项目链接:https://pan.baidu.com/s/1yOu0DogWkL8WOJksJmeiPw?pwd=4bsg 提取码: 4bsg 复制这段内容后打开百度网盘手机App,操作更方便哦
--来自百度网盘超级会员v4的分享
1.基于上一篇文章中的文本分类项目进行精度调优,提升模型准确率,需要改动的地方除了参数以外,就是模型结构,这里主要就是进行模型结构调优,因此代码只需要修改rnn_model.py,修改前后代码如下:
原模型结构:
双层LSTM+两层全连接神经网络+softmax
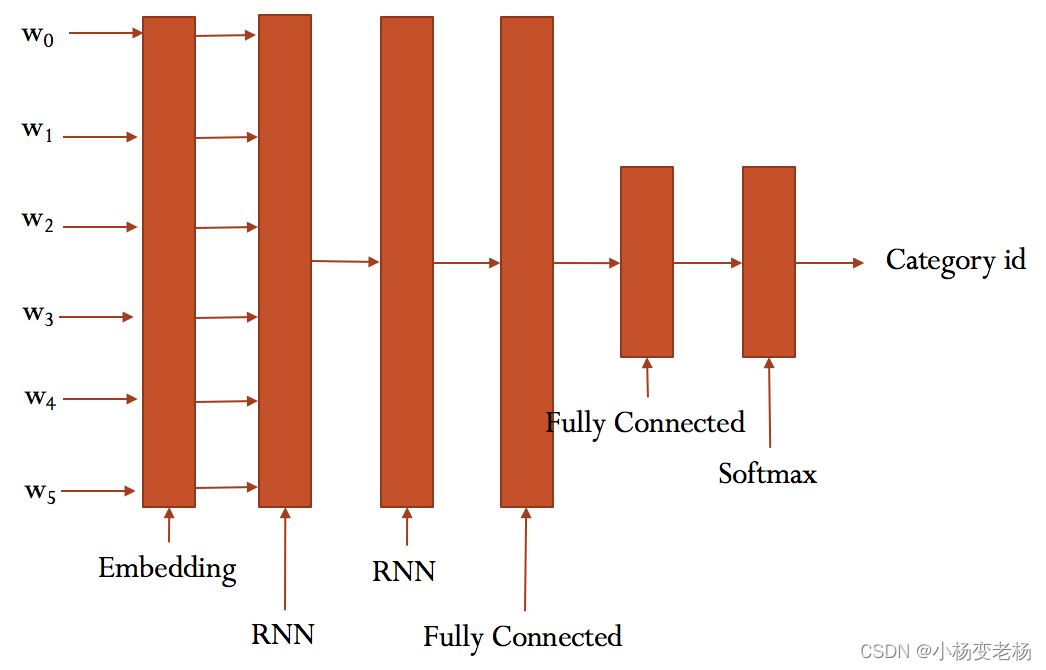
原模型代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import tensorflow as tf
class TRNNConfig(object):
"""RNN配置参数"""
# 模型参数
embedding_dim = 64 # 词向量维度
seq_length = 600 # 序列长度
num_classes = 10 # 类别数
vocab_size = 5000 # 词汇表达小
num_layers= 2 # 隐藏层层数
hidden_dim = 128 # 隐藏层神经元
rnn = 'gru' # lstm 或 gru
dropout_keep_prob = 0.8 # dropout保留比例
learning_rate = 1e-3 # 学习率
batch_size = 128 # 每批训练大小
num_epochs = 10 # 总迭代轮次
print_per_batch = 100 # 每多少轮输出一次结果
save_per_batch = 10 # 每多少轮存入tensorboard
class TextRNN(object):
"""文本分类,RNN模型"""
def __init__(self, config):
self.config = config
# 三个待输入的数据
self.input_x = tf.placeholder(tf.int32, [None, self.config.seq_length], name='input_x')
self.input_y = tf.placeholder(tf.float32, [None, self.config.num_classes], name='input_y')
self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')#定义dropout占位符,输入失活比例
self.rnn()
def rnn(self):
"""rnn模型"""
def lstm_cell(): # lstm核
return tf.contrib.rnn.BasicLSTMCell(self.config.hidden_dim, state_is_tuple=True)
def gru_cell(): # gru核
return tf.contrib.rnn.GRUCell(self.config.hidden_dim)
def dropout(): # 为每一个rnn核后面加一个dropout层
if (self.config.rnn == 'lstm'):
cell = lstm_cell()
else:
cell = gru_cell()
return tf.contrib.rnn.DropoutWrapper(cell, output_keep_prob=self.keep_prob)
# 词向量映射
with tf.device('/cpu'):
embedding = tf.get_variable('embedding', [self.config.vocab_size, self.config.embedding_dim]) # [5000, 64]
embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x) # [?, 600, 64]
with tf.name_scope("lstm"):
'''
TF 低版本RNN多层获取cell,使用一下代码
cell = rnn.BasicLSTMCell(hidden_size, state_is_tuple=True)
cell = rnn.MultiRNNCell([cell] * 2, state_is_tuple=True)
'''
# 多层rnn网络
cells = [dropout() for _ in range(self.config.num_layers)]
rnn_cell = tf.contrib.rnn.MultiRNNCell(cells, state_is_tuple=True)
_outputs, _ = tf.nn.dynamic_rnn(cell=rnn_cell, inputs=embedding_inputs, dtype=tf.float32) # [?, 600, 128]
last = _outputs[:, -1, :] # 取最后一个时序输出作为结果 # [?, 128]
with tf.name_scope("score"):
# 全连接层,后面接dropout以及relu激活
fc = tf.layers.dense(last, self.config.hidden_dim, name='fc1')
fc = tf.contrib.layers.dropout(fc, self.keep_prob)
fc = tf.nn.relu(fc)
fc=tf.layers.dense(fc,units=64,name='fc2')
fc = tf.contrib.layers.dropout(fc, self.keep_prob)
fc = tf.nn.relu(fc)
fc = tf.layers.dense(fc, units=32, name='fc3')
fc = tf.contrib.layers.dropout(fc, self.keep_prob)
fc = tf.nn.relu(fc)
# 分类器
self.logits = tf.layers.dense(fc, self.config.num_classes, name='fc4')
self.y_pred_cls = tf.argmax(tf.nn.softmax(self.logits), 1) # 预测类别
with tf.name_scope("optimize"):
# 损失函数,交叉熵
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=self.input_y)
self.loss = tf.reduce_mean(cross_entropy)
# 优化器
self.optim = tf.train.AdamOptimizer(learning_rate=self.config.learning_rate).minimize(self.loss)
with tf.name_scope("accuracy"):
# 准确率
correct_pred = tf.equal(tf.argmax(self.input_y, 1), self.y_pred_cls)
self.acc = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
修改为双层双向LSTM+4层全连接神经网络+softmax
#!/usr/bin/python
# -*- coding: utf-8 -*-
import tensorflow as tf
class TRNNConfig(object):
"""RNN配置参数"""
# 模型参数
embedding_dim = 64 # 词向量维度
seq_length = 600 # 序列长度
num_classes = 10 # 类别数
vocab_size = 5000 # 词汇表达小
num_layers= 2 # 隐藏层层数
hidden_dim = 128 # 隐藏层神经元
rnn = 'gru' # lstm 或 gru
dropout_keep_prob = 0.8 # dropout保留比例
learning_rate = 1e-3 # 学习率
batch_size = 128 # 每批训练大小
num_epochs = 10 # 总迭代轮次
print_per_batch = 100 # 每多少轮输出一次结果
save_per_batch = 10 # 每多少轮存入tensorboard
class TextRNN(object):
"""文本分类,RNN模型"""
def __init__(self, config):
self.config = config
# 三个待输入的数据
self.input_x = tf.placeholder(tf.int32, [None, self.config.seq_length], name='input_x')
self.input_y = tf.placeholder(tf.float32, [None, self.config.num_classes], name='input_y')
self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')#定义dropout占位符,输入失活比例
self.rnn()
def rnn(self):
"""rnn模型"""
def lstm_cell(): # lstm核
return tf.contrib.rnn.BasicLSTMCell(self.config.hidden_dim, state_is_tuple=True)
def gru_cell(): # gru核
return tf.contrib.rnn.GRUCell(self.config.hidden_dim)
def bilstm_cell():
return tf.contrib.rnn.BasicLSTMCell(self.config.hidden_dim)
def dropout(): # 为每一个rnn核后面加一个dropout层
if (self.config.rnn == 'lstm'):
cell = lstm_cell()
else:
cell = gru_cell()
return tf.contrib.rnn.DropoutWrapper(cell, output_keep_prob=self.keep_prob)
# 词向量映射
with tf.device('/cpu'):
embedding = tf.get_variable('embedding', [self.config.vocab_size, self.config.embedding_dim]) # [5000, 64]
embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x) # [?, 600, 64]
with tf.name_scope("lstm"):
'''
TF 低版本RNN多层获取cell,使用一下代码
cell = rnn.BasicLSTMCell(hidden_size, state_is_tuple=True)
cell = rnn.MultiRNNCell([cell] * 2, state_is_tuple=True)
'''
cell_fw=[dropout() for _ in range(self.config.num_layers)]
cell_bw=[dropout() for _ in range(self.config.num_layers)]
lstm_forward = tf.contrib.rnn.MultiRNNCell(cells=cell_bw, state_is_tuple=True)
lstm_backward=tf.contrib.rnn.MultiRNNCell(cells=cell_fw, state_is_tuple=True)
outputs, states = tf.nn.bidirectional_dynamic_rnn(cell_fw=lstm_forward, cell_bw=lstm_backward, inputs=embedding_inputs,
dtype=tf.float32)
outputs_fw = outputs[0]
outputs_bw = outputs[1]
last = outputs_fw[:, -1, :] + outputs_bw[:, 0, :] # 取最后一个时序输出作为结果 # [?, 128]
with tf.name_scope("score"):
# 全连接层,后面接dropout以及relu激活
fc = tf.layers.dense(last, self.config.hidden_dim, name='fc1')
fc = tf.contrib.layers.dropout(fc, self.keep_prob)
fc = tf.nn.relu(fc)
fc=tf.layers.dense(fc,units=64,name='fc2')
fc = tf.contrib.layers.dropout(fc, self.keep_prob)
fc = tf.nn.relu(fc)
fc = tf.layers.dense(fc, units=32, name='fc3')
fc = tf.contrib.layers.dropout(fc, self.keep_prob)
fc = tf.nn.relu(fc)
# 分类器
self.logits = tf.layers.dense(fc, self.config.num_classes, name='fc4')
self.y_pred_cls = tf.argmax(tf.nn.softmax(self.logits), 1) # 预测类别
with tf.name_scope("optimize"):
# 损失函数,交叉熵
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=self.input_y)
self.loss = tf.reduce_mean(cross_entropy)
# 优化器
self.optim = tf.train.AdamOptimizer(learning_rate=self.config.learning_rate).minimize(self.loss)
with tf.name_scope("accuracy"):
# 准确率
correct_pred = tf.equal(tf.argmax(self.input_y, 1), self.y_pred_cls)
self.acc = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
修改结束后,记得在原项目中的TextRNN\checkpoints\textrnn中将训练好的模型删除,避免冲突。
注:如使用tensorflow gpu版本进行模型训练,将with tf.device('/cpu'):改为with tf.device('/gpu:0'):
注:可通过此命令下载scikit-learn包:conda install -c anaconda scikit-learn 注:(安装sklearn)
注:conda环境:
conda create -n 环境名 python=版本号 : 新建虚拟环境
activate 环境名 进入环境
conda deactivate 退出
conda env list 显示环境
conda remove -n 环境名 --all