目录
一、为啥是Xception
二、Xception结构
2.1 Xception结构基本描述
2.2 实现细节
2.3 DeepLabV3+改进
三、记录pytorch采坑relu激活函数inplace=True
Xception笔记,记录一些自己认为重要的要点,以免日后遗忘。
复现Xception论文、DeepLabV+改进的Xception,代码地址https://github.com/Ascetics/Pytorch-Xception
一、为啥是Xception
Xception脱胎于Inception,Inception的思想是将卷积分成cross-channel conv和spatial conv,更准确的说是先用1x1卷积得到几个不同channel(小于输入channel)的结果,再在这些结果上分别用3x3、5x5 conv,也就是论文Figure 1描述的那样。Inception的这种算法背后,本质上是将cross-channel conv和spatial conv解耦。
考虑将Inception简化:去掉平均池化层,只用3x3 conv(2个3x3 conv相当于1个5x5 conv)。就测到了论文Figure 2描述的这种结构。
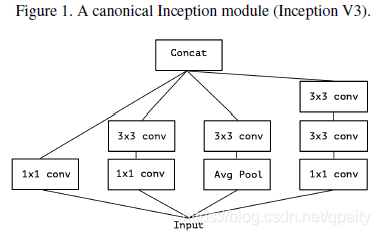

在Figure 2的基础上,用1个channel很大的1x1 conv 将输入映射到一个channel很大的输出上。再将这个输出“切成几段”,“切成几段”分别做3x3 spatial conv,就得到了论文中Figure 3的结构。作者在此提出一个问题,这样将cross-channel conv和spatial conv完全解耦分开合理吗?完全解耦分开,可以这样做吗?
基于Figure 3提出的假设,做一个极端的Inception模型。还是先用1个channel很大的1x1 conv 将输入映射到一个channel很大的输出上,然后“切成几段”变成“切片”,每个channel切一片。对每个channel做3x3卷积。这样极端的设计就接近于深度可分离卷积depthwise separable convolution。


为什么是“接近”,而不是“就是”呢?因为和depthwise separable convolution的操作顺序、操作内容不一样。
- 顺序上,depthwise separable convolution,先用3x3 conv进行spatial conv,后用1x1 conv进行cross-channel conv;极端版本Inception先用1x1 conv再用3x3 conv;
- 内容上,depthwise separable convolution,spatial conv和cross-channel conv之间没有非线性(ReLU激活函数);极端版本Inception,卷积之间有非线性(ReLU激活函数);
作者认为第一个区别是不重要的,特别是因为这些操作要在堆叠(深度学习)的环境中使用。第二个区别重要,作者研究了一下,结论见论文Figure 10。本文后面会解释。
要看懂Xception,需要了解VGG、Inception、Depthwise Separable Convlution和ResNet,都会用到。
二、Xception结构
2.1 Xception结构基本描述
卷积神经网络特征提取中的卷积都可以完全解耦,变成深度可分离卷积(Xception也就是Extreme Inception的意思)。接收了这一设定,Xception结构被解释为论文Figure 5的样子。
Xception的特征提取基础由36个conv layer构成。这36个conv layer被组织成14个module,除了第一个和最后一个module,其余的module都带有residual connection(残差,参看何凯明大神的ResNet)。简言之,Xception结构就是连续使用depthwise separable convolution layer和residual connection。

2.2 实现细节
如Figure 5 描述所述。
输入先经过Entry flow,不重复;再经过Middle flow,Middle flow重复8次;最后经过Exit flow,不重复。
所有的Conv 和 Separable Conv后面都加BN层,但是Figure 5没有画出来。
所有的Separable Conv都用depth=1,也就是每个depth-wise都是“切片”的。
注意, depthwise separable convolution在spatial conv和cross-channel conv之间不要加ReLU激活函数,任何激活函数都不要加。论文Figure 10展示了,这里不加激活函数效果最好,加ReLU、ELU都不好。

还有一些是论文中没有明说的细节。
Residual Connection在1x1卷积后面也加上BN。Residual Connection加上以后,不要着急做激活函数,仔细看图,激活函数ReLU是属于下一个Block的。这就导致了代码实现上采坑,下一节详细记录一下。也算长个记性。
2.3 DeepLabV3+改进
这一部分在下一篇博客,学DeepLabV3+中再记录。
三、记录pytorch采坑relu激活函数inplace=True
上面2.2写了一个细节,如果严格按照论文的示意图来实现Xception,那么每个block第一个操作不是SeparableConv,而是ReLU(红色框)。如果仅仅是第一个操作是ReLU也没有关系,但是旁边还有个Residual Connection(蓝色框)。自古红蓝出CP,于是坑来了,在反向传播的时候,报了个错,明显是因为inplace导致了某个对象被modify了,反向传播求梯度报错。(此时我所有代码的ReLU用的都是inplace=True,省内存嘛)


以Entry Flow的Block为例,先来欣赏一下错误的代码。
class _PoolEntryBlock(nn.Module):def __init__(self, in_channels, out_channels, relu1=True):"""Entry Flow的3个下采样module按论文所说,每个Conv和Separable Conv都需要跟BN论文Figure 5中,第1个Separable Conv前面没有ReLU,需要判断一下,论文Figure 5中,每个module的Separable Conv的out_channels一样,MaxPool做下采样:param in_channels: 输入channels:param out_channels: 输出channels:param relu1: 判断有没有第一个ReLU,默认是有的"""super(_PoolEntryBlock, self).__init__()self.project = ResidualConnection(in_channels, out_channels, stride=2)self.relu1 = Noneif relu1:self.relu1 = nn.ReLU(inplace=True) self.sepconv1 = SeparableConv2d(in_channels, out_channels,kernel_size=3, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(out_channels)self.relu2 = nn.ReLU(inplace=True)self.sepconv2 = SeparableConv2d(out_channels, out_channels,kernel_size=3, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(out_channels)self.maxpool = nn.MaxPool2d(3, stride=2, padding=1)passdef forward(self, x):identity = self.project(x) # residual connection 准备if self.relu1: # 第1个Separable Conv前面没有ReLU,需要判断一下x = self.relu1(x)x = self.sepconv1(x) # 第2个Separable Convx = self.bn1(x)x = self.relu2(x)x = self.sepconv2(x) # 第2个Separable Convx = self.bn2(x)x = self.maxpool(x) # 下采样2倍x = x + identity # residual connection 相加return xpass采坑时的做法,先算出Residual Connection,再做relu、SeparableConv。Residual Connection时,已经进行过一次卷积操作,此时要求输入x本身不能发生改变,不能再被modify。后面的ReLU(inplace=True)恰恰就modify了x。所以反向传播时报错。
改变执行的先后顺序呢?也不行。如果先ReLU(inplace=True),那么x也被modify了,再做Residual Connection时输入就不是block输入的那个x了。
解决的办法,改为ReLU(inplace=False),或者Residual Connection的输入改为x.clone(),总之不能省内存……正确的代码已经push到github上了,地址详见文章开头。
为此,我写了一个简化的模型:
- class Wrong就是采坑的错误实现;
- class RightOne就是改为ReLU(inplace=False);
- class RightTwo就是Residual Connection的输入改为x.clone();
一杯茶,一包烟,一个bug改一天……
import torch
import torch.nn as nnclass Wrong(nn.Module):def __init__(self):super(Wrong, self).__init__()self.convs = nn.Sequential(nn.ReLU(inplace=True),nn.Conv2d(3, 3, 3, padding=1))self.residual = nn.Conv2d(3, 3, 3, padding=1)passdef forward(self, x):r = self.residual(x) # 卷积之后,x就不能modify了h = self.convs(x) # relu就modify了x,反向传播时候会报错h = h + rreturn hpassclass RightOne(nn.Module):def __init__(self):super(RightOne, self).__init__()self.convs = nn.Sequential(nn.ReLU(inplace=False), # 改法1,别省内存了nn.Conv2d(3, 3, 3, padding=1))self.residual = nn.Conv2d(3, 3, 3, padding=1)passdef forward(self, x):r = self.residual(x)h = self.convs(x)h = h + rreturn hpassclass RightTwo(nn.Module):def __init__(self):super(RightTwo, self).__init__()self.convs = nn.Sequential(nn.ReLU(inplace=True),nn.Conv2d(3, 3, 3, padding=1))self.residual = nn.Conv2d(3, 3, 3, padding=1)passdef forward(self, x):r = self.residual(x.clone()) # 改法2,clone还是消耗内存的h = self.convs(x)h = h + rreturn hpassif __name__ == '__main__':in_data = torch.randint(-2, 2, (1, 3, 2, 2), dtype=torch.float)in_label = torch.randint(0, 3, (1, 2, 2))print(in_data.shape)func = nn.CrossEntropyLoss()t = RightTwo()in_data = in_data.cuda()in_label = in_label.cuda()t.cuda()out_data = t(in_data)print(out_data.shape)loss = func(out_data, in_label)loss.backward()