啊~ 两个月,终于写出了人生第一只独立的小爬虫....
抓取网易新闻页面的更新。
分析:
1.标题、url:
<h2><a href="http://money.163.com/16/0425/14/BLGM1PH5002551G6.html">贾跃亭的成功意味着实体失败?</a><h2>
<a href="http://money.163.com/16/0422/15/BL90MCB400253G87.html">海尔模式为何在西方叫好不叫座</a>
<a href="http://money.163.com/16/0412/15/BKFAETGB002552IJ.html">有前科就不能开网约车?</a>
<a href="http://money.163.com/16/0331/13/BJG7HME600253G87.html">影业公司能助网络视频抬身价吗</a>
上面三个是不行的,下面两个不完善,直接从网页上看比较好,复制的
<a href="http://money.163.com/16/0126/14/BE8V83A500253G87.html" title="iPhone 6s太失败? 苹果需创新" class="newsimg" lang="http://img6.cache.netease.com/stock/2016/1/26/20160126144328b85b7.jpg"><img src="http://s.cimg.163.com/stock/2016/1/26/20160126144328b85b7.jpg.119x83.jpg" alt="iPhone 6s太失败? 苹果需创新"></a>
<a href="http://money.163.com/16/0118/16/BDKGF2C000253G87.html" title="从贴吧事件看大公司如何担责" class="newsimg" lang="http://img3.cache.netease.com/stock/2016/1/18/20160118153051acf71.jpg"><img src="http://s.cimg.163.com/stock/2016/1/18/20160118153051acf71.jpg.119x83.jpg" alt="从贴吧事件看大公司如何担责"></a>
...
根据上面分析到标题的正则规则,中间就是网址
<a href=/".*/">.*</a>
2.created_at:
<span class="time">2016-03-31 13:43:27</span>
<span class="time">2016-03-31 08:48:45</span>
<span class="time">2016-03-18 16:40:02</span>
created_at正则规则:
<span class="time">.*</span>
抓取过程分析:
1.requests
2.正则
3.对字符串进行截取,实际上还是正则
4.定义一个函数:一个将数据拿下来到本地
好吧,正则、火狐的魅力真是无穷大,requests获取时,实际上涉及到了编码的问题,还不是很清楚,encode--->编码到,decode在3中不存在...有解决
接下来附上抓取代码:
import requests
import re
def url_gain(url):
f = requests.get(url)
cotet = f.text
return cotet
content = url_gain("http://money.163.com/special/pinglun/")
news = []
title_url = re.findall(r'<a href=.+?title=".+?"', content) # ? 非贪婪。。吖,实际上这边加上小括号到后期会容易获取数据,血泪吖。。
,血泪
creat_time = re.findall(r'<span class="time">.+?</span>', content) # len(creat_time)=15,len(title_url)=55 我只需首页的数据,所以取title_url前15个
title_url = title_url[0:15]
# 现在可以安心匹配了...
for i in title_url:
new = {} # 每做完一次运算,都对new进行更新一次。
new['url'] = re.search(r'".+?"', i).group()
new['title'] = re.findall(r'".+?"', i)[1]
new['created_at'] = re.search(r'[0-9\-]+\s[0-9\:]+', creat_time[0]).group() # 关于时间的匹配算法
news.append(new)
import pandas
newss = pandas.DataFrame(news)
===================================我是分割线
然后是运行结果:

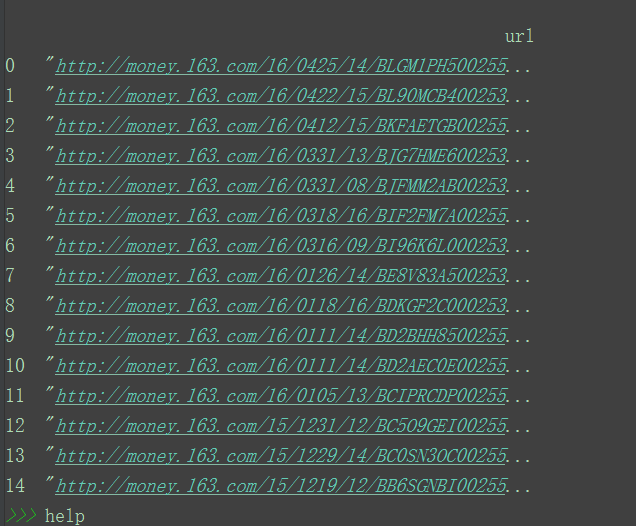
看起来是不是挺简单的,哈哈哈哈~~~
下次更新对于京东商品价格对于网址的爬取......