一、前言
入坑SLAM也有一年了,也看了不少视觉SLAM的方法,最近也开始涉猎一些激光SLAM的方法,在看的这些方法中,大多数的重点都放在了前端的部分,因为师兄说过大多数的SLAM方法后端都没什么变化,都是画因子图然后做BA优化,趁着疫情在宿舍封控,理顺一下这一年看SLAM的理解。
二、前端
首先明确前端的用途,个人理解前端就是计算两帧之间的位姿变换关系T,对于视觉SLAM来说,就是用两帧图像来计算,而对于激光SLAM来说就是用两帧点云来计算,但最终目标都是计算这个T。
针对于这两大SLAM分支,不同的分支有不同的计算方法,这是针对于传感器得到数据的特点做的适应性处理。对于视觉SLAM,数据是两帧图像,也就是两张照片,相较于点云,图像表示方便而且数据量要小,对于一些光照特征有着很好的表现性能,所以在视觉SLAM中延伸出特征点法、直接法和半直接法,这三种方法都用的是图像上的局部特征。而对于激光SLAM,点云规模大而且不规则,所以没有办法像视觉SLAM那样海量提取特征,一般使用像NDT/ICP/LOAM这些方法来进行位姿计算,激光SLAM中位姿计算的过程貌似也可以称为点云配准。
前端其实是大多数SLAM方案玩花样玩得最多的地方,拿视觉SLAM来说,从计算帧间位姿的方法可以分为特征点法、直接法和半直接法。特征点法顾名思义,用图像中的特征点进行匹配,匹配之后先通过对极几何计算出两帧之间的位姿,再用位姿进行三角化恢复特征点的空间信息,也就是恢复出深度信息。深度信息是视觉SLAM一个很关键的问题,因为视觉不能像激光SLAM那样直接就得到深度,必须要经过三角化这个步骤来计算深度,当然双目相机和RGBD相机除外,双目相机可以利用视差计算深度,RGBD也可以利用传感器获得深度,而对于单目相机来说,就只能用相邻的两帧图像来计算深度。在特征点法的基础上,又延伸出特征线甚至特征面法,因为线和面包含的特征信息是要比点多的,所以按道理这些方法是可以提升视觉SLAM的性能的,但是貌似是受限于优化和匹配的方法,所以目前的主流依然还是点特征。特征点法典型的算法包括ORBSLAM/VINS-MONO,简直就是视觉SLAM必须要看的论文。而线特征和面特征显然要少很多,线特征比较出名的是PL-SLAM/PL-SVO,但它是基于半直接法的。
直接法则少了提取特征点并匹配的过程,个人理解这种方法实际上就是利用了一个图像局部相似性,省略了在当前帧图像上提取特征的步骤。它的核心是将上一帧的特征点直接投影到当前帧,然后比较投影位置的局部相似程度,其实和我们提取特征点是相同的,只不过我们直接用局部相似性而不做提取的步骤。这个方法貌似没看到很出名的论文使用这个方法,很大一个可能是本人论文涉猎程度不广。
半直接法则介于前面两种方法之间,有点不伦不类的味道了,这个方法有一个很出名的论文就是前面提到的SVO,准确的说半直接法就是SVO这篇论文里面提出来的。但是现在仔细想想,这个半直接法貌似和直接法区别不那么大,可以查看以前记录的SVO的论文笔记。
二、后端
前端得到的位姿,是一个小范围的位姿,由于累积误差的存在,这个偏差会越来越大,所以需要回环检测和校正来优化这个流程。当然,回环检测和优化是出现回环时才用得到,而没有回环时,也就需要后端去承担一定的责任。
之前对后端理解一直不到位,这几天看了点网课,稍微加深了一点理解。简单来说,和神经网络差不多,后端也是个最小化偏差的过程,而这个误差,其实就是前面前端过程中的观测关系的累积。一般的优化,优化的对象就是前面相机的位姿以及路标点的坐标,而这些量都会作为一个整体,也就是待优化向量参与到优化过程,既然是优化,那么必然有一个损失函数,考虑到不同方法传感器类型的差别,所以损失函数这里我们就按照各个偏差的和来理解,我们希望总体的误差最小,就需要不断对待优化向量做调整,来逐步减小损失函数的值。这个过程涉及到一些数值优化的方法,比如牛顿法、高斯牛顿法等,牵扯到雅可比矩阵和海森矩阵的计算,这些都是一些比较乱的数学计算,当然能理顺清楚的话其实也没那么难,这里可以参考教学视频的讲解。
而在实际的SLAM项目中,并不会暴力去计算后端的这些内容,因为大多数时间我们都是在使用现成的库文件,比如g2o库等,使用这些库,像库中描述图优化的一些边、点的约束条件,剩下的就交给库去执行计算了,因为可以使用一些图论的知识,所以在一些情况下计算的时间开销会更加优秀。不仅如此,一些IMU等约束条件也可以一起加入其中,在此基础上又延伸出紧耦合和松耦合这些区别,这些其实就涉及到多传感器融合的部分了,紧耦合将其他传感器的内容作为约束一起优化得到一个结果,而松耦合将不同传感器计算结果分别计算后融合多个结果。
BA优化将位姿和地图点都作为优化的对象,在运行一段时间之后,开销会明显增大,所以又出现了因子图优化,它的意义在于在优化几次以后把特征点固定住不再优化,只当做位姿估计的约束,之后主要优化位姿。
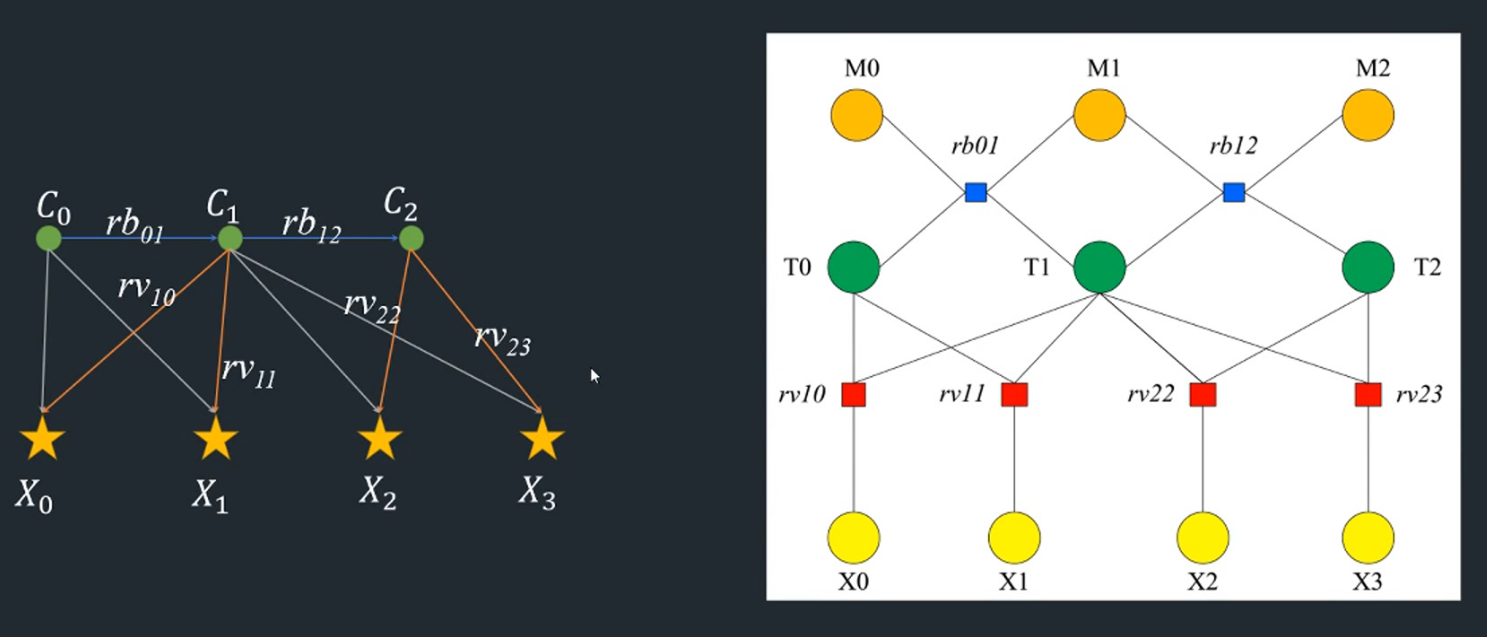
至于因子图优化和BA优化有啥区别,网上说啥的都有,有说是一个东西的,也有说要分开理解的。本人更倾向于将其都看做一种东西,位姿图优化和BA优化都是slam中的具体问题,可以使用前面提到的优化方法进行优化,BA优化中,路标点和位姿都是不确定的,都是优化变量。位姿图优化,假设路标点是确定的,优化变量只有位姿,路标点成了约束。
简单总结一下,因子图优化和BA优化都是后端优化的具体方法,区别在于路标点是作为约束还是作为优化的量,解决这两个优化问题,都需要使用到非线性优化的方法,也就是图优化的知识,其中涉及到图论和高斯牛顿法等理论知识。两种方法的目的都是让整体更加准确,这也就是后端的目标。
参考链接:https://www.zhihu.com/question/389810365