简介
本文提出了一种新的基于条件神经辐射场(Condition NeRF)的talking portrait合成框架ER-NeRF,能够在较小的参数量下实现高精度的实时渲染和快速收敛。该方法利用空间区域的不平等贡献来指导谈话肖像建模,以提高动态头部重建的准确性。
具体而言,为了解决动态头部重建的问题,本文引入了一种紧凑且富有表现力的基于NeRF的三平面哈希表示,通过三个2D哈希编码器修剪空间区域,实现了对空间区域的精细划分。在处理语音音频时,本文提出了一个区域注意模块,利用区域注意力机制生成区域感知条件特征。与现有的方法不同的是,该方法使用了显式连接的注意力机制,将音频特征与空间区域建立了直接联系,以捕捉局部运动的先验知识。
此外,针对身体部分的建模问题,本文提出了一种直观且快速的适应性姿态编码,将头部姿态的复杂变换映射到空间坐标中,从而优化了头部-躯干分离问题。
大量实验证明,在talking portrait合成任务中,该方法相比现有方法具有更高的保真度和唇形同步程度,同时表现出逼真的细节和更高的效率。这一方法为高质量的talking portrait合成提供了一种新的有效途径。
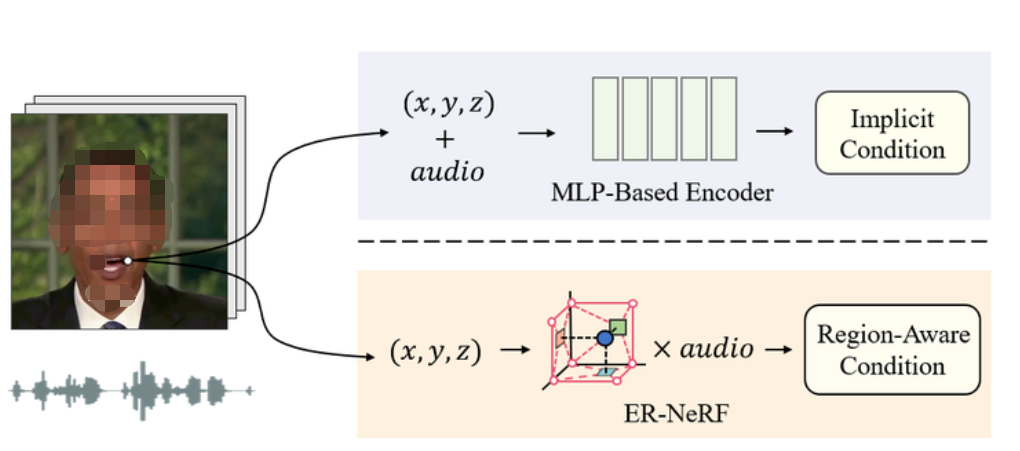
图1:与以往的方法不同,我们没有通过基于MLP的编码器来学习隐含的音频-视觉关系,而是明确地关注语音音频和空间区域之间的跨模态交互。区域感知使ER NeRF能够呈现更准确的面部运动。
论文单位:北京航空航天大学,格里菲斯大学,RIKEN AIP,东京大学
论文地址:https://arxiv.org/abs/2307.09323
代码代码:https://github.com/Fictionarry/ER-NeRF
引言
音频驱动的说话肖像合成是一个重要且具有挑战性的问题,有着多种潜在应用场景,例如数字人物、虚拟化身、电影制作和视频会议。近年来,许多研究人员已经使用深度生成模型来处理这一任务。其中,神经辐射场(NeRF)被引入到音频驱动的说话肖像合成中,提供了一种通过深度多层感知器(MLP)学习从音频特征到相应视觉外观的直接映射的新方法。一些研究通过端到端方式或通过中间表示对音频信号进行NeRF条件处理,以重建特定的说话肖像。尽管这些基于NeRF的方法在合成质量上取得了巨大成功,但其推理速度远远不能满足实时性要求,这限制了它们的实际应用。
近期的一些关于高效神经表示的工作通过用稀疏特征网格替换MLP网络的一部分,实现了对NeRF的显著加速。Instant-NGP引入了哈希编码体素网格用于静态场景建模,并使用紧凑的模型实现了快速和高质量的渲染。RAD NeRF首先将这项技术应用于说话肖像合成,并构建了一个具有最先进性能的实时渲染框架。然而,RAD-NeRF需要一个复杂的带有MLP的网格编码器来隐式学习区域性的音频-动作映射,这限制了其收敛速度和重建质量。
本文旨在探索一种更有效的解决方案,以实现高效、高保真的说话肖像合成。基于之前的研究,我们注意到不同的空间区域对于说话肖像的外观的贡献并不相等:(1)在体渲染中,由于只有表面区域有助于表示动态头部,因此大多数其他空间区域是无用的,且头部的表面结构较为简单,可以进一步探索如何使用一些高效NeRF技术进行修剪,以降低训练难度;(2)由于不同的面部区域与语音音频具有不同的关联,因此不同的空间区域以其独特的方式与音频信号固有地相关,并表现出独特的音频驱动的局部运动。
受到这些观察结果的启发,我们明确利用空间区域的不平等贡献来指导说话肖像建模,并提出了一种新颖的高效区域感知说话肖像NeRF(ER-NeRF)框架,用于逼真高效的说话肖像合成。该框架在具有较小模型尺寸的情况下实现了高质量的渲染、快速收敛和实时推理。
本文的贡献主要在于:(1)我们引入了一种高效的三平面哈希表示来促进动态头部重建,以紧凑的模型大小实现了高质量的渲染、实时推理和快速收敛;(2)我们提出了一种新颖的区域注意模块来捕捉音频条件和空间区域之间的相关性,以进行精确的面部运动建模。
算法架构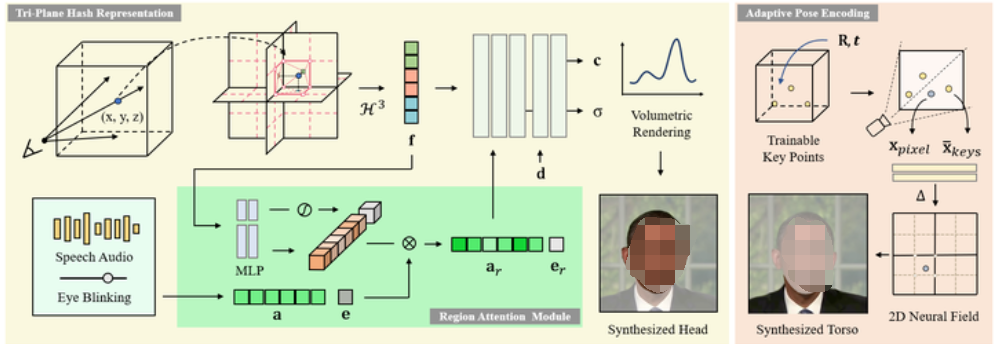
图2: ER-NeRF框架概述。Talking portrait 的头部由三平面哈希表示建模。三平面散列编码器 H 3 H^3 H3用于将3D坐标 x x x编码为其空间几何特征 f f f。语音音频 a a a和眨眼 e e e的输入条件特征通过区域注意力模块在通道级别重新加权, 并转换为区域感知条件特征 a r a_r ar和 e r e_r er。然后, 将与空间几何特征 f f f和视角方向 d d d相结合的区域感知特征输入到MLP解码器中, 以预测头部的颜色 c c c以及密度 σ \sigma σ。躯干部分由另一个具有自适应姿势编码的躯干NeRF渲染。应用相应的头部姿态 P = ( R , t ) P=(R,t) P=(R,t)来变换可训练的关键点, 以获得它们的归一化2D坐标 并作为条件输入指定的2D神经场, 以预测躯干图像。
哈希三平面
我们的第一个改进针对动态头部表示进行了优化。尽管RAD NeRF使用Instant-NGP来表示说话肖像并实现了快速推理,但在对音频驱动的3D动态头部建模时,其渲染质量和收敛性受到哈希冲突的限制。为了解决这个问题,我们引入了一种三平面哈希表示,通过基于NeRF的三平面分解将3D空间分解为三个正交平面。在因子分解过程中,所有空间区域都被压缩到2D平面上,并修剪相应的特征网格。因此,散列冲突仅发生在低维子空间中且数量更少。在噪声较少的情况下,网络可以更加关注音频特征的处理,从而能够重建更准确的头部结构和更精细的动态运动。

图3. 可视化的占用网格。(a)没有音频条件的纯静态3D哈希网格。(b,c)3D哈希网格和我们的以音频为条件的三平面哈希表示。在被要求处理音频特征并同时学习动态运动后,3D哈希网格的MLP解码器表现出过载,而我们的表示仍然可以重建精细的表面。
对于给定的坐标
x
=
(
x
,
y
,
z
)
∈
R
X
Y
Z
x=(x,y,z)\in\mathbb{R}^{\mathbf{XYZ}}
x=(x,y,z)∈RXYZ我们通过三个2D多分辨率哈希编码器分别对其投影坐标进行编码:
H
A
B
:
(
a
,
b
)
→
f
a
b
A
B
\mathcal{H}^{\mathrm{AB}}:\left(a,b\right)\rightarrow f_{a b}^{\mathrm{AB}}
HAB:(a,b)→fabAB
其中输出
f
a
b
A
B
∈
R
L
F
\mathbf{f}_{a b}^{\mathbf{AB}}\in\mathbb{R}^{\mathrm{{LF}}}
fabAB∈RLF是投影坐标$
(
a
,
b
)
(a,b)
(a,b)的平面级几何特征,(a,b)和
H
A
B
\mathcal{H}^{AB}
HAB是平面
R
A
B
\mathbb{R}^{AB}
RAB的多分辨率哈希编码器, 层数为
L
L
L, 特征 每个条目的尺寸
F
F
F。
然后我们将结果进行concat得到最终的几何特征
f
g
∈
R
3
×
L
F
:
{\bf f}_{g}\in\mathbb{R}^{3\times L F}:
fg∈R3×LF:
f x = H X Y ( x , y ) ⊕ H Y Z ( y , z ) ⊕ H X Z ( x , z ) \mathrm{f_{x}}=\cal{H}^{\mathrm{XY}}(x,y)\oplus\mathit{}\cal{H}^{\mathrm{YZ}}(y,z)\oplus\mathit{}\cal{H}^{\mathrm{XZ}}(x,z) fx=HXY(x,y)⊕HYZ(y,z)⊕HXZ(x,z)
符号 ⊕ \oplus ⊕表示连接运算符, 它将特征连接到 3 × L F 3\times LF 3×LF通道向量中。
区域注意力模块
音频等动态条件几乎不会均匀地对整个portrait产生影响。因此,了解这些条件如何影响肖像的不同区域对于生成自然的面部运动至关重要。许多以往的工作在特征层面忽略了这一点,并使用一些昂贵的方法来隐式地学习其中的相关性。通过利用存储在哈希编码器中的多分辨率区域信息,我们引入了一种轻量级区域注意机制来显式获取动态特征和不同空间区域之间的关系。
区域注意力机制。 区域注意力机制涉及计算注意力向量的外部注意力步骤和用于重新加权的跨模式通道注意力步骤。我们的目标是将动态条件特征与多分辨率几何特征 f x ∈ R N {\cal f}_{\bf x}\in\mathbb{R}^{\bf N} fx∈RN连接起来, 其中几何特征由哈希编码器 H \cal{H} H表示空间点 x x x得到。然而, 由于这种分层特征是通过concat构建的, 因此在编码期间不存在显式的信息流动。
为了有效地提高
f
x
f_x
fx中不同级别之间的区域信息交换, 并通过注意力向量的范数进一步区分音频对于每个区域的重要性, 我们使用了两层 MLP 捕获空间的全局背景。我们可以将其解释为external attention 的形式, 其中两个外部记忆单元
M
k
M_k
Mk和
M
v
M_v
Mv用于各个级别连接和自条件查询:
A
=
R
e
L
U
(
F
M
k
T
)
,
A=\mathrm{ReLU}(F M_{k}^{T}),
A=ReLU(FMkT),
V
o
u
t
=
A
M
v
.
V_{\mathrm{out}}\,=\,A M_{v}.
Vout=AMv.
其中向量
f
x
f_x
fx被视为矩阵
F
∈
R
N
×
1
F\in\mathbb{R}^{N\times1}
F∈RN×1。
随后,参考通道注意力机制,我们将得到的特征
V
o
u
t
∈
R
O
×
1
V_{\mathrm{out}}~\in~\mathbb{R}^{{\cal O}\times1}
Vout ∈ RO×1视为区域注意力向量
v
∈
R
O
\mathbf{v}\in\mathbb{R}^{O}
v∈RO, 并将其用于对动态条件特征
q
∈
R
O
\mathbf{q}\in\mathbb{R}^{O}
q∈RO的每个通道进行重新加权。最终输出特征向量为:
q
o
u
t
=
v
⊙
q
q_{out} = v \odot q
qout=v⊙q
其中
⊙
\odot
⊙表示 Hadamard 乘积。
至此, 区域感知特征
q
o
u
t
q_{out}
qout的每个通道均与
x
x
x所在的层级的区域相关, 因为区域注意力向量
v
v
v包含具有丰富多分辨率空间信息表示。因此, 多分辨率空间区域可以决定
q
q
q中的哪部分信息应该保留或增强。我们将其应用于声音和眨眼信息对NeRF的动态条件驱动。

图4. 区域注意力模块的可视化。即使受到一些不确定细节(如蓬松的头发)的影响,我们的区域注意模块也成功地捕获了动态条件和空间区域之间的关系,而无需显式的标注。
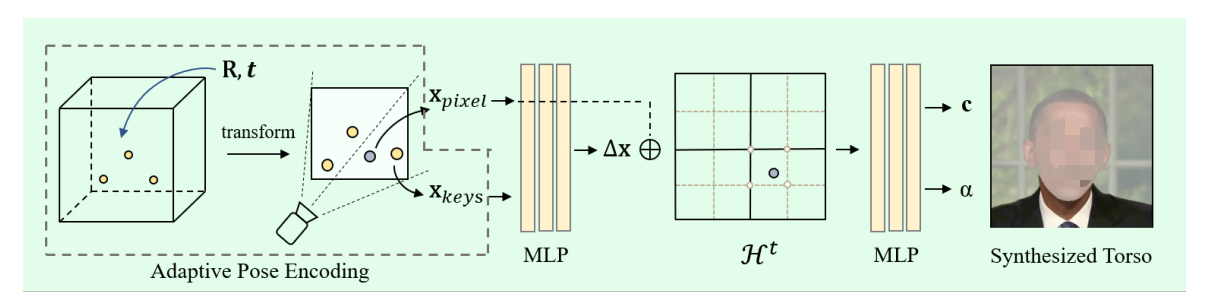
自适应姿势编码
为了解决头躯干分离问题,我们在之前的工作的基础上进行了改进(RAD-NeRF,GeneFace)。我们没有直接使用整个图像或姿势矩阵作为条件,而是将头部姿势的复杂变换映射到具有更清晰位置信息的几个关键点的坐标,并引导torso-NeRF从中学习隐式躯干姿势坐标。