题目如下:
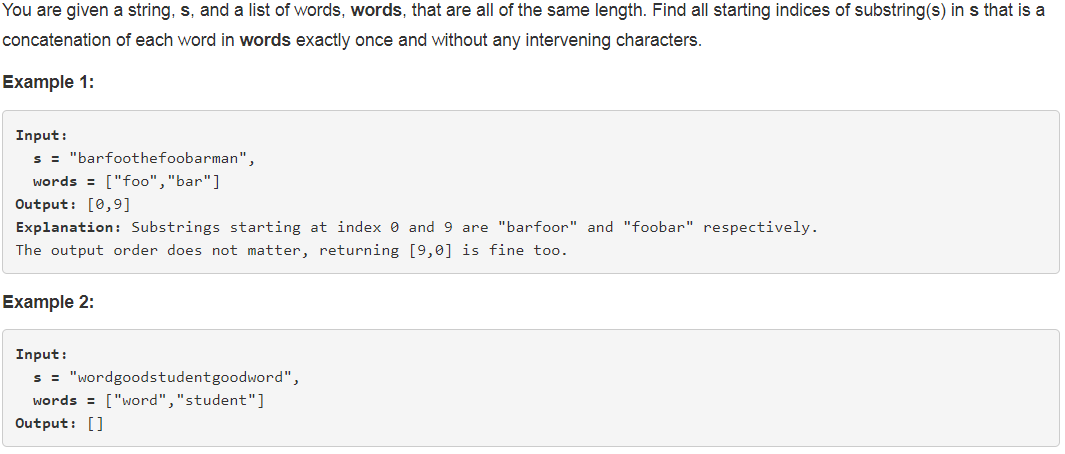
解题思路:本题题干中有一个非常关键的前提,就是words中的所有word的长度一样,并且都要被使用到。所以,我们可以把输入的s按word的长度进行等分,以s = "barfoothefoobarman",words = ["foo","bar"]为例,下表是等分的结果。为什么只分到startInx=[0,2]? 因为word的长度就是3,startInx = 3是startInx = 0的子集。分解完成后,再对startInx=[0,2]中每一种分解的方法进行比对。例如startInx = 0的时候,因为words的长度是2,所以用word1和word2组成集合和words比对,比对完成后记录结果,同时删除word1,把word3加入集合,直到wordn加入集合为止。这样就能得到所有能满足题意的all starting indices of substring(s) in s。

代码如下:
class Solution(object):def findSubstring(self, s, words):""":type s: str:type words: List[str]:rtype: List[int]"""import bisectif len(words) == 0:return []words.sort()res = []length = len(words[0])for i in range(length):start = il = []ol = []while start + length <= len(s):l.append(s[start:start+length])bisect.insort_left(ol,s[start:start+length])start += lengthif len(l) == len(words):if ol == words:res.append(start - length*len(l))del ol[bisect.bisect_left(ol,l.pop(0))]return res