给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]] 输出:[1,1,2,3,4,4,5,6] 解释:链表数组如下: [1->4->5,1->3->4,2->6] 将它们合并到一个有序链表中得到。 1->1->2->3->4->4->5->6
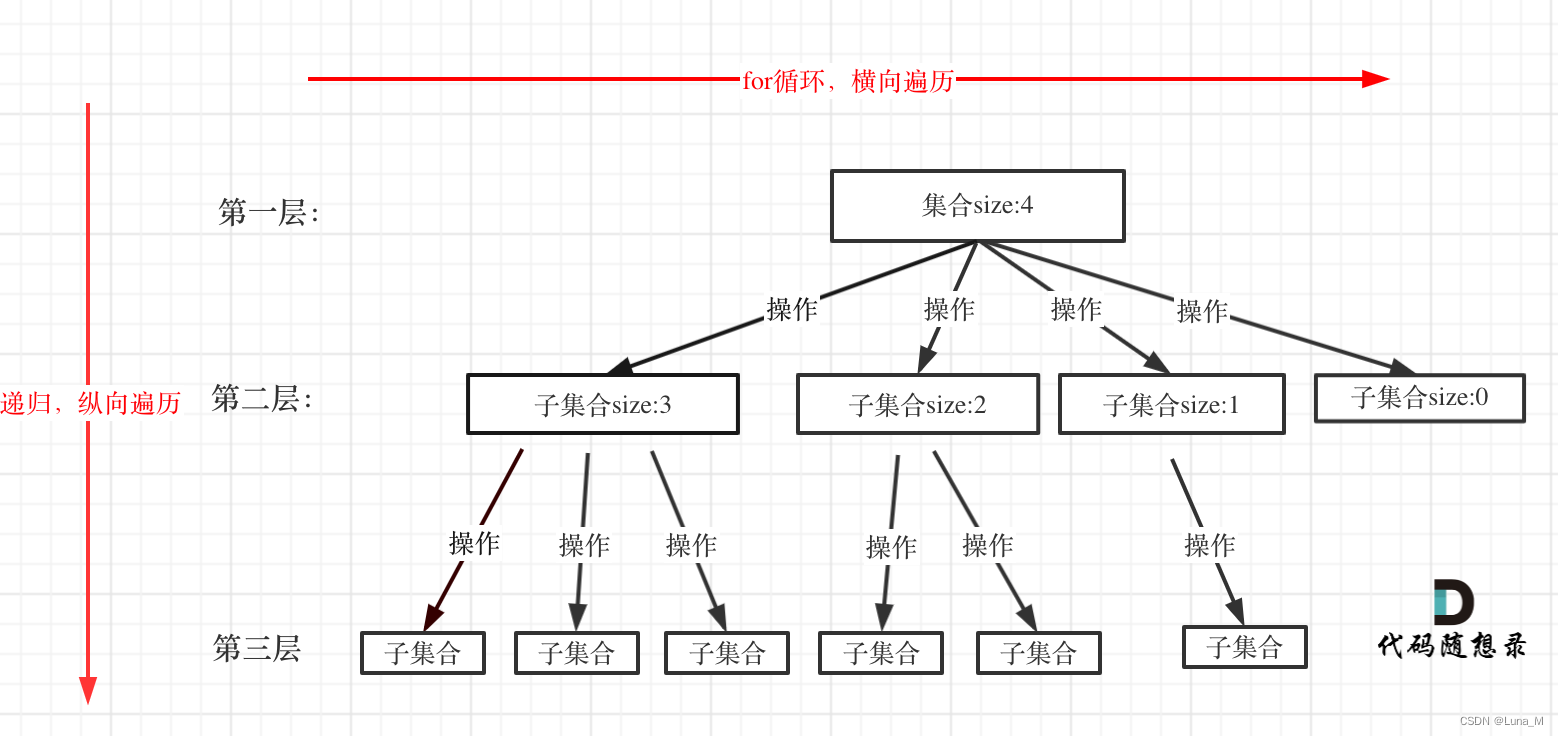
老样子,先贴我的图,可以说是又快又好,不过这里原题给的是子链表有序(常规写法也能写,不难),如果子链表无序,那各位读者应该是焦头烂额+汗流浃背了
这个题,其实看完我上一篇分享可以立马写出来了,链表排序?看完你也能手撕
思路还是一样,先转换成数组存放,再排序,再存回链表中(思路很简单)
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
vector<int> s; // 存储所有链表节点的值的容器
// 遍历所有链表,将节点的值依次放入容器中
for (int i = 0; i < lists.size(); i++) {
ListNode* cur = lists[i]; // 当前链表的头节点
while (cur != nullptr) {
s.push_back(cur->val); // 将节点值加入容器
cur = cur->next; // 指针移动到下一个节点
}
}
sort(s.begin(),s.end()); // 将容器中的值进行排序(升序)
ListNode *tt = new ListNode(-1); // 创建一个哑节点 tt,用于构建结果链表
ListNode *res = tt; // 使用 res 保存结果链表的头节点
int i = 0; // 用于遍历排序后的容器 s
// 遍历列表
for (int j = 0; j < lists.size(); j++) {
ListNode* cur1 = lists[j]; // 当前链表的头节点
while(cur1 != nullptr) {
cur1->val = s[i++]; // 将排序后的值赋给当前节点
tt->next = cur1; // 连接当前节点到结果链表
tt = cur1; // tt 指针移动到当前节点
cur1 = cur1->next; // cur1 指针移动到下一个节点
}
}
return res->next; // 返回结果链表的头节点
}
};
以下是LeetCode官方的各种题解,为大家添加上了注释
方法一:顺序合并
我们可以想到一种最朴素的方法:用一个变量 ans 来维护以及合并的链表,第 i次循环把第 i 个链表和 ans 合并,答案保存到 ans 中。
class Solution {
public:
// 合并两个有序链表
ListNode* mergeTwoLists(ListNode* a, ListNode* b) {
// 如果其中一个链表为空,则直接返回另一个链表
if ((!a) || (!b)) return a ? a : b;
ListNode head, *tail = &head, *aPtr = a, *bPtr = b;
while (aPtr && bPtr) {
if (aPtr->val < bPtr->val) {
// 当a链表的值小于b链表的值时,将a链表的节点拼接到结果链表后面,并更新a链表的指针
tail->next = aPtr; aPtr = aPtr->next;
} else {
// 当a链表的值大于等于b链表的值时,将b链表的节点拼接到结果链表后面,并更新b链表的指针
tail->next = bPtr; bPtr = bPtr->next;
}
// 更新结果链表的尾指针
tail = tail->next;
}
// 将剩下的未合并的链表直接拼接到结果链表的尾部
tail->next = (aPtr ? aPtr : bPtr);
// 返回结果链表
return head.next;
}
// 合并K个有序链表
ListNode* mergeKLists(vector<ListNode*>& lists) {
ListNode *ans = nullptr;
for (size_t i = 0; i < lists.size(); ++i) {
// 逐个合并链表,将结果保存到ans中
ans = mergeTwoLists(ans, lists[i]);
}
// 返回最终的合并结果
return ans;
}
};
方法二:分治合并
考虑优化方法一,用分治的方法进行合并。
class Solution {
public:
// 合并两个有序链表
ListNode* mergeTwoLists(ListNode *a, ListNode *b) {
if ((!a) || (!b)) return a ? a : b; // 如果其中一个链表为空,则直接返回另一个链表
ListNode head, *tail = &head, *aPtr = a, *bPtr = b;
while (aPtr && bPtr) {
if (aPtr->val < bPtr->val) { // 比较两个节点的值,将较小的节点接入结果链表
tail->next = aPtr;
aPtr = aPtr->next; // 更新a链表指针
} else {
tail->next = bPtr;
bPtr = bPtr->next; // 更新b链表指针
}
tail = tail->next; // 更新结果链表的尾节点
}
tail->next = (aPtr ? aPtr : bPtr); // 将剩余未合并完成的节点接入结果链表
return head.next; // 返回结果链表的头节点
}
// 递归合并多个有序链表
ListNode* merge(vector <ListNode*> &lists, int l, int r) {
if (l == r) return lists[l]; // 当l和r相等时,表示只有一个链表,直接返回该链表
if (l > r) return nullptr; // 当l大于r时,表示没有待合并的链表,返回空指针
int mid = (l + r) >> 1; // 计算中间位置
return mergeTwoLists(merge(lists, l, mid), merge(lists, mid + 1, r)); // 递归合并左右两个部分
}
ListNode* mergeKLists(vector<ListNode*>& lists) {
return merge(lists, 0, lists.size() - 1); // 调用递归函数,合并整个链表数组
}
};
方法三:使用优先队列合并
这个方法和前两种方法的思路有所不同,我们需要维护当前每个链表没有被合并的元素的最前面一个,k 个链表就最多有 k 个满足这样条件的元素,每次在这些元素里面选取 val 属性最小的元素合并到答案中。在选取最小元素的时候,我们可以用优先队列来优化这个过程。
class Solution {
public:
// 定义结构体Status,用于在优先队列中存储节点信息
struct Status {
int val; // 节点的值
ListNode *ptr; // 节点指针
bool operator < (const Status &rhs) const {
return val > rhs.val; // 优先队列按照节点值的大小进行排序
}
};
priority_queue<Status> q; // 创建优先队列q,按照节点值的大小进行排序
ListNode* mergeKLists(vector<ListNode*>& lists) {
// 将每个链表的第一个节点放入优先队列
for (auto node : lists) {
if (node)
q.push({node->val, node});
}
ListNode head, *tail = &head; // 创建结果链表的头节点head和尾节点tail
while (!q.empty()) {
auto f = q.top();
q.pop();
tail->next = f.ptr; // 将当前队列中最小的节点连接到结果链表的尾部
tail = tail->next; // 更新尾节点为当前节点
if (f.ptr->next)
q.push({f.ptr->next->val, f.ptr->next}); // 如果当前节点还有下一个节点,则将下一个节点放入优先队列继续排序
}
return head.next; // 返回结果链表的头节点
}
};