16.Synchronized关键字加在静态方法和实例方法的区别?
- 修饰静态方法,是对类进行加锁(Class对象),如果该类中有methodA和methodB都是被Synch修饰的静态方法,此时有两个线程T1、T2分别调用methodA()和methodB(),则T2会阻塞等待直到T1执行完成之后才能执行。
- 修饰实例方法时,是对实例进行加锁,锁信息在实例对象的对象头,如果调用同一个对象的两个不同的被Synch修饰的实例方法时,看到的效果和上面的一样,如果调用不同对象的两个不同的被Synch修饰的实例方法时,则不会阻塞。
17. CountDownLatch的用法?
- 让主线程await,业务线程进行业务处理,处理完成时调用countDownLatch.countDown(),CountDownLatch实例化的时候需要根据业务去选择CountDownLatch的count。
- 让业务线程await,主线程处理完数据之后进行countDownLatch.countDown(),此时业务线程被唤醒,然后去主线程拿数据,或者执行自己的业务逻辑。
18.解释一下volatile:
功能:
- 保证线程可见性
- 防止指令重排序
底层实现:
- 可见性:
- 被修饰的变量在被修改后可以立即同步到主内存,被修饰的变量在每次是用之前都从主内存刷新。JVM底层通过内存屏障来实现可见性。OS底层通过MESI(缓存一致性协议)。
- 写内存屏障可以促使处理器将当前store buffer(存储缓存)的值写回主存。(先不记)
- 读内存屏障可以促使处理器处理invalidate queue(失效队列),进而避免由于Store Buffer和Invalidate Queue的非实时性带来的问题。(先不记)
- 禁止指令重排序:
- 内存屏障来禁止指令重排序。
- JMM内存屏障的策略:
- 在每个volatile写操作的前面插入一个StoreStore屏障。
- 在每个volatile写操作的后面插入一个StoreLoad屏障。
- 在每个volatile读操作的前面插入一个LoadLoad屏障。
- 在每个volatile读操作的后面插入一个LoadStore屏障。
使用场景(待完整总结,20231121):
根据经验总结,volatile最适合在一个线程写,其他线程读的场景。
19. 描述一下ThreadLocal的底层实现形式及实现的数据结构?
作用:
提供线程的局部变量,保证线程安全。使用不当会造成内存泄漏。
原理和数据结构:
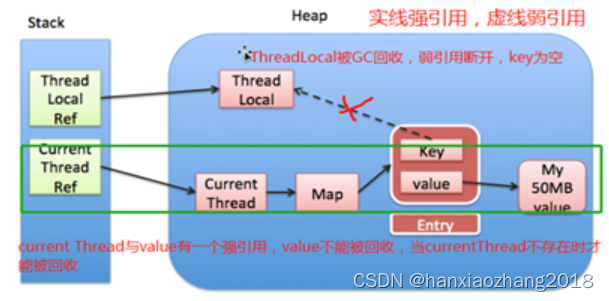
- ThreadLocal定义了ThreadLocalMap数据结构,它主要包含一个Entry类型的数组,Entry的keyThreadLocal本身(是弱引用),value为ThreadLocal对应添加的值。
- 它通过key.threadLocalHashCode & (table.length – 1)确定数组索引位置,如果该位置的key不对,再通过nextIndex()计算下一个索引位置;它通过线性开放定址法减少hash冲突。
- 每个线程(Thread类)都有一个ThreadLocalMap类型的threadLocals变量,存储这些局部变量(ThreadLocal对象)。
内存泄漏问题:
- Entry的key是弱引用,在下一次GC后,就被回收了。此时,Map中存在key为null的Entry,ThreadLocal不会主动回收这些,可能会发生内存泄漏。
- get、set、remove等方法都可以有清除key为null的Entry。
ThreadLocal碰撞解决与神奇的 0x61c88647:
- 每次创建ThreadLocal实例时,哈希值都会累加 0x61c88647,目的是让哈希值能均匀的分布在2的N次方的数组里,减少碰撞。类似HashMap。
20. 线程池问题:
Executors提供了5种线程池:
- newFixedThreadPool()(工作队列:LinkedBlockingQueue)
- newCachedThreadPool()(工作队列: SynchronousQueue【同步移交队列,该队列没有缓冲区】、核心线程数为零、最大线程数为无限)
- newSingleThreadExecutor()(工作队列:LinkedBlockingQueue)
- newScheduledThreadPool()(工作队列:DelayedWorkQueue)
- newSingleThreadScheduledExecutor()(工作队列:DelayedWorkQueue)
线程池参数:
- int corePoolSize 线程池核心线程大小
- int maximumPoolSize 线程池最大线程数量
- long keepAliveTime 空闲线程存活时间
- TimeUnit unit 空闲线程存活时间单位
- BlockingQueue workQueue 工作队列
- ThreadFactory threadFactory 线程工厂,主要用来创建线程(默认的工厂方法是:Executors.defaultThreadFactory()对线程进行安全检查并命名)
- RejectedExecutionHandler handler 拒绝策略
4种拒绝策略:
当有界队列被填满后,拒绝策略(饱和策略)开始发挥作用。具体策略有:AbortPolicy中止策略(默认)、DiscardPolicy抛弃策略、DiscardOldestPolicy抛弃最旧的策略、CallerRunsPolicy调用者运行策略。
工作队列:
ArrayBlockingQueue、 LinkedBlockingQueue、SynchronousQueue、PriorityBlockingQueue、DelayedWorkQueue。
线程池执行顺序:
- 默认情况下,创建完线程池后并不会立即创建线程,而是等到有任务提交时才会创建线程来进行处理。
- 当线程数小于核心线程数时,每提交一个任务就创建一个线程来执行(即便当前有线程处于空闲状态),直到当前线程数达到核心线程数。
- ... ...
- 如果某个线程的空闲时间超过了keepAliveTime,将被标记为可回收的,并且当前线程池的当前大小超过了核心线程数时,这个线程将被终止。
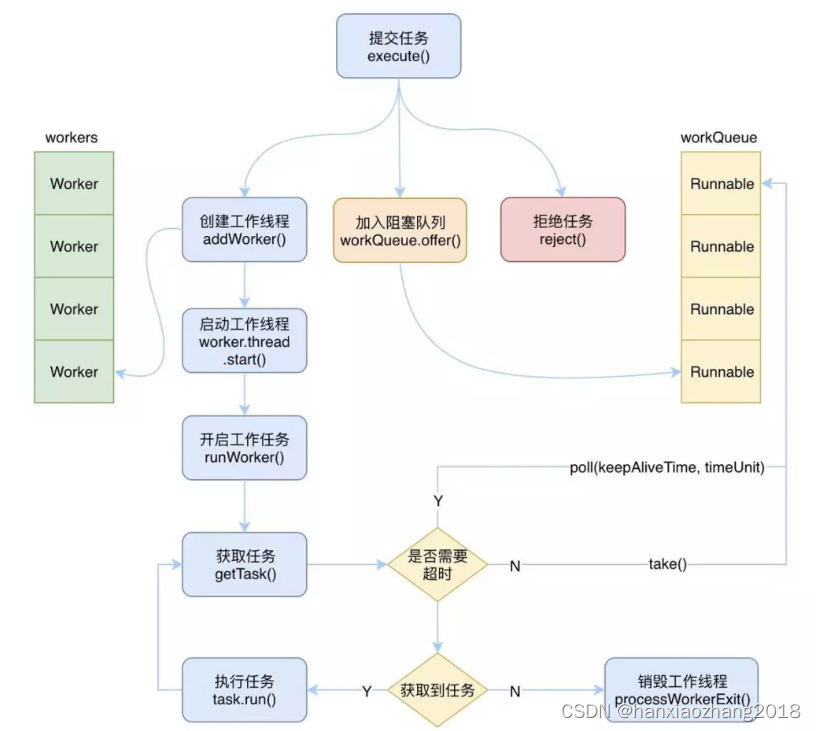
线程池原理(execute()举例):
- ctl变量(AtomicInteger):高3位表示线程池的生命周期,底29位表示线程池的线程容量。
- 生命周期:RUNNING -1、SHUTDOWN 0 、STOP 1、TIDYING 2、TERMINATED 3
- Worker对象底层也用到了AQS。
- 也用到了ReentrantLock锁 --> mainLock。
- 面试前,源码过一遍。
任务结束后会不会回收线程?
不会回收线程,线程会重复利用。
我通过源码了解:
- 在getTask()中,会循环获取队列中任务,直到队列为空并且当前有效线程数量大于核心线程数量或者其他条件时,会减去有效线程数,结束循环,返回null。
- 在runWorker()中,循环调用getTask()获取任务执行,如果getTask()==null结束循环,最后finally模块会调用processWorkerExit()回收Worker即工作线程。
- processWorkerExit()中,completedAbruptly为true时,即出现异常时,会减去有效线程数。
- processWorkerExit()是会将当前Worker回收。 如果线程异常结束,不能满足最小需要的线程数,就会添加,调用addWorker()
21. 什么叫做阻塞队列的有界和无界,实际中有用过吗?
有界与无界的概念:
- 有界队列:固定大小的队列
- 无界队列:没有设置固定大小的队列
具体队列:
- ArrayBlockingQueue:
- 一个由数组结构组成的有界阻塞队列。
- 一把锁(ReentrantLock),不支持读写同时操作。
- 可以实现生产者消费者模型(put()+take()),底层使用同一个锁的两个condition。
- LinkedBlockingQueue:
- 一个由链表结构组成的无界阻塞队列。
- 入队使用一把锁(ReentrantLock),出队使用一把锁,支持读写同时操作。
- 可以实现生产者消费者模型(put()+take()),底层使用两个锁的condition。
- PriorityBlockingQueue:
- 一个支持优先级排序的无界阻塞队列。
- 大堆、小堆,实现compareTo。
- DelayQueue:
- 一个使用优先级队列实现的无界阻塞队列,可以实现精确的定时任务。
- SynchronousQueue:
- 一个不存储元素的阻塞队列。
- LinkedTransferQueue:
- 一个由链表结构组成的无界阻塞队列。
- 它是LinkedBolckingQueue和SynchronousQueue的合体。生产者会一直阻塞,直到所添加到队列的元素被某一个消费者所消费。
- LinkedBlockingDeque:
- 一个由链表结构组成的双向无界阻塞队列。
- 可以用在“工作窃取”模式中 -> ForkJoinPool。
22. 如何在方法栈中进行数据传递?
- 通过方法参数传递。
- 通过共享变量。
- 如果在用一个线程中,还可以使用ThreadLocal进行传递。
23. 描述一下AQS?****
简介(AbstractQueuedSynchronizer):
AQS是一个用于构建锁和同步器的框架。它是除了java自带的synchronized关键字之外的锁机制。例如ReentrantLock、ReentrantReadWriteLock、Semaphore、FutureTask等都是基于AQS实现的。
状态变量state:
AQS中定义了一个状态变量state,特点:volatile变量修饰,CAS方式更新。
它的两种使用方法:(拓展时说)
- 互斥锁:
- 当AQS只实现为互斥锁的时候,每次只要原子更新state的值从0变为1成功了就获取了锁,可重入是通过不断把state原子更新加1实现的。
- 互斥锁 + 共享锁:
- 当AQS需要同时实现为互斥锁+共享锁的时候,低16位存储互斥锁的状态,高16位存储共享锁的状态,主要用于实现读写锁。
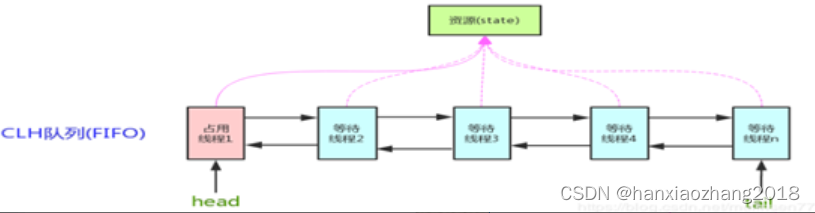
AQS队列(CLH队列):
是一个FIFO的双向队列,AQS依赖它来完成同步状态的管理,CLH队列包含多个Node对象,每个节点表示一个线程,它保存着线程的引用(thread)、状态(waitStatus)、前驱节点(prev)、后继节点(next)、条件队列中的后继节点(nextWaiter)。
获取锁失败(非tryLock())的线程都将进入这个队列中排队,等待锁释放后唤醒下一个排队的线程(互斥锁模式下)。
AQS队列的头结点不为空,头结点是加锁成功的节点,在设置成头节点后,会将该节点的线程设置为null。
waitStatus值:CANCELLED= 1、SIGNAL=-1、CONDITION=-2、PROPAGATE=-
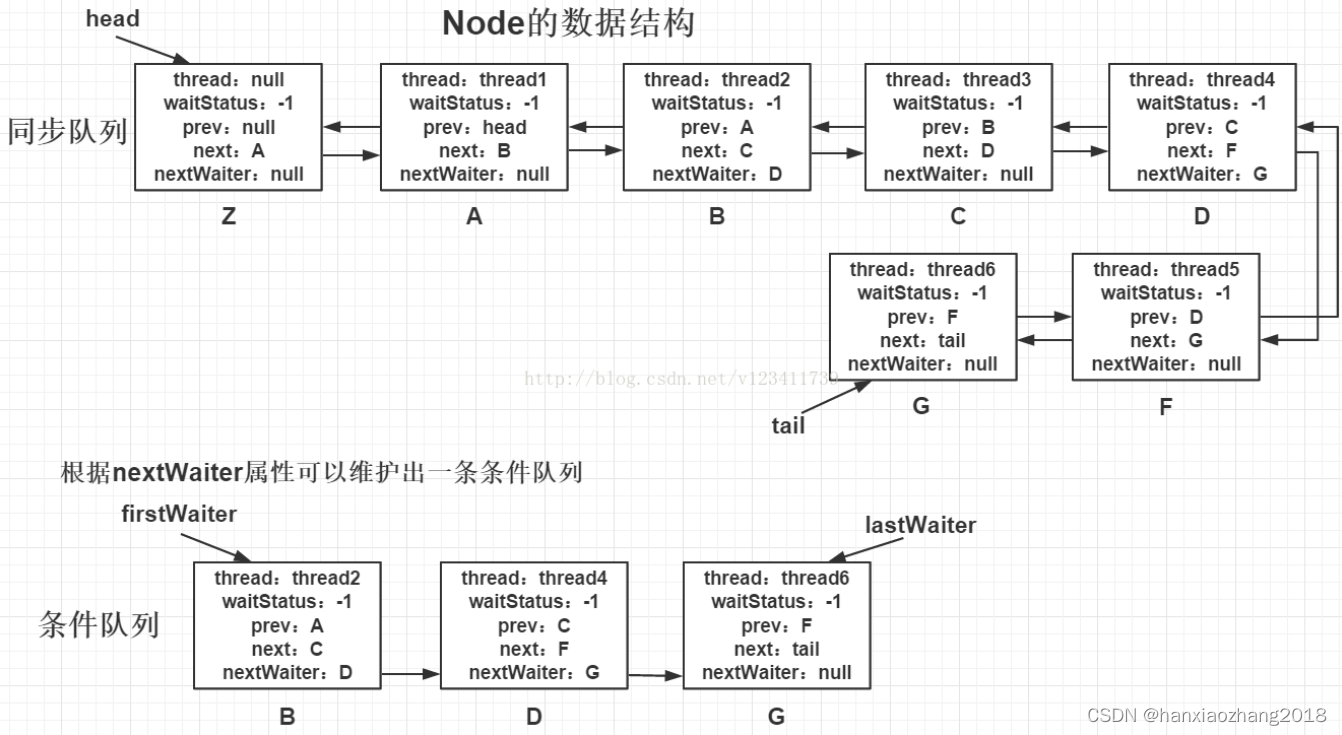
Condition队列:
内部类ConditionObject,它实现了Condition接口,主要用于实现条件锁。
ConditionObject中也维护了一个队列,这个队列主要用于等待条件的成立,当条件成立时,这个队列中的元素将其移动到AQS的队列中,等待占有锁的线程释放锁后被唤醒。
Condition典型的运用场景:在BlockingQueue中的实现,当队列为空时,获取元素的线程阻塞在notEmpty条件上,一旦队列中添加了一个元素,将通知notEmpty条件,可从阻塞队列中获取元素。
模板方法:
AQS里面定义了一系列的模板方法,我们只需重新部分钩子方法就可以,比如下面这些:
- isHeldExclusively():该线程是否正在独占资源(只有用到condition需实现)。
- tryAcquire(int):独占方式,尝试获取资源。成功true,失败false。
- tryRelease(int):独占方式,尝试释放资源。成功true,失败false。
- ... ...
常用的方法:
- acquire(int):独占模式的获取,忽略中断。
- acquireInterruptibly(int):独占模式的获取,可中断
- release(int):独占模式的释放。
- ... ...
源码:
面试前,源码过一遍,这个简单过一下,感觉没啥问的。
24. 简要描述一下ConcurrentHashMap底层原理?
JDK1.7:
- 分段锁:内部主要是一个Segment数组,而数组的每一项又是一个HashEntry数组,元素都存在HashEntry数组里。因为每次锁定的是Segment对象,也就是整个HashEntry数组,所以又叫分段锁。
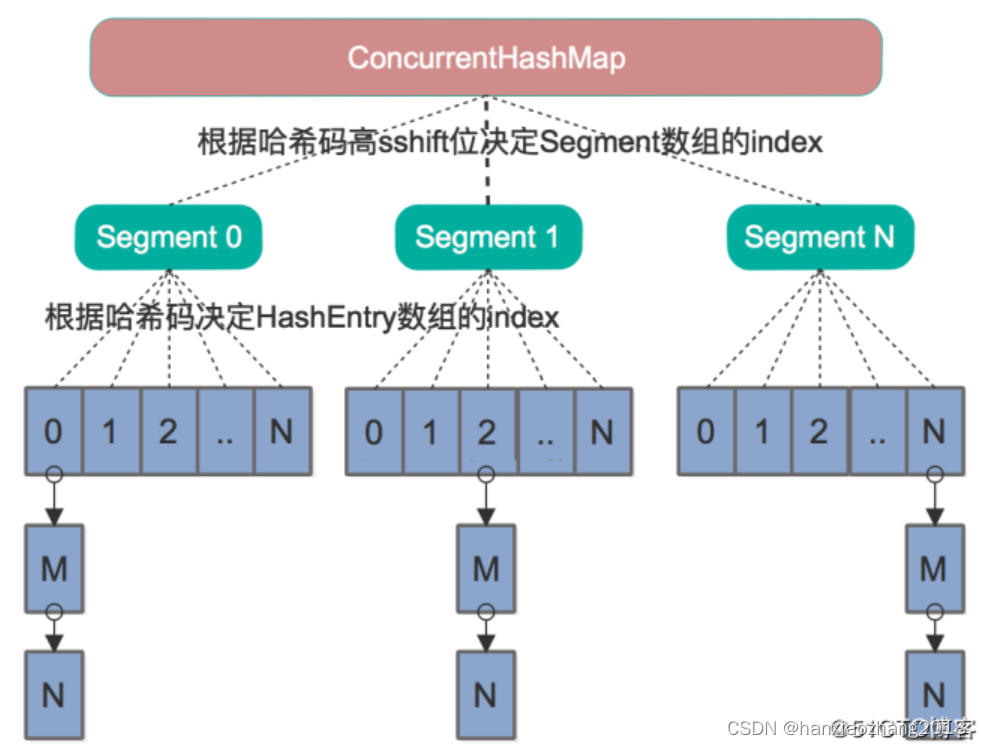
- 计算Segment数组位置:
![]()
- ConcurrentHashMap默认长度是16,即有16个Segment,最大支持16个线程并发。
JDK1.8:*****
- ConcurrentHashMap舍弃了分段锁的实现方式,利用CAS + synchronized + volatile(关键变量,例如table、nextTable、sizeCtl)来保证并发更新的安全。
- 底层数据结构:数组+链表+红黑树来实现。
- 重要成员变量:
- table:默认为null,初始化发生在第一次插入操作,用来存储Node节点数据。
- nextTable:默认为null,扩容时新生成的数组,其大小为原数组的两倍。
- sizeCtl :默认为0,用来控制table的初始化和扩容操作。
- 1:代表table正在初始化
- N:表示有N-1个线程正在进行扩容操作
- Node:保存key,value及key的hash值的数据结构(其中value和next都用volatile修饰)。
- put过程简述:
- put操作采用CAS+synchronized实现并发插入或更新操作:
- 当前bucket为空时,使用CAS操作,将Node放入对应的bucket中。
- 出现hash冲突,则采用synchronized关键字。
- 倘若当前hash对应的节点是链表的头节点,遍历链表,若找到对应的node节点,则修改node节点的值,否则在链表末尾添加node节点;
- 倘若当前节点是红黑树的根节点,在树结构上遍历元素,更新或增加节点。
- 倘若当前map正在扩容(f.hash == MOVED),先协助扩容,在更新值。
- put操作采用CAS+synchronized实现并发插入或更新操作:
ConcurrentHashMap 不允许key value 为空。 -> null 是特殊值,充当了所有非标量归约运算的隐式基础。