很多网站会检测某一段时间某个IP的访问次数(通过流量统计,系统日志等),如果访问次数多的不像正常人,它会禁止这个IP的访问。
所以我们可以设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取
使用代理流程
代理的使用大概可以分为四步
1.构建处理器handler(代理IP)
2.使用处理器构建连接方法(build_opener)
3.构建请求
4.使用连接方法中的open函数打开请求
其中最重要的是第一步构建处理器的ProxyHandler函数
爬取数据
这一步,你要明确要得到的内容是什么?是HTML源码,还是Json格式的字符串等。
最基本的爬取
抓取大多数情况属于get请求,即直接从对方服务器上获取数据。
首先,Python中自带urllib及urllib2这两个模块,基本上能满足一般的页面抓取。另外,requests也是非常有用的包,与此类似的,还有httplib2等等。
import requests
url = http://current.ip.16yun.cn:802
response = requests.get(url)
content = requests.get(url).content
print(“response headers:”, response.headers)
print(“content:”, content)
此外,对于带有查询字段的url,get请求一般会将来请求的数据附在url之后,以?分割url和传输数据,多个参数用&连接。
import requests
data = {‘wd’:‘nike’, ‘ie’:‘utf-8’}
url=‘https://www.baidu.com’
response = requests.get(url=url, params=data)
如何配置动态的代理ip
这里使用的是收费的代理ip了,你可以使用亿牛云云代理服务商提供的服务,当你注册并缴费之后,会给你一个域名端口和用户名密码,这里直接看代码吧!最后,如果你的时间不是很紧张,并且又想快速的python提高,最重要的是不怕吃苦,建议你可以架尉♥信(同音):2028979958 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~
#! – encoding:utf-8 –
import requests
import random
# 要访问的目标页面
targetUrl = “http://httpbin.org/ip”
# 要访问的目标HTTPS页面
# targetUrl = “https://httpbin.org/ip”
# 代理服务器(产品官网 www.16yun.cn)
proxyHost = “t.16yun.cn”
proxyPort = “31111”
# 代理隧道验证信息
proxyUser = “username”
proxyPass = “password”
proxyMeta = “http://%(user)s:%(pass)s@%(host)s:%(port)s” % {
“host” : proxyHost,
“port” : proxyPort,
“user” : proxyUser,
“pass” : proxyPass,
}
# 设置 http和https访问都是用HTTP代理
proxies = {
“http” : proxyMeta,
“https” : proxyMeta,
}
# 设置IP切换头
tunnel = random.randint(1,10000)
headers = {“Proxy-Tunnel”: str(tunnel)}
resp = requests.get(targetUrl, proxies=proxies, headers=headers)
print resp.status_code
print resp.text
http://current.ip.16yun.cn:802
这是一个检测代理是否使用成功的网站
python爬虫如何配置动态爬虫代理
news/2024/7/2 13:55:54
相关文章
用于小型图形挖掘研究的瑞士军刀:空手道俱乐部的图表学习Python库
作者 | Benedek Rozemberczki译者 | 天道酬勤 责编 | Carol出品 | AI科技大本营(ID:rgznai100)空手道俱乐部(Karate Club)是NetworkX Python软件包的无监督机器学习扩展库。详细可以参阅此处的文档:https://github.com…
送一台高清航拍无人机
最近有粉丝留言让我多搞些抽奖活动,为了感谢大家对本公众号的大力支持本次联合了11个号主,送无人机4K航拍,祝所有人新的一年工作顺利,工资芝麻开花节节高,希望本次抽奖可以给你带来好运。生活不易,望大家来…

实战:使用Nginx限流
点击上方“方志朋”,选择“设为星标”回复”666“获取新整理的面试文章来源:深入浅出大型网站架构设计Nginx不仅可以做Web服务器、做反向代理、负载均衡,还可以做限流系统。此处我们就Nginx为例,介绍一下如何配置一个限流系统。Ng…

一步一步粗谈linux文件系统(三)----超级块(superblock)【转】
本文转载自:https://blog.csdn.net/fenglifeng1987/article/details/8302921 超级块是来描述整个文件系统信息的,可以说是一个全局的数据结构,可以把它理解成文件系统的心脏 比较简单的文件系统中(如ramfs和sysfs)&…

使用Photoshop制作网页模板
用图层组管理网页元素首先是在Photoshop中制作好网页的框架。网页中的元素有很多, 像Banner条、文本框、文字、版权、Logo、广告等。尽量把这些相对独立的元素放在不同的图层中,这样方便以后的再编辑。不过图层一多,就 显得很凌乱,…

技巧:利用 Python 实现多任务进程
一、进程介绍
进程:正在执行的程序,由程序、数据和进程控制块组成,是正在执行的程序,程序的一次执行过程,是资源调度的基本单位。
程序:没有执行的代码,是一个静态的。
二、线程和进程之间的…
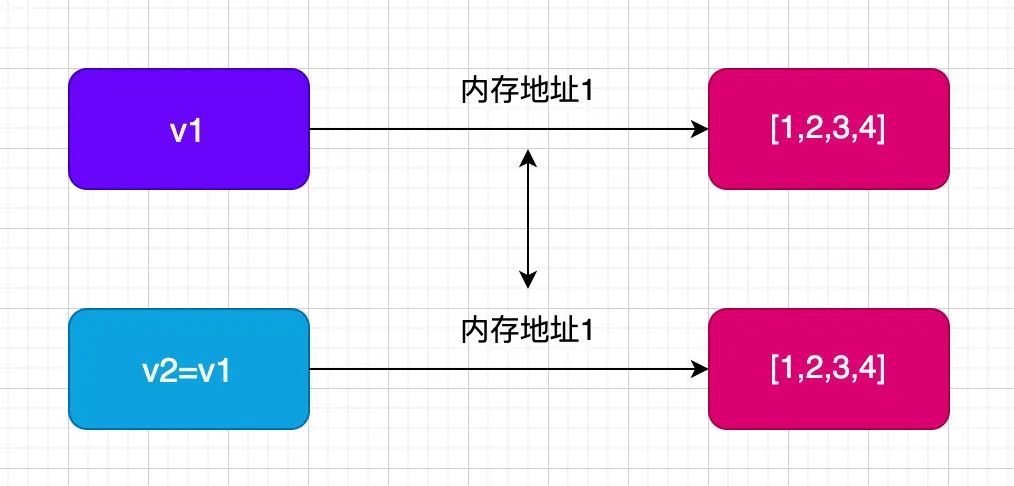
【Python基础】Python的深浅拷贝讲解
点击上方“小白学视觉”,选择加"星标"或“置顶”重磅干货,第一时间送达前言在很多语言中都存在深浅拷贝两种拷贝数据的方式,Python中也不例外。本文中详细介绍了Python中的深浅拷贝的相关知识,文章的内容包含࿱…