【快速排序——详解】(上)
在介绍快速排序之前我们必须要了解一下冒泡排序
下面我就简单的介绍一下冒泡排序
(一) 冒泡排序
例如:现有一个10个元素的数组并对其进行“冒泡排序”。
那么总共比较了多少次呢?
答:总共45次
排序过程大体为如下所示:
第1次排序:用第1个元素与其他9个元素依次进行比较,
所以第一次排序总共比较了9次,并得到全数组中最小的一个元素(放在数组的第1个元素位置上)
第2次排序:由于经过上次排序,所以得到了一个已排序好的元素(即:数组的第1个元素)。
所以这次排序要从第2个元素开始,用第2个元素与剩下的其他8个元素依次比较。
(第二次排序总共比较了8次)
并得出一个全数组中“第二小”的元素。(即:仅次于第1个元素小的元素)即:升序
然后按照上述方法以此类推
所以整个冒泡排序的总比较次数为
9次+ 8次+ 7次+ 6次+ 5次+ 4次+ 3次+ 2次+ 1次 = 45次
我们可以利用如下公式来得到冒泡排序所需要比较次数总和。
// n 为数组长度
即公式:(n-1) * (n-1+1) / 2
例如:对5个元素的数组采用冒泡排序需要比较 (5-1)* (5-1+1) / 2 = 10次
假如我们要利用冒泡排序分别对2组数据进行排序
A组为:一个10个元素的数组(即: A[10])
B组为:两个5个元素的数组(即:B1[5] 与 B2[5] )
请问是A组花费的比较次数多还是B组所花费的比较次说多呢?还是一样多呢?
答:前者所花费的比较次数最多。
套用公式 (n-1) * (n-1+1) / 2
A组:
数组A[10] 即:n = 10
(10-1) * (10-1+1) / 2 = 45次
所以A组总共比较了45次
B组:
数组B1[5] 即: n = 5
(5-1) * (5-1+1) / 2 = 10次
因为因为B组中比较的2个数组长度一致,所以B组总共比较了20次。
通过上面的实例说明了什么?
答:说明了范围小的数组(即:长度小的数组),比较的范围就小,
所以比较的次数就相对来说会少。
那么这个规律又和“快速排序”有什么关系呢?
其实“快速排序”的目地就是将一个范围较大的数组分割为几个范围较小的数组。
然后再分别再对这些小数组进行排序。
那么“快速排序”是怎么将一个数组分为几个小数组?而后又是怎么对其进行排序的呢?
关于这个疑问我会在《快速排序——详解》(中)中进行详细的介绍。
———————————————————————————————————————————————————————
【快速排序——详解】(中)
在介绍快速排序之前一定要知道什么是“中值”?
(“中值”的好坏决定了排序效率的好坏)
所谓“中值”
即:最佳理想情况下“中值”就是一个数组中“既不最大,也不最小”,而是大小最为适中的那个元素。
例如:A[9] = {2, 9, 6, 1, 5, 7, 8, 3, 4}那么数组A里的最佳理想的“中值”就是 5
本文以介绍“快速排序”算法为主,关于如何找到一个数组中相对来说较为理想的中值,在这里就不介绍了。
在下面的部分中,我们暂设定最佳中值就是数组中最中间的那个元素。
(这样做的目的只是为了讲解方便而已)
“快速排序”本质就是“分而治之”,也就是将一个数组划分为2部分。
即:低于中值的部分(这里简称: LA) 和 高于中值的部分(这里简称: HA)
然后在LA 和 HA 中再分别的找出他们各自内部的中值
并按照他们各自的中值在其内部再划分出高于中值和低于中值的部分,然后以此类推。
下面以数组A举例来阐述一下快速排序的执行过程:
原始数组A为: A[9] = {2, 9, 6, 1, 5, 7, 8, 3, 4}
进行排序…
第一步:
寻找中值。这里我们假定最佳中值就是数组里最中间的那个元素。
即:(n/2)+1 // n为数组长度
第二步:
为了排序起来更加方便,我们先将中值与数组中的最后一个元素交换,
使其“可排序的范围”是一个连续的空间,这样一来排序就变得方便多了。
此时调换完中值的数组A为:A[9] = {2, 9, 6, 1, 7, 8, 3, 4, 5}
(不妨对照一下原始数组A,看看发生了那些变化)
第三步:(正式开始排序)
首先从数组的最左端起依次选取每个元素与中值(即:数组的最后一个元素) 进行比较
(即:自左至右)
当发现有元素大于中值时,则先暂停比较,并暂时记录下这个元素的位置。
然后此时再从数组的
“倒数第二位”开始取每个元素与“中值”进行比较(即:自右至左)
(注:之所以要从数组的“倒数第二位”开始取元素,那是因为当前数组的倒数第一位存放的内容是“中值”自身)
当发现有小于中值的元素时则先暂停比较,然后将这个小于中值的元素与稍早前最左边发现的那个大于中值的元素进行交换。
已达到小于中值的元素靠近数组左侧,大于中值的靠近数组右侧的目的,然后反复进行上面的步骤。
即:在左侧找到一个大于中值的元素后,再从右侧找到一个小于中值的元素,然后将他们相互交换,直到所有元素都与中值比较过为止。
(也就是说“左端取的元素与右端取的元素出现重复相交时停止”)
听起来有些难懂?不要紧先看代码。如果还看不懂? 再看“排序演示”说明~
部分代码如下:
L = -1;
R = n -1; // n为数组长度
do
{
/*
* 当A[++L]大于中值时则跳出循环
* L存放的内容就是大于中值元素的元素下标
*/
While ( A[++L] < 中值 ) ; // 无执行体
/*
* 当A[--R]小于中值时则跳出循环
* R存放的内容就是小于中值元素的元素下标
*/
While ( (R!=0) && A[--R] > 中值) ; // 无执行体
/*
* 将数组A中的L, R元素交换
* 使得小于中止的靠近数组左端大于中值元素靠近右端
*/
Swap(A, L, R)
}
/*
* 当左端取的元素与右端取的元素出现重复相交时停止
* (也就是所有元素都与中值比较过为止)
*/
while( L < R )
// 到此为止,此时的数组已经根据中值划分为大于中值和小于中值的2部分了。
排序结果演示(这里忽略排序细节,只呈现每个步骤的结果):
(1) 现有数组A(准备对其进行快速排序,红色为中值):A[9] = {2, 9, 6, 1, 5, 7, 8, 3, 4}
(2) 将中值调换位置:A[9] = {2, 9, 6, 1, 4, 7, 8, 3, 5}
(3) 用中值与数组中的元素进行比较,小于中值的元素靠近左侧,大于的则靠近右侧:
A[9] = {2, 3, 5, 1,6, 7, 8, 9,5}
粉色代表:小于中值的部分。
棕色代表:大于中值的部分。
注意 “蓝色”位置的元素是“高于中值的那部分”里的第一个元素。
看只要将蓝色的元素与中值调换后数组就划分好了。
(4) 将高于中值部分中的第一个元素与中值交换:
A[9] = {2, 3, 5, 1,5, 7, 8, 9, 6}
看! 第一次范围划分就完成了。
按照上述步骤我们再反复对大于中值和小于中值的2部分进行划分,最后一个数组就排序完毕了。
上面已经说到了快速排序就是反复的对数组进行划分范围,直到每个划分的子范围内的
元素个数为3个时(即:中值在中间,小于和大于中值的部分在中值两侧),一个数组就排序好了。
但值得注意的是一般情况下采用快速排序划分数组的时候
当将子范围划分到一定程度时(例如:子数组的元素个数为10个时)就应当停止划分,
然后再对其子数组使用其他的排序算法(例如:插入排序)
这样做能提高排序效率。
我将会在
————————————————————————————————————————————————————————
// 快速排序 (标准版)
package cx.sort;
/**
* @function : 快速排序(标准版)
*/
public class QuickSort
{
// 排序
public void sort(int[] data)
{
quickSort(data, 0, data.length - 1);
}
/**
* @param data 排列的数组
* @param i 第一元素的下标
* @param j 最后一个元素的下标
*/
private void quickSort(int[] data, int i, int j)
{
// 确定中值(假定最佳中值为数组最中间的元素)
int pivotIndex = (i + j) / 2;
/*
* 为了便于排序,
* 将中值放置到数组的最后一个位置上。
*/
swap(data, pivotIndex, j);
/*
* 将数组划分为小于中值和大于中值的两个部分
* 小于中值的部分的靠近左侧,
* 大于中值的则靠近右侧。
* k为大于中值那部分的第1元素的下标位置。
* (也就是小于中值部分后面的那位元素下标)
*/
int k = partition(data, i - 1, j, data[j]);
/*
* 将中值(即: 数组的最后一位)与
* "大于中值部分"中的第一元素交换
* 以保证从中值开始向左都是小于中值的内容,
* 向右则都是大于中值的内容。
*/
swap(data, k, j);
/*
* 以中值为界标,
* 对中值左半部份的内容
* (即:小于中值的部分)再次划分
*/
/*
* 如果"左"半部份的长度大于1个元素]
* 则可以继续进行划分
*/
if ((k - i) > 1)
{
/*
* 将中值左侧的部分
* (即:小于中值的部分)继续进行划分。
* 之所以不包括中值(即:k-1)的原因是:
* 中值的位置已经被确立
* 无需在比较了。
* 为什么呢? 因为:
* (1)中值左侧的元素都是小于中值的,
* 也就是说中值是左侧元素里面
* 最大的那个元素,所以按照升序排列,
* 中值则是他们的最后一位。
* (2)中值右边的元素都是大于中值的,
* 所以右侧中的每个元素都会大于中值,
* 所以中值相对于右侧的元素来说就是最小的元素,
* 所以按照升序排列,应放在右侧的第一位。
*/
quickSort(data, i, k - 1);
}
/*
* 以中值为界标,对中值右半部份的内容(即:大于中值的部分)再次划分
*/
// (如果"右"半部份的长度大于1个元素则继续进行划分)
if ((j - k) > 1)
{
quickSort(data, k + 1, j);
}
}
/**
*
* @param data 目标数组
* @param l 数组的最左侧元素位置
* @param r 数组的最右侧元素位置
* @param pivot 中值
* @return 大于中值的部分的第一元素位置的下标(即:右侧的第一元素下标)
*/
private int partition(int[] data, int l, int r, int pivot)
{
do
{
/*
* L 保存的是从左侧开始依次每个元素的下标。
* 当 data[++l] 不再小于中值时(pivot)
* (也就是左侧出现大于中值的元素时),则会跳出循环。
* 此时L保存的下标就是大于中值的那个元素的下标。
*/
while (data[++l] < pivot)
{
// 无执行体(因为条件本身就是执行体)
}
/*
* R 保存的是从右侧开始依次每个元素的下标。
* 当 data[--r] 不再大于中值时(pivot)
* (也就是右侧出现小于中值的元素时),则会跳出循环。
* 此时r保存的下标就是小于中值的那个元素的下标。
*/
while ((r != 0) && data[--r] > pivot)
{
// 无执行体(因为条件本身就是执行体)
}
/*
* 将左侧大于中的元素与右侧小于中值的元素交换,
* 以保证靠近左侧的都是小于中值的元素,
* 靠近右侧则是大于中值的元素。
*/
swap(data, l, r);
}
// 如果所有元素都与中值比较过则跳出循环 (即:左侧下标l与右侧r相交时)
while (l < r);
swap(data, l, r);
return l;
}
private void swap(int[] data, int i, int j)
{
int tmp = data[i];
data[i] = data[j];
data[j] = tmp;
}
public static void main(String[] args)
{
int[] data =
{ 1, 22, 19, 10, 13, 11, 8, 100, 18 };
System.out.println("原始: ");
System.out.println(java.util.Arrays.toString(data));
System.out.println();
new QuickSort().sort(data);
System.out.println(java.util.Arrays.toString(data));
}
}
————————————————————————————————————————————————————————
快速排序法(QuickSort)是一种非常快的对比排序方法。它也Divide-And-Conquer思想的实现之一。自从其产生以来,快速排序理论得到了极大的改进,然而在实际中却十分难以编程出正确健壮的代码。本文将对快速排序算法的基本理论和编程实践方面做作一个全面的讲解。在本文讲解中,将忽略很多细枝末节,试图给读者形成一个非常具体的快速排序形象。
1.快速排序---基本理论
因为该算法是Divide-And-Conquer思想的一个实现,所以本文将以Divide-And-Conquer思想对其进行分析。首先,假设所要排序的数字存储在数组S中,则该算法的操作可以拆分为两部分:
在S中选出一个元素v;
将S数组分为三个子数组。其中v这个元素单独形成子数组1,比v小的元素形成子数组2,比v大的元素形成自数组3.
分别对子数组2和子数组3进行前两步操作,实现递归排序;
返回时,依次返回S1,V,S2;
该程序具有平均运行时间T(n) = O(nlgn), 最差运行时间T(n) = O(n^2);
下面给出一个简单的排序实例对以上算法进行简单说明:
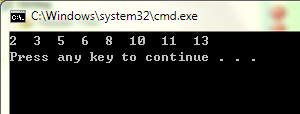
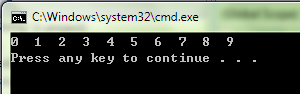
初始数组为--------------> S: 6,10,13,5,8,3,2,11
将第一个元素赋值给v----->v = 6;
以v为标准将S进行拆分--->[2,5,3],[6],[8,13,10,11]
同样对子数组S1进行拆分->[ ], [2], [ 5, 3]
对子数组S2进行拆分----->[ ], [8], [13, 10, 11]
此时的数组S为---------->2,5,3,6,8,13,10,11
对子数组S12进行拆分---->[3], [5],[ ];
对自数组S22进行拆分---->[10,11],[13],[]
此时的数组S为----------->2,3,5,6,8,10,11,13
对子数组S221进行拆分--->[ ], [11], [13]
对后得到的数组为-------->2,3,5,6,8,10,11,13;
根据以上分析,编写快速排序算法程序,得到的程序如下:

1 #include
2 #include
3
4 using namespace::std;
5
6 int Partition( int A[], int p, int q ) //这里是以第一个为mid
7 {
8 int key = A[p];
9 int i = p;
10 for(int j = p + 1 ;j <= q; j++ ) //这里应该是=q,最后一个数要遍历到
11 {
12 if( A[j] <= key )
13 {
14 i++;
15 swap(A[i], A[j]);
16 }
17 }
18 swap(A[p], A[i]);
19 return i;
20 }
21
22 void QuickSort( int A[], int p, int q )
23 {
24 if( p < q )
25 {
26 int r = Partition(A, p, q);
27 QuickSort(A,p,r-1);
28 QuickSort(A,r+1,q);
29 }
30 }
31
32 int main()
33 {
34 int A[10] = {8,1,4,9,0,3,5,2,7,6};
35 QuickSort(A,0,9);
36 for( int k = 0; k < 10; k++ )
37 cout << A[k] << " ";
38 cout << endl;
39 }
计算结果如图:
看似结果很好,但是很遗憾,在实际中,我们却并不采用这样的程序。为什么呢?因为该程序还有几点需要进行改进:
当我们输入的数组S是已经排序好的一列数,那么这个程序的运行时间将是O(n^2),这个效率是插入排序的效率,所以是很低很低的。(可以利用递归树进行具体分析)
为了提高效率,可以使得i和j分别从左边和右边进行搜索,将值分别与v进行对比,当S[i]>v而S[j]
快速排序算法在数组很小的时候的效率是十分低下的,其速度并没有插入排序算法的速度快,因而在数组的大小小于一定的值之后,应该采用插入排序完成排序。
为了解决第一个问题,很多专家学者进行了如下尝试:
选取最前面的两个不同的元素,取其中较大的一个赋值给v;但是这种做法和第一种做法有相同的弊端,读者可自行进行分析,在此不作赘述。
在诸多元素之中选取一个随机的元素作为v。这种做法可以避免O(n^2)的弊端,但是随机数的产生需要花费很多的时间,所以这种做法是正确的,但是却并不是高效的。
选取最左边,中间和最右边三个数中的中间值。比如左中右三个值分别是0、8、6,那么我们就选取6作为v值。这样做是高效而安全的。所以一般的快速排序算法就用这种策略。
下面给出以上分析之后的快速排序算法程序:
1 #include
2 #include
3 #include
4 using namespace::std;
5
6 int Median3(int A[], int p, int q )
7 {
8 int c = ( p + q ) / 2;
9 if( A[p] > A[c] )
10 swap(A[p], A[c]);
11 if( A[p] > A[q] )
12 swap(A[p], A[q]);
13 if( A[c] > A[q] )
14 swap(A[c], A[q]);
15 swap(A[c],A[q-1]);
16 return A[q-1];
17 }
18
19 int Partition( int A[], int p, int q )
20 {
21 int key = Median3( A, p, q );
22 int i = p;
23 int j = q-1;
24 while(1)
25 {
26 while( A[++i] < key ){}
27 while( A[--j] > key ){}
28 if( i < j )
29 swap( A[i], A[j] );
30 else
31 break;
32 }
33 swap( A[i], A[q-1] );
34 return i;
35 }
36
37 void InsertionSort(int A[], int N)
38 {
39 int tmp;
40 int j;
41 int p;
42
43 for( p = 1; p < N; p++ )
44 {
45 tmp = A[p];
46 for( j = p; j > 0 && A[j -1] > tmp; j -- )
47 A[j] = A[j-1];
48 A[j] = tmp;
49 }
50 }
51
52 #define cutoff 5
53 void QuickSort(int A[], int p, int q)
54 {
55 if( p + cutoff <= q )
56 {
57 int r = Partition(A, p, q);
58 QuickSort( A, p, r - 1 );
59 QuickSort( A, r + 1, q );
60 }
61 else
62 InsertionSort(A + p, q - p + 1 );
63 }
64
65 int main()
66 {
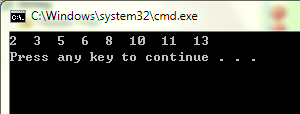
67 int A[8] = {6,10,13,5,8,3,2,11};
68 QuickSort(A,0,7);
69 for( int k = 0; k < 8; k++ )
70 cout << A[k] << " ";
71 cout << endl;
72 }
排序结果如图所示:
该程序中,cutoff的值必须大于等与2!
因为若是cutoff = 1;也就是说,插入法排序的数字只有一个;那么递归的最内一层是两个数字。在这个时候就会出现问题,具体分析如下:
以上例中的数组A为例,在递归树的右侧,会出现对13,11的排序;此时,p = 6, q = 7;
设C, L, R分别代表了中间,左边和右边三个值,那么根据Median3函数算法的计算,最终得到L = 13, C = 13, R = 11; 于是:
L < C => L和C不交换;
L > R => L和R交换,此时 C = 11, L = 11, R = 13;
C < R => C和R不交换;
所以最后得到的Key = 11, 经过Median3排序之后的顺序是11,13;
于是对其进行排序,完成时i = 7, 因此在执行33句时会交换A[7]和A[6],交换之后得到的顺序是 13, 11;
这个顺序就是最终的排序结果,因此在排序的最后导致了程序的排序结果错误;
产生这个错误的主要原因是:剩余了两个数,而在求meidian值的时候,对三个数进行了对比。
同时,若cutoff的值小于2还将产生一个错误,那就数:
--j的岗哨依赖于数组的元素A[P] < key,这样才使得,--j不会越过p值;而在上述情况中,A[p] = key值,为了提高程序的效率, 该程序在编写时设定,当A[j] = A[p]时,j会继续搜索,所以导致--j越过了A[p];
所以在设定cutoff的时候,cutoff的值至少为2,也就说InsertionSort至少要对两个数进行排序或者更多。