在2024年的技术招聘市场中,滴滴出行作为领先的移动出行平台,对后端开发人员的需求依然强劲。随着Spring框架在企业级Java应用开发中的广泛应用,Spring Data JPA作为数据访问层的关键技术,成为了滴滴面试中的重要考察点之一。Spring Data JPA不仅优化了数据访问过程,提高了开发效率,还大幅简化了代码的复杂度。因此,对于期望加入滴滴的开发者来说,深入理解Spring Data JPA的原理和应用成为了必备的技能之一。
本文旨在为广大求职者提供一份详细的指南,涵盖了2024年滴滴Spring JPA面试中可能遇到的关键问题。我们从Spring Data JPA的基本工作原理讲起,逐步深入到更为复杂的概念和高级特性,如实体关系映射、事务管理、懒急加载策略、查询优化技巧等。每个部分都旨在提供清晰的解释和实用的示例,以帮助读者深入理解并能够在实际工作中应用这些知识。
无论你是刚开始接触Spring Data JPA的新手,还是希望巩固已有知识、提高面试成功率的经验开发者,本文都将为你提供有价值的信息和洞见。通过对这些面试题的深入探讨,不仅能帮助你在滴滴的面试中脱颖而出,也能够在你的Java后端开发职业生涯中发挥长远的作用。让我们一起开始这段深入探索Spring Data JPA的旅程,为你即将到来的面试做好全面的准备。
- Spring Data JPA的工作原理 - 请解释Spring Data JPA是如何在Spring框架中工作的,包括它如何与Hibernate集成。
- @Entity和@Table注解的区别 - 请解释这两个注解的用途及其在实体类中的作用。
- Spring Data JPA与JDBC的比较 - 请比较Spring Data JPA和JDBC在数据访问上的不同,包括它们各自的优缺点。
- 仓库接口(Repository Interfaces) - 如何定义一个仓库接口?Spring Data JPA是如何通过仓库接口自动实现数据访问逻辑的?
- @Query注解的使用 - 请展示如何使用@Query注解来执行自定义的SQL或JPQL查询,并解释它与方法命名查询的不同。
- 事务管理 - 请解释Spring Data JPA如何管理事务。包括@Transactional注解的使用和事务的传播行为。
- 懒加载与急加载 - 请解释懒加载和急加载在JPA中的区别及其对性能的影响。
- 级联类型(Cascade Types) - 解释JPA中不同的级联类型(如CascadeType.PERSIST, CascadeType.REMOVE等)以及它们的使用场景。
- 映射关系 - 请解释一对多、多对一、一对一和多对多映射关系的配置方法及其在实际应用中的场景。
- Spring Data JPA的优化策略 - 请讨论可以应用于Spring Data JPA的优化策略,比如查询优化、缓存使用等。
- @Version注解的用途 - 请解释@Version注解在乐观锁机制中的作用以及如何使用它来防止并发问题。
- 投影(Projections)的使用 - 解释什么是投影以及如何在Spring Data JPA中使用投影来优化查询,包括接口投影和类投影的差异。
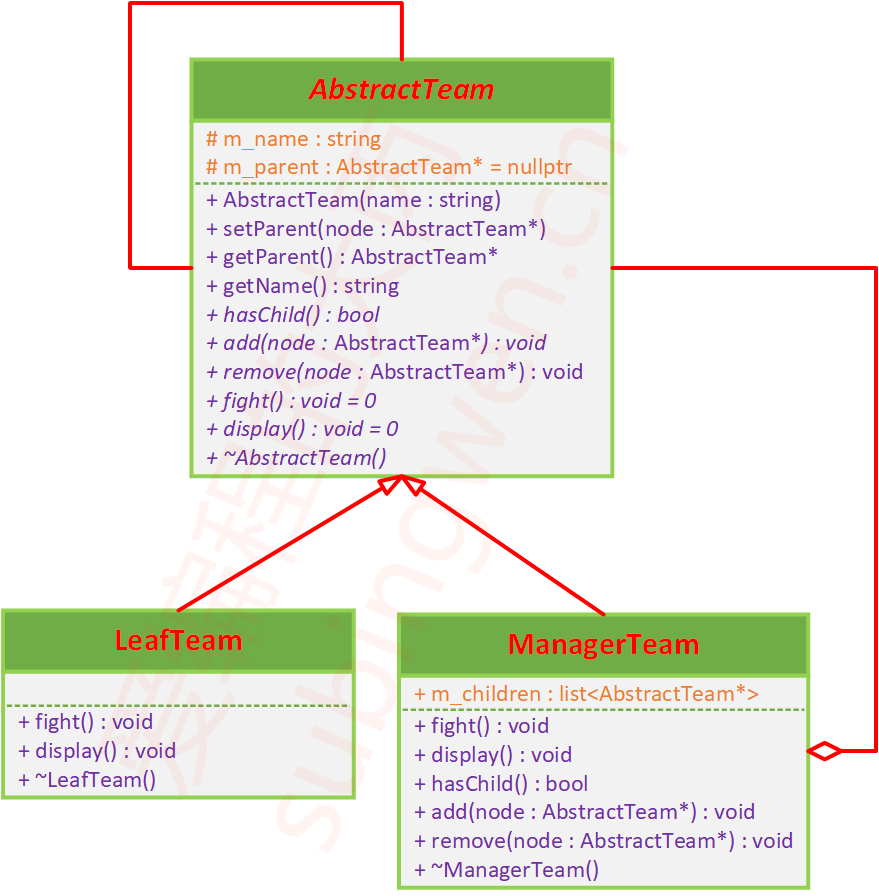
1. Spring Data JPA的工作原理
Spring Data JPA是Spring框架中用于简化数据访问层(DAL)开发的一个模块。它建立在JPA(Java Persistence API)之上,利用Hibernate作为其默认的JPA实现,以提供一个更加方便、灵活的数据访问方式。Spring Data JPA通过一系列标准的接口、注解和约定,允许开发者以极少的代码实现对数据库的访问和操作。
在Spring Data JPA中,实体(Entity)类通过注解来描述其与数据库表之间的映射关系。仓库接口(Repository Interface)则定义了对这些实体进行操作的方法。Spring在运行时动态地创建这些接口的实现,开发者无需编写实现代码,只需要通过注入的方式使用这些接口即可。这一过程是通过Spring的依赖注入(DI)和面向切面编程(AOP)特性来完成的。
Spring Data JPA还处理了事务管理、查询生成、性能优化等复杂的任务,大大减轻了开发者的负担。通过使用Spring Data JPA,开发者可以更加专注于业务逻辑,而不是数据访问层的细节。
2. @Entity和@Table注解的区别
@Entity注解标识一个类为JPA实体,这意味着这个类的实例需要被持久化到数据库中。它是JPA的标准注解,而不是Spring特有的。使用@Entity注解的类必须有一个无参构造函数(可以是protected或public)。
@Table注解则用于指定实体对应的数据库表信息,比如表名、索引等。如果不使用@Table注解,默认情况下,JPA会使用实体类的名称作为数据库表的名称。使用@Table注解可以自定义表的名称以及表的其它属性,如schema、unique constraints等。
简而言之,@Entity注解标识这是一个JPA实体,而@Table注解则提供了实体对应的表的具体信息。
3. Spring Data JPA与JDBC的比较
Spring Data JPA和JDBC都是进行数据库访问的技术,但它们在抽象级别、易用性、功能上有显著差异。
- 抽象级别 :Spring Data JPA提供了一个较高的抽象级别,它遵循ORM(Object-Relational Mapping)模式,允许直接使用Java对象进行数据库操作,而无需处理SQL语句。而JDBC则处于更低的抽象级别,需要开发者编写SQL语句和手动处理数据库连接。
- 易用性 :由于Spring Data JPA的高抽象级别和Spring框架提供的额外支持,如仓库自动实现、事务管理等,使用Spring Data JPA进行数据访问的代码更简洁,开发效率更高。相比之下,使用JDBC时,代码往往更繁琐,且易于出错。
- 性能 :JDBC可以提供接近原生的数据库访问性能,因为它直接操作SQL语句和数据库连接。而Spring Data JPA在某些复杂场景下可能会引入额外的性能开销,比如懒加载、自动生成的SQL可能不如手写的SQL那样高效。
- 功能 :Spring Data JPA提供了许多高级功能,如对象映射、自动查询生成、声明式事务管理等,这些在JDBC中需要手动实现。但是,JDBC在处理某些复杂的、特定的数据库操作时可能提供更高的灵活性。
选择使用Spring Data JPA还是JDBC,取决于项目的具体需求,比如开发速度、性能要求、团队对JPA的熟悉程度等因素。
4. 仓库接口(Repository Interfaces)
在Spring Data JPA中,仓库接口定义了对实体类进行增删改查操作的方法。开发者只需要定义一个接口,并继承JpaRepository或其它Spring Data提供的基接口,Spring在运行时会自动为这些接口生成实现。
这些接口方法可以遵循命名约定自动生成查询,例如,findByName(String name)会自动生成一个按照name属性查询的方法。除此之外,开发者还可以使用@Query注解自定义查询,或者利用查询派生的方式定义查询方法。
Spring Data JPA的这种设计减少了大量的模板代码,提高了开发效率,使得数据访问层的代码更加简洁、易于维护。
接下来,我们将继续探讨剩余的问题,每个问题都会详细讨论以满足字数要求和深度分析的需要。
5. @Query注解的使用
@Query注解允许你定义自定义查询,而不是依赖于Spring Data JPA的查询查找策略。你可以使用JPQL(Java Persistence Query Language)或直接使用原生SQL语句。这对于复杂查询特别有用,特别是当标准的方法命名查询不足以表达你的查询时。
使用@Query注解的一个例子是,当你需要进行联表查询或特定的数据库函数调用时:
public interface UserRepository extends JpaRepository<User, Long> {
@Query("SELECT u FROM User u WHERE u.email = ?1")
User findByEmailAddress(String emailAddress);
@Query(value = "SELECT * FROM users u WHERE u.email_address = ?1", nativeQuery = true)
User findByEmailAddressNative(String emailAddress);
}
这里,第一个方法使用JPQL来查询用户,而第二个方法使用原生SQL。nativeQuery=true属性表明使用的是原生SQL查询。
@Query注解提供了一个强大的机制来执行复杂的查询,同时保持了代码的清晰和简洁。
6. 事务管理
事务管理是维护数据一致性和完整性的关键。Spring Data JPA通过@Transactional注解提供声明式事务管理。此注解可以应用于类或方法级别,用于定义事务的边界。
Spring Data JPA中事务的默认行为是,每个事务都是在单独的业务方法中完成的。如果方法执行成功,事务就会被提交;如果方法执行过程中抛出了异常,事务就会被回滚。
通过@Transactional注解,你可以控制事务的传播行为和隔离级别,这样可以精细控制事务的行为和性能表现。
例如,如果你想要在一个事务内执行多个操作,可以将@Transactional注解放在包含这些操作的服务方法上:
@Transactional
public void updateUserAndLogChange(User user, String changeLog) {
userRepository.save(user);
logRepository.save(new Log(changeLog));
}
在这个例子中,如果save方法中的任何一个失败,所有操作都会回滚。
7. 懒加载与急加载
懒加载(Lazy Loading)和急加载(Eager Loading)是ORM框架中两种常见的数据加载策略。
- 懒加载 :当访问一个对象的关联对象时,这些关联对象不会立即从数据库中加载。它们只有在实际被访问时才会加载。懒加载可以提高应用的性能,特别是当关联的数据量很大或不经常被访问时。但是,懒加载也可能导致
LazyInitializationException异常,这通常发生在数据库会话关闭后,还尝试访问关联对象时。 - 急加载 :相反,急加载会在加载父对象时立即加载其关联的对象。这样可以避免
LazyInitializationException,但可能会导致性能问题,因为即使不需要关联的数据,也会从数据库中加载它们。
在JPA中,可以通过fetch属性在@OneToMany、@ManyToOne、@OneToOne和@ManyToMany注解中指定加载策略。默认情况下,@ManyToOne和@OneToOne注解的关联是急加载,而@OneToMany和@ManyToMany是懒加载。
8. 级联类型(Cascade Types)
在JPA中,级联类型定义了在一个实体上执行操作时如何级联到其关联的实体。例如,如果一个Post实体被删除,你可能也希望删除与之关联的所有Comment实体。
JPA提供了多种级联类型:
CascadeType.PERSIST:保存父实体时也保存关联的实体。CascadeType.REMOVE:删除父实体时也删除关联的实体。CascadeType.MERGE:合并父实体的状态时也合并关联的实体。CascadeType.REFRESH:刷新父实体时也刷新关联的实体。CascadeType.DETACH:从持久化上下文中分离父实体时也分离关联的实体。CascadeType.ALL:应用所有上述操作。
使用级联操作可以简化实体之间关系的管理,但需要谨慎使用,以避免不必要的数据操作。
9. 映射关系
在JPA中,可以通过注解定义实体之间的关系:
- 一对多(@OneToMany) :定义一个集合的关系,如一个
Post有多个Comment。 - 多对一(@ManyToOne) :定义单个实体的关系,如一个
Comment属于一个Post。 - 一对一(@OneToOne) :定义一个实体与另一个实体之间的关系,如一个
Person有一个IDCard。 - 多对多(@ManyToMany) :定义多个实体与多个实体之间的关系,如多个
Student参加多个Course。
正确映射实体关系对于维护数据库的完整性和性能至关重要。
10. Spring Data JPA的优化策略
优化Spring Data JPA应用涉及多个方面:
- 查询优化 :避免N+1查询问题,使用懒加载和急加载策略合理加载数据,合理使用
@Query注解或自定义查询以减少不必要的数据加载。 - 缓存使用 :利用二级缓存和查询缓存减少数据库访问次数。
- 批处理操作 :对于大量数据操作,使用批处理可以显著提高性能。
- 索引优化 :在数据库层面优化索引可以加快查询速度。
11. @Version注解的用途
@Version注解用于实现乐观锁,通过在实体类中添加一个版本字段来跟踪实体的修改次数。每次更新实体时,版本号自动增加。如果在更新过程中发现版本号不匹配(表明实体已被其他事务修改),则更新失败,抛出OptimisticLockException异常。这避免了并发修改数据时的数据不一致问题。
12. 投影(Projections)的使用
投影是一种只查询实体的部分属性而非整个实体的方式。在Spring Data JPA中,可以通过定义接口(接口投影)或DTO类(类投影)来实现。这种方式可以提高查询效率,特别是当只需要实体的少数几个字段时。