doctotext中没有make install选项,make后生成可执行文件
在buile目录下面有.so动态库和头文件,需要的可以从这里面拷贝
build/doctotext就是可执行程序。
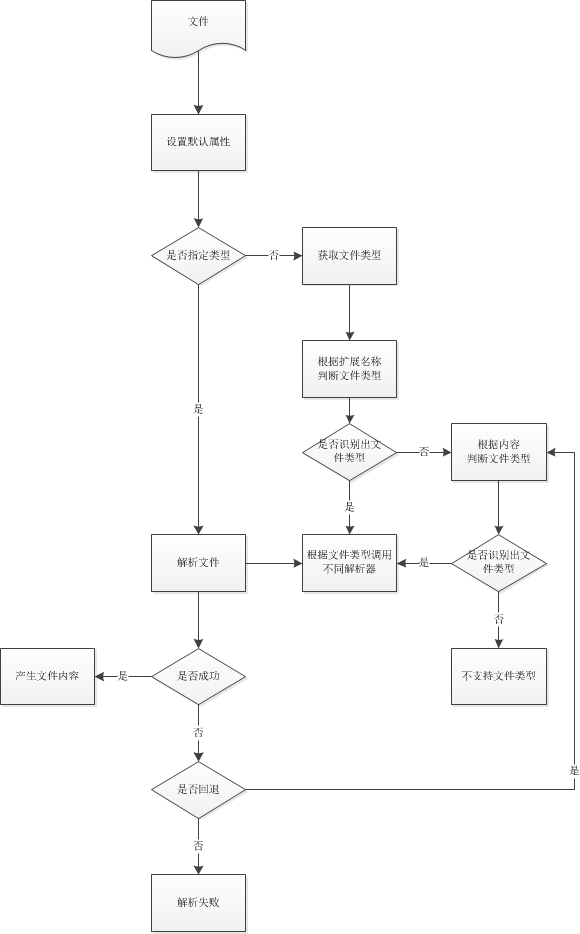
doctotext内置了两种检测文件类型方法:
1、以后缀为依据检测文件类型
2、以内容为依据检测文件类型
下面是doctotext支持的文件类型:
DOC, XLS, XLSB, PPT, RTF, ODF (ODT, ODS, ODP),
OOXML (DOCX, XLSX, PPTX), iWork (PAGES, NUMBERS, KEYNOTE),
ODFXML (FODP, FODS, FODT), PDF, EML and HTML documents to plain text.
Extracts metadata and annotations.
对于解析像office2007这类的文件,doctotext只是识别出来格式是OOXML类型,并没有细分是word还是execl。
如果用户没有指定文件类型,在解析文件的时候先先进行后缀检测判断文件类型,根据检测结果调用相应格式的文件解析器。
当解析过程中发现格式错误的时候,终止解析。使用内容检测判断文件类型,然后再根据检测结果调用相应格式的文件解析器。
如果是未识别的文件格式则终止进程。
main()函数位于src/doctotext.cpp中
从main()函数开始分析。
doctotext_init_tracing()函数,用于调试跟踪。产生信息文件doctotext.trace
定义变量extract_metadata,初始为不显示文件属性信息
bool extract_metadata = false;
名字空间:
namespace doctotext
{enum TableStyle { TABLE_STYLE_TABLE_LOOK, TABLE_STYLE_ONE_ROW, TABLE_STYLE_ONE_COL, };enum UrlStyle { URL_STYLE_TEXT_ONLY, URL_STYLE_EXTENDED, URL_STYLE_UNDERSCORED, };class ListStyle {};struct FormattingStyle {TableStyle table_style;UrlStyle url_style;ListStyle list_style;}; enum XmlParseMode {PARSE_XML, FIX_XML, STRIP_XML};
}类:
class PlainTextExtractor
{//文件类型的枚举enum ParserType{......}//实现结构体struct Implementation; //实现结构体私有变量Implementation *impl;
}
implementation中实现的函数列表
//判断不同的文件类型是否正确
isRTF [PlainTextExtractor::Implementation]
isODFOOXML [PlainTextExtractor::Implementation]
isXLS [PlainTextExtractor::Implementation]
isDOC [PlainTextExtractor::Implementation]
isPPT [PlainTextExtractor::Implementation]
isHTML [PlainTextExtractor::Implementation]
isIWork [PlainTextExtractor::Implementation]
isXLSB [PlainTextExtractor::Implementation]
isPDF [PlainTextExtractor::Implementation]
isEML [PlainTextExtractor::Implementation]
isODFXML [PlainTextExtractor::Implementation]//不同文件类型的解析器
parseRTF [PlainTextExtractor::Implementation]
parseODFOOXML [PlainTextExtractor::Implementation]
parseXLS [PlainTextExtractor::Implementation]
parseDOC [PlainTextExtractor::Implementation]
parsePPT [PlainTextExtractor::Implementation]
parseHTML [PlainTextExtractor::Implementation]
parseIWork [PlainTextExtractor::Implementation]
parseXLSB [PlainTextExtractor::Implementation]
parsePDF [PlainTextExtractor::Implementation]
parseTXT [PlainTextExtractor::Implementation]
parseEML [PlainTextExtractor::Implementation]
parseODFXML [PlainTextExtractor::Implementation]
parseRTFMetadata [PlainTextExtractor::Implementation]
parseODFOOXMLMetadata [PlainTextExtractor::Implementation]
parseXLSMetadata [PlainTextExtractor::Implementation]
parseDOCMetadata [PlainTextExtractor::Implementation]
parsePPTMetadata [PlainTextExtractor::Implementation]
parseHTMLMetadata [PlainTextExtractor::Implementation]
parseIWorkMetadata [PlainTextExtractor::Implementation]
parseXLSBMetadata [PlainTextExtractor::Implementation]
parsePDFMetadata [PlainTextExtractor::Implementation]
parseEMLMetadata [PlainTextExtractor::Implementation]
parseODFXMLMetadata [PlainTextExtractor::Implementation]PlainTextExtractor类中实现的函数列表
PlainTextExtractor [PlainTextExtractor]
~PlainTextExtractor [PlainTextExtractor]
setVerboseLogging [PlainTextExtractor]
setLogStream [PlainTextExtractor]
setFormattingStyle [PlainTextExtractor]
setXmlParseMode [PlainTextExtractor]
setManageXmlParser [PlainTextExtractor]
parserTypeByFileExtension [PlainTextExtractor]
parserTypeByFileExtension [PlainTextExtractor]
parserTypeByFileContent [PlainTextExtractor]
parserTypeByFileContent [PlainTextExtractor]
parserTypeByFileContent [PlainTextExtractor]
processFile [PlainTextExtractor]
processFile [PlainTextExtractor]
processFile [PlainTextExtractor]
processFile [PlainTextExtractor]
根据输入参数选项指定文件类型
指定parser_type的值
创建变量
PlainTextExtractor extractor(parser_type);
详细日志默认关闭
verbose = false
设置详细日志开启: extractor.setVerboseLogging(true);
设置XM解析模式:extractor.setXmlParseMode(mode);
设置格式类型:extractor.setFormattingStyle(options);
解析文件显示详细文件属性:
extractor.extractMetadata(argv[argc - 1], meta);
解析文件显示文件内容:
extractor.processFile(argv[argc - 1], text);
根据文件类型调用不同的文件解析器
processFile(parser_type, fallback, buffer, size, plain_text)
根据文件扩展名称判断文件类型
parserTypeByFileExtension(file_name);
根据内容判断文件类型:
parserTypeByFileContent(buffer, size, parser_type);
程序流程图:
官方从2014年开始就不更新了,具体什么原因不知,github 上自己维护的 doctotext
https://github.com/etangyushan/doctotext