点此获取backtrader技术教程
========
前一个帖子介绍了梯度提升gradient ascent的概念,本文介绍如何使用梯度提升最大化回报函数。
文末有github源码链接。
In my last post we learned what gradient ascent is, and how we can use it to maximize a reward function. This time, instead of using mean squared error as our reward function, we will use the Sharpe Ratio. We can use reinforcement learning to maximize the Sharpe ratio over a set of training data, and attempt to create a strategy with a high Sharpe ratio when tested on out-of-sample data.


def gradient(x, theta, delta):
Ft = positions(x, theta)
R = returns(Ft, x, delta)
T = len(x)
M = len(theta) - 2
A = np.mean(R)
B = np.mean(np.square(R))
S = A / np.sqrt(B - A ** 2)
dSdA = S * (1 + S ** 2) / A
dSdB = -S ** 3 / 2 / A ** 2
dAdR = 1. / T
dBdR = 2. / T * R
grad = np.zeros(M + 2) # initialize gradient
dFpdtheta = np.zeros(M + 2) # for storing previous dFdtheta
for t in range(M, T):
xt = np.concatenate([[1], x[t - M:t], [Ft[t-1]]])
dRdF = -delta * np.sign(Ft[t] - Ft[t-1])
dRdFp = x[t] + delta * np.sign(Ft[t] - Ft[t-1])
dFdtheta = (1 - Ft[t] ** 2) * (xt + theta[-1] * dFpdtheta)
dSdtheta = (dSdA * dAdR + dSdB * dBdR[t]) * (dRdF * dFdtheta + dRdFp * dFpdtheta)
grad = grad + dSdtheta
dFpdtheta = dFdtheta
return grad, S

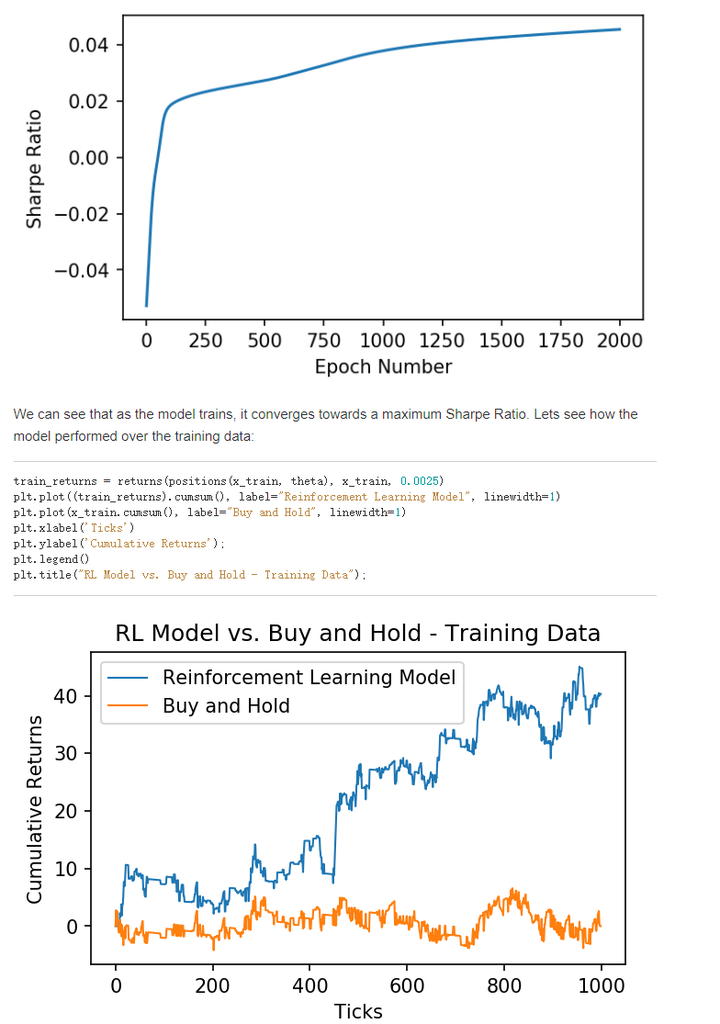
Once again the model outperforms the asset! This model may be able to be improved by engineering more features (inputs), but it is a great start. If you found this post useful, be sure to cite my paper,Cryptocurrency Trading Using Machine Learning。
As always, the notebook for this post is available on my Github.