作者:俊欣
来源:关于数据分析与可视化
前言
大家好,这里是俊欣,今天和大家来分享几个Pandas方法可以有效地帮助我们在数据分析与数据清洗过程当中提高效率,加快工作的进程,希望大家看了之后会有收获。
首先导入模块和读取数据,这回用到的数据集中有各种各样类型的数据,链接为:https://www.kaggle.com/dgomonov/new-york-city-airbnb-open-data
import pandas as pd
df = pd.read_csv("AB_NYC_2019.csv")
df.head()
01
pandas.factorize()
针对离散型的数据,我们通常用“sklearn”模块中的“LabelEncoder”方法来对其进行打标签,而在“pandas”模块中也有相对应的方法来对处理,“factorize”函数可以将离散型的数据映射为一组数字,相同的离散型数据映射为相同的数字,例如我们针对数据集当中的“room_type”这一列来进行处理
pd.factorize(df['room_type'])结果返回的是元组形式的数据,由两部分组成,其中的第一部分是根据离散值映射完成后的数字,另一部分则是具体的离散值数据。

02
pandas.get_dummies()
在上面的例子当中,我们对离散值进行了编码,编码的结果有大小的意义,例如针对尺码的离散值:【X,XL,XXL】我们映射出来的结果是{X: 1,XL: 2,XXL: 3},但是有时候离散值取值之间没有大小的意义,例如颜色:【红色、蓝色、黄色】等,而这个时候用上述的方法就不太合适了,我们会使用独热编码的方式来对离散值进行编码。
所谓独热编码,就是将离散型特征的每一种取值都看成一种状态,若某一个特征当中有N个不相同的取值,则我们就可以将该特征抽象成N中不同的状态。而在“Pandas”模块当中有相应的方法来实现上面的功能:
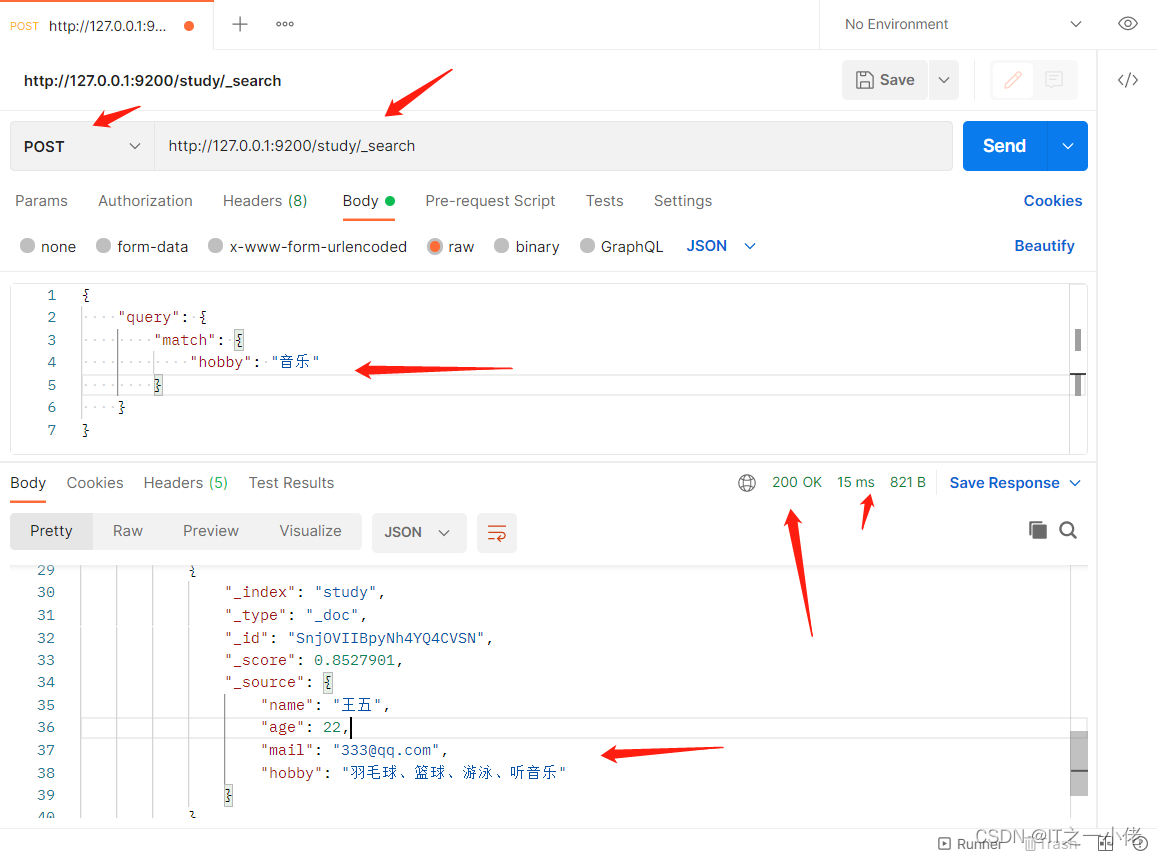
pd.get_dummies(df['room_type'])
## 参数prefix: 给输出的列添加前缀
## drop_first: 将第一列的给去掉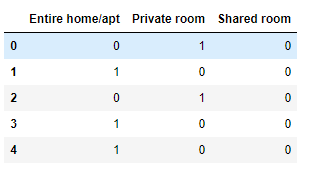
我们将它与源数据进行合并的话
df.join(pd.get_dummies(df['room_type']))
03
pandas.qcut()
有时候我们需要对数据集中的某一列进行分箱处理,也就是把一段连续的数据切分成若干段,每一段的值看成一个分类。例如我们把学生年龄按15岁划分成一组,0-15岁的叫做少年,16-39岁的叫做青年,而31-45岁的叫做壮年。在这个过程当中我们把连续的年龄分成三个类别,“少年”、“青年”、和“壮年”就是各个类别的名称或者叫做是标签。在“Pandas”模块当中也有相对应的方法来实现分箱操作。
pd.qcut(df['price'],4) # 第二个参数确定的是要分成几段
当然出来的结果是Interval类型的数据,例如
pd.qcut(df['price'],4)[0]
-------------------------------------
## output
## Interval(106.0, 175.0, closed='right')我们可以将其变成字符串的格式
pd.qcut(df['price'],4)[0]
-------------------------------------
## output
## Interval(106.0, 175.0, closed='right')
04
pandas.drop_duplicates()
数据集当中存在的重复值可能会对机器学习以及深度学习的模型造成不好的影响,当遇到这样的情况的时候,我们使用“pandas”模块当中的“drop_duplicates”的方法来去除重复值,我们先人为的制造一些重复值出来,
df.loc[1] = df.loc[0]
df.loc[2] = df.loc[0]
df.loc[3] = df.loc[0]
df.head()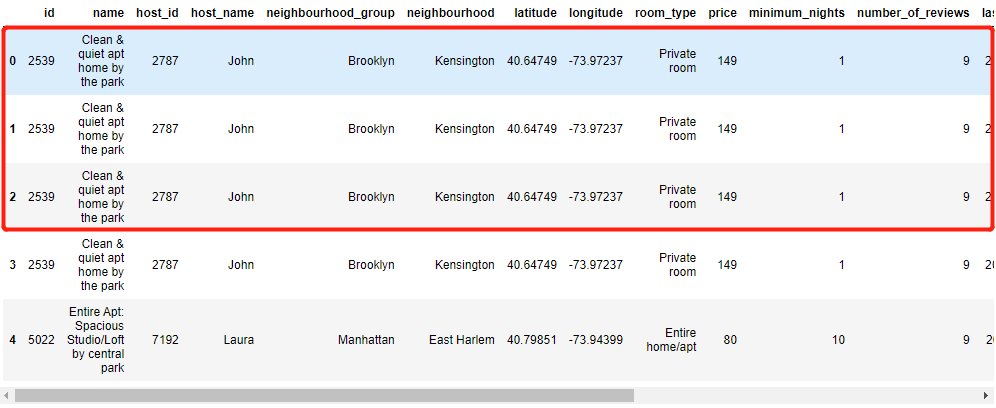
df.drop_duplicates(inplace=True) # 前面几行的重复值被去除掉了
df.head()
05
pandas.clip()
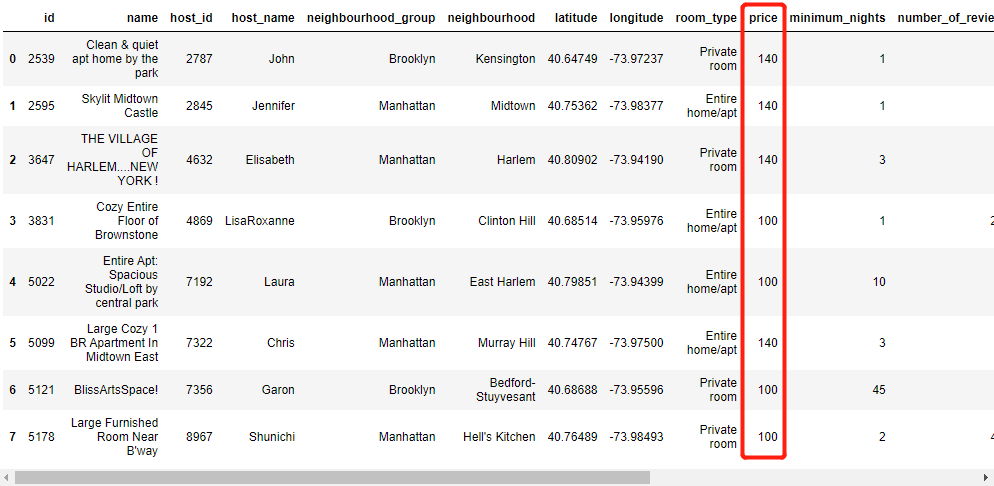
由于极值的存在,经常会对模型的训练结果产生较大的影响,而在“pandas”模块中有针对极值的处理方法,“clip”方法中对具体的连续型的数据设定范围,要是遇到超过所规定范围的值,则会对其进行替换,替换成所设定范围中的上限与下限,例如下面的例子,我们针对数据集当中的“price”这一列进行极值的处理
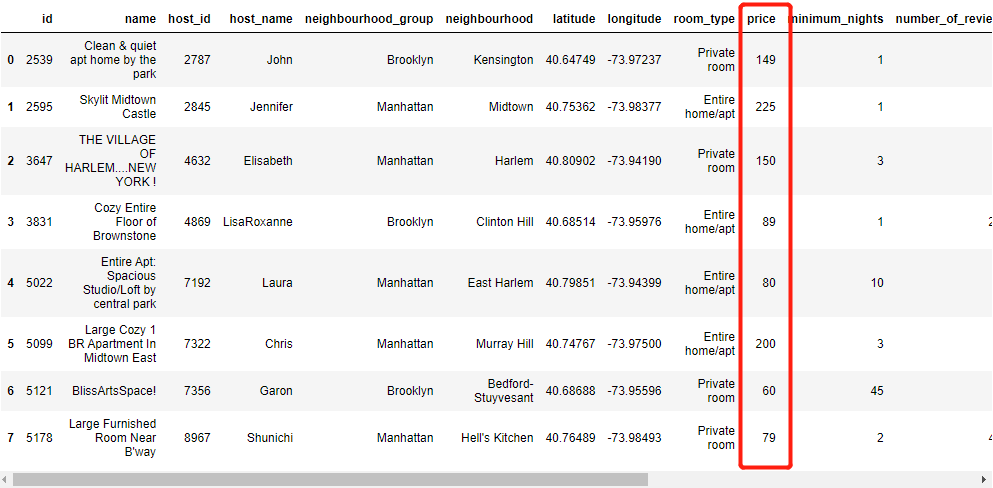
df['price'] = df['price'].clip(100,140)
df.head(8)超过140的值被替换成了140了,没到100的值被100给代替了


更多精彩推荐
大手笔 !Julia Computing 获 2400 万美元融资,前 Snowflake CEO 加入董事会芯片开发语言:Verilog 在左,Chisel 在右深度学习实现场景字符识别模型|代码干货