用到的软件:
一、安装jdk:
1、要安装的jdk,我把它拷在了共享文件夹里面。
(用优盘拷也可以)
2、我把jdk拷在了用户文件夹下面。
(其他地方也可以,不过路径要相应改变)

3、执行复制安装解压命令:

解压完毕:
查看解压的文件夹:

4、配置 环境变量:

写入如下5行代码:

使配置生效:
5、查看安装的jdk:
java -version

java
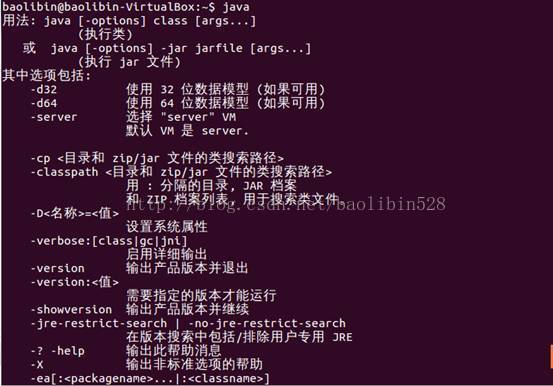
javac
二、SSH免密码登陆:
1、安装SSH:
2、是否生成 .ssh 目录:

3、如果没有生成,自己手动创建一个 .ssh 目录:
生成的 .ssh 目录:

4、生成公钥与私钥:

效果如下:

5、将公钥加入到用于认证的公钥文件中:

6、免密码登陆:

效果:
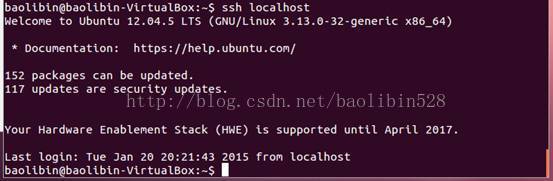
Ubuntu 免密码登陆,SSH配置完。
三、安装配置Hadoop:
1、复制安装解压Hadoop :

解压完毕效果:

2、配置 etc/profile
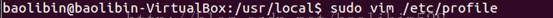

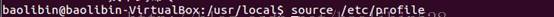
3、配置 hadoop-env.sh
进入



4、修改hadoop-2.6.0文件权限为用户权限:

默认没有mapred-site.xml文件,复制mapred-site.xml.template一份,并把名字改为mapred-site.xml

5、配置下面4个重要文件:
mapred-site.xml


core-site.xml


hdfs-site.xml


yarn-site.xml


6、格式化:

格式化部分效果:

7、启动:
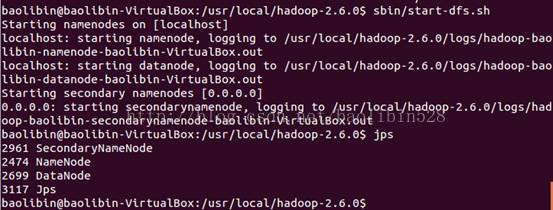
先启动 start-dfs.sh:

效果:
再启动 start-yarn.sh:

效果:
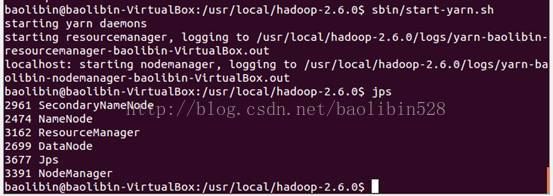
关闭hadoop:

(注:也可以 sbin/start-all.sh: 建议分开启动。)效果一样,如下:
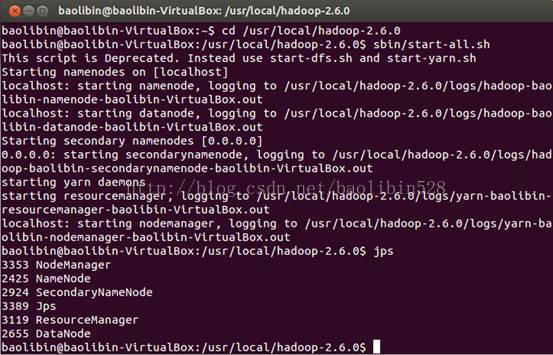
8、查看Web页面信息:


至此,hadoop-2.6.0伪分布配置成功。
附录:文字版
一. ubuntu下JDK的安装:
见Ubuntu中安装配置jdk。
二. ubuntu下安装ssh:
1. $ sudo apt-get install openssh-server (用此方法安装不成功,参考在Ubuntu中配置SSH)
2. 启动ssh:/etc/init.d/ssh start
3. $ ps -e | grep ssh 来验证是否启动sshserver
4. 免密码化
$ ssh-keygen -t rsa //生成密钥对
一直按Enter键,就会按照默认的选项将生成的密钥对保存在.ssh/id_rsa文件中。
$cd .ssh //进入.ssh目录
$cp id_rsa.pub authorized_keys
$ssh localhost
三. ubuntu下安装hadoop:
1. 下载hadoop-0.20.2.tar.gz,放在/opt下解压
2. 修改hadoop配置文件
conf/hadoop-env.sh 修改JAVA_HOME选项:
export JAVA_HOME=/usr/java/jdk1.6.0_24,一定记得去除前面的#
3. 伪分布式单机配置
conf/core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
conf/hdfs-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name> //为了保证每次重启不用格式化
<value>/opt/hadoop-0.20.2/rq</value> //namenode,此处设置非常重要
</property>
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop-0.20.2/rq/data</value>
</property>
</configuration>
conf/mapred-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
5. 创建hdfs文件系统
$ bin/hadoop namenode -format
6. 启动hadoop
需要先启动ssh: $ /etc/init.d/ssh start
$ bin/start-all.sh
7. 在hadoop下创建test目录,然后建立file1.txt file2.txt 写入几个单词;将hadoop/test下的测试文件上传到hadoop文件系统中
$ bin/hadoop dfs -put ./test input
8. 运行wordCount例子
$ bin/hadoop jar hadoop-0.20.2-examples.jar wordcount input output
9. 把结果从dfs上拷贝下来
$ bin/hadoop dfs -get output output
10. 查看结果
$ cat output/* 也可以直接查看 $ bin/hadoop dfs -cat output/*
11. 停止hadoop运行
$ bin/stop-all.sh
12. 关闭ssh-server
$ /etc/init.d/ssh stop





