作者 | 胖虎
转载自Python3X(ID: python3xxx )
爬取公众号的方式常见的有两种:
通过搜狗搜索去获取,缺点是只能获取最新的十条推送文章。
通过微信公众号的素材管理,获取公众号文章。缺点是需要申请自己的公众号。
今天介绍一种通过抓包PC端微信的方式去获取公众号文章的方法。相比其他的方法非常方便。

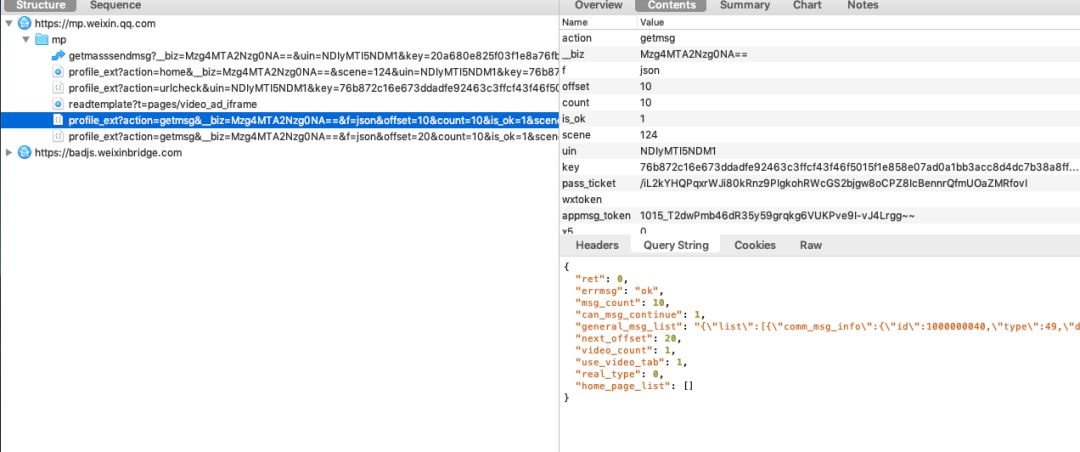
如上图,通过抓包工具获取微信的网络信息请求,我们发现每次下拉刷新文章的时候都会请求 mp.weixin.qq.com/mp/xxx (公众号不让添加主页链接,xxx表示profile_ext) 这个接口。
经过多次测试分析,用到了以下几个参数
__biz : 用户和公众号之间的唯一id,
uin :用户的私密id
key :请求的秘钥,一段时候只会就会失效。
offset :偏移量
count :每次请求的条数
数据如下:
部分代码如下:
最后打印的list就是公众号的文章信息详情。包括标题(titile)、摘要(digest)、文章地址(content_url)、阅读原文地址(source_url)、封面图(cover)、作者(author)等等...
输出结果如下:
获取数据之后,可以保存到数据库中,也可以将文章保存在PDF中。
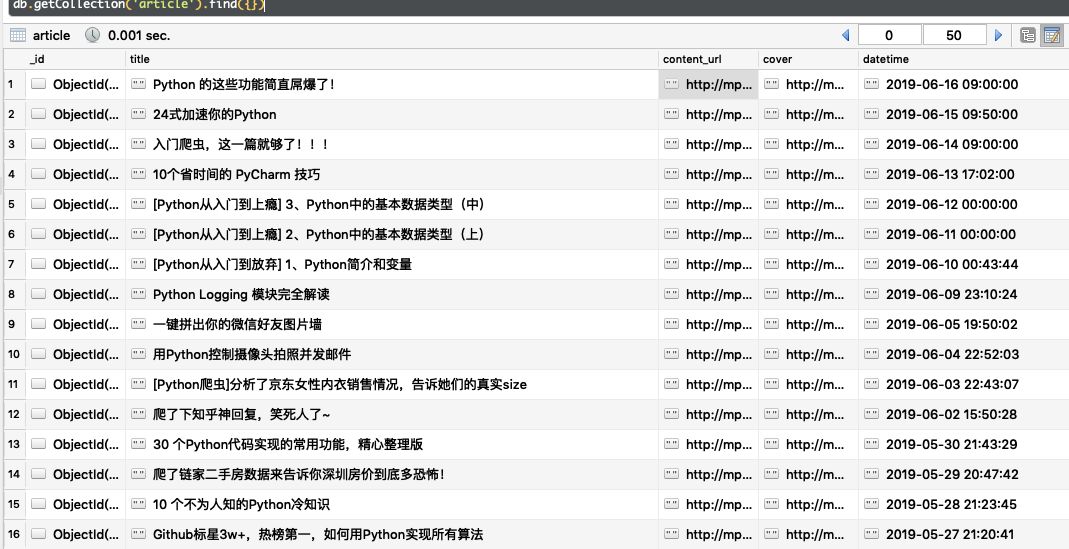
1、保存在Mongo中
结果如下:
2、导入到PDF文件中
Python3中常用的操作PDF的库有python-pdf和pdfkit。我用了pdfkit这个模块导出pdf文件。
pdfkit是工具包Wkhtmltopdf的封装类,因此需要安装Wkhtmltopdf才能使用。
可以访问 https://wkhtmltopdf.org/downloads.html 下载和操作系统匹配的工具包。
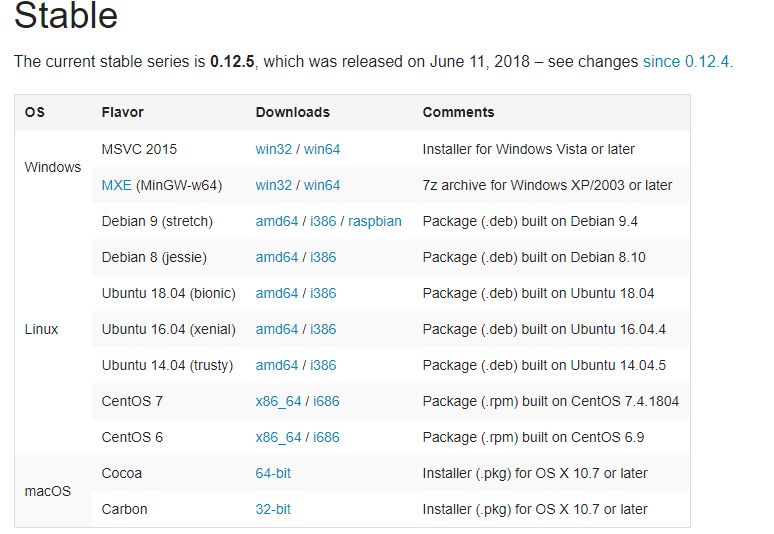
实现代码也比较简单,只需要传入导入文件的url即可。
安装pdfkit库:
运行之后成功导出pdf文件:
完整代码
(*本文为 AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆

推荐阅读
阿里达摩院刷新纪录,开放域问答成绩比肩人类水平,超微软、Facebook
200行代码实现一个滑动验证码
收藏!本、硕、博、程序员必备神器
三十四载Windows崛起之路: 苹果、可视做过微软“铺路石”
苹果首席设计师离职,或因库克对设计没兴趣?
孩子学编程,更要学算法编程!否则你的机械键盘传给谁?
物联网终端五年后将超 270 亿!破竹之势下程序员如何修炼内功?
视频 |「以太坊开发训练营」如何带你安全、高效跑通以太坊开发全流程! 收藏!
百度自动驾驶新突破:获首批T4牌照,升级Apollo 5.0,将进行复杂城市场景路测
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢