论文链接:https://arxiv.org/pdf/2012.04584.pdf
目录
方法
交叉注意机制
交叉注意力得分作为段落检索的相关性度量
用于段落检索的密集双编码器
将交叉注意力分数提取到双编码器
数据集
方法
我们的系统由两个模块组成,即检索器和阅读器,遵循开放域问答的标准管道。
给定一个输入问题,这些模块用于分两步生成答案。
首先,检索器在大型知识源中选择支持段落。
然后,读者会处理这些段落以及问题,以生成答案。
对于读取器模块,我们使用 Fusion-in-Decoder 模型 (Izacard & Grave, 2020),该模型与 BM25 或 DPR 结合使用时可实现最先进的性能(Karpukhin 等人,2020)。
它基于序列到序列架构,并从 T5 或 BART 等预训练模型进行初始化(Raffel 等人,2019 年;Lewis 等人,2019 年)。
这项工作的重点是在没有强监督或基于启发式的弱监督学习的情况下训练检索器。为此,我们建议通过学习近似读者的注意力分数来训练检索器。此处概述的训练方案可以看作是学生-教师管道,其中教师(即阅读器模块)生成用于训练学生网络(即阅读器)的目标。通过这样做,我们希望利用读者从问答对中提取的信号。由于检索器的目标是检索最相关的段落,通过训练检索器估计读者注意力分数,我们隐含地假设这些分数可以很好地代表段落回答问题的有用性。
在本节中,我们将首先描述 Fusion-in-Decoder 架构,然后详细说明用于训练检索器的信号、检索器的设计以及该模块的训练方式。
交叉注意机制
首先,让我们简要回顾一下 Fusion-in-Decoder 模型 (FiD, Izacard & Grave, 2020)。底层架构是一个序列到序列模型,由编码器和解码器组成。
编码器独立处理 个不同的文本输入
。在基于维基百科的开放域问答的情况下,每个输入 sk 是问题 q 和支持段落的串联,在问题之前添加特殊标记问题question:,标题title:和上下文context:维基百科文章的标题以及每段文字。
然后将编码器的输出表示连接起来形成维度为 的全局表示 X,其中 ℓk 是第 k 段的长度,d 是嵌入和隐藏表示的维度该模型。然后,解码器将这种表示处理为常规自回归模型、交替进行自注意力、交叉注意力和前馈模块。
只有交叉注意力模块明确地将编码器的全局输出表示 X 作为输入。如果 表示解码器前一个自注意层的输出,则交叉注意操作包括以下操作。首先,通过应用线性变换计算查询 Q、键 K 和值 V:
![]()
然后通过计算这两个元素之间的点积获得,位置 i 的查询Qi和位置 j 的键 Kj 之间的相似性得分,并在维度上进行归一化:
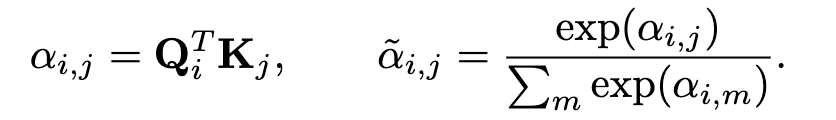
在通过最终线性变换 Wo 之前,通过注意力概率加权的值的总和获得新的表示:
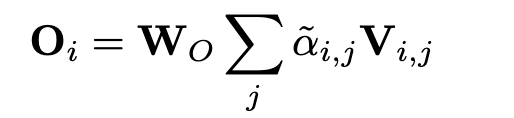
在多头注意力的情况下,上述操作与不同的线性变换并行执行。最后应用一个规范化层,这个管道被一个跳过连接包裹。参见 Vaswani 等人。 (2017) 有关变形金刚结构的更多详细信息。
交叉注意力得分作为段落检索的相关性度量
在某种意义上,涉及第 j 个键的注意力分数衡量这个键和相应值的重要性,以计算下一个表示。我们假设它是估计段落相关性的良好代理——文本片段中的标记越多,文本片段与回答问题的相关性就越高。
给定读者模型、输入问题 q 和相应的一组支持段落 ,我们通过聚合注意力分数获得每个段落的相关分数 (Gq,pk)1≤k≤n。特别地,分数 Gq,pk 是通过对预注意分数 α0 进行平均得到的:在输入 sk 中对应于段落 pk 的所有标记、解码器的所有层和所有头上。请注意,FiD 解码器联合处理段落,因此得分 Gq,pk 取决于其他支持段落。我们考虑其他池运算符,例如 max,以聚合层、头和标记的注意力分数,并在第 5.2节中根据经验对它们进行比较。
在我们继续之前,让我们考虑以下简单的实验,这是读者注意力分数确实是一个很强的相关性信号的第一个迹象。给定一个问题和使用 DPR 检索到的 100 篇文章,我们的目标是选择 10 篇最佳文章。当使用 DPR 的前 10 篇文章而不是前 100 篇文章时,读者的表现从 48.2 EM 下降到 42.9 EM。另一方面,如果我们根据注意力得分选择前 10 个文档,则性能仅下降到 46.8 EM。
用于段落检索的密集双编码器
理想情况下,我们希望根据读者的交叉注意力得分对文章进行排名。然而在实践中,由于文章和问题需要由阅读器模块同时处理,因此以这种方式查询大型知识源是不切实际的。因此,我们使用由嵌入函数 E 组成的检索器模型,该函数将任何文本段落映射到 d 维向量,这样问题 q 和段落 p 之间的相似度得分定义为 Sθ (q, p) = E( q)TE(p)/√d。这种相似性度量使我们能够将知识源中的所有段落作为预处理步骤进行索引。然后在运行时,通过使用 FAISS(Johnson 等人,2019)等高效的相似性搜索库,检索与输入问题相似度最高的段落。
对于嵌入器,我们使用 BERT 并遵循 DPR,考虑到编码 E(q) 和 E(p) 是通过提取初始 [CLS] 令牌的表示获得的。在基本模型的情况下,这导致维度 d = 768 的表示。与 DPR 不同的是,我们通过共享参数对问题和段落使用相同的编码函数 E。
将交叉注意力分数提取到双编码器
在这一部分中,我们描述了如何基于3.2节获得的相关分数来训练检索器模型。对于检索器的训练目标,我们建议在归一化后最小化输出 Sθ (q,p)和得分 Gq,p 之间的 KL- 散度:
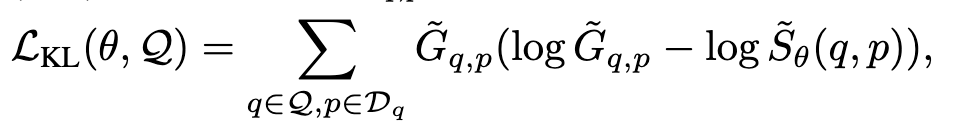
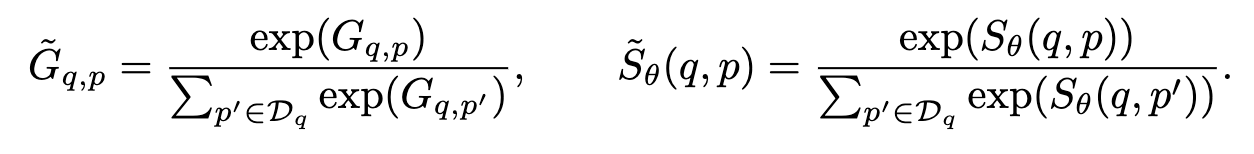
在第5.1节中,我们介绍了在使用这个训练目标的替代方案时取得的结果。我们考虑了 Dehghani 等人(2017)使用的另外两个目标,其中 BM25被用作教师模型来训练神经排序器。第一个选择是通过最小化均方差来训练检索器:
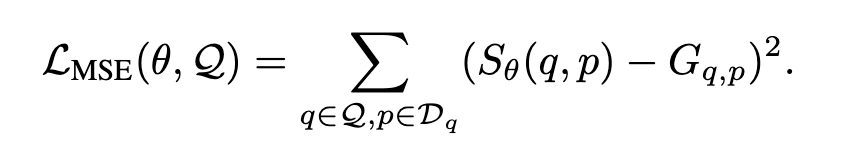
我们考虑的第二个选择是使用最大边际损失,明确惩罚由检索器估计的排名中的倒置:
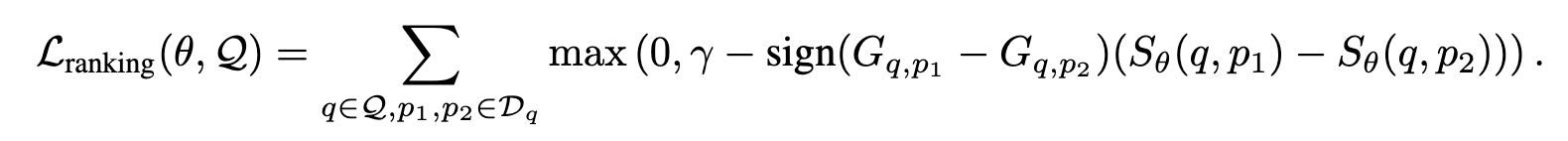
换句话说,如果 p1 比 p2 与回答问题 q 更相关,即 Gq,p1 > Gq,p2,则损失会使 p1 的检索器分数比 p2 的分数至少大 γ 的余量。
数据集
数据集。我们在 TriviaQA (Joshi et al., 2017) 和 NaturalQuestions (Kwiatkowski et al., 2019) 上进行实验,这是开放域问答的两个标准基准。 TriviaQA 由来自琐事和问答联盟网站的问题组成,不包含黄金支持文档。 NaturalQuestions 包含与网络搜索查询相对应的问题,以及来自维基百科的黄金支持文档。遵循Lee等人(2019)的设定;Karpukhin et al(2020),我们使用原始的评估集作为测试集,并保留10%的训练数据进行验证。我们使用 2018 年 12 月 20 日的维基百科转储作为支持文档,将文章拆分为 100 个标记的非重叠段落,并应用与 Chen 等人相同的预处理。 (2017)。
我们还使用公开可用的预处理版本对 NarrativeQuestions (Koˇcisk`y et al., 2018) 进行评估。 这是一个建立在书籍和电影剧本语料库上的阅读理解数据集。对于每个故事,人工注释者都会根据给定文档的摘要生成问题。我们考虑完整的故事设置,其中的任务是根据整个故事回答问题,而不是用于生成问答对的摘要。在这里,所有问题的知识来源都不相同:给定一个问题,检索操作是在相关故事的所有段落上执行的。这些段落是通过将故事分成 100 个单词的块来获得的。这些故事是很长的文档,平均有 60k 字。虽然部分文档可以完全由 Fusion-in-Decoder 模块处理,但有趣的是限制支持段落的数量以减少阅读步骤的计算成本。
虽然 TriviaQA 和 NaturalQuestions 中的答案很短,但 NarrativeQA 的答案平均大约五个字长,中等长度的答案例如“他拆掉它并将它连接到他母亲的吉普车上”回答了“马克用他的广播电台做了什么”的问题?”。值得注意的是,大量答案与故事中的跨度不符。因此,使用问答对通过启发式方法训练检索器并不简单。在我们的案例中,我们使用与 TriviaQA 和 NaturalQuestions 相同的管道,展示了我们方法的灵活性。
评估。模型性能通过两种方式进行评估。首先,在 DPR 和 ColbertQA 等之前的工作之后,我们报告了 top-k 检索准确度 (R@k),即在 top-k 检索到的段落中至少有一个段落包含黄金答案的问题的百分比。目前尚不清楚该指标如何评估检索器的性能,因为答案可以包含在与问题无关的段落中。对于常用词或实体尤其如此。
我们还报告了由检索器和阅读器模块组成的问答系统的最终端到端性能。这是我们从根本上感兴趣的指标。对于 TriviaQA 和 NaturalQuestions,预测答案使用标准精确匹配指标 (EM) 进行评估,如 Rajpurkar 等人所介绍的(2016)。对于 NarrativeQA,我们报告了原始论文中提出的指标:ROUGE-L、BLEU-1、BLEU-4 和 METEOR。
初始化。与 DPR 类似,我们使用 BERT 基础模型初始化检索器,并使用未区分大小写的文本进行预训练。 Fusion-in-Decoder 阅读器使用 T5 基本模型进行初始化。迭代训练过程的一个关键组成部分是与每个问题 q 相关联的支持段落 的初始化。为此,我们考虑不同的选择。第一种方法是使用使用BM25检索的段落。我们使用带有默认参数的 Apache Lucene2 的实现,并使用 SpaCy3 标记问题和段落。我们还使用 BERT 获得的段落作为检索器而不进行微调,这会导致初始性能不佳。最后,在表 2 中,我们表明使用 DPR(Karpukhin 等人,2020)获得的段落初始化
优于之前的两个初始化。我们使用 100 篇文章训练所有的检索器。对于读者,我们为 NaturalQuestions 和 TriviaQA 使用 100 篇文章,为 NarrativeQA 使用 20 篇文章。
迭代训练。我们独立地对每个数据集应用迭代训练程序。读取器和检索器都使用 ADAM 算法 (Kingma & Ba, 2014) 进行微调,批量大小为 64。读取器经过 10k 梯度步长训练,学习率为 10−4,最佳根据验证性能选择模型。检索器以 5 · 10−5 的恒定学习率进行训练,直到性能饱和。为了在训练期间监控检索器的表现,我们测量了阅读者和检索器排名之间的相似性。在每次新的训练迭代中,阅读器从 T5 -base重新初始化,而我们继续训练检索器。我们发现从 T5 base 重新启动对于从 BERT 文档开始的第一次迭代很重要。我们没有尝试在每次迭代之间重新初始化检索器。附录 A.2 中报告了有关超参数和训练过程的更多详细信息。