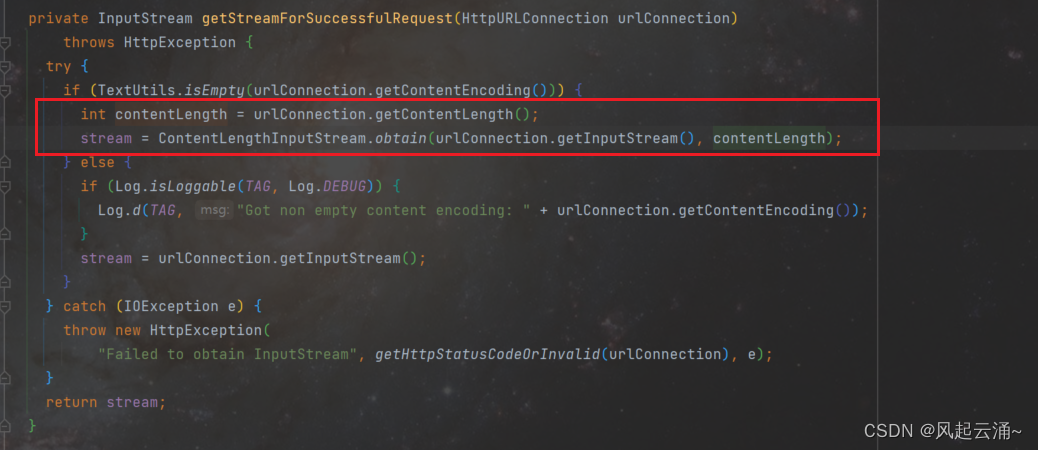
Apache Spark DataFrame API 提供了丰富的方法来处理分布式数据集。以下是一些常见的 DataFrame API 类别和方法,但这不是一个完整的列表,因为 API 非常广泛。这些方法可以分为几个主要类别:
转换操作(Transformations)
这些方法不会立即执行,但会返回一个新的 DataFrame,通常用于构建计算的执行计划。
select(): 选择一列或多列。filter(),where(): 根据给定的条件过滤行。groupBy(): 根据某一列或多列对数据进行分组。sort(),orderBy(): 根据一列或多列对数据进行排序。join(): 将两个 DataFrame 根据指定的条件连接起来。union(): 合并两个 DataFrame 的行。withColumn(): 添加一个新列或替换一个现有列。withColumnRenamed(): 重命名一个列。drop(): 删除一列或多列。distinct(): 返回一个只包含不同行的新 DataFrame。groupBy().agg(): 分组后的聚合操作。pivot(): 用于创建数据透视表。window(): 定义窗口函数。withWatermark(): 用于流数据处理中的事件时间。
动作操作(Actions)
这些方法会触发实际的计算过程,并返回结果到驱动程序或写入存储系统。
show(): 打印 DataFrame 的前几行。count(): 返回 DataFrame 中的行数。first(),head(): 返回 DataFrame 中的第一行。collect(): 收集 DataFrame 的所有数据到驱动程序中的一个数组。take(): 返回 DataFrame 的前 n 行。toPandas(): 将 DataFrame 转换为 Pandas DataFrame(仅适用于能够适应单个机器内存的数据集)。write(): 将 DataFrame 写入外部存储系统,如 HDFS、S3、数据库等。save(): 将 DataFrame 保存为文件。
输入和输出(I/O)
read(): 用于读取数据成为 DataFrame。write(): 用于将 DataFrame 写出到文件系统、数据库等。
缓存和持久化
cache(): 将 DataFrame 缓存到内存中。persist(): 将 DataFrame 以指定的存储级别缓存。unpersist(): 从缓存中移除 DataFrame。
其他操作
explain(): 打印出 DataFrame 的执行计划。printSchema(): 打印出 DataFrame 的 schema 信息。schema: 返回 DataFrame 的 schema。columns: 返回 DataFrame 的列名列表。dtypes: 返回列名和数据类型的列表。
UDFs(用户定义函数)
udf(): 定义一个新的用户定义函数。
Spark SQL
createOrReplaceTempView(): 创建一个临时视图,可以用 SQL 查询。sql(): 执行 SQL 查询。
这些方法只是 Spark DataFrame API 的一部分。Spark 的 API 经常更新和扩展,具体的方法和功能可能会随着版本的不同而有所变化。为了获得最新和最完整的 API 列表,你应该查看官方的 Spark 文档。
-------