文章目录
- 前言
- 背景
- 问题
- Remote Compaction
- 接口设计
- 实践过程中的一些经验
- 1. Compaction Tier
- 2. 加速 Compaction Tier的db open
- 3. Disable L0->L0 compaction
- 总结
- 参考
前言
又到了让人激动的周末,而且最近这一个月女朋友回老家了,所以这几周的周末时光都是自己安排。白天公司学习一段时间,中午蹭一顿健身餐,下午借公司的健身福利去游一个不限时的泳,顺便练一练自己的肌肉,还是希望今年末的时候能够实现年初一口气100个俯卧撑的目标,晚上看一会会小说(最近看到一个硬核理工男写的科幻小说,有一种三体的感受,当然还是因为自己懒,不想思考,也就跟着大佬的思路来让自己分泌一些多巴胺罢了 )。
絮絮叨叨,没意思,来,看一些有意思。
刚好周五早上8.00 参加了rocksdb社区举办的 线上 meetup,主要是听社区大佬们最近一年做的一些有趣的且已工业化的特性,全程英文,再加上很多大佬是印度口音,很多细节都没有听明白,不过siying 大佬很考虑国内的开发者们的感受,在微信群里解答一些大家没有听明白的疑惑的地方,整场的分享都是围绕 rocksdb 在 rockset (分析型数据库)实践上的一些痛点 以及 对应的优化,这一些优化特性是具有通用性的,能够被其他类似的服务借鉴。
这一篇主要是分享 remote compaction 功能的背景 以及 其 在 rocksdb-cloud 中的应用。后续 的文章会介绍 Rockset 中使用rocksdb 的 ribbon filter 以及 Cluster search index。
remote compaction的实践收益还是备受业界关注的,因为分享到这一块大家提的问题是最多的,包括 tidb的 东旭也用不太好的英文提了相关的问题(有得时候英文还真是挺重要的,一口流利准确的英文还是能极大得提升和大佬们的交流效率)。
背景
以 Rocksdb 的LSM-tree 的架构为例

新的写入请求会先写入到 memtable,当memtable满了之后会flush形成一个新的sst文件到持久化存储。
一些后台线程会被用来进行compaction,对一个sst文件的集合进行重复key以及delete key的清理,并将最后保留的key写入到新的sst,旧的sst文件的集合在没有读的时候会被删除掉。Compaction的过程需要大量的计算资源和I/O 资源,而且随着用户写入速度越快,如果想要保持系统的稳定(不会有持续累积的pending-compaction),那么更多的 cpu 以及 I/O需要被用来调度compaction 。
大家这里会说,我们在使用Rocksdb write-heavy场景 的 时候大多数的瓶颈是在磁盘上,而且使用性能更好的optane5800 以及 pmem 这种高性能介质瓶颈才可能出现在CPU上。
所以,接下来讨论的痛点其实并不是单机Rocksdb compaction中的问题,而是底层存储是共享存储的时候compaction 引入的痛点,比如rockset 提供云原生数据分析服务的时候底层就是使用 s3 作为共享存储的,底层存储并不是瓶颈,大概率瓶颈会落到虚拟服务器的cpu上。
个人理解,remote compaction 在仍然是shard-nothing 架构 下的数据存储(newsql ,nosql, 分布式kv等)中并没有很明显的优势,因为shard-nothing 架构下,如果存储用的是nvme-ssd及以上 则 compaction消耗的 CPU 是会到瓶颈, 而如果用的是sata-ssd及以下,则基本都是I/O瓶颈。所以,kvell 在nvme-ssd及以上性能的存储介质中重新做了架构的设计,compaction对于这样的顺序和随机I/O性能差异不是很大的存储介质来说还是较为冗余。然而在shared-storage 场景中,做离线分析,数据仓库,数据湖这种大数据量存储下的分析服务还是有一定的应用场景。
问题
因为compaction 的计算和I/O 调度在rocksdb中是混合在一起的,并没有分离计算和存储,这个时候如果CPU成为瓶颈,那用户想要更高的吞吐,只能扩机器了,而且对于只需要一定存储容量的用户来说扩展机器之后增加的存储容量就被浪费了,这种方案归纳为如下两个问题:
- 扩机器之后,数据需要在不同的服务器之间进行同步,而如果想要提供更好性能的实时分析能力,这种情况性能就很差了。
- 底层存储资源因为没有被完全利用到,就会被浪费,无形中增加了存储成本。
Remote Compaction
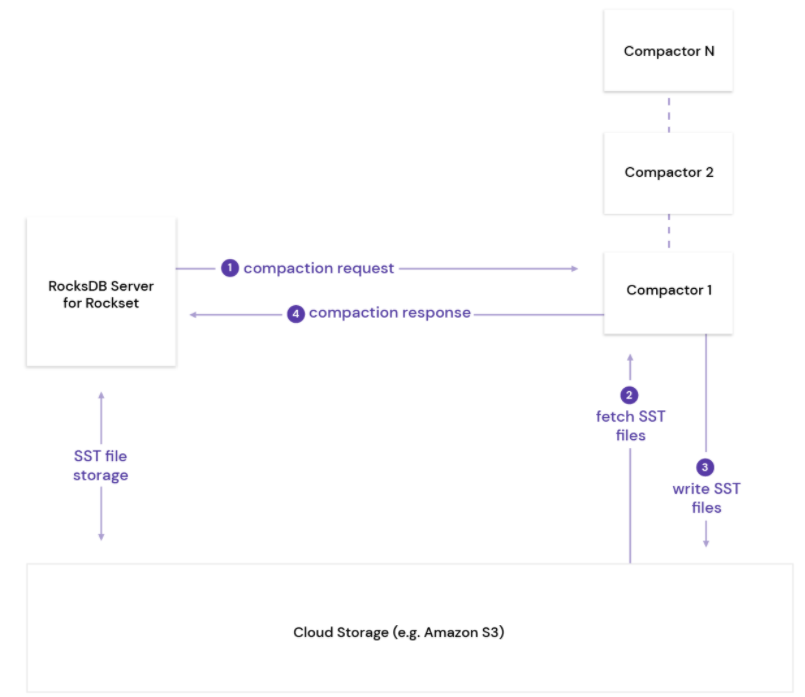
rockset 提供包括实时、数据仓库、数据湖 等分析服务,对于用户来说在使用实时分析服务的时候希望最小的成本拥有最高的性能,这也是我们做存储所想要达到的目标。而Remote Compaction 则是 rockset 为了解决rocksdb 在共享存储之上cpu是瓶颈的一种有效解决方案,并且已经集成到了rocksdb-cloud (rockset的存储底座,将rocksdb对接到底层的s3之上)中。大体思想如下:
- 对于lsm-tree来说已经生成的sst文件是只读的,而且他们会被持久化到s3 共享存储上,并且被能够被其他所有服务器访问;当然这个共享存储也可以是其他的系统,比如HDFS/CephFs等。
- Rocksdb-cloud server A能够对一个compaction服务进行封装 通过rpc 发送到一个远端的无状态的服务器B
- B服务器解析收到的compaction调度服务,并从s3 读取需要参与compaction的sst文件
- B 服务执行compaction的计算逻辑(堆排序,处理overwrite/delete/merge等),并将最后的新的sst文件写入到 s3存储中。
- B 将compaction 执行的状态通过rpc 返回给server A。
大体架构如下:
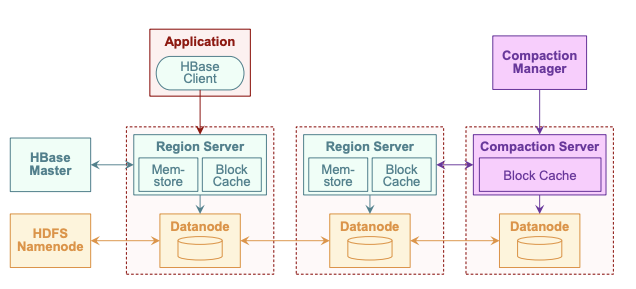
同样的Remote Compaction 逻辑在HBASE中的实现也是差不多的(数据主体存储在 hdfs 共享存储上,上层提供一个hbase 的region server 作为一个单独的compaction manager 进行整个hbase 集群 统一的compaction 调度):
接口设计
这一些接口都是在上图的服务区A 也就是 Rocksdb Server上执行的。
-
注册一个可插拔的compaction服务:
Status RegisterPluggableCompactionService(std::unique_ptr<PluggableCompactionService>);这个接口主要是用来注册一个可以运行的compaction job。
像原本的compaction job逻辑主要包含如下几步:- file picker, 选择需要参与compaction的文件
- process-key, 逐个处理参与compaction的文件的k/v(包括读上来,排序,处理type,写文件)
- intall results,更新最后的元数据(生成的sst文件元数据会更新到manifest中,保存当前db状态),以及删除过期文件
所以这个可插拔的服务也需要提供大体的步骤:
-
调度执行 compaction 以及 生成新的sst文件
Status Run(const PluggableCompactionParam& job, PluggableCompactionResult* result)std::vector<Status> InstallFiles(const std::vector<std::string>& remote_paths,const std::vector<std::string>& local_paths,const EnvOptions& env_options, Env* local_env)Run是可以单独执行的Compaction job,通过RPC 在远端的Tier 节点单独执行。
InstallFiles指将远端服务器的sst文件写入到本地共享存储中。
实践过程中的一些经验
1. Compaction Tier
执行可插拔 Compaction的主体逻辑是在远端的一个Compaction Tier服务器上进行的。这个服务器可以执行多个Job,每一个job被称为Compactor。首先,Compactor 收到 rocksdb server 的 compaction调度rpc请求,会非常轻量的open(ghost mode方式打开) 共享存储的rocksdb 实例(仅加载一些必要的sst文件元数据)而不会去直接加载sst。一旦成功打开了Rocksdb实例,那就可以进行compaction的调度了。
rocksdb-cloud 提供了 rocksdb::CloudOptions cloud_options; 来进行open过程的选择:
2. 加速 Compaction Tier的db open
原本打开一个rocksdb实例的时候 需要获取整个db的sst文件列表 以及 每个sst的大小(获取每一个sst的properties-block),对于数据仓库这样的巨量存储来说,这样open获取sst信息的话会极度耗时。而且,这一些信息是从共享存储获得的,对于共享存储来说,他们还需要去对应的物理服务器去读相关的数据,整个链路可能会跨多次网络,耗时自然就增加了。怎么能够让 每一个 compactor 快速得打开db就是 remote compaction第一个需要解决的问题。
这一些配置 则是能够加速open db的过程,主要是能够减少一些 rpc的消耗。
rocksdb::CloudOptions cloud_options;
cloud_options.ephemeral_resync_on_open = false;
cloud_options.constant_sst_file_size_in_sst_file_manager = 1024;
cloud_options.skip_cloud_files_in_getchildren = true;rocksdb::Options rocksdb_options;
rocksdb_options.max_open_files = 0;
rocksdb_options.disable_auto_compactions = true;
rocksdb_options.skip_stats_update_on_db_open = true;
rocksdb_options.paranoid_checks = false;
rocksdb_options.compaction_readahead_size = 10 * 1024 * 1024;
3. Disable L0->L0 compaction
remote-compaction 的实现性能肯定没有本地compaction的效率高,因为中间涉及到rpc 以及 数据的网络传输,所以实际的 remote compaction 效率会远低于local compaction,只能通过足够高的并发来提升compaction效率(compaction 不会再影响用户侧服务器的cpu使用了)。因为L0->L1 调度不能并发执行,只能单线程,在L0->L1执行期间rocksdb会执行L0->L0的compaction,防止L0满,达到write-stall的限制。
而rocksdb-cloud 之所以要禁止这个功能,是因为 L0->L0 compaction 往往会生成一个特别大的sst文件,而这个特别大的文件则会导致compactor 的执行时间会特别长,从而无法高效得将L0 的文件 compaction 下去,间接造成write-stall。所以,rocksdb-cloud的经验就是禁止L0->L0的compaction 相比于 L0->L1 + L0 -> L0 不会出现write-stall的概率更高。
总结
总的来说 remote compaction 应用场景还是 性能要求没有那么高的 数据仓库/数据湖 这种 以云原生为基础服务的 分析场景。对于真正实时性要求特别高的TP/AP业务来说,shared-nothing的 架构才是满足需求的选择,而在shared-nothing架构下的remote compaction 其实并没有必要,毕竟CPU瓶颈/磁盘瓶颈 之间的差异没有那么大。那有的人会说 offload-compaction 的计算到其他的硬件(FPGA),这个阿里的X-DB 已经做过探索,其实收益相比于FPGA的成本有限,要不就是像rENANIC 为cassandra 做的一个完整的链路,不仅仅offload compaction,还包括通过SPDK/DPDK 旁路读/写和网络。不然,仅仅offload compaction 到FPGA的收益 相比于FPGA 本身的成本来说还是不够的。
参考
1. Remote Compactions in RocksDB-Cloud
2. Compaction management in distributed key-value datastores




