1. 数据与文字的表示方法
1.数据格式
选择数的表示时要考虑的因素:
要表示的数的类型:决定表示方式
可能遇到的数值范围:确定存储、处理能力
数值的精确度:处理能力相关
数据的存储、处理所需的硬件代价:造价高低
计算机中常用的数据表示格式(优缺点):
定点格式(Fixed-Point Representation)小数点位置固定
浮点格式(Floating-Point Representation)小数点位置不固定
2.定点数的表示方法
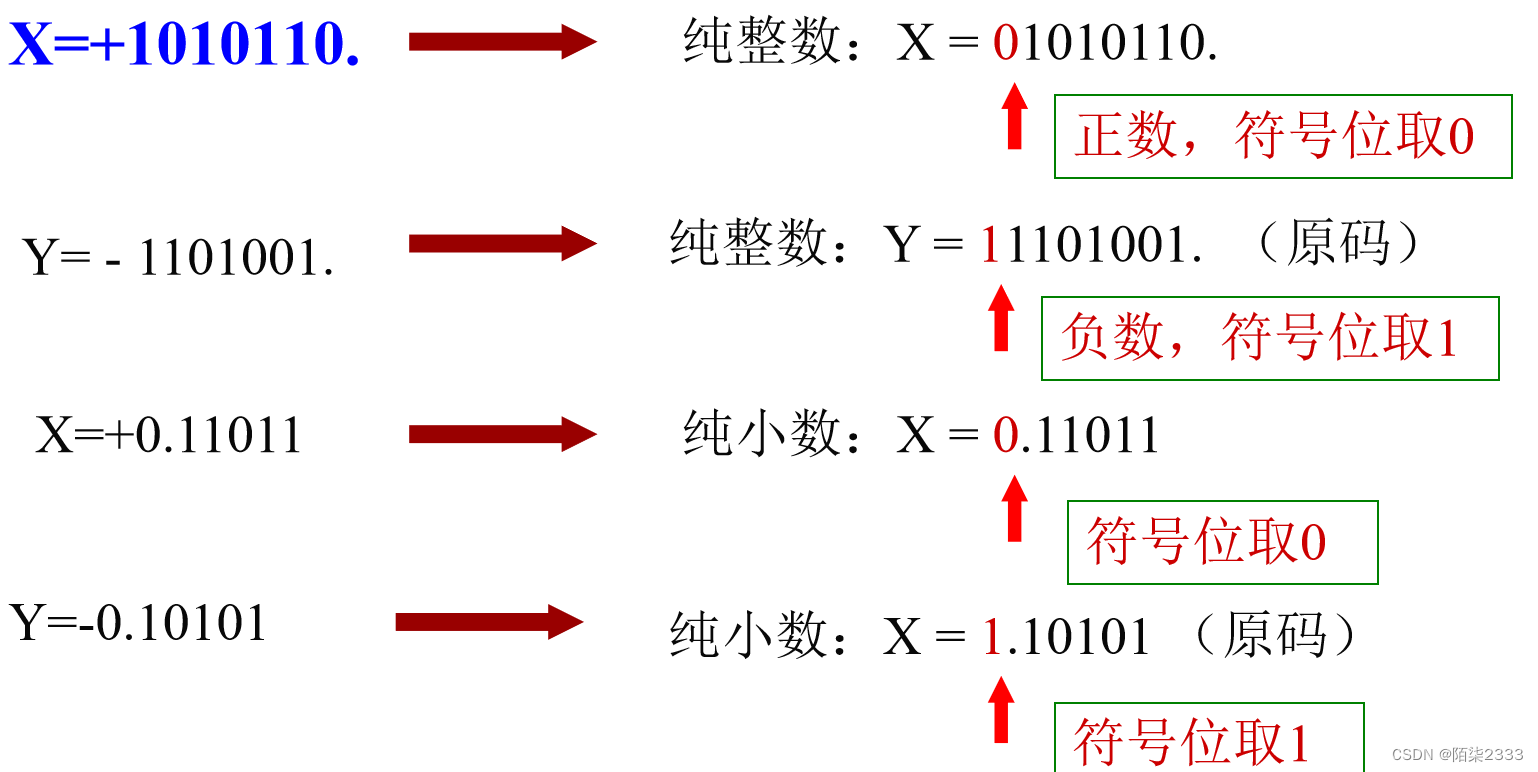
特点:小数点(radix point)的位置固定通常有纯小数和纯整数两种。
对于任意定点数x=x0x1……xn
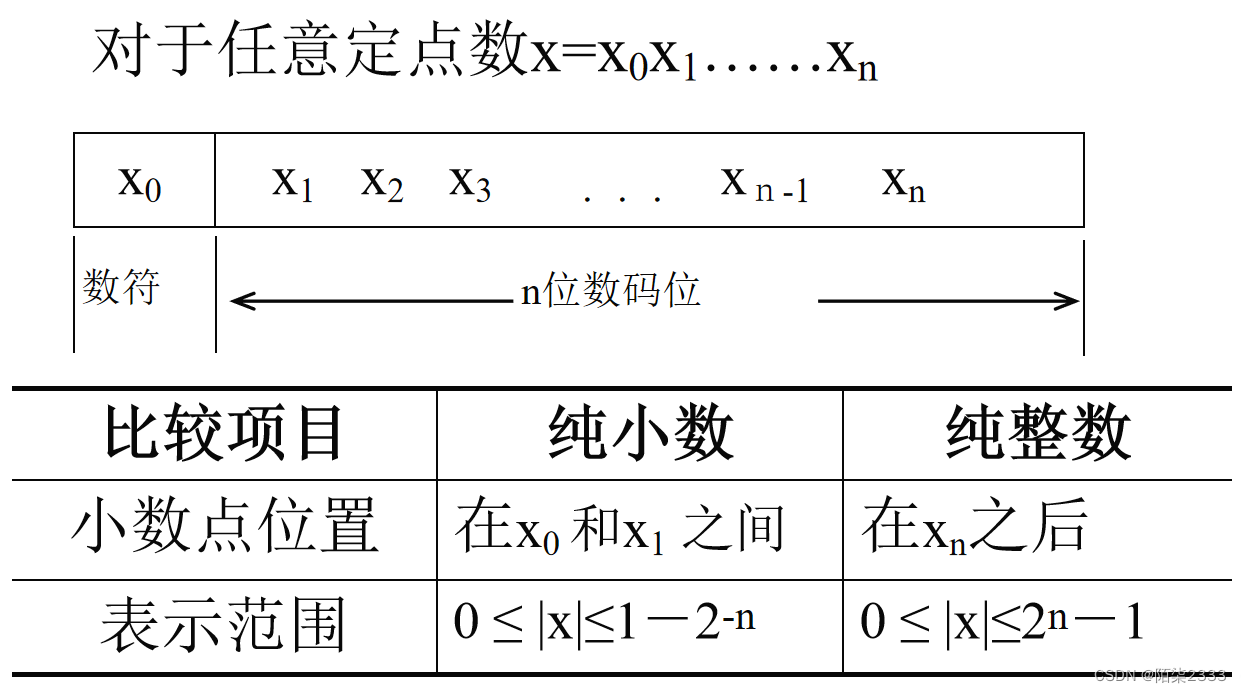
定点纯小数:
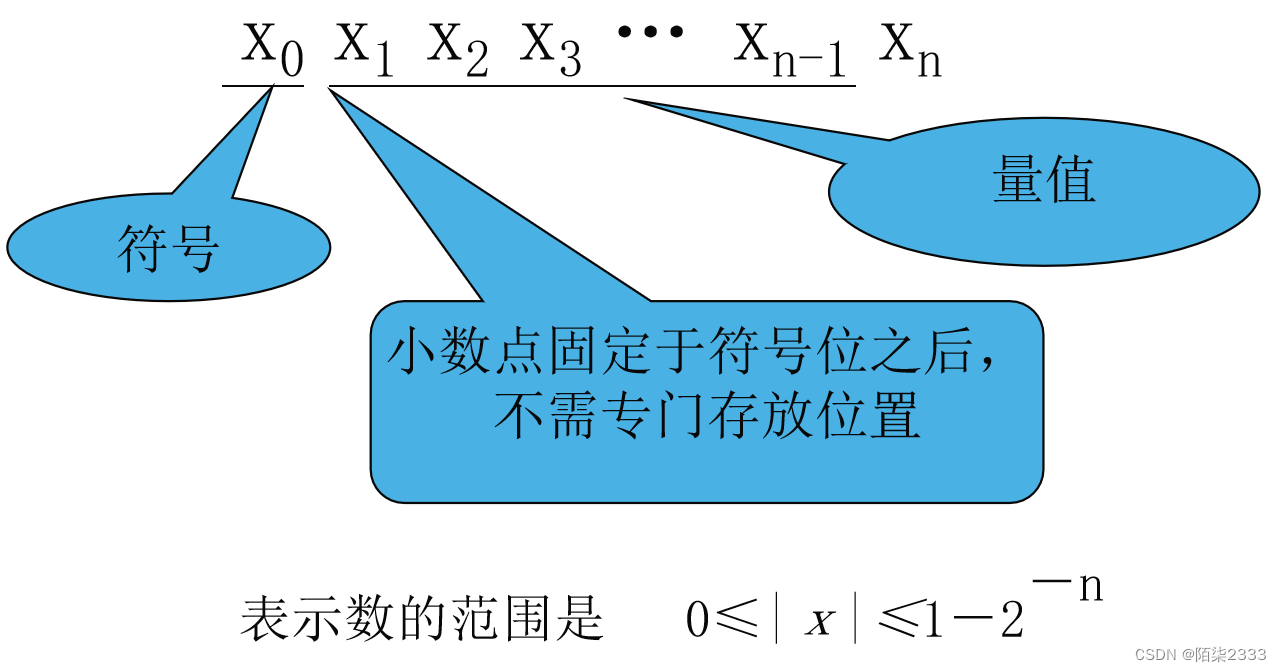
定点纯小数的表示范围

定时纯整数:
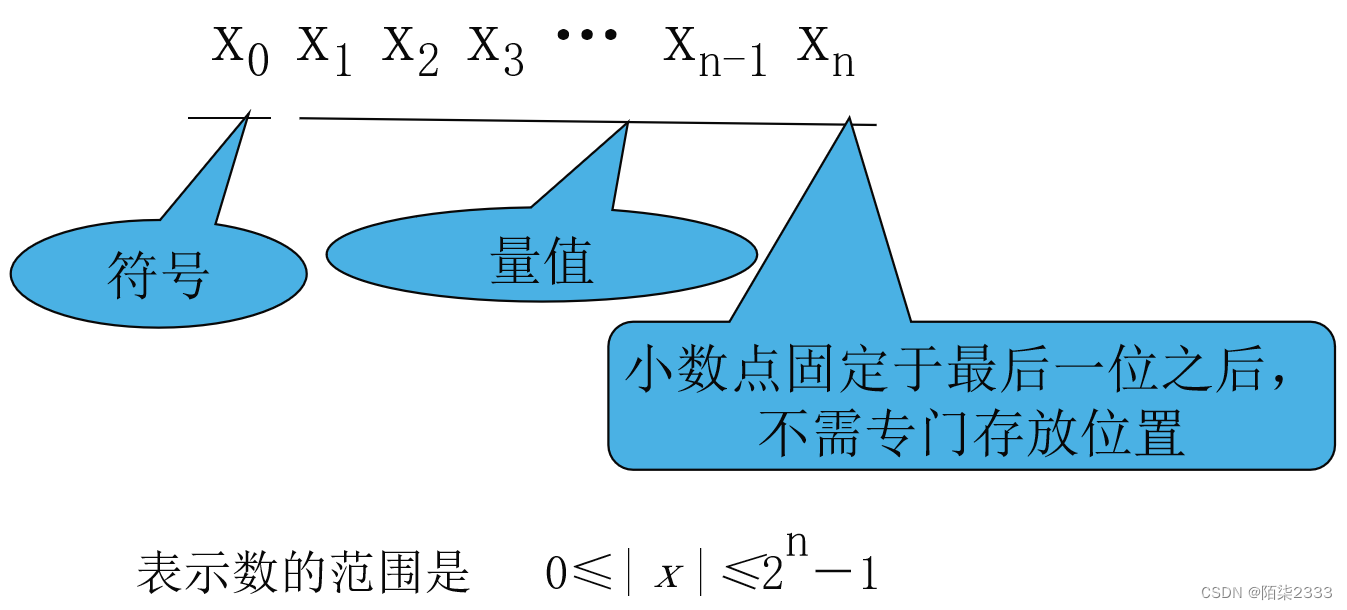
3.浮点数的表示方法
特点:小数点位置不固定(浮动)。
实质:把一个数的有效数字和范围在一个存储单元中分别予以表示。
653.12=10 3 × 0.65312 对于任意进制数 N可表示:N=Re•M(科学计数法)
其中M是浮点数的尾数(纯小数、有效数字位数,精度), e称为指数,为阶码(纯整数,小数点位置,范围) ,比例因子R为基数。在计算机中常为2、8、16。
一个机器浮点数应当由阶码、尾数和符号位组成(基数固定)
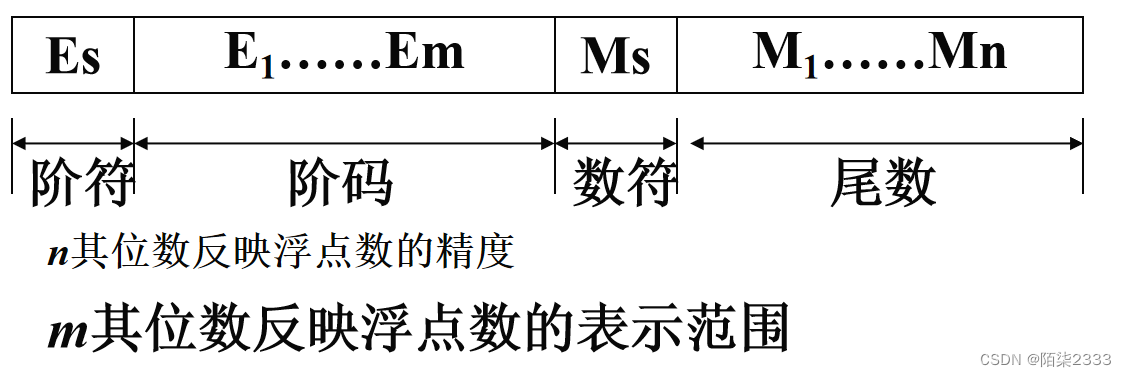
上溢 阶码 > 最大阶玛
下溢 阶码 < 最小阶码 按 机器零 处理

浮点数规格化表示(尾数):
绝对值为>=0.5(0除外)。形式为:0.1…,最高位1视为隐藏在小数点左侧,提高数据表示精度。
指数表示:采用移码方式(加上一个固定的偏移值)。
一个规格化的32位浮点数x的真值为: X=(-1)s × (1.M) × 2 E-127 e=E - 127
机器零:当一个浮点的尾数为0,不论阶码为何值;或当阶码的值比阶码的最小值还小,不论尾数为何值,视为机器零
规格化表示原则
尾数最高有效位为1,隐藏,并且隐藏在小数点的左边(即:1≤M<2)
32位单精度浮点数规格化表示 x= (-1)s×(1.M)× 2E-127 e=E-127(E=e+127)
64位双精度浮点数规格化表示 x= (-1)s ×(1.M)× 2E-1023 e=E-1023(E=e+1023)
指数真值e 用偏移码形式表示为阶码E
32位单精度规格化浮点数:
E=1(0000 0001)~254(1111 1110)
e=-126~+127
表达的数据范围(绝对值):
最小值: e=-126,M=0(1.M=1) ,最大值: e=127,M=11…1(23个1)
64位双精度规格化浮点数:
E=1~2046 e=-1022~+1023
表达的数据范围(绝对值) :
最小值: e=-1022,M=0(1.M=1) ,最大值: e=1023,M=11…1(52个1)
例题:若浮点数x的二进制存储格式为(43AC0000)16,求其32位浮点数的十进制值。

例题:将数(20.59375)10转换成754标准的32位浮点数的二进制存储格式。
解:首先分别将整数和分数部分转换成二进制数:
20.59375=10100.10011
然后移动小数点,使其在第1,2位之间
10100.10011=1.010010011×2^4 e=4
于是得到: S=0, E=4+127=131, M=010010011
最后得到32位浮点数的二进制存储格式为:
01000001101001001100000000000000=(41A4C000)16
4. 十进制数串的表示方法
(1)字符串的形式:一个字节存放一个十进制的数位或符号位。为了指明这样一个数,需要给出该数在主存中的起始地址和位数(串的长度)。主要用于非数值计算。
(2)压缩的十进制数串形式:一个字节存放两个十进制的数位。既节省存储空间,又便于直接完成算术运算,是广泛采用的较为理想的方法。
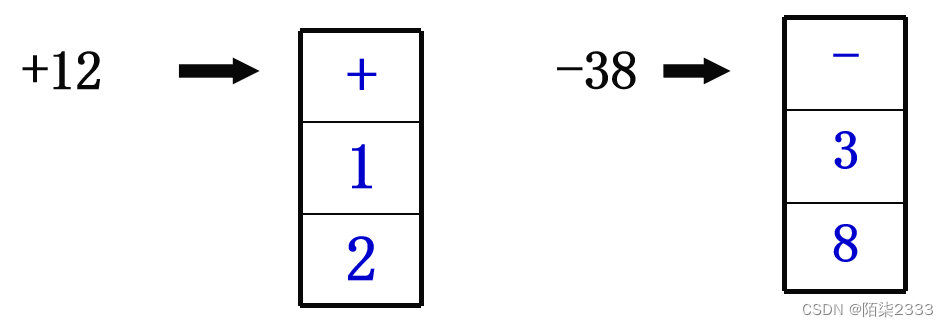
1.字符串形式 每个十进制的数位或符号位都用一个字节存放
2.压缩的十进制数串形式 一个字节存放两个十进制的数位,符号位占半个字节(例如用C表示正,D表示负)
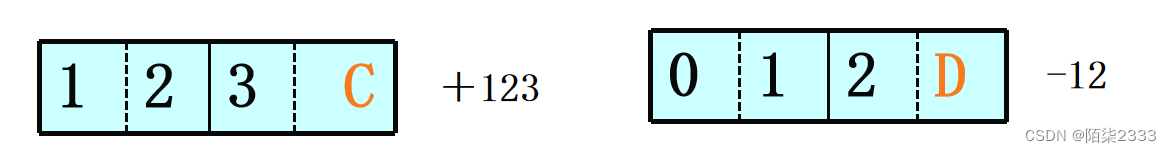
二进制编码的十进制数:
一个十进制数位用4位二进制编码来表示
常用8421 BCD码:低10个4位二进制编码表示0~9
压缩BCD码:一个字节表达两位BCD码
非压缩BCD码:一个字节表达一位BCD码(低4位表达数值,高4位常设置为0)
BCD码很直观
BCD码:0100 1001 0111 1000.0001 0100 1001 十进制真值: 4978.149
5.数的机器码表示
真值:一般书写的数
机器码:机器中表示的数, 要解决在计算机内部数的正、负符号和小数点运算问题。
原码

(3) 浮点数原码定义
阶码部分按照定点整数的方法进行编码
尾数部分按照定点小数的方法进行编码
(4) 原码表示的特点
与真值转换关系:符号位:正数->“0”,负数->“1”
[+0]原=00 000 000,[-0]原=10 000 000
优点:简单直观
缺点:用原码进行加减运算不方便
补码
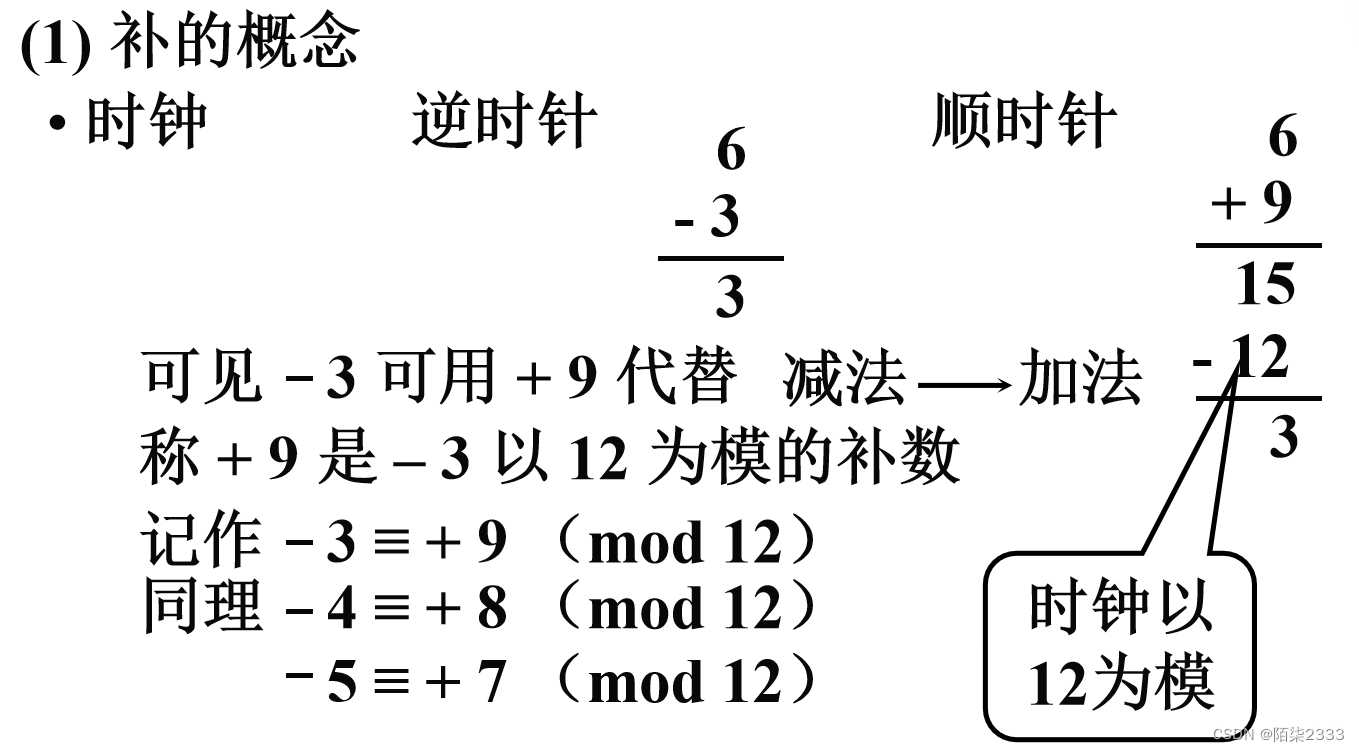
一个负数加上 “模” 即得该负数的补数
两个互为补数的数 它们绝对值之和即为模数
(2)模的概念
计算机中运算器、寄存器、计数器都有一定的位数,不可能容纳无限大的任意数。当运算结果超出实际的最大表示范围,就会发生溢出,此时所产生的溢出量就是模(module)。
因此,可以把模定义为一个计量器的容量。如:一个4位的计数器,它的计数值为0--15。当计数器计满15之后再加1,这个计数器就发生溢出,其溢出量为16,也就是模等于16。
定点小数的溢出量为2(将符号位也当作数来对待),即以2为模;
一个字长为n+1位的定点整数的溢出量为2n+1,即以2n+1为模。

(3)定点小数

(4)定点整数

补码的表示范围

(5)特点:
补码最高一位为符号位,0正1负;
补码零有唯一编码;
补码能很好用于加减运算。
补码满足 [-x]补+ [x]补=0,最高位参与演算,与其它位一样对待。
(6)浮点数补码定义
阶码部分按照定点整数的方法进行编码
尾数部分按照定点小数的方法进行编码
(7)补码表示的特点
①与真值转换:符号位:正数--“0”,负数--“1”其它数据位:正数--不变,负数--模减绝对值(按位取反后在末尾上加1)
②0的补码唯一: [+0]补=00 000 000,[-0]补=00 000 000
反码

(3)浮点数反码定义
阶码部分按照定点整数的方法进行编码
尾数部分按照定点小数的方法进行编码

移码


特点:移码和补码尾数相同,符号位相反
范围:-2n~2n-1
00000000阶码表示数字”0”,尾数的隐含位为0
11111111阶码表示数字”无穷大” ,尾数的隐含位为0
小结:
移码表示法主要用于表示浮点数的阶码。
由于补码表示对加减法运算十分方便,因此目前机器中广泛采用补码表示法。在这类机器中,数用补码表示、存储、运算。
也有些机器,数用原码进行存储和传送,运算时改用补码。
还有些机器在做加减法时用补码运算,在做乘除法时用原码运算。
三种编码的比较:
相同点:
1、 三种编码(原码、反码、补码)的最高位都是符号位。
2、 当真值为正时,三种编码的符号位都用0表示,数值部分与真值相同。 即它们的表示方法是相同的。
3、 当真值为负时,三种编码的符号位都用1表示,但数值部分的表示各不相同,数值部分存在这样的关系:补码是原码的“求反加1”(整数),或者“求反末位加1”(小数);反码是原码的“每位求反”。
4、 它们所能表示的数据范围基本一样,-2n<X<2n(整数)或 -1<X<1( 小数),补码多表示一个数-2n(整数)或-1(小数)。
5、移码是在补码的最高位加1,因此移码的求得只须改变补码的符号位即可,故移码又称为增码。
区别:在于对负数的表示方法有所不同。
6.练习题



机械零:
当浮点数 尾数为 0 时,不论其阶码为何值按机器零处理
当浮点数 阶码等于或小于它所表示的最小数 时,不论尾数为何值,按机器零处理

有利于机器中“ 判 0 ” 电路的实现
2.字符和字符串的编码
普遍采用的字符系统:七单位的ASCII码(美国国家信息交换标准字符码— American Standard Code for Interchange Information)。
其包括95个打印字符:10个十进制数,26个英文字母(大小写),通用的运算符和标点符号等。33个控制码:用于控制某些外围设备的工作特性和计算机软件的运行情况。
字符串:连续的一串字符,通常他们占用主存中连续的多个字节,每个字节存一个字符。
ASCII码
标准ASCII码用7位二进制编码,有128个
不可显示的控制字符:前32个和最后一个编码
回车CR:0DH 换行LF:0AH 响铃BEL:07H
可显示和打印的字符:20H后的94个编码
数码0~9:30H~39H
大写字母A~Z:41H~5AH
小写字母a~z:61H~7AH
空格:20H
扩展ASCII码:最高D7位为1,表达制表符号
字符串
字符串是指连续的一串字符,通常占用主存中连续的多个字节,每个字节存一个字符
多字节数据通常也连续存放在主存,占用多个连续的字节存储单元
小端方式(Little Endian)
低字节数据存放在低地址存储单元
高字节数据存放在高地址存储单元
大端方式(Big Endian)
低字节数据存放在高地址存储单元
高字节数据存放在低地址存储单元
3.汉字的编码方式

数字编码 :国标区位码,用数字串代表一个汉字输入
拼音码: 以汉字拼音为基础的输入方法
字形编码 :用汉字的形状(笔划)来进行的编码 ,例如五笔字形
汉字交换码:
汉字交换码是不同的汉字处理系统之间交换信息用的编码汉字也是一种字符1981年我国制定了《信息交换用汉字编码字符集基本GB2312-80》国家标准(简称国标码)。每个汉字的二进制编码用两个字节表示。共收录一级汉3755个,二级汉字3008个,各种符号682个,共计7445个
汉字内码:
汉字内码是用于汉字信息的存储、检索等操作的机内代码,一般采用两个字节表示
汉字内码有多种方案,常以国标码为基础的编码
例如,将国标码两字节的最高位置1后形成
汉字“啊”的国标码 : 3021H (0011 0000 0010 0001)
对应的汉字内码 B0A1H (1011 0000 1010 0001)
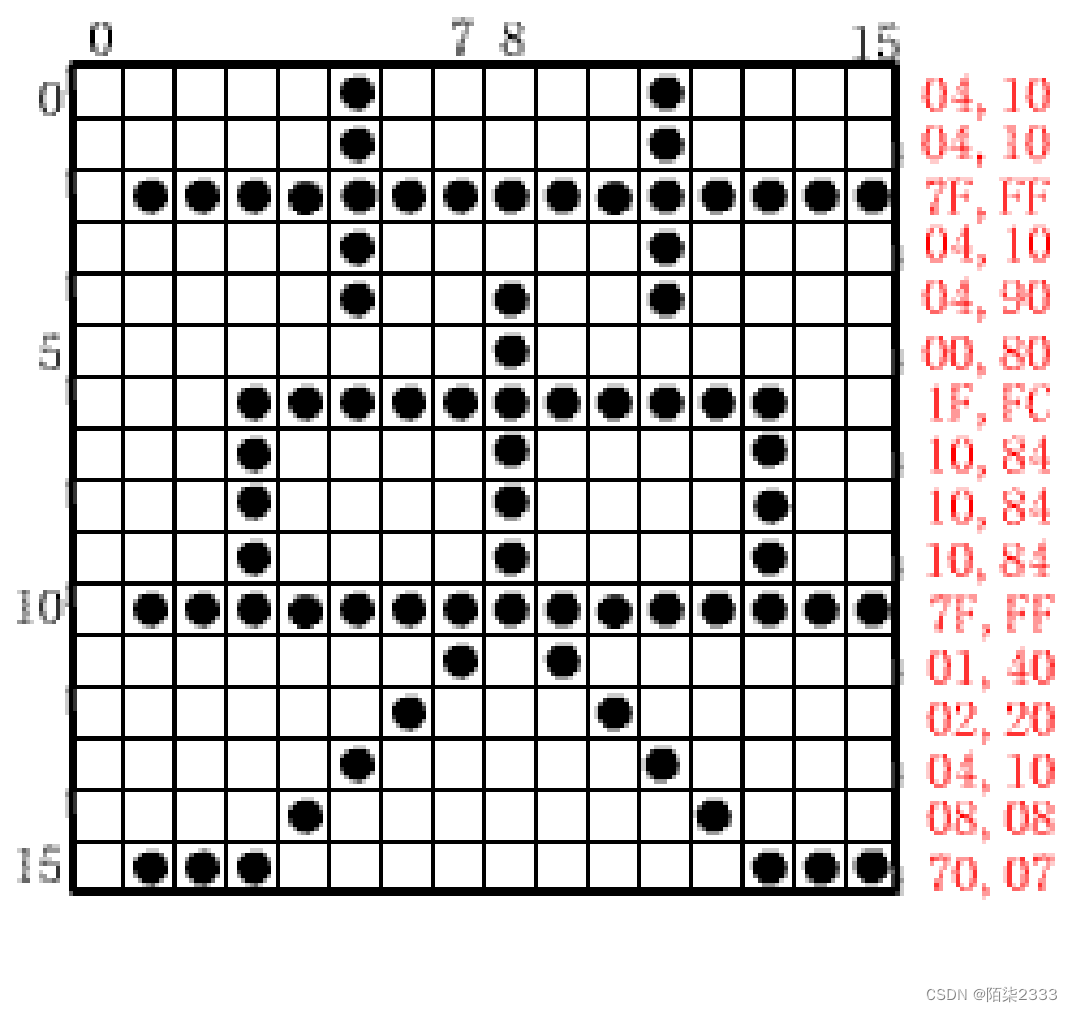
汉字字模点阵及编码
4.校验码

校验码:能够发现甚至纠正信息传输或存储过程中出现错误的编码
检错码:仅能检测出错误的编码
纠错码:能够发现并纠正错误的编码
最简单且应用广泛的检错码:奇偶校验码
奇校验:使包括校验位在内的数据中为“1”的个数恒为奇数
偶校验:使包括校验位在内的数据中为“1”的个数恒为偶数(包括0)
只能检测出奇数个位出错的情况,不能纠错