
点击上方蓝字关注我吧!
本篇文章大概3300字,阅读时间大约10分钟
前面文章,透彻分析了Netty的接收缓冲区优化的套路和实现细节,以及写数据和刷新数据的宏观流程和细节:
从源码出发:在宏观上把握Netty写数据到应用层缓冲区的过程
从源码出发:在宏观上把握Netty刷新数据到网络的过程
其中,反复提到了一个组件叫ChannelOutboundBuffer,对这个缓冲区的着墨并不多。本文就单独总结这个发送缓冲区的设计思想和实现细节,以及为何这样设计。
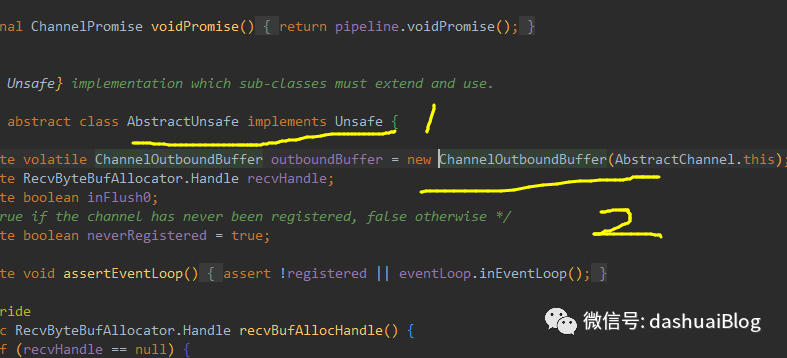
Netty为每个已经创建的Channel都绑定了一个ChannelOutboundBuffer对象,如下一个Netty的Channel的代码片段:黄色1处是Channel聚合的Unsafe,在每个Netty的Channel里,都会通过其unsafe获取一个独立的ChannelOutboundBuffer,如黄色2所示。即它调控的粒度是Channel级。
如下是官方对ChannelOutboundBuffer的解释:
*(Transport implementors only)an internal data structure used by{@link AbstractChannel}to store its pending*outbound write requests.*<p>*All methods must be called by a transport implementation from an I/O thread,except the following ones:*<ul>*<li>{@link#size()}and{@link#isEmpty()}li>*<li>{@link#isWritable()}li>*<li>{@link#getUserDefinedWritability(int)}and{@link#setUserDefinedWritability(int,boolean)}li>*ul>*p>*/即它是一个Netty内部的数据结构,由每个Channel独立保存一份,并且只能被Netty的I/O线程调度,除了一些get方法,比如size()方法,isEmpty方法等。回忆文章从源码出发:在宏观上把握Netty写数据到应用层缓冲区的过程中拆解的流程,当用户调用writeAndFlush方法发消息时,首先添加消息到ChannelOutboundBuffer,最终会层层调用到pipeline的头结点的write方法,内部会调用unsafe的write方法,如下由于unsafe的write和flush方法会被客户端,服务端复用,故被实现在了AbstractUnsafe类:
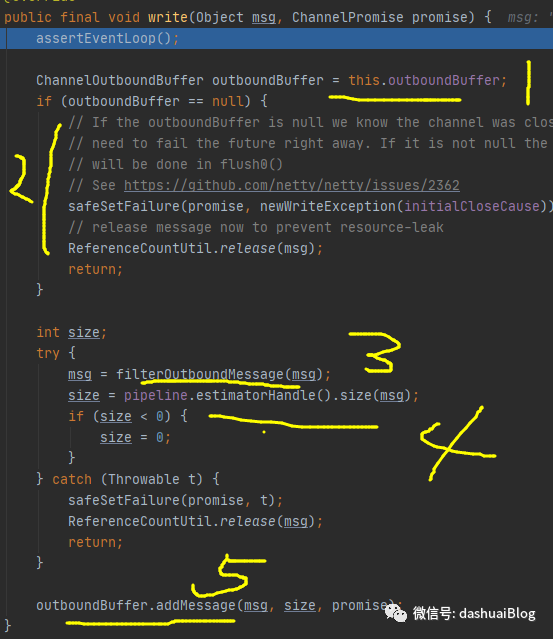
首先在黄色1处,拿到发送缓冲区的一个快照,正常情况黄色2不会执行,进入黄色3处的filter0utboundMessage(msg)方法——对非堆外内存进行转换,转换为堆外内存,即Netty的设计理念是——所有的I/O操作都走堆外内存,以提升性能。接着下一步是执行黄色4处代码——拿到当前msg消息对象的大小(单位是字节),接着看最后一行——黄色5处调用了ChannelOutboundBuffer的addMessage方法,目的是将待发送消息msg加入应用层的发送缓冲区,并且一旦加入就会通过promise回调用户的监听器。
下面进入addMessage方法细致的看下它的实现,该方法将本次待发送的msg以及msg的字节数,和异步对象promise当做参数传入:
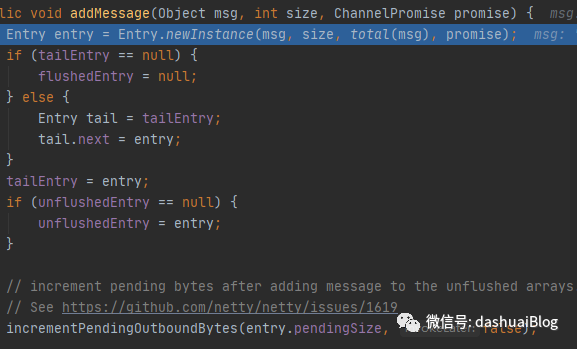
这里知道一个结论——ChannelOutboundBuffer的数据结构是一个单向Entry链表+Netty对象池,故上面的addMessage方法主要就是在操作单向链表的指针。
基本思路是:首先将待发送的msg——ByteBuf对象封装为ChannelOutboundBuffer内部的Entry节点,然后使用尾插法将该新节点加入Entry链表。最后在addMessage方法的结束处调用一个incrementPendingOutboundBytes方法,这是Netty的流控机制,前面也简单提过,后续专题总结。
下面梳理ChannelOutboundBuffer的单向Entry链表结构,如下是创建Entry节点的过程:
Entry entry=Entry.newInstance(msg,size,total(msg),promise);total方法会计算当前发送消息的字节数,本demo为6,然后进入newInstance方法实例化一个Entry:
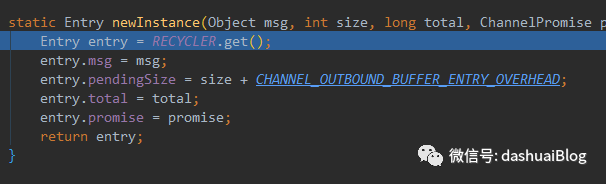
1、RECYCLER对象,它涉及到了Netty的对象池技术,此处先抓主要矛盾,不深究,后续专题总结,只需要知道它实现了一个线程安全的轻量级的对象池——通过复用已有的对象来避免频繁创建和回收对象带来的性能损耗。所以这个Entry节点可以被重复使用,即每次ChannelOutboundBuffer用完一个Entry,便将Entry的参数都置为null,然后仍回到对象池RECYCLER,下次可以拿出来重复利用,并且使用了本地线程存储来保证线程安全
2、属性pendingSize记录的是当前待发送消息msg的一个估计值,这里有一个容易费解的地方,即CHANNEL_OUTBOUND_BUFFER_ENTRY_OVERHEAD常量,它默认是96(单位字节),即Netty会给当前待发送的消息msg额外加上96字节,算作msg的估计值,后续会通过这个值去影响流量控制机制,关于这里的设计想法暂且不表,后续专题总结。属性total是当前待发送消息本身的大小。
对Entry有了一个理解后,下面梳理一下Entry链表的几个指针和属性:
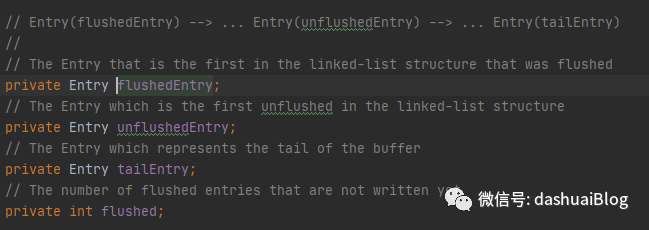
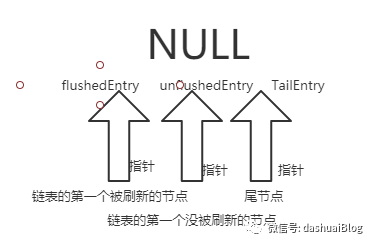
1、flushedEntry:代表被flush方法标记为已刷新的消息节点,即可以认为该Entry马上或者已经被发到网络了,它指向的是链表里第一个要被刷新出去的节点
2、unflushedEntry:代表只是通过write方法添加到了Entry链表的消息节点。它是链表里第一个等待刷新的节点
3、tailEntry:Entry链表的最后一个节点
4、next:链表中节点的下一个节点
5、属性flushed代表当前缓冲区的大小,即链表中还没有被刷新出去的节点的数量
下面看Entry链表是如何被组织的,回忆addMessage方法:
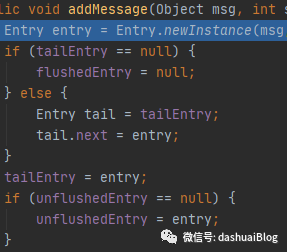
调用addMessage方法之前,Entry链表的样子如下:
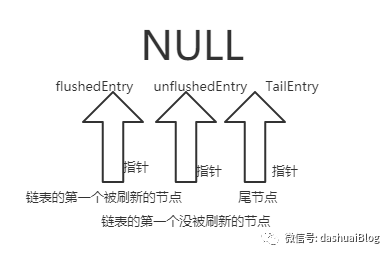
调用addMessage方法后,将待发送的消息节点,即新的Entry节点,通过尾插法追加到tailEntry节点后,同时tailEntry指向新Entry,unflushedEntry也指向新Entry,其结构变化为如下模样:
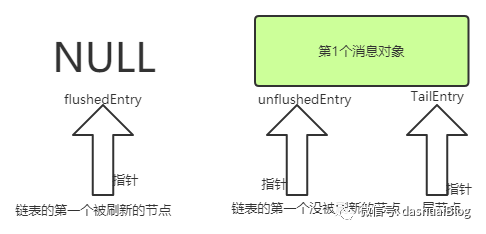
当第二个待发送消息被加入Entry链表时,它的结构变为如下模样:
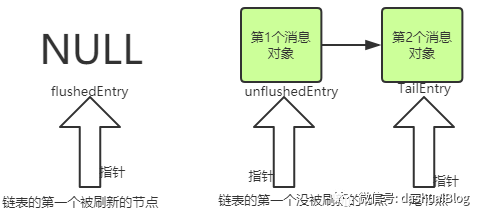
以此类推,用户只要没有执行flush操作,最终当前Channel的发送缓冲区的待发送消息的堆积形式如下,直到触发了流控保护后才停止堆积:
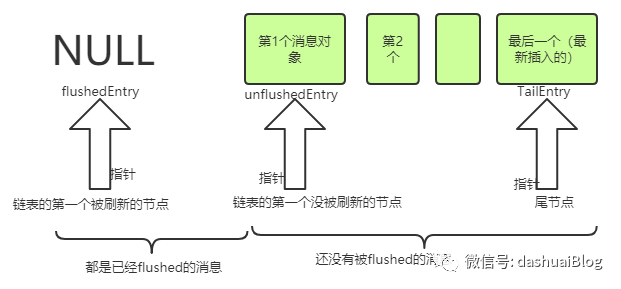
以上,也能看出这是一个FIFO的添加顺序,即Netty保证通过write添加的消息,会严格按照它的调用顺序缓存,其Entry链表被消费时总是先消费最老的节点。接着回忆flush的流程,当用户调用flush方法后,会调用到pipeline的头结点的flush方法,即unsafe的flush方法:
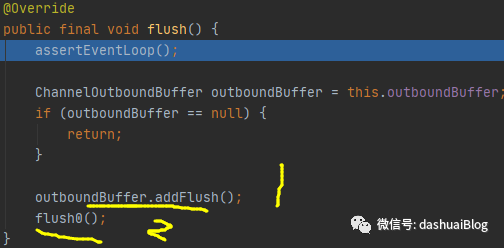
当调用黄色1处的addFlush方法时,会将unflushedEntry的引用赋给flushedEntry,然后将unflushedEntry置为null,即设置刷新消息的标记。如下:
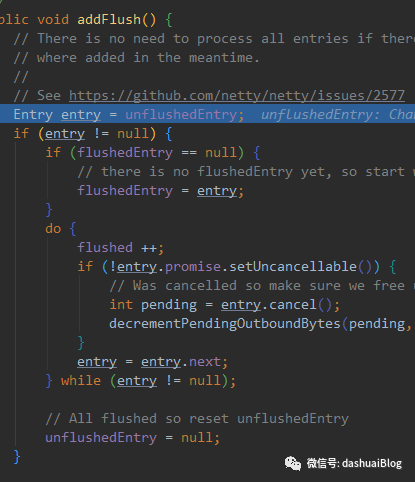
通过unflushedEntry指针拿到第一个待发送的消息节点,并且判null后,将这个unflushedEntry赋值给flushedEntry,然后开一个循环设置这些节点的标记,并且告诉用户不能做取消操作了,如果当前某个消息节点在设置之前就已经取消发送了,那么就将这个节点过滤(后续不会flush),同时将totalPendingSize减小。此时Entry链表的结构如下:
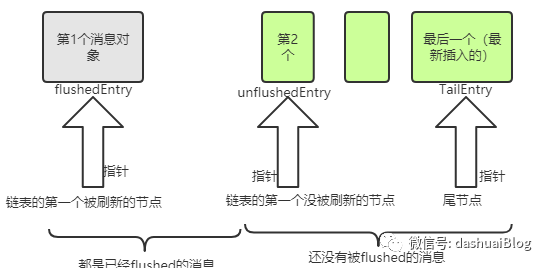
由于addFlush方法里会循环的设置待发送节点的标记指针,最终Entry链表变为如下的样子;
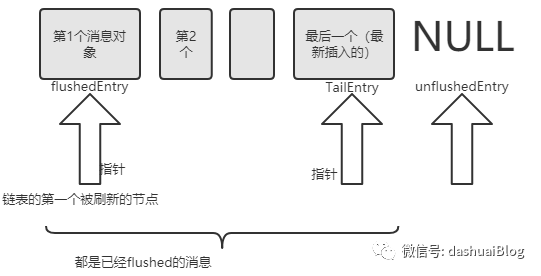
此时addFlush结束,但是以上操作仅仅对待发送消息节点做了标记和过滤,紧接着调用的flush0方法才会执行真正的刷新操作,回忆前面的文章从源码出发:在宏观上把握Netty刷新数据到网络的过程。
此时要真的刷新数据到Socket缓冲区里,会从flushedEntry节点开始,循环的将每个flushed状态的节点取出,存入一个JDK的ByteBuffer数组,通过nioBuffers方法做转化:
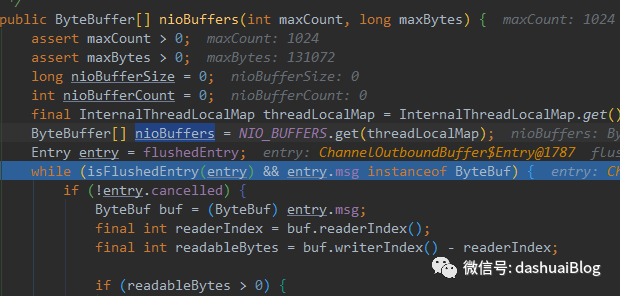
得到ByteBuffer数组后,后续分策略刷新。如果消息发送成功,那么调用ChannelOutboundBuffer的remove方法,将已发送消息从Entry链表中删除,此步骤也包括清理堆外内存,如果是非池化分配,那么直接释放——通过调用UNSAFE.freeMemory(address);,如果是池化内存分配,那么将内存回收到池子里,如下是Netty清理内存的核心方法free:
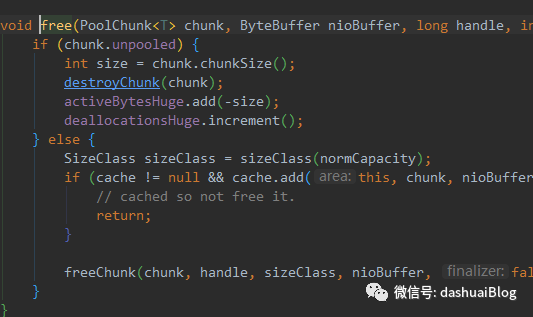
清理内存后,同时更新待发送的消息节点指针flushedEntry=flushedEntry.next。如下是此时链表的样子,红色方块代表已经刷新到了网络的消息:
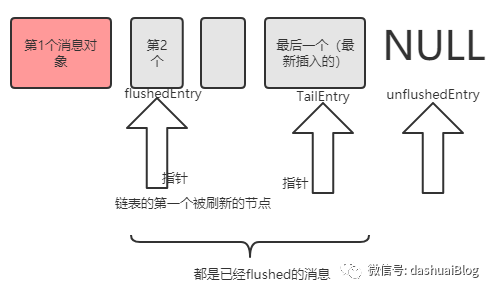
以上循环往复,直到Entry链表里已经没有flushed的消息节点,就把flushedEntry设置为null,最终缓冲区被排干:
做个小结——设计的意义
a)一方面是吞吐量和延时的考虑。可以联系TCP协议的Nagle算法,默认都是启用的,Java可以通过setTcpNoDelay(true)来禁用。Netty就是如下配置,参考Netty里配置的TCP_NODELAY参数作用是啥,应该如何调优?:
.childOption(ChannelOption.TCP_NODELAY,true)如果开启了Nagle算法(关闭TCP_NODELAY),那么在网络应用里就可能出现频繁的延时,用户体验极差。不过连续进行多次对小数据包的发送操作,本身就不是一个好的编程模式,在应用层就应该进行优化。对于既要求低延时,又有大量小数据传输,还同时想提高网络利用率的应用,只能用UDP自己在应用层来实现可靠性保证了。更合理的方案还是应该使用一次大数据的写操作,而不是多次小数据的写操作,所以Netty也在应用层设计实现了发送缓冲区。
b)给用户取消写操作的时间上的缓冲
Netty设计的write方法,在内部有一个addMessage操作,它会添加待发消息进ChannelOutboundBuffer,并且这个方法并不会刷新数据到Socket,只有调用了flush方法,才会将unflushedEntry的引用转移到flushedEntry引用中,表示即将刷新这个flushedEntry,至于为什么这么做?
因为Netty提供了实现了promise模式的API,使得每个I/O操作都可以被取消,例如,“我”在一些条件下,不打算发这个ByteBuf了,所以flush之前,都是可以反悔的。
c)方便实现流控
众所周知,TCP协议在发端也有发送缓冲区,在我理解,Netty在应用层搞一个缓冲区和传输层TCP协议设计缓冲区的目的一致,即在应用层提高吞吐量和实现应用层的流控。如下语句:
ctx.channel().write("hello dashuaiRPC!\r\n");只是将hello dashuaiRPC!\r\n消息写到了Netty的ChannelOutboundBuffer对象,此处并不涉及到网络相关的操作。这样就可以在一定程度上提高服务的吞吐量,当累计当一定数量,在调用flush方法实现一次性批量发送。即write方法可以调用多次,flush才是真正的写入到Socket。并且由于发送缓冲区的存在,Netty还能方便的在应用层实现限流保护,以防止内存被打爆。
d)底层实现=单向链表+对象池
一方面可以节省内存,减少GC次数,另一方面链表实现缓冲区,也能减少数据的移动,只需要修改指针的指向即可。
e)在其它的Netty的功能实现上,起到一个辅助作用,比如辅助记录某个Channel的发消息的进度和总量,为空闲检测等做支持。可以参考文章:Netty进化之路:赏析空闲检测处理器对写检测的优化
END
点亮在看,你最好看
点击此处写留言~


点


