目录
一、定义 What is Machine Learning
二、建模 Model Representation
三、一元线性回归 Linear Regression with One Variable
3.1 一元线性归回的符号约定 Notation
3.2 一元线性回归 Linear Regression with One Variable
3.3 代价函数 Cost Function
3.4 梯度下降概述 Gradient Descent Outline
3.5 梯度下降算法 Gradient Descent Alg
3.5.1 同步更新参数 Simultaneously Update
3.5.2 收敛 Convergence
3.5.3 学习率的取值 evaluate alpha
3.5.4 梯度下降更新参数公式
四、多元线性回归 Multiple Features and Gradient Descent
4.1 多元线性归回的符号约定 Notation
4.2 多元线性回归 Linear Regression with Multiple Variables
4.3 估值、代价函数、梯度下降
4.4 多元线性回归的矩阵描述
4.5 平均值归一化 Mean Normalization
4.6 多项式拟合 Polynomial Regression
4.7 过拟合Overfit与欠拟合Underfit
4.8 一般等式、梯度下降和一般等式的比较
复习Andrew Ng的课程Machine Learning,总结线性回归、梯度下降笔记一篇,涵盖课程week1、week2。
一、定义 What is Machine Learning
有两种业界比较认可的对机器学习的定义。
一种是Aithur Samuel在1959年给出的定义。机器学习:不需要明确编程就能使计算机具有学习能力的研究领域。
另一种是Tom Mitchell在1998年给出的定义。适定学习问题:如果一个计算机程序在任务T上的性能(以P衡量性能)随着经验E的提高而提高,那么它就被称为从经验E对某些任务T和性能度量P的学习。(拉倒吧,还是看英文原文吧!)
Machine Learning Definition
-Aithur Samuel 1959. Machine Learning: Field of study that gives computer the ability to learn without being explicitly programmed.
-Tom Mitchell 1998. Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and performance measure P, if its performance on T, as measured by P, improves with experience E.
二、建模 Model Representation
机器学习分很多种类
- Supervised Learning 有监督的学习
- Unsupervised Learning 无监督的学习
- Reinforcement learning 强化学习
- Recommender System 推荐系统
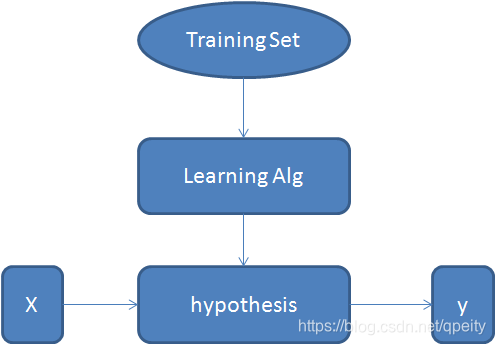
但是他们的建模几乎是一样的。都是通过在训练集(Training Set)上运行学习算法(Learning Alg)得到估值函数(hypothesis),这个假设函数可以对输入的特征X进行预测(估计 estimated value),输出y。
三、一元线性回归 Linear Regression with One Variable
3.1 一元线性归回的符号约定 Notation
约定一元线性回归问题中的符号定义。
训练集的大小。
输入变量,也就是特征。
输出变量,也就是估值。
一个训练用例。
训练集中的第i个用例。
3.2 一元线性回归 Linear Regression with One Variable
一元线性回归,Linear Regression with One Variable也叫做Univariate Linear Regression。其输入特征是一维的,输出值也是一维的。估值为 。一元线性回归的思想是,选择合适的
和
使
对训练集
上的
接近
。

Idea: Choose
so that
is close to
for our training example
.
minimize
3.3 代价函数 Cost Function
Cost Function Definition is square error function. 代价函数是平方误差函数。这个函数用来衡量估值与真实值之间的偏差。
代价函数是
其中 。使
最小的
和
值确定
。 公式里面为了表示“平均”,所以除以
,但为什么不简单的就写个
而是
呢?因为后面求导数的时候,平方的求导会把这个2抵消掉,这样导数式的样子就和逻辑回归问题的导数式子形式上统一了。
注意:
是关于
的函数,
和
是参数。也就是说求取导数的时候,变量是
是关于
的函数,
3.4 梯度下降概述 Gradient Descent Outline
Have some function , Want
Outline:
- Start with some
- Keep changing
梯度下降的思想就是,我们先假定有
有某个值,通过改变
的值使
减小,直至得到最小值。
3.5 梯度下降算法 Gradient Descent Alg
3.5.1 同步更新参数 Simultaneously Update 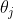
重复进行
,
其中是学习率(learning rate),必大于0。
注意,这种更新是各个维度上的同步更新,也就是说更新过程是这样的
3.5.2 收敛 Convergence
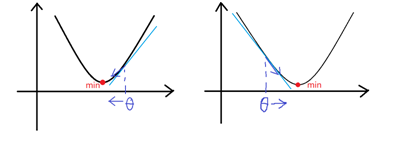
对于一元线性回归,代价函数的几何形状是个碗状曲面,因此代价函数一定收敛。根据上面同步更新的公式,我们分两种情况讨论,示意图如下。
当时,
减小,趋向于收敛;
当时,
增大,也趋向于收敛;
3.5.3 学习率 的取值 evaluate alpha
的取值 evaluate alpha
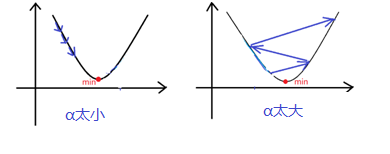
这个过程要注意学习率的取值应适中。如果
太小,收敛速率低,学习缓慢。如果
太大,可能跳过minimum不能收敛,甚至发散。示意图如下。
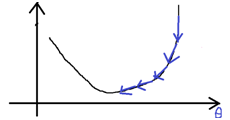
根据同步更新参数公式,,随着接近minimum,
逐渐减小。在接近minimum时,梯度下降自动减小步长,因此收敛的过程中不需要改变学习率
。示意图如下。
at local optima。经过学习获得的是局部最优解。
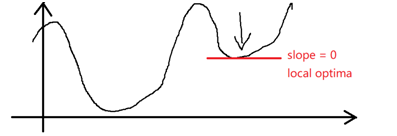
3.5.4 梯度下降更新参数公式
由代价函数得到两个参数的偏导数函数。
当时,
。
当时,
。
四、多元线性回归 Multiple Features and Gradient Descent
4.1 多元线性归回的符号约定 Notation
约定多元线性回归问题中的符号定义。
训练集的大小。
特征的维度大小。
第i个训练用例。
第i个训练用例的第j维特征值。
4.2 多元线性回归 Linear Regression with Multiple Variables
多元线性回归的估值为
4.3 估值、代价函数、梯度下降
为了方便起见,我们给特征值增加一个维度,也就是。
特征值和参数都写作向量的形式:
估值写作矩阵相乘的形式:
代价函数:
同步更新参数,以使代价函数最小,对于每一个参数而言
也就是说
……………………
写作矩阵式
4.4 多元线性回归的矩阵描述
综合4.3中讨论的内容,我们这样定义,并给出多元线性回归的矩阵描述公式
满足
那么梯度下降过程公式为
4.5 平均值归一化 Mean Normalization
Feature Scaling: Get every feature into approximately a range .
使用梯度下降时,为了加速收敛,应将特征值进行缩放(Feature Scaling)。缩放的具体算法就是Mean Normalization平均值归一化。
Mean Normalization平均值归一化的具体做法是,取得某一维度上特征值的平均值,最大值
,最小值
。
进行缩放,使缩放后该维度上特征值的平均值接近于0。
注意:
- 平均值归一化算法只能对维度
的特征值进行,决不能对
进行。因为
- 使用了平均值归一化,必须要在这个过程中记录下每个特征的平均值和标准差。在梯度下降得到模型参数以后,给出新的测试样本,那么就要用这个平均值和标准差先对这个测试样本进行平均值归一化,再计算估值。否则,估值是错误的。
4.6 多项式拟合 Polynomial Regression
回归问题也可以采用多项式(开方)来进行拟合。
4.7 过拟合Overfit与欠拟合Underfit
机器学习问题解决的答案并不是唯一的,我们用一元线性回归可以得到一种估值,也可以用多项式拟合得到另一种估值,也可以用开方的拟合得到另一种估值。不同的估值并没有对错之分,完全取决于我们选择了什么样的模型来解决问题。
对于明显的采用一元线性回归或者开平方拟合就能解决的问题,如果非要使用多项式拟合,在给定的训练集上可能效果很好。但是,随着特征(输入)范围的扩大,拟合效果将可能出现较大偏差,这就是过拟合Overfit。同理,如果我们用一元线性回归(“直线”)去解决一个明显是多项式回归的问题,或者多项式拟合的阶数不够,就会走向另一个极端欠拟合Underfit。
因此,我们应当对训练集的数据进行预处理,剔除明显带有错误或者重大偏差的数据,并小心谨慎的选择解决问题的模型(恰拟合),避免过拟合或欠拟合。
4.8 一般等式、梯度下降和一般等式的比较
根据,我们得出一个求参数
的一般等式。过程并不是严格的数学证明,只是一种演示,不严谨不要喷我。
这样我们不需要经过梯度下降,根据这个公式进行矩阵运算即可求得参数。如果使用octave或者matlab等软件,对于求矩阵逆的运算应使用pinv函数,以防止矩阵
不可逆。
最后对比一下梯度下降和一般等式的优缺点。
| Gradient Decent 梯度下降 | Normal Equation 一般等式 |
|---|---|
| Need to choose 需要选择学习率 | No Need to choose 不需要选择学习率 |
| Need many iterations 需要迭代 | No need to iterate 不需要迭代 |
| Work well even when n is large 当参数个数n较大时依然性能良好 | Need to compute slow if n is large 需要求矩阵的逆 当参数个数n较大时计算缓慢 |