python 线程安全和锁
进程是计算机中最小的资源分配单位。
线程是计算机中能被cpu调度的最小单位。
一、什么是线程?
线程也叫轻量级进程,是操作系统能够进行调度的最小单位,它被包含在进程之中,是进程的实际运作单位。线程自己不拥有系统资源,一个进程里面的所有线程共享进程全部资源。
二、GIL全局解释器锁
GIL的全称是 Global Interpreter Lock(全局解释器锁)。
python代码的执行由Python解释器控制。(在一个进程中)每个执行的python线程都会先锁住自己,以阻止别的线程执行。
当然,python解释器不可能容忍一个线程一直独占,它会轮流执行 Python 线程。这样一来,用户看到的就是“伪”并行,即 Python 线程在交替执行,来模拟真正并行的线程。
有同学可能会问,既然解释器能控制线程伪并行,为什么还要 GIL 呢?其实这和Python的底层内存管理有关。
三、为什么要有GIL锁?
python使用引用计数来管理内容,所有 Python 脚本中创建的实例,都会配备一个引用计数,来记录有多少个指针来指向它。当实例的引用计数的值为 0 时,会自动释放其所占的内存。
假设有两个 Python 线程同时引用一个数据,那么双方就都会尝试操作该数据,很有可能造成引用计数的条件竞争,导致引用计数只增加 1(实际应增加 2),这造成的后果是,当第一个线程结束时,会把引用计数减少 1,此时可能已经达到释放内存的条件(引用计数为 0),当第 2 个线程再次试图访问这个数据时,就无法找到有效的内存了。
所以,Python解释器引进 GIL,可以最大程度上规避类似内存管理这样复杂的竞争风险问题。
四、GIL底层实现原理
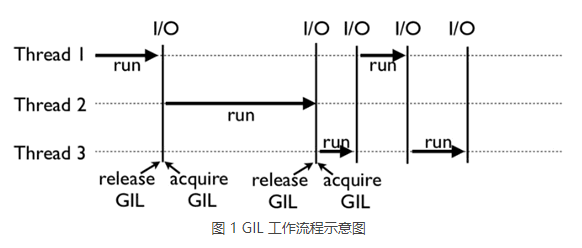
上面这张图,就是 GIL 在 Python 程序的工作示例。
其中,Thread 1、2、3 轮流执行,每一个线程在开始执行时,都会锁住 GIL,以阻止别的线程执行;同样的,每一个线程执行完一段后,会释放 GIL,以允许别的线程开始利用资源。
为什么 Python 线程会去主动释放 GIL 呢?毕竟,如果仅仅要求 Python 线程在开始执行时锁住 GIL,且永远不去释放 GIL,那别的线程就都没有运行的机会。其实,Python解释器中还有另一个机制,叫做间隔式检查(check_interval),意思是 Python解释器会去轮询检查线程 GIL 的锁住情况,每隔一段时间,Python 解释器就会强制当前线程去释放 GIL,这样别的线程才能有执行的机会。
注意,不同版本的 Python,其间隔式检查的实现方式并不一样。早期的 Python 是 100 个刻度(大致对应了 1000 个字节码);而 Python 3 以后,间隔时间大致为 15 毫秒。当然,我们不必细究具体多久会强制释放 GIL,同学们只需要明白,Python解释器会在一个“合理”的时间范围内释放 GIL 就可以了。
五、Python线程模块(threading)
from threading import Thread
import time
import os
# 并发
# def func(i):
# # time.sleep(1)
# print('子:', i, os.getpid())
#
# print('主:', os.getpid())
# for i in range(10):
# t1 = Thread(target=func, args=(i, ))
# t1.start()
轻量级体现:
from threading import Thread
from multiprocessing import Process
import time
import os
# def func(i):
# # time.sleep(1)
# print('子:', i, os.getpid())
# 轻量级
# if __name__ == '__main__':
# start = time.time()
# t_lst = []
# for i in range(100):
# t = Thread(target=func, args=(i, ))
# t.start()
# t_lst.append(t)
# for t in t_lst:
# t.join()
# tt = time.time() - start
#
# start = time.time()
# t_lst = []
# for i in range(100):
# t = Process(target=func, args=(i,))
# t.start()
# t_lst.append(t)
# for t in t_lst:
# t.join()
# pp = time.time() - start
# print('启动100个线程需要:%s' % tt)
# print('启动100个进程需要:%s' % pp)
数据共享:
from threading import Thread
from multiprocessing import Process
import time
import os
num = 100
def func():
global num
num -= 1
t_lst = []
for i in range(100):
t = Thread(target=func)
t.start()
t_lst.append(t)
for t in t_lst:
t.join()
print(num)
六、Python GIL不能绝对保证线程安全
注意,有了 GIL,并不意味着 Python 程序员就不用去考虑线程安全了,因为即便 GIL 仅允许一个 Python 线程执行,但别忘了 Python 还有 check interval 这样的抢占机制。
num = 0
def func1():
global num
for i in range(15000000):
num -= 1
def func2():
global num
for i in range(15000000):
num += 1
if __name__ == '__main__':
t_lst = []
for i in range(10):
t2 = Thread(target=func2)
t1 = Thread(target=func1)
t1.start()
t2.start()
t_lst.append(t2)
t_lst.append(t1)
for t in t_lst:
t.join()
print('-->', num)
上面的程序对num做了同样数量的加法和减法,那么num理论上是0。但运行程序,打印num,发现它不是0。问题出在哪里呢,问题在于python的每行代码不是原子化的操作。比如 num += 1 这步,不是一次性执行的。如果去查看python编译后的字节码执行过程,可以看到如下结果。
LOAD_GLOBAL
LOAD_CONST
BINARY_ADD
STORE_GLOBAL
从过程可以看出,num += 1 操作分成了四步完成。因此,num += 1 不是一个原子化操作。
- 加载全局变量
- 加载常数1
- 进行二进制加法运算
- 将运算结果存入变量n
根据前面的线程释放GIL原则,线程执行这四步的过程中,有可能会让出GIL。如果这样,num += 1的运算过程就被打乱了。最后的结果中,得到一个非零的n也就不足为奇。
解决上面的问题:(加锁)(互斥锁)
from threading import Thread, Lock
# 注意:之前我们用的是进程锁,现在我们用的是线程锁
num = 0
def func1(lock):
global num
for i in range(1500000):
lock.acquire()
num -= 1
lock.release()
def func2(lock):
global num
for j in range(1500000):
lock.acquire()
num += 1
lock.release()
if __name__ == '__main__':
t_lst = []
lock = Lock()
for i in range(10):
t2 = Thread(target=func2, args=(lock, ))
t1 = Thread(target=func1, args=(lock, ))
t1.start()
t2.start()
t_lst.append(t2)
t_lst.append(t1)
for t in t_lst:
t.join()
print('-->', num)
七、递归锁
哲学家吃饭问题
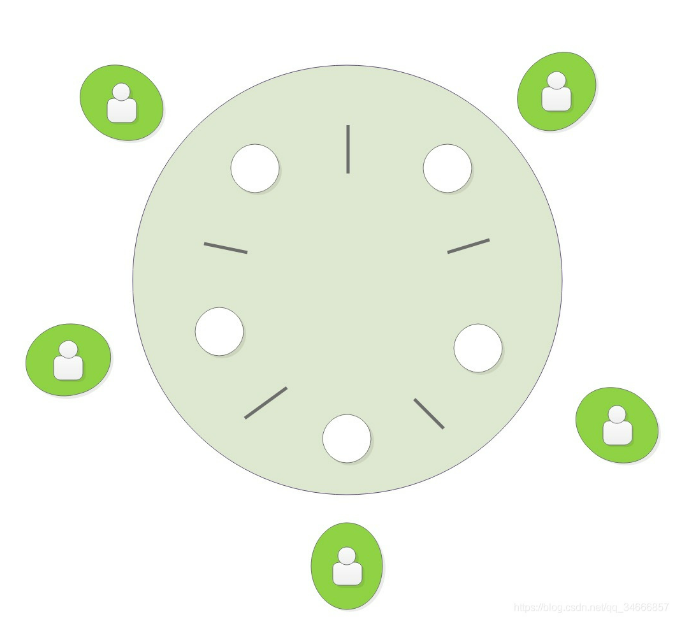
死锁例子:
# 例子
import time
from threading import Thread, Lock
noodle_lock = Lock() # 面锁
fork_lock = Lock() # 叉子锁
def eat1(name):
noodle_lock.acquire()
print('%s拿到面条了' % name)
fork_lock.acquire()
print('%s拿到叉子了' % name)
print('%s吃面' % name)
time.sleep(3)
fork_lock.release()
print('%s放下叉子' % name)
noodle_lock.release()
print('%s放下面' % name)
def eat2(name):
fork_lock.acquire()
print('%s拿到叉子了' % name)
noodle_lock.acquire()
print('%s拿到面条了' % name)
print('%s吃面' % name)
time.sleep(3)
noodle_lock.release()
print('%s放下面' % name)
fork_lock.release()
print('%s放下叉子' % name)
if __name__ == '__main__':
name_list1 = ['zhangsan', 'lisi']
name_list2 = ['wangwu', 'zhaoliu']
for name in name_list1:
Thread(target=eat1, args=(name, )).start()
for name in name_list2:
Thread(target=eat2, args=(name, )).start()
# 死锁的条件
# 两把锁
# 异步的
# 操作的时候 抢到一把锁之后还要去抢第二把锁
# 一个线程抢到一把锁,另一个线程抢到另一把锁
解决死锁的问题,递归锁:
import time
from threading import Thread, Lock, RLock
# noodle_lock = Lock() # 面锁
# fork_lock = Lock() # 叉子锁
fork_lock = noodle_lock = RLock()
def eat1(name):
noodle_lock.acquire()
print('%s拿到面条了' % name)
fork_lock.acquire()
print('%s拿到叉子了' % name)
print('%s吃面' % name)
time.sleep(3)
fork_lock.release()
print('%s放下叉子' % name)
noodle_lock.release()
print('%s放下面' % name)
def eat2(name):
fork_lock.acquire()
print('%s拿到叉子了' % name)
noodle_lock.acquire()
print('%s拿到面条了' % name)
print('%s吃面' % name)
time.sleep(3)
noodle_lock.release()
print('%s放下面' % name)
fork_lock.release()
print('%s放下叉子' % name)
if __name__ == '__main__':
name_list1 = ['茉莉', '学无止尽']
name_list2 = ['大锤', '李氏小生']
for name in name_list1:
Thread(target=eat1, args=(name, )).start()
for name in name_list2:
Thread(target=eat2, args=(name, )).start()
七、守护线程
强调:
- 对主进程来说,运行完毕指的是主进程代码运行完毕。
- 对主线程来说,运行完毕指的是主线程所在的进程内,所有非守护线程运行完毕,主线程才算运行完毕。
详细解释:
- 主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束。
- 主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束。
import time
from threading import Thread
def func1():
while True:
time.sleep(0.5)
print(123)
def func2():
print('func2, start')
time.sleep(3)
print('func2 end')
t1 = Thread(target=func1)
t2 = Thread(target=func2)
# 设置守护线程
t1.setDaemon(True)
t1.start()
t2.start()
print('主线程的代码结束了')
八、线程信号量(Semaphore)
import time
from threading import Semaphore, Thread
def func(index, sem):
sem.acquire()
print(index)
time.sleep(1)
sem.release()
if __name__ == '__main__':
sem = Semaphore(5)
for i in range(10):
Thread(target=func, args=(i, sem)).start()
# 大家会发现一下会打印5个
# 信号量和池的区别(哪个好?)
# 当然是池好
九、Event(事件)
线程的一个关键特性是每个线程都是独立运行且状态不可预测。
如果程序中的其他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就会变得非常棘手。
为了解决这些问题,我们需要使用threading库中的Event对象。
Event对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象,而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。
- event.isSet():返回event的状态值;
- event.wait():如果event.isSet()==False将阻塞线程;
- event.set():设置event的状态值为True,所有阻塞的线程激活进入就绪状态,等待操作系统调度;
- event.clear():恢复event的状态值False。
示例一:
from threading import Event, Thread
import time
import random
def check(e):
print('开始检测数据库连接')
time.sleep(random.randint(1, 5)) # 检测数据库的连接(所需时间)
e.set() # 检测成功了
def connect(e):
for i in range(3):
e.wait(1.5) # 超过1.5秒就算连接超时
if e.is_set():
print('数据库连接成功')
break
else:
print('尝试连接数据库%s次失败' % (i + 1))
else:
raise TimeoutError
e = Event()
Thread(target=connect, args=(e, )).start()
Thread(target=check, args=(e, )).start()
十、定时器
定时器,指定n秒后执行某操作
from threading import Timer
def func():
print('我执行了')
t = Timer(5, func)
t.start()
print('主线程代码结束了')
十一、线程池
import time
from concurrent.futures import ThreadPoolExecutor
def func(i):
print('thread', i)
time.sleep(1)
print('thread %s end' % i)
tp = ThreadPoolExecutor(5)
# 提交任务
for i in range(20):
tp.submit(func, i) # 注意这里传的参数,不是之前的元组
tp.shutdown()
print('主线程')
如何获取返回值:
import time
from concurrent.futures import ThreadPoolExecutor
def func(i):
print('thread', i)
time.sleep(1)
print('thread %s end' % i)
# 获取返回值
return i * '*'
tp = ThreadPoolExecutor(5)
# 提交任务
for i in range(20):
ret = tp.submit(func, i) # 注意这里传的参数,不是之前的元组
print('ret: ', ret.result())
tp.shutdown()
print('主线程')
但我们发现上述的代码是同步的,我们希望是异步的:
import time
from concurrent.futures import ThreadPoolExecutor
def func(i):
print('thread', i)
time.sleep(1)
print('thread %s end' % i)
# 获取返回值
return i * '*'
tp = ThreadPoolExecutor(5)
# 提交任务
ret_l = []
for i in range(20):
ret = tp.submit(func, i) # 注意这里传的参数,不是之前的元组
ret_l.append(ret)
for ret in ret_l:
print(ret.result())
# tp.shutdown()
print('主线程')
十二、协程
协程:又叫纤程,
定义:把一个线程的工作分成了好几个,可以在多个任务来回切换的现象称为协程。
对于cpu、操作系统来说协程是不存在的,它们只能看到线程。
对外界来说,协程仍然是一条线程。
举例:(任务切换)
一条线程在两个任务之间来回切换。
# def my_generator():
# for i in range(10):
# yield i # 保存当前程序的状态
#
#
# for num in my_generator():
# print(num)
# 写一个最简单的生产者消费者模型
def consumer():
g = producer()
for num in g:
print(num)
def producer():
for i in range(1000):
yield i
那如何利用协程?
协程能把一个线程的执行明确的区分开。
两个任务,协程帮助我们记住哪个任务执行到哪个位置了,并且实现安全的切换。
一个任务不得不陷入阻塞了,在这个任务阻塞的过程中,切换到另一个任务继续执行。
你的程序只要还有任务需要执行,当前线程永远不会阻塞。
利用协程在多个任务陷入阻塞的时候进行切换,来保证一个线程在处理多个任务的时候总是在忙碌。
好处就是能够更加从分的利用cpu。
无论是进程还是线程,都是由操作系统来切换的,开启过的线程、进程会给操作系统的调度增加负担。
如果我们使用的是协程,协程在任务之间的切换操作系统感知不到。
无论开启多少个协程对操作系统来说总是一个线程在执行。操作系统不会有任何的压力。
协程本身就是一条线程,所以完全不会产生数据安全的问题。
十三、协程模块
- greenlet (gevent的底层,主要控制协程的切换)
- gevent(需要安装,直接用,功能比greenlet更全面)
import gevent
def eat():
print('eating 1')
gevent.sleep(1)
print('eating 2')
def play():
print('playing 1')
gevent.sleep(1)
print('playing 2')
g1 = gevent.spawn(eat) # 自动检测阻塞事件,遇见阻塞就会进行切换,有些阻塞他不认识
g2 = gevent.spawn(play)
g1.join() # 阻塞直到g1结束
g2.join() # 阻塞直到g2结束
优化一下:
from gevent import monkey
monkey.patch_all()
import time
import gevent
def eat():
print('eating 1')
time.sleep(1)
print('eating 2')
def play():
print('playing 1')
time.sleep(1)
print('playing 2')
g1 = gevent.spawn(eat) # 自动检测阻塞事件,遇见阻塞就会进行切换,有些阻塞他不认识
g2 = gevent.spawn(play)
g1.join() # 阻塞直到g1结束
g2.join() # 阻塞直到g2结束