在开放领域的搜索场景下得到的网页数据会非常复杂,其中往往存在着网页文档质量参差不齐、长短不一,问题答案分布零散、长度较长等问题,给答案抽取和答案置信度计算带来了较大挑战。
本文基于百度搜索技术创新挑战赛中的搜索问答赛题,对搜索问答类任务做详细解读。本文思路如图:
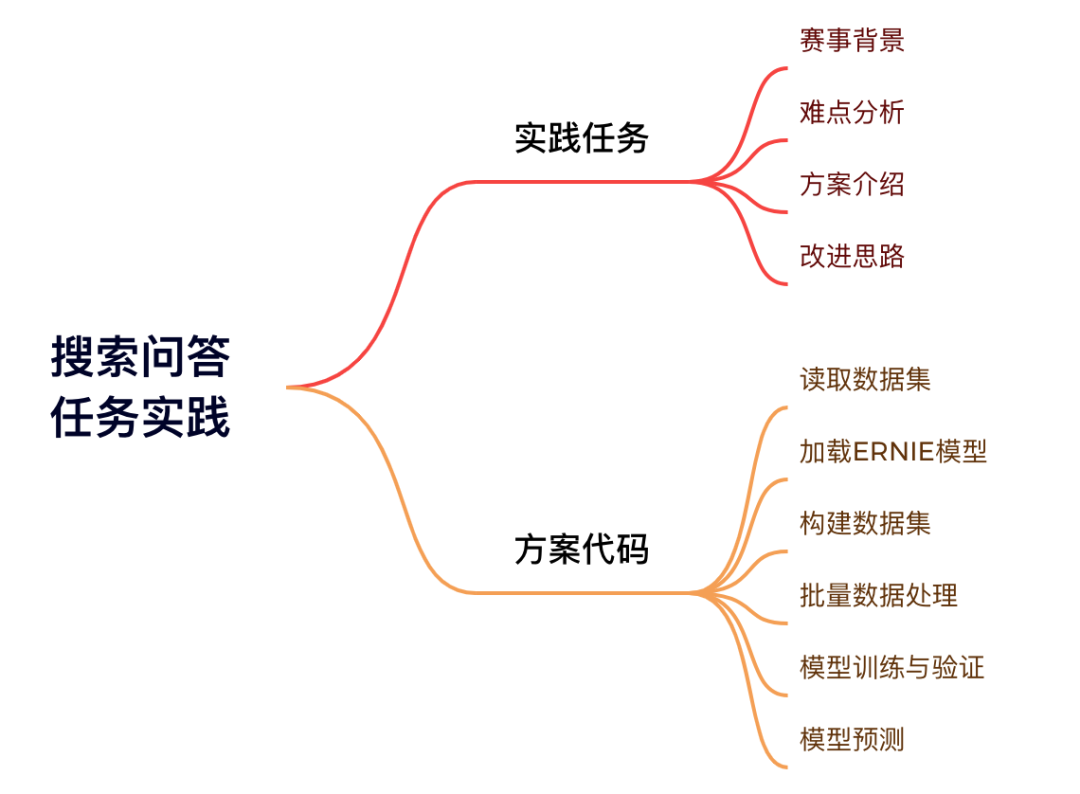
(本文实践讲解框架,其中改进思路见文末)
赛题背景
本赛题希望调研真实网络环境下的文档级机器阅读理解技术,共分为两个子任务,涉及基于复杂网页文档内容的答案抽取和答案检验技术(详细任务定义可参考赛事官网)。
赛事官网:
https://aistudio.baidu.com/aistudio/competition/detail/660/0/introduction
难点分析
如何在文档长度不定,答案长度较长的数据环境中取得良好且鲁棒的答案抽取效果是子任务1关注的重点。
方案介绍
赛题可以视为基础的信息抽取任务,也可以直接视为问答类型的信息抽取问题。我们需要构建一个模型,根据query从document中找到想要的答案。
思路一:BERT或ERNIE
如果我们使用BERT 或者 ERNIE 可以直接参考如下思路,模型的输出可以为对应的两个位置,分别是回答的开始位置和结束位置。
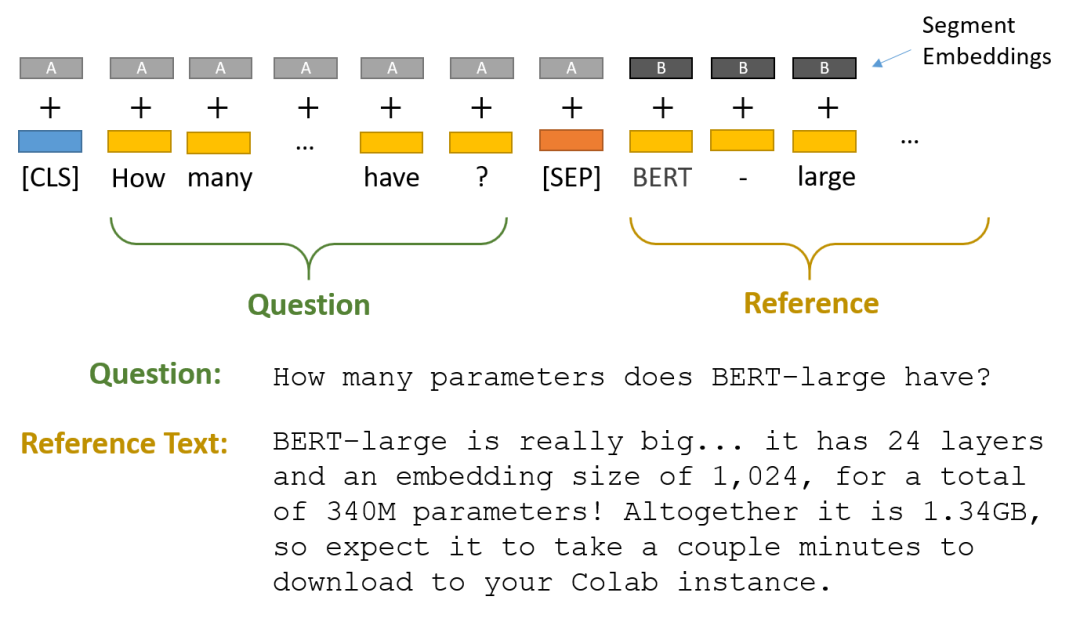
这里需要深入一下模型的实现细节:
query和documnet是一起输入给模型,一般情况下query在前面。
回答对应的输出可以通过模型输出后的全连接层完成分类,当然回归也可以。
思路二:QA
如果采用QA的思路,则需要将比赛数据集转换为QA的格式,特别是文本的处理:长文本需要进行截断。
方案代码
方案借助QA的思路,使用ERNIE快速完成模型训练与预测。同时,文末给出了提分改进方案的思路。
详情可参考源Notebook:
https://aistudio.baidu.com/aistudio/projectdetail/5013840(一键运行提交)
步骤1:解压数据集
!pip install paddle-ernie > log.log
# !cp data/data174963/data_task1.tar /home/aistudio/
!tar -xf /home/aistudio/data_task1.tar步骤2:读取数据集
# 导入常见的库
import numpy as np
import pandas as pd
import os, sys, json# 读取训练集、测试集和验证集
train_json = pd.read_json('data_task1/train_data/train.json', lines=True)
test_json = pd.read_json('data_task1/test_data/test.json', lines=True)
dev_json = pd.read_json('data_task1/dev_data/dev.json', lines=True)# 查看数据集样例
train_json.head(1)train_json.iloc[0]test_json.iloc[0]步骤3:加载ERNIE模型
这里我们使用paddlenlp==2.0.7,当然你也可以选择更高的版本。更高的版本会将损失计算也封装进去,其他的部分区别不大。
import paddle
import paddlenlp
print('paddle version', paddle.__version__)
print('paddlenlp version', paddlenlp.__version__)from paddlenlp.transformers import ErnieForQuestionAnswering, ErnieTokenizer
tokenizer = ErnieTokenizer.from_pretrained('ernie-1.0')
model = ErnieForQuestionAnswering.from_pretrained('ernie-1.0')# 对文档的文档进行划分、计算文档的长度
train_json['doc_sentence'] = train_json['doc_text'].str.split('。')
train_json['doc_sentence_length'] = train_json['doc_sentence'].apply(lambda doc: [len(sentence) for sentence in doc])
train_json['doc_sentence_length_max'] = train_json['doc_sentence_length'].apply(max)
train_json = train_json[train_json['doc_sentence_length_max'] < 10000] # 删除了部分超长文档# 对文档的文档进行划分、计算文档的长度
dev_json['doc_sentence'] = dev_json['doc_text'].str.split('。')
dev_json['doc_sentence_length'] = dev_json['doc_sentence'].apply(lambda doc: [len(sentence) for sentence in doc])
dev_json['doc_sentence_length_max'] = dev_json['doc_sentence_length'].apply(max)
dev_json = dev_json[dev_json['doc_sentence_length_max'] < 10000] # 删除了部分超长文档# 对文档的文档进行划分、计算文档的长度
test_json['doc_sentence'] = test_json['doc_text'].str.split('。')
test_json['doc_sentence_length'] = test_json['doc_sentence'].apply(lambda doc: [len(sentence) for sentence in doc])
test_json['doc_sentence_length_max'] = test_json['doc_sentence_length'].apply(max)train_json.iloc[10]test_json.iloc[10]步骤4:构建数据集
接下来需要构建QA任务的数据集,这里的数据集需要处理为如下的格式:
query [SEP] sentence of document训练集数据集处理
train_encoding = []# for idx in range(len(train_json)):
for idx in range(10000):# 读取原始数据的一条样本title = train_json.iloc[idx]['title']answer_start_list = train_json.iloc[idx]['answer_start_list']answer_list = train_json.iloc[idx]['answer_list']doc_text = train_json.iloc[idx]['doc_text']query = train_json.iloc[idx]['query']doc_sentence = train_json.iloc[idx]['doc_sentence']# 对于文章中的每个句子for sentence in set(doc_sentence):# 如果存在答案for answer in answer_list:answer = answer.strip("。")# 如果问题 + 答案 太长,跳过if len(query + sentence) > 512:continue# 对问题 + 答案进行编码encoding = tokenizer.encode(query, sentence, max_seq_len=512, return_length=True, return_position_ids=True, pad_to_max_seq_len=True, return_attention_mask=True)# 如果答案在这个句子中,找到start 和 end的 位置if answer in sentence: encoding['start_positions'] = len(query) + 2 + sentence.index(answer)encoding['end_positions'] = len(query) + 2 + sentence.index(answer) + len(answer)# 如果不存在,则位置设置为0else:encoding['start_positions'] = 0encoding['end_positions'] = 0# 存储正样本if encoding['start_positions'] != 0:train_encoding.append(encoding)# 对负样本进行采样,因为负样本太多# 正样本:query + sentence -> answer 的情况# 负样本:query + sentence -> No answer 的情况if encoding['start_positions'] == 0 and np.random.randint(0, 100) > 99:train_encoding.append(encoding)if len(train_encoding) % 500 == 0:print(len(train_encoding))验证集数据集处理
val_encoding = []for idx in range(len(dev_json)):
# for idx in range(200):title = dev_json.iloc[idx]['title']answer_start_list = dev_json.iloc[idx]['answer_start_list']answer_list = dev_json.iloc[idx]['answer_list']doc_text = dev_json.iloc[idx]['doc_text']query = dev_json.iloc[idx]['query']doc_sentence = dev_json.iloc[idx]['doc_sentence']for sentence in set(doc_sentence):for answer in answer_list:answer = answer.strip("。")if len(query + sentence) > 512:continueencoding = tokenizer.encode(query, sentence, max_seq_len=512, return_length=True, return_position_ids=True, pad_to_max_seq_len=True, return_attention_mask=True)if answer in sentence: encoding['start_positions'] = len(query) + 2 + sentence.index(answer)encoding['end_positions'] = len(query) + 2 + sentence.index(answer) + len(answer)else:encoding['start_positions'] = 0encoding['end_positions'] = 0if encoding['start_positions'] != 0:val_encoding.append(encoding)if encoding['start_positions'] == 0 and np.random.randint(0, 100) > 99:val_encoding.append(encoding)测试集数据集处理
test_encoding = []
test_raw_txt = []
for idx in range(len(test_json)):title = test_json.iloc[idx]['title']doc_text = test_json.iloc[idx]['doc_text']query = test_json.iloc[idx]['query']doc_sentence = test_json.iloc[idx]['doc_sentence']for sentence in set(doc_sentence):if len(query + sentence) > 512:continueencoding = tokenizer.encode(query, sentence, max_seq_len=512, return_length=True, return_position_ids=True, pad_to_max_seq_len=True, return_attention_mask=True)test_encoding.append(encoding)test_raw_txt.append([idx, query, sentence])步骤5:批量数据读取
# 手动将数据集进行批量打包
def data_generator(data_encoding, batch_size = 6):for idx in range(len(data_encoding) // batch_size):batch_data = data_encoding[idx * batch_size : (idx+1) * batch_size]batch_encoding = {}for key in batch_data[0].keys():if key == 'seq_len':continuebatch_encoding[key] = paddle.to_tensor(np.array([x[key] for x in batch_data]))yield batch_encoding步骤6:模型训练与验证
# 优化器
optimizer = paddle.optimizer.SGD(0.0005, parameters=model.parameters())# 损失函数
loss_fct = paddle.nn.CrossEntropyLoss()best_val_start_acc = 0for epoch in range(10):# 每次打乱训练集,防止过拟合np.random.shuffle(train_encoding)# 训练部分train_loss = []for batch_encoding in data_generator(train_encoding, 10):# ERNIE正向传播start_logits, end_logits = model(batch_encoding['input_ids'], batch_encoding['token_type_ids'])# 计算损失start_loss = loss_fct(start_logits, batch_encoding['start_positions'])end_loss = loss_fct(end_logits, batch_encoding['end_positions'])total_loss = (start_loss + end_loss) / 2# 参数更新total_loss.backward()train_loss.append(total_loss)optimizer.step()optimizer.clear_gradients()# 验证部分val_start_acc = []val_end_acc = []with paddle.no_grad():for batch_encoding in data_generator(val_encoding, 10):# ERNIE正向传播start_logits, end_logits = model(batch_encoding['input_ids'], batch_encoding['token_type_ids'])# 计算识别精度start_acc = paddle.mean((start_logits.argmax(1) == batch_encoding['start_positions']).astype(float))end_acc = paddle.mean((end_logits.argmax(1) == batch_encoding['end_positions']).astype(float))val_start_acc.append(start_acc)val_end_acc.append(end_acc)# 转换数据格式为floattrain_loss = paddle.to_tensor(train_loss).mean().item()val_start_acc = paddle.to_tensor(val_start_acc).mean().item()val_end_acc = paddle.to_tensor(val_end_acc).mean().item()# 存储最优模型if val_start_acc > best_val_start_acc:paddle.save(model.state_dict(), 'model.pkl')best_val_start_acc = val_start_acc# 每个epoch打印输出结果print(f'Epoch {epoch}, {train_loss:3f}, {val_start_acc:3f}/{val_end_acc:3f}')# 关闭dropout
model = model.eval()步骤7:模型预测
test_start_idx = []
test_end_idx = []# 对测试集中query 和 sentence的情况进行预测
with paddle.no_grad():for batch_encoding in data_generator(test_encoding, 12):start_logits, end_logits = model(batch_encoding['input_ids'], batch_encoding['token_type_ids'])test_start_idx += start_logits.argmax(1).tolist()test_end_idx += end_logits.argmax(1).tolist()if len(test_start_idx) % 500 == 0:print(len(test_start_idx), len(test_encoding))test_submit = [''] * len(test_json)# 对预测结果进行后处理
for (idx, query, sentence), st_idx, end_idx in zip(test_raw_txt, test_start_idx, test_end_idx):# 如果start 或 end位置识别失败,或 start位置 晚于 end位置if st_idx == 0 or end_idx == 0 or st_idx >= end_idx:continue# 如果start位置在query部分if st_idx - len(query) - 2 < 0:continuetest_submit[idx] += sentence[st_idx - len(query) - 2: end_idx - len(query) - 2]# 生成提交结果
with open('subtask1_test_pred.txt', 'w') as up:for x in test_submit:if x == '':up.write('1\tNoAnswer\n')else:up.write('1\t'+x+'\n')改进方向
从精度改变大小,可以从以下几个角度改进:训练数据 > 数据处理 > 模型与预训练 > 模型集成
训练数据:使用全量的训练数据
数据处理:对文档进行切分,现在使用
。进行切分,后续也可以尝试其他。模型与预处理:尝试ERNIE版本,或者进行预训练。
模型集成:
尝试不同的数据划分得到不同的模型
尝试不同的文本处理方法得到不同的模型
当然也可以考虑其他数据,如不同的网页拥有答案的概率不同,以及从标题可以判断是否包含答案。
完整代码也可以点击左下角“原文链接”进行查看。

整理不易,点赞三连↓





