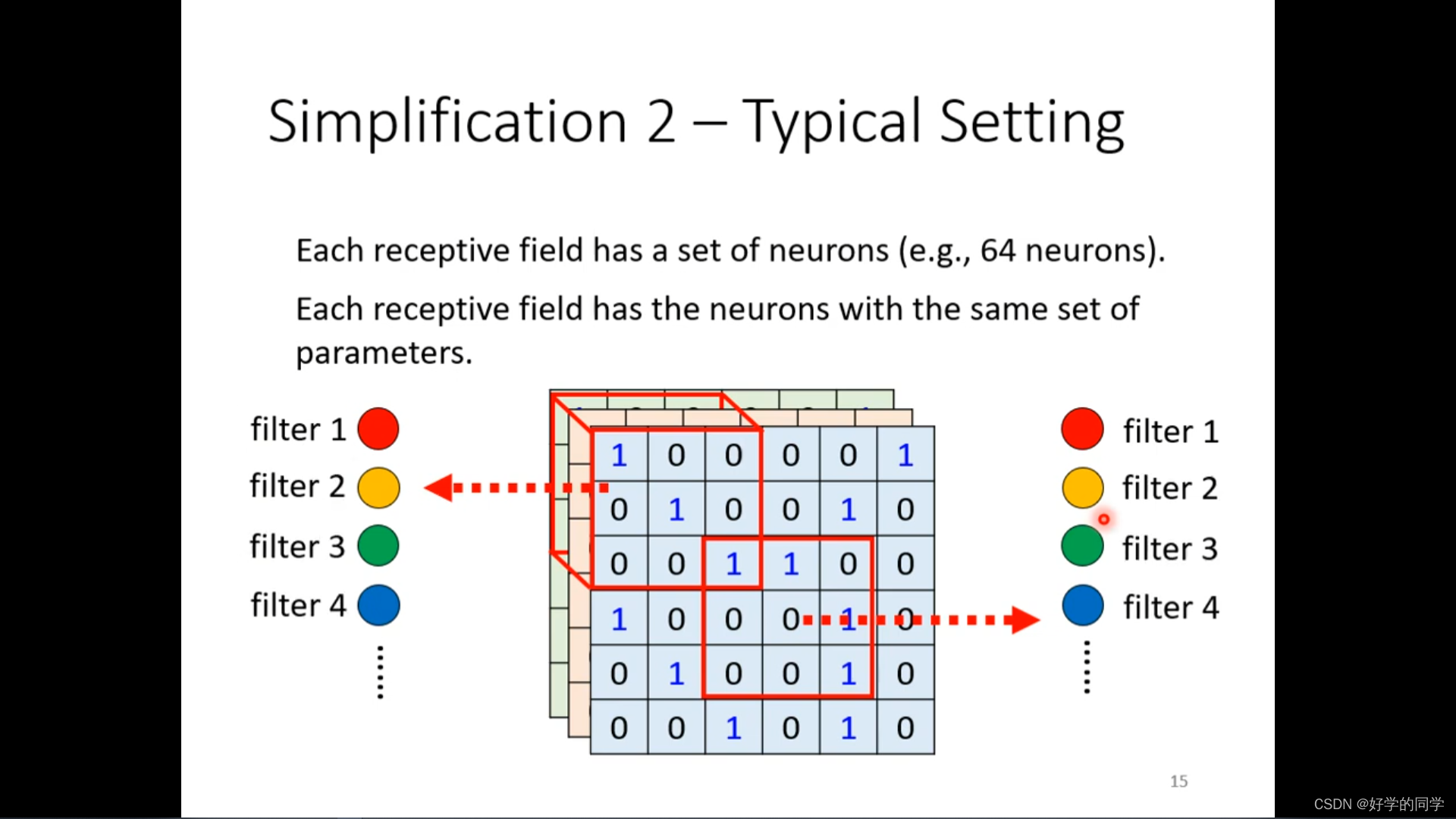
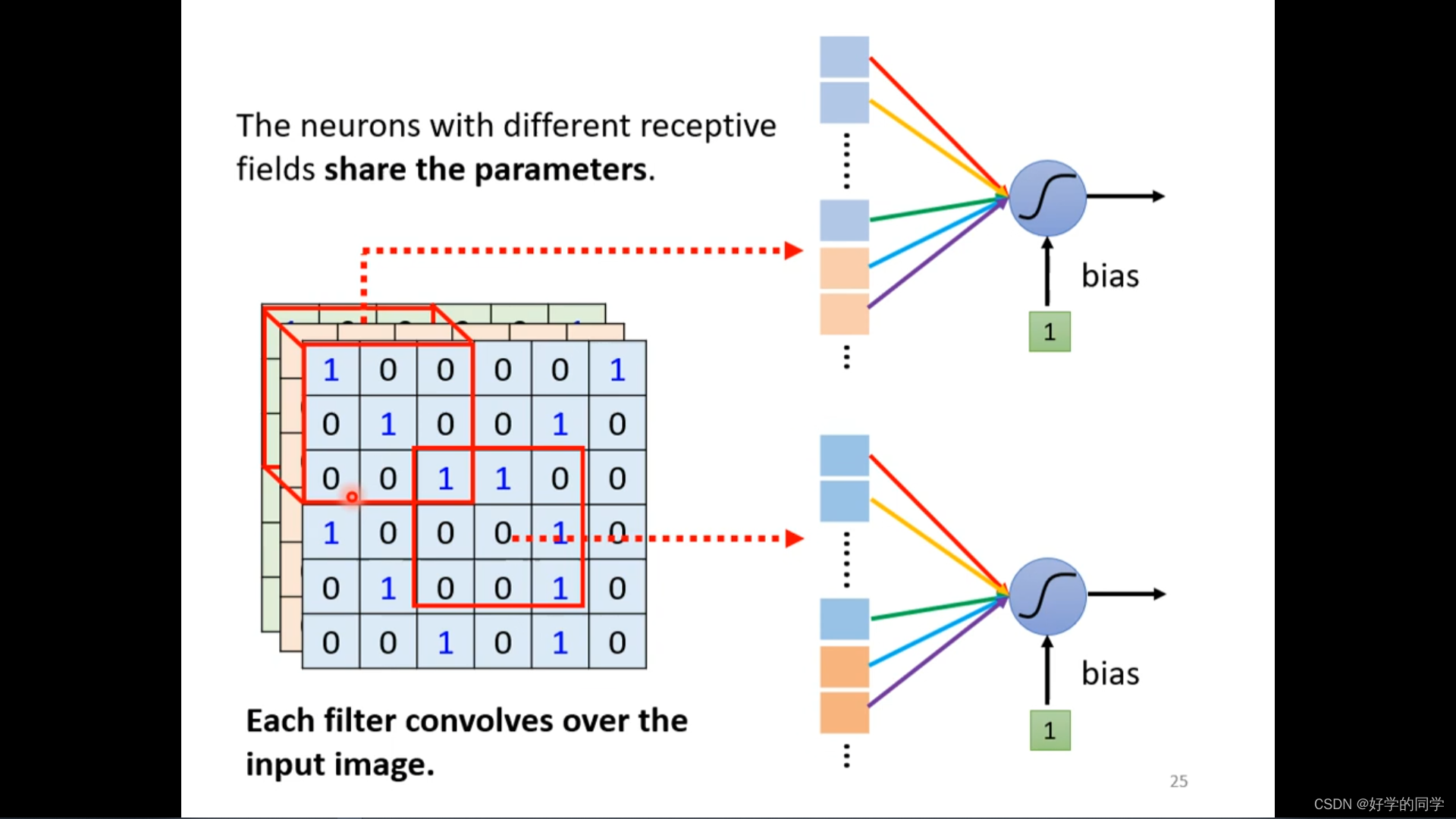
同样的patterns会出现在图像的不同区域中。在每个感受域是否都需要一个detector来对鸟嘴进行识别。
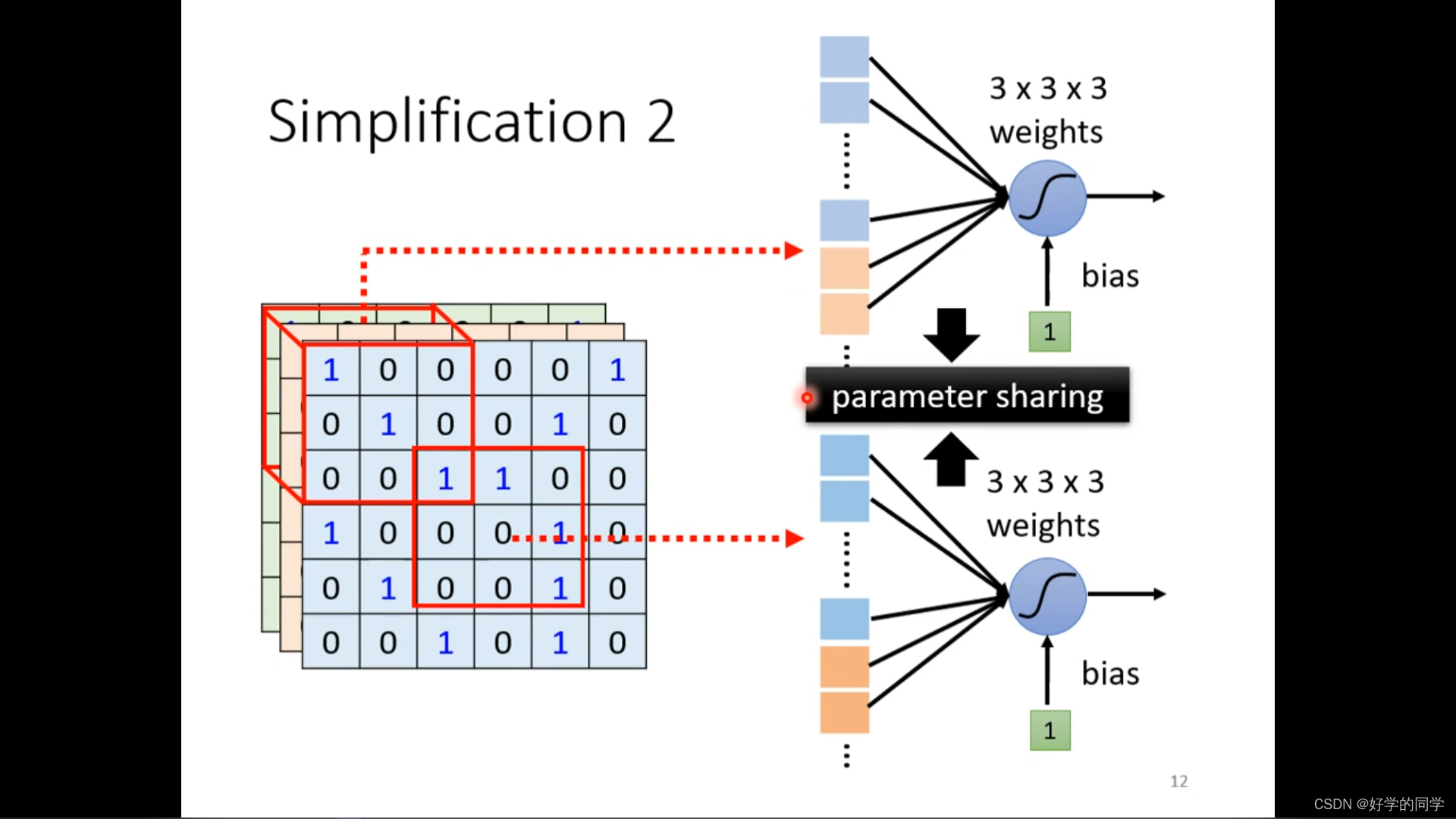
可以把通过让不同的receptive field共享相同的detector,利用参数共享机制减少模型的中的参数数目,参数是相同的,但是输入是不同的,因此输出也是不一样的。
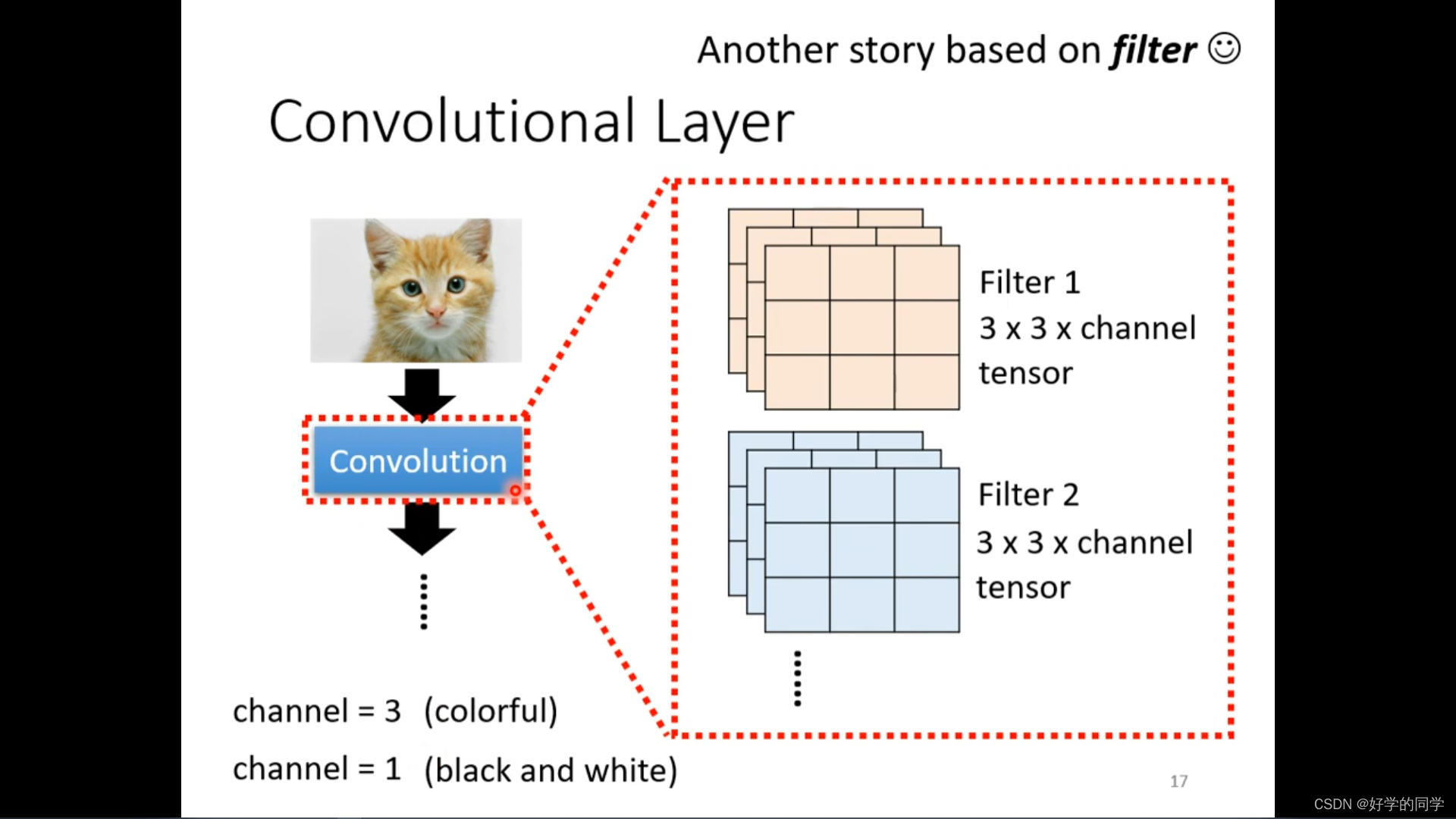
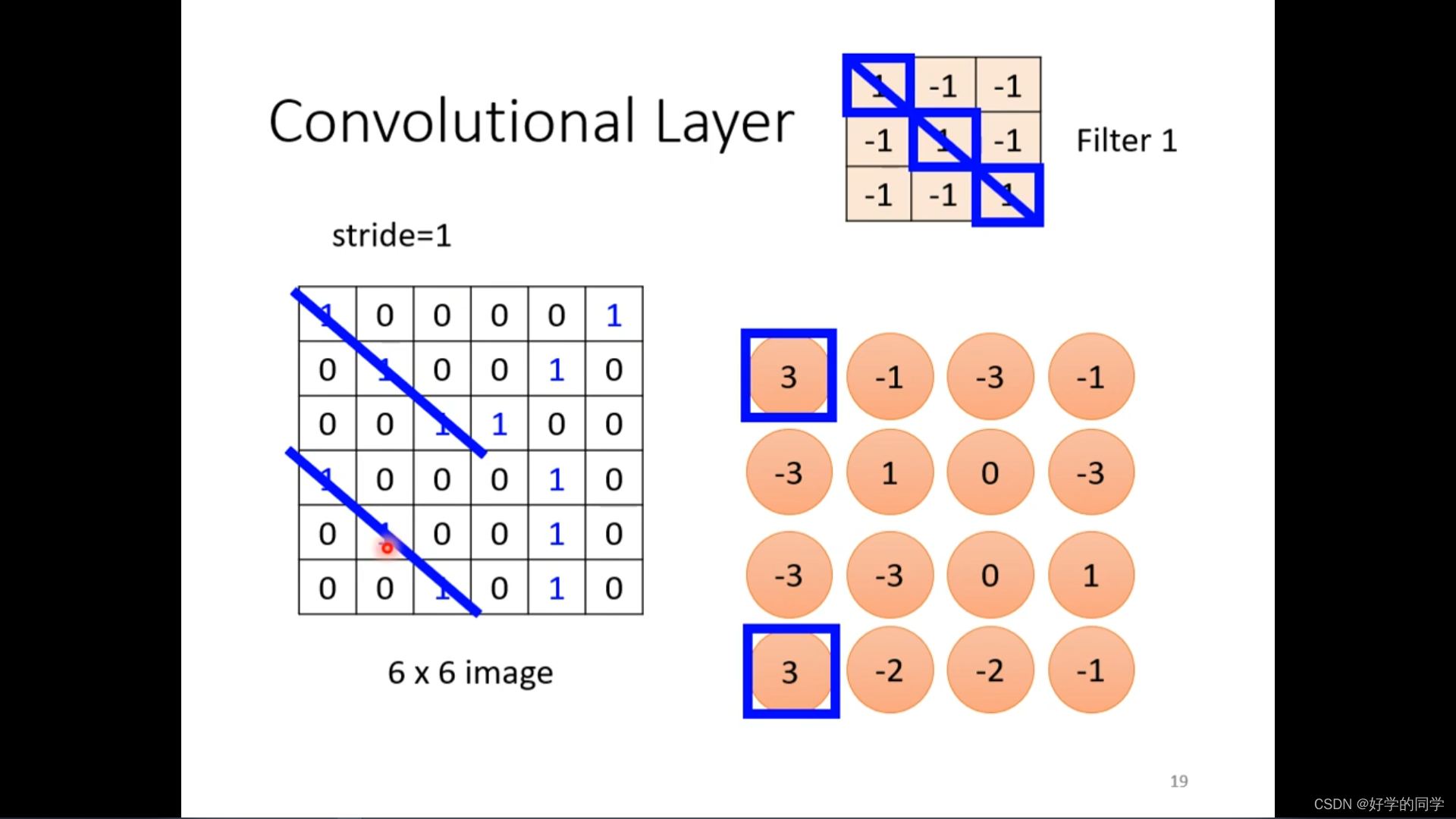
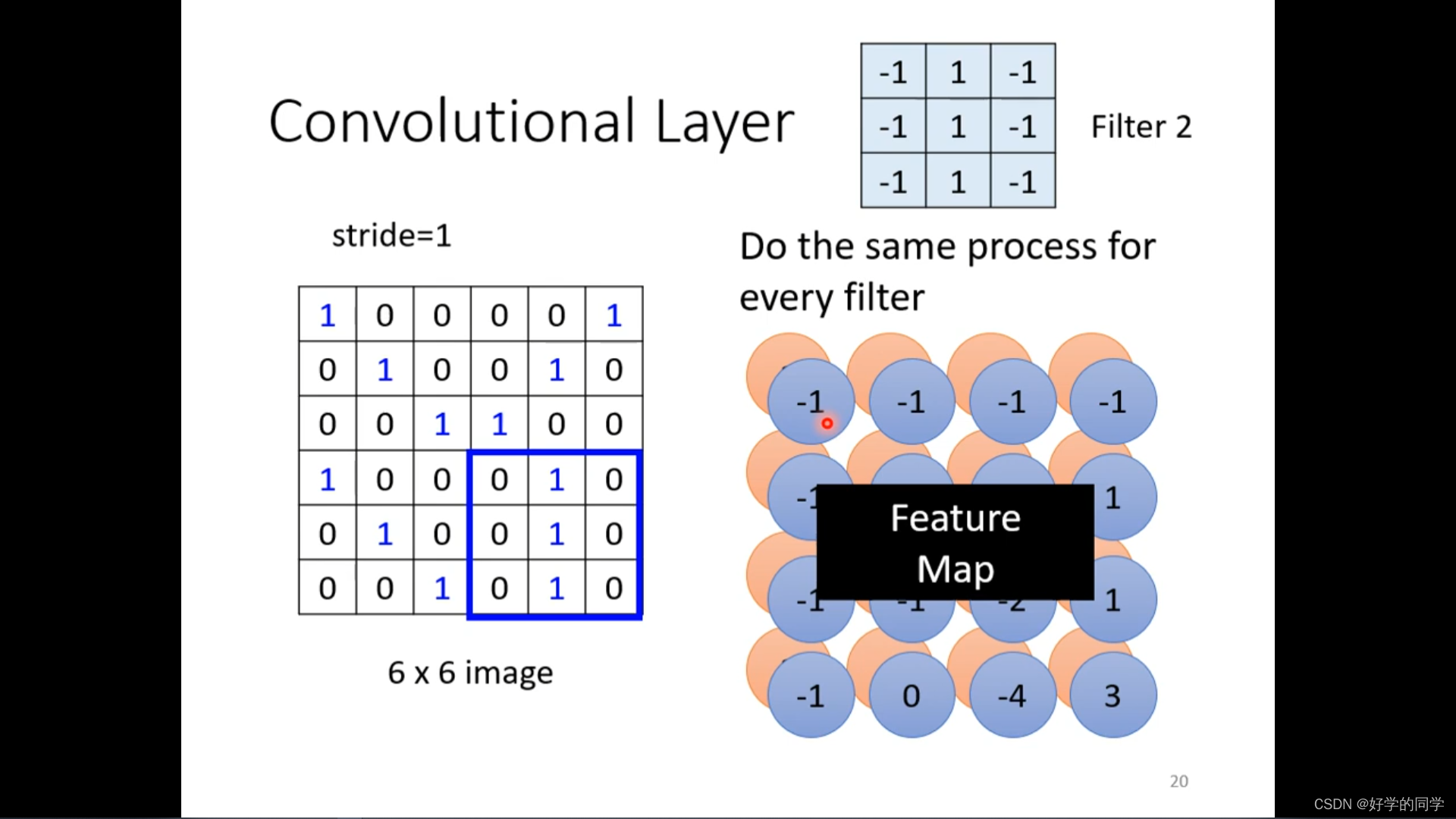
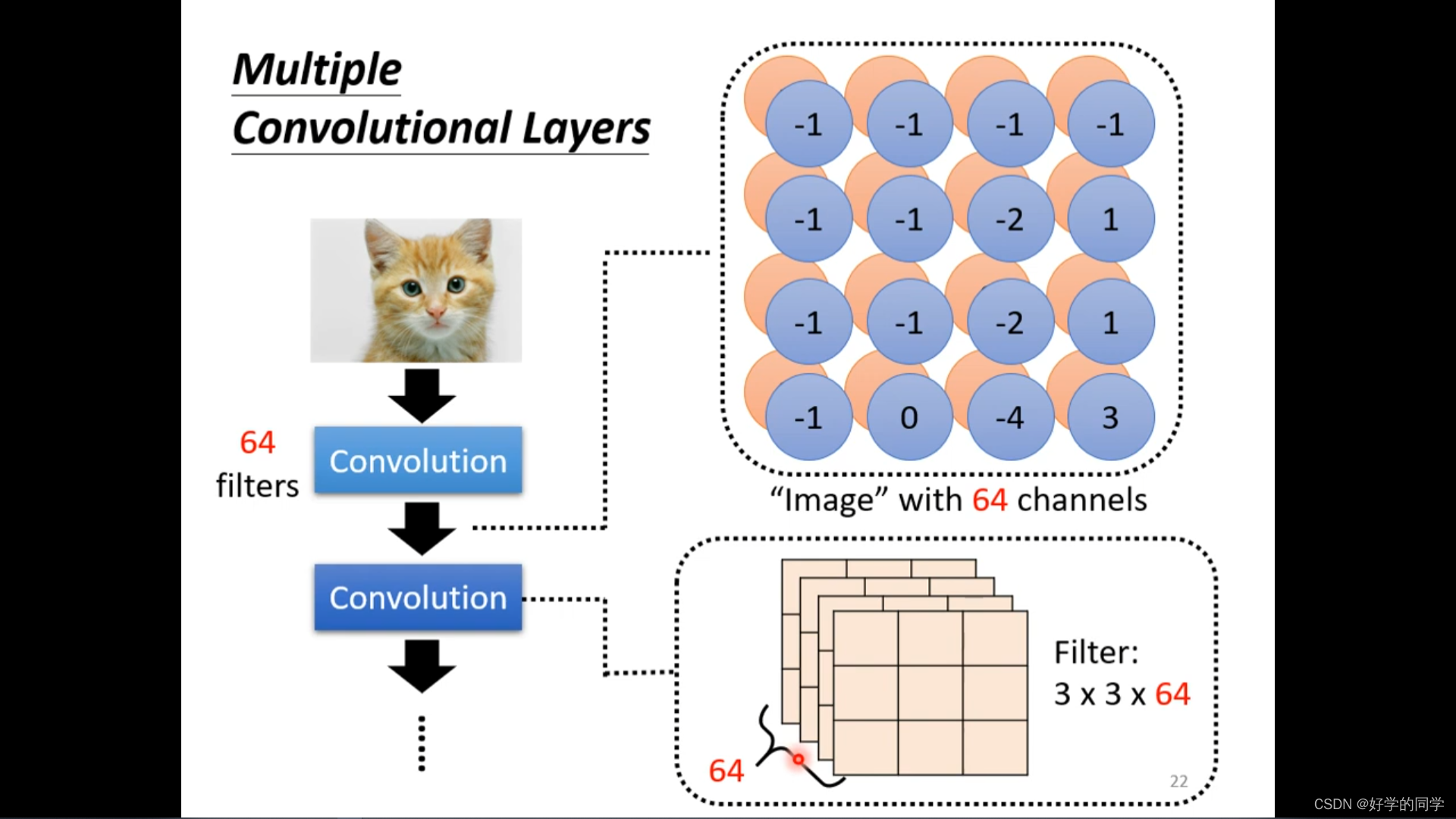
小的卷积核会不会不能侦测到一些大的特征信息?
解答:不会,因为只要网络的深度足够大,随着卷积运算的进行,卷积核都可以对图像中的特征进行有效提取(无论是大特征或者是小特征)。


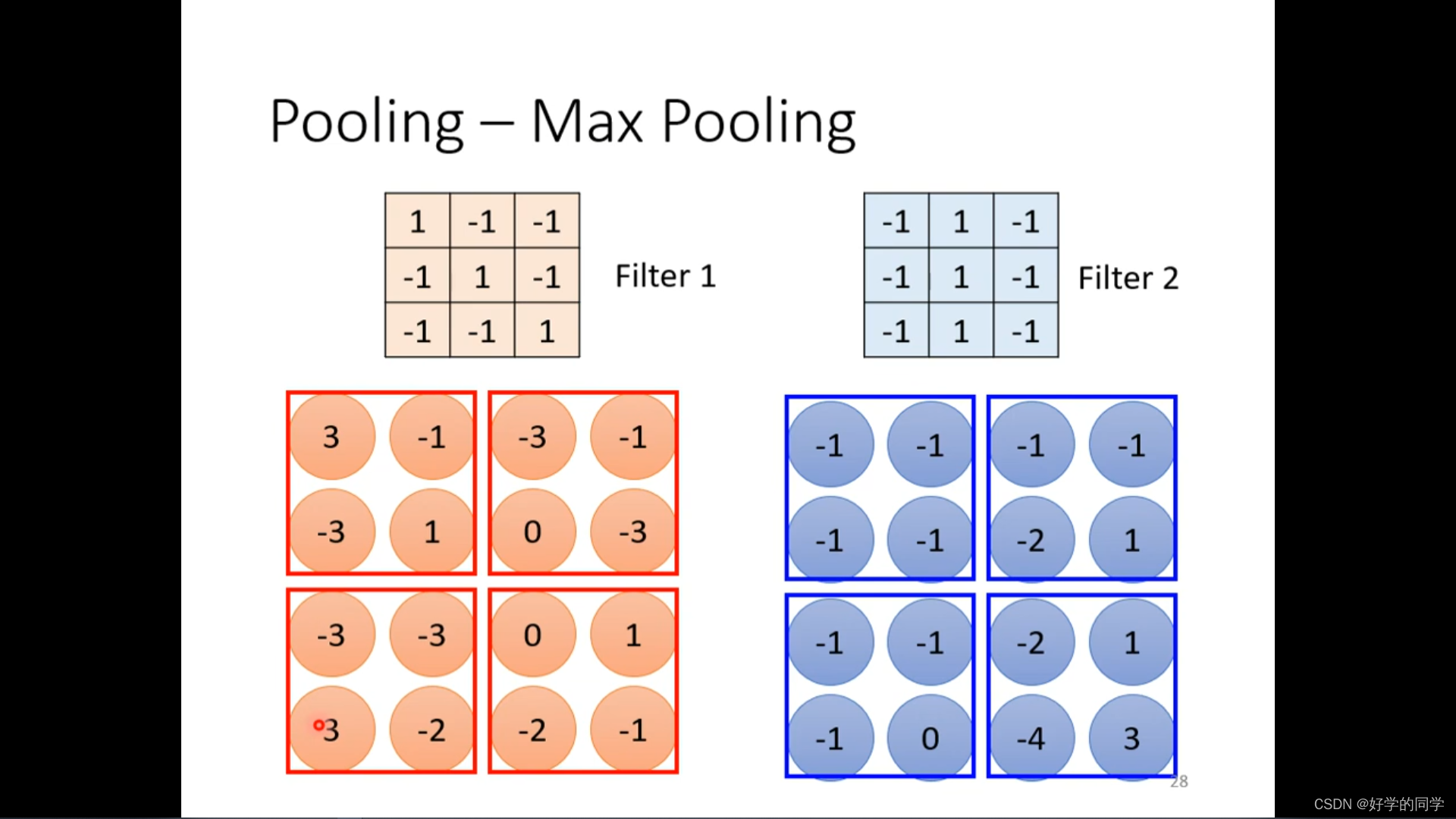
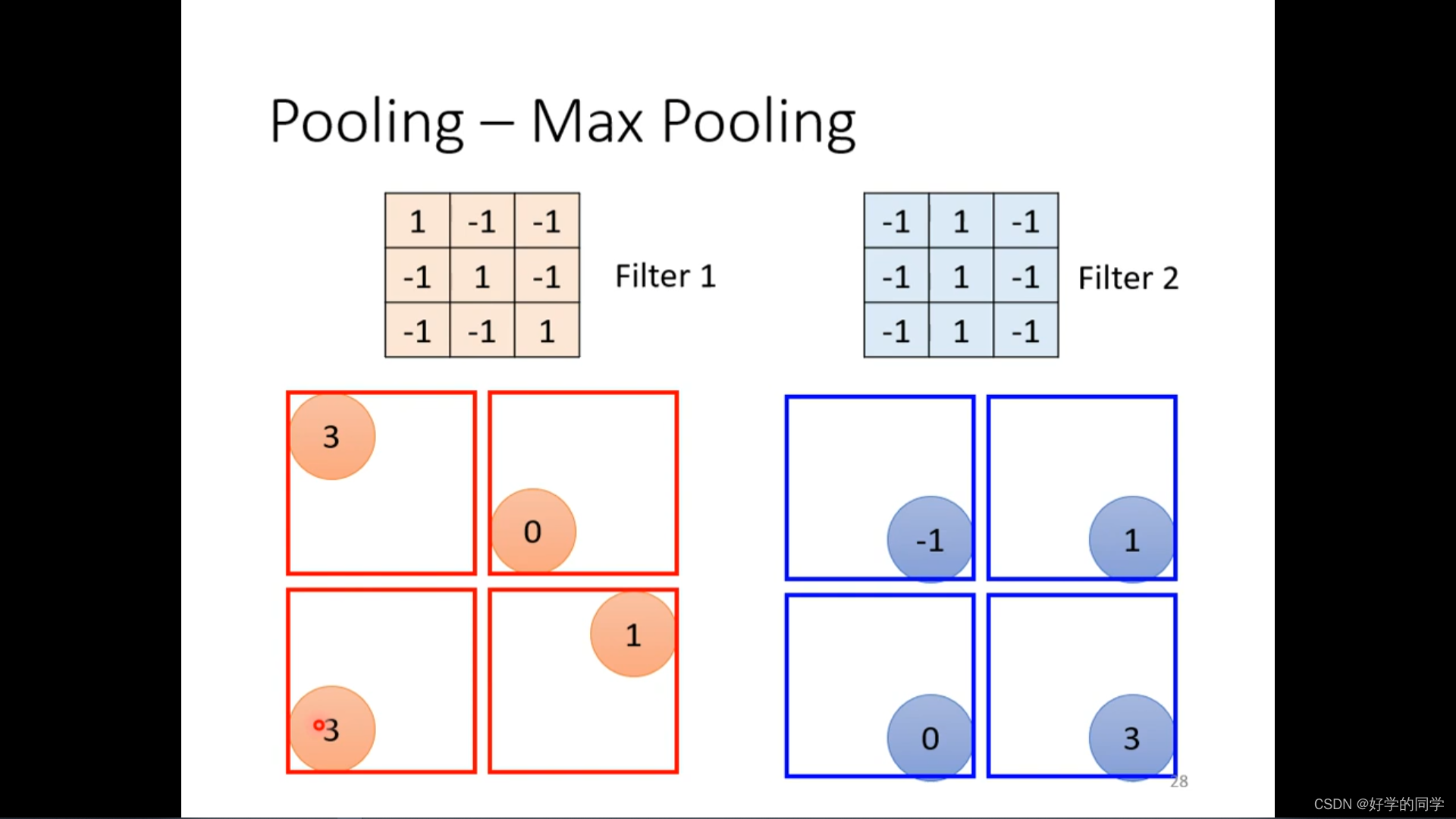
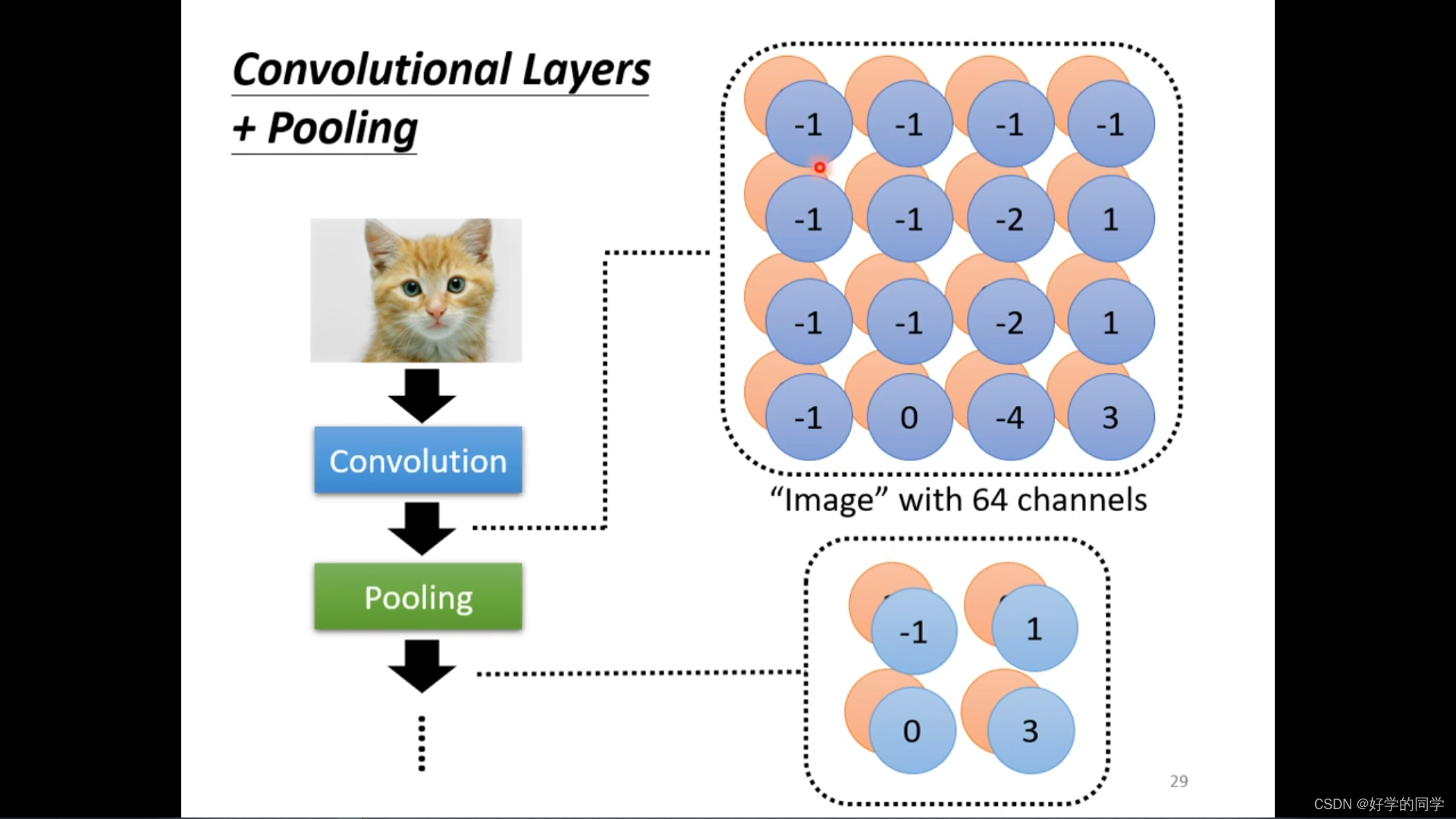
Pooling的使用在减少模型计算量的同时,也会使得原始数据一些细微的特征被忽视,从而不能被考虑到,近些年随着计算能力的提升,模型的Pooling层使用会越来越少。
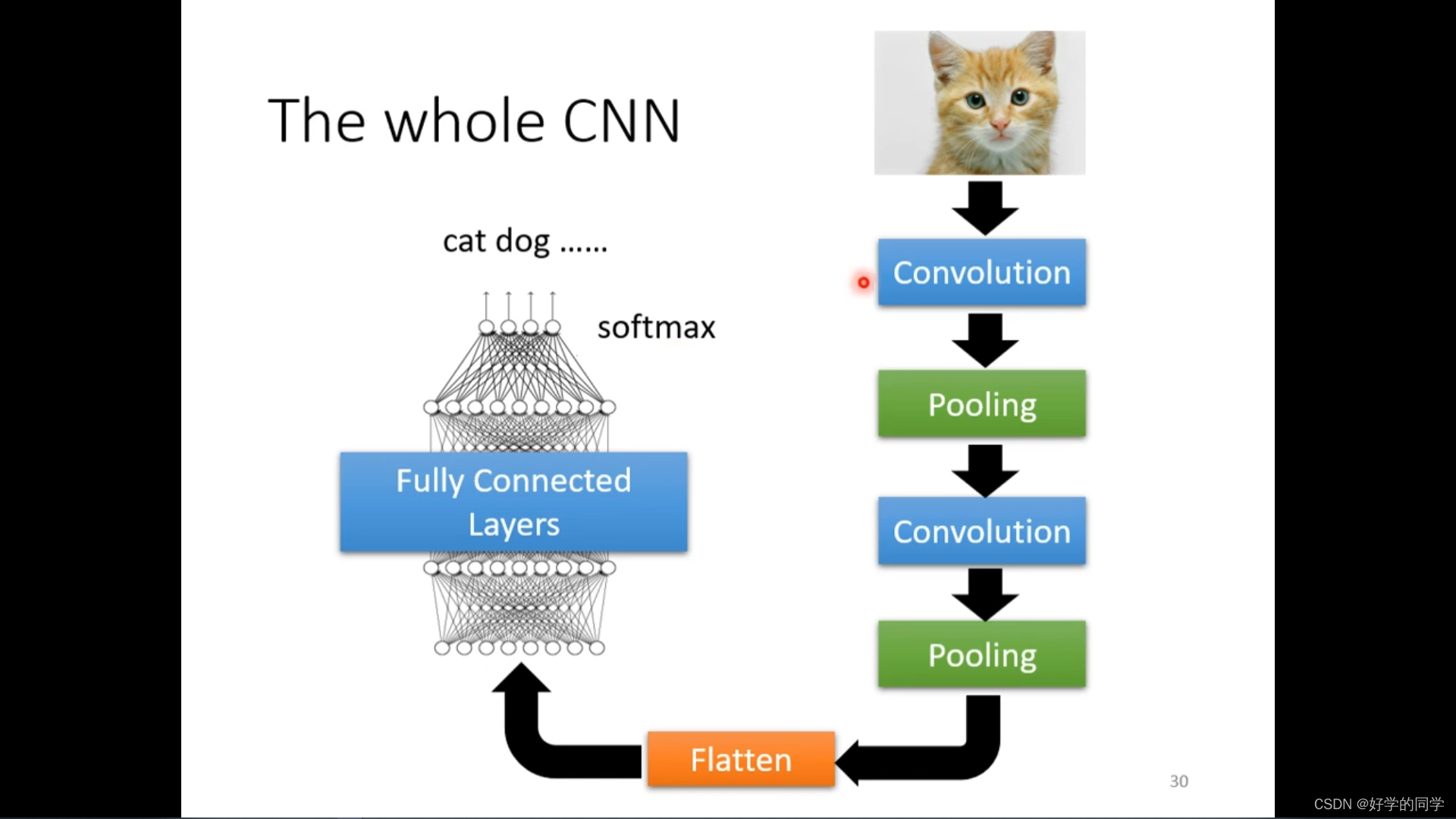
围棋问题中的下棋任务就可以划分为一个分类任务,其共有19*19个类别,可以采用全连接神经网络来进行解决,但是采用CNN的效果会更好,将棋盘视作为19*19的matrix,在Alpha Go中每个位置由48个chanel构成。
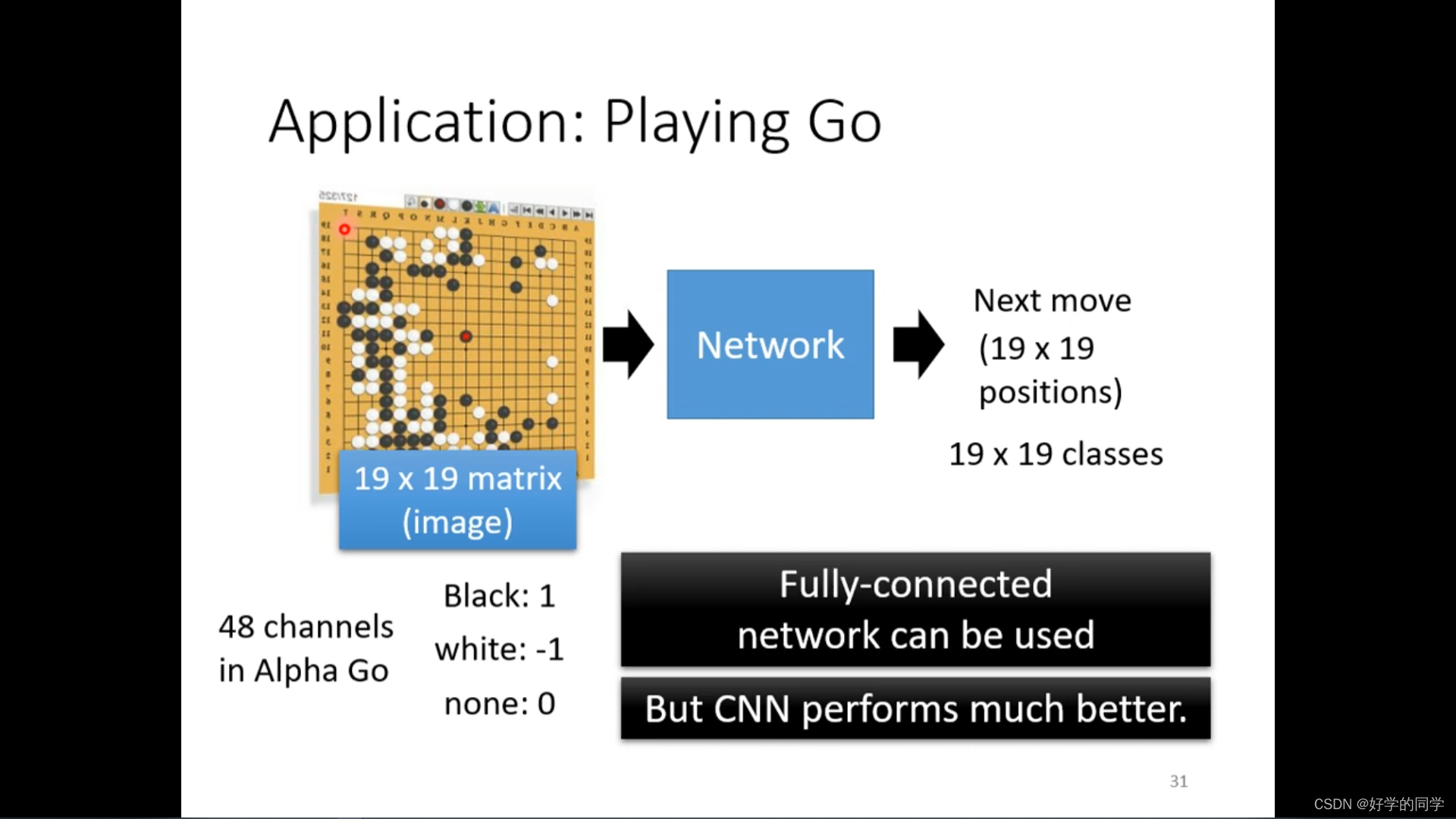

Alpha Go中的池化层操作如何解释?实际并没有采用Pooling操作。

CNN不能辨识放缩或者旋转后的图片。