因为 Redis AOF 的实现有些绕, 就分成 2 篇进行分析, 本篇主要是介绍一下 AOF 的一些特性和依赖的其他函数的逻辑,为下一篇 (Redis AOF 源码) 源码分析做一些铺垫。
AOF 全称: Append Only File, 是 Redis 提供了一种数据保存模式, Redis 默认不开启。
AOF 采用日志的形式来记录每个写操作, 并追加到文件。开启后, 执行更改 Redis 数据的命令时, 就会把命令写入到 AOF 文件中。
Redis 重启时会根据日志文件的内容把写指令从前到后执行一次以完成数据的恢复工作。
1 AOF 相关的配置
appendonly no # AOF 开关, 默认为关闭
appendfilename "appendonly.aof" # 保存的文件名
appendfsync everysec # AOF 持久化策略 (硬盘缓存写入到硬盘)
AOF 简单使用的话就这 3 个配置, 前 2 个就是字面的意思, 理解其他比较简单。
我们说明一下第三个配置的使用。
开启 AOF 后, 每次修改的命令都会存到 Redis 的一个缓存区。
缓存区的数据最终是需要写入到磁盘的, 而 Redis 是通过 write 函数, 将缓存中的数据写入到磁盘中。
但是 write 函数实际是先将数据先保存到系统层级的缓存, 后续由系统自身将数据保存到磁盘, 系统默认为 30 秒保存一次。这样的话, 可能有风险, 如果系统直接宕机了
可能会丢失 30 秒左右的数据, 所以系统提供了一个 fsync 函数, 可以把系统层级的缓存立即写入到磁盘中, 但是这是一个阻塞且缓慢的操作, 会影响到执行的线程。
所以上面的配置的第 3 项就是控制这个 Redis 缓存到磁盘的行为
- everysec: AOF 默认的持久化策略。每秒执行一次 fsync, 可能导致丢失 1s 数据, 这种策略兼顾了安全性和效率
- no: 表示不执行 fsync, 由操作系统保证数据同步到磁盘, 速度最快, 但是不太安全
- always: 表示每次写入到执行 fsync, 保证数据同步到磁盘, 效率很低
除了上面的 3 个基础配置, 还有几个关于 AOF 执行中的行为配置
# 默认为 100
# 当目前 AOF 文件大小超过上次重写的 AOF 文件的百分之多少进行重写 (重写的含义可以看下面的重写机制), 即当 AOF 文件增长到一定大小的时候, Redis 能够调用 bgrewriteaof 对日志文件进行重写
auto-aof-rewrite-percentag 100
# 默认为 64m
# 设置允许重写的最小 AOF 文件大小, 避免达到约定百分比但占用的容量仍然很小的情况就重写
auto-aof-rewrite-min-size 64mb
# 默认为 no
# 在 AOF 重写时, 是否不要执行 fsync, 将缓存写入到磁盘, 默认为 no。
# 如果对低延迟要求很高的应用, 这里可以设置为 yes, 否则设置为 no, 这样对持久化特性来说这是更安全的选择
# 设置为 yes 表示重写期间对新的写操作不 fsync, 暂时存在内存中, 等重新操作完成后再写入
# 默认为 no, 建议改为 yes, 因为 Linux 的默认 fsync 策略为 30 秒, 所以可能丢失 30 秒数据
no-appendfsync-on-rewrite no
# 默认为 yes
# 当 Redis 启动的时候, AOF 文件的数据会被重新载入内存
# 但是 AOF 文件可能在尾部是不完整的, 比如突然的断电宕机什么的, 可能导致 AOF 文件数据不完整
# 对于不完整的 AOF 文件如何处理
# 配置为 yes, 当截断的 AOF 文件被导入的时候, 会自动发布一个 log 给客户端, 然后继续加载文件中的数据
# 配置为 no, 用户必须手动 redis-check-aof 修复 AOF 文件才可以
aof-load-truncated yes
2 AOF 重写机制
上面的配置中有好几个提示到重写的概念, 那么什么是重写呢?
由于 AOF 持久化是 Redis 不断将写命令记录到 AOF 文件中, 随着 Redis 不断的运行, AOF 文件将会越来越大, 占用服务器磁盘越来越大, 同时 AOF 恢复要求时间越长。
为了解决这个问题, Redis 新增了重写机制, 当 AOF 文件的大小超过了所设定的阈值时, Redis 就会自动启动 AOF 文件的内容压缩, 只保留可以恢复数据的最小指令集。
AOF 文件不是对原文件进行整理, 而是直接读取服务器现有的键值对, 然后用一条命令去代替之前记录这个键值对的多条命令, 生成一个新的文件替换原来的 AOF 文件。
用户可以通过 bgrewriteaof 命令来手动触发 AOF 文件的重写, 这个重写的过程也是通过子进程实现的。
在子进程进行 AOF 重写时, 主线程需要保证
- 处理客户端的请求
- 将新增和更新命令追加到现有的 AOF 文件中
- 将新增和更新命令追加到 AOF 重写缓存中
3 AOF 文件的优势和劣势
优势
- AOF 持久化的方法提供了多种的同步频率, 即使使用默认的同步频率每秒同步一次, Redis 最多也就丢失 1 秒的数据而已
- AOF 日志文件以 append-only 模式写入, 所以没有任何磁盘寻址的开销, 写入性能非常高, 而且文件不容易受损, 即使文件尾部受损, 也能很容易恢复, 打开文件, 把后面损坏的数据删除即可
劣势
- 对于具有相同数据的的 Redis, AOF 文件通常会比 RDF 文件体积更大 (RDB 存的是数据快照)
- 虽然 AOF 提供了多种同步的频率, 默认情况下, 每秒同步一次的频率也具有较高的性能。但是在高并发的情况下, RDB 比 AOF 具好更好的性能保证
4 AOF 和 RDB 两种方案比较
如果可以忍受一小段时间内数据的丢失, 使用 RDB 是最好的, 定时生成 RDB 快照 (snapshot) 非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快, 否则使用 AOF。
但是一般情况下建议不要单独使用某一种持久化机制, 而是应该两种一起用, 在这种情况下, 当 Redis 重启的时候会优先载入 AOF 文件来恢复原始的数据, 因为在通常情况下 AOF 文件保存的数据集要比 RDB 文件保存的数据集要完整。
在 Redis 4.0 带来了一个新的持久化选项 —— 混合持久化。将 RDB 文件的内容和增量的 AOF 日志文件存在一起。
这里的 AOF 日志不再是全量的日志, 而是自持久化开始到持久化结束的这段时间发生的增量 AOF 日志, 通常这部分 AOF 日志很小。
在 Redis 重启的时候, 可以先加载 RDB 的内容, 然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放, 重启效率因此大幅得到提升。
5 AOF 的过程
高度概括如下:
- 所有的修改命令会追加到 Redis 的一个 AOF 缓存区
- AOF 缓存区根据配置的策略向硬盘做同步操作
- 随着 AOF 文件越来越大, 达到配置的条件, 对 AOF 文件进行重写, 达到压缩的目的
到此, AOF 的理论知识就没了, 下面是介绍几个比较重要的函数的逻辑。
6 AOF 文件结构
如果现在向 Redis 中写入一个 key 为 redis-key, value 为 redis-value 的字符串键值对后, 这对键值对会以下面的格式保存在 AOF 文件中:
*3\r\n$3\r\nset\r\n$9\r\nredis-key\r\n$11\r\nredis-value\r\n
以 *数字 的格式开始, 表示后面的命令的参数个数, 然后通过 $数字 表示后面参数的长度, 然后各个分隔之间通过 \r\n 进行分隔。
整体的格式就是 Redis 自定义的 RESP 协议, 具体的 RESP 介绍, 可以看一下这篇文章。
可以看到这种文本格式具有很高的可读性, 同时可以直接进行修改。
注: Redis 中有多个数据库, 写入的数据是保存在哪个数据库的?
在写入对应的数据库数据时, 内部会自动插入一条 select 数据库的编号 的命令到 AOF 文件, 表明对应的数据库, 解析时也是通过这条命令切换到对应的数据库。
源码中将 key 和 value 转换为上面的文件格式的实现是由 2 个函数实现的: catAppendOnlyGenericCommand 和 catAppendOnlyExpireAtCommand, 前者处理的是正常的命令, 而后者处理的是命令的过期时间。
6.1 catAppendOnlyGenericCommand - 没有过期时间的命令
/**
* 将入参的参数转为 RESP 格式写入到入参的 dst
* @param dst 当前未写入到文件的命令文本, 新的命令会追加到这个的后面
* @param argc 命令参数的个数
* @param argv 命令参数, 比如 set key value
*/
sds catAppendOnlyGenericCommand(sds dst, int argc, robj **argv) {
char buf[32];
int len, j;
robj *o;
// 上面的 set redis-key redis-value, 按照 RESP 协议转换的内容如下
// *3\r\n$3\r\nset\r\n$9\r\nredis-key\r\n$11\r\nredis-value\r\n
// 这里面可以拆为 2 部分处理
// 1. *3\r\n --> 命令的参数个数
// 2. $3\r\nset\r\n$9\r\nredis-key\r\n$11\r\nredis-value\r\n --> 具体的命令
// 1. 处理命令的参数个数部分
// 命令开始的前缀为 *
buf[0] = '*';
// argc 表示的是写入命令的个数, 经过这一步 buf = *参数个数
len = 1+ll2string(buf+1,sizeof(buf)-1,argc);
// 追加 \r\n, 到了这一步 经过这一步 buf = *参数个数\r\n
buf[len++] = '\r';
buf[len++] = '\n';
// 先将处理的文本第一步拼接到 dst 的后面, 此时 dst = *参数个数\r\n
dst = sdscatlen(dst,buf,len);
// 2. 处理具体的命令
// 拼接参数列表
for (j = 0; j < argc; j++) {
// 将对应的参数转为字符串类型
o = getDecodedObject(argv[j]);
buf[0] = '$';
// 将命令的长度写入到 buf 中
len = 1+ll2string(buf+1,sizeof(buf)-1,sdslen(o->ptr));
// 继续在后面拼接 \r\n, 到这一步 buf = $命令的长度\r\n
buf[len++] = '\r';
buf[len++] = '\n';
// 同样将 $命令的长度\r\n 写入到 dst
dst = sdscatlen(dst,buf,len);
// 将当前的命令具体的内容 写入到 dst
dst = sdscatlen(dst,o->ptr,sdslen(o->ptr));
// 在 dist 后面追加一个 \r\n
dst = sdscatlen(dst,"\r\n",2);
// 经过一次循环, dist 里面多了一段 $命令的长度\r\n命令\r\n 的内容
// 引用此数 - 1
decrRefCount(o);
}
return dst;
}
/**
* 如果入参的对象是 raw 或者 embstr 编码, 引用次数 + 1
* 如果为 int 编码, 根据这个整数创建出一个字符串, 同时返回这个字符串
* 其他类型不会处理
*/
robj *getDecodedObject(robj *o) {
robj *dec;
// 判断一个对象的编码是否为 OBJ_ENCODING_EMBSTR 或者 OBJ_ENCODING_RAW
if (sdsEncodedObject(o)) {
// 对象的引用次数还没达到最大值时, 进行引用次数 + 1
incrRefCount(o);
return o;
}
// 是字符串类型同时编码为 OBJ_ENCODING_INT
if (o->type == OBJ_STRING && o->encoding == OBJ_ENCODING_INT) {
char buf[32];
// 整形转为 char 数组
ll2string(buf,32,(long)o->ptr);
// 转为字符串
dec = createStringObject(buf,strlen(buf));
return dec;
} else {
serverPanic("Unknown encoding type");
}
}
2.7.2 catAppendOnlyExpireAtCommand - 带过期时间的命令
/**
* 将入参的过期时间转为 RESP 格式的字符串并存入 buf
* @param buf 当前未写入到文件的命令文本, 新的命令会追加到这个的后面, 同时将命令修改为 pexpireat 的格式
* @param cmd 执行的命令
* @param key redis 的 key 值
* @param second 过期的时间, 单位秒
*/
sds catAppendOnlyExpireAtCommand(sds buf, struct redisCommand *cmd, robj *key, robj *seconds) {
long long when;
robj *argv[3];
// 转为字符串类型, 以便使用 strtoll 函数
seconds = getDecodedObject(seconds);
// 根据指定的进制将入参的 char 数组转为一个整数, 10 --> 10 进制
// 得到过期的时间
when = strtoll(seconds->ptr,NULL,10);
// 当前执行的命令为 expire, setex expireat 将参数的秒转换成毫秒
if (cmd->proc == expireCommand || cmd->proc == setexCommand || cmd->proc == expireatCommand) {
when *= 1000;
}
// 将 expire, setex expireat 命令的参数,从相对时间设置为绝对时间
// 以前可能是 10s 后过期, 经过这一步,得到的是 xxx 年 yyy 月 的具体时间
if (cmd->proc == expireCommand || cmd->proc == pexpireCommand || cmd->proc == setexCommand || cmd->proc == psetexCommand) {
when += mstime();
}
// 减少 second 的引用次数, 便于回收
decrRefCount(seconds);
// 拼接为 pexpireat key 超时时间 的命令格式
argv[0] = createStringObject("PEXPIREAT",9);
argv[1] = key;
argv[2] = createStringObjectFromLongLong(when);
// 将上面的 pexpireat key 过期时间 的命令通过 catAppendOnlyGenericCommand 转为 RESP 格式的字符串
buf = catAppendOnlyGenericCommand(buf, 3, argv);
decrRefCount(argv[0]);
decrRefCount(argv[2]);
// 返回buf
return buf;
}
7 代码中涉及的几个模块
在 Redis 的 AOF 中涉及了几个模块功能, 这些功能辅助着整个 AOF 的功能, 这里对这些功能进行一个简单的讲解, 需要说明的时, 这些功能具体的实现可以不用去深入理解, 到了 AOF 源码时, 知道对应的函数的功能就行了。
这里也只是简单的介绍一下, 感兴趣了解一下大体的思路而已, 可以在后面 AOF 源码分析后, 再回来看一下。
7.1 延迟统计
Redis 中会对一些比较耗时的操作做一下统计, 便于后面的性能分析。
而在 AOF 中在调用 write 函数等操作也会进行延迟操作的统计。
大体的延迟统计实现如下:
统计延迟信息的配置
#define CONFIG_DEFAULT_LATENCY_MONITOR_THRESHOLD 0
struct redisServer {
// 延迟监视的阈值, 默认值为 0, 如果配置为大于 0 的值, 表示开启延迟监控, 同时超过了这个时间就进行延迟记录
long long latency_monitor_threshold;
// 字典, 也就是延迟记录的保存地方, 保存的格式是 延迟记录的事件名 和 latencyTimeSeries (一个数组)
dict *latency_events;
}
统计延迟样本对象的定义
struct latencyTimeSeries {
// 用于记录的下一个延迟样本的位置, 超过了数组的长度, 会重新被赋值为 0
int idx;
// 最大的延时
uint32_t max;
// 最近的延时记录样本数组
struct latencySample samples[LATENCY_TS_LEN];
}
struct latencySample {
// 延时样本创建的时间
int32_t time;
// 延迟样本的延迟时间, 单位毫秒
uint32_t latency;
}
统计延迟样本的函数定义
// 下面的函数做了小改动, 逻辑一样的
// 获取延迟事件的时间
void latencyStartMonitor(var) {
// mstime() 获取到当前的时间
var = server.latency_monitor_threshold ? mstime() : 0;
}
void latencyEndMonitor(var) {
if (server.latency_monitor_threshold) {
var = mstime() - var;
}
}
/**
* 判断是否需要记录延迟时间
* @param event 事件名
* @param var 延迟事件的耗时时间
*/
void latencyAddSampleIfNeeded(event,var) {
if (server.latency_monitor_threshold && (var) >= server.latency_monitor_threshold)
latencyAddSample((event),(var));
}
/**
* 添加延迟事件到 redisServer 的 latency_events 字典
*/
void latencyAddSample(char *event, mstime_t latency) {
// 找出 event 对应的延时事件记录结构体
struct latencyTimeSeries *ts = dictFetchValue(server.latency_events,event);
time_t now = time(NULL);
int prev;
// 没有对应事件的 latencyTimeSeries, 添加一个
if (ts == NULL) {
ts = zmalloc(sizeof(*ts));
ts->idx = 0;
ts->max = 0;
memset(ts->samples,0,sizeof(ts->samples));
dictAdd(server.latency_events,zstrdup(event),ts);
}
// 获取存储的位置
prev = (ts->idx + LATENCY_TS_LEN - 1) % LATENCY_TS_LEN;
// 数组对应位置的样本的创建时间等于当前时间
if (ts->samples[prev].time == now) {
// 当前的延迟时间大于样本里面的延迟时间, 更新为当前时间
if (latency > ts->samples[prev].latency)
ts->samples[prev].latency = latency;
return;
}
// 修改对应位置的样本的时间信息
ts->samples[ts->idx].time = time(NULL);
ts->samples[ts->idx].latency = latency;
// 如果大于当前所有样本的时间, 更新最大延迟时间为当前的延迟时间
if (latency > ts->max)
ts->max = latency;
ts->idx++;
// 超过了上限, 重新设置为 0
if (ts->idx == LATENCY_TS_LEN)
ts->idx = 0;
}
上面就是延迟事件的创建和保存, 至于在哪里使用的, 如何汇总分析, AOF 这里没有涉及, 就跳过了, 如果需要继续研究可以查看 latency.h 和 latency.c 这 2 个文件。
7.2 BIO - 后台线程
在上面的介绍中可以知道 fsync 是一个很耗时的过程, 如果把这个过程同样放在 Redis 的主线程中, 那么可能影响到整个 Redis 的性能, 所以 Redis 将 fsync 的过程交给了后台的线程处理。
Reids 将后台相关耗时的操作封装为了一个 BIO 的功能, 可以看出是一个线程池, 线程池在启动时初始了几个线程, 然后生产者向这个池中添加任务。
而 Redis 主线程在执行到 fsync 时, 会提交一个 fsync 的任务到 BIO 中, 完成结束。真正的 fsync 由后台线程处理。
大体的实现如下:
任务类型定义
// 执行 close 函数, 也就是文件的关闭
#define BIO_CLOSE_FILE 0
// 执行 redis_fsync 函数, 也就是 fsync 函数
#define BIO_AOF_FSYNC 1
// 延迟对象释放
#define BIO_LAZY_FREE 2
// 任务类型的总数
#define BIO_NUM_OPS 3
BIO 的初始化
// 存放声明的线程数组
static pthread_t bio_threads[BIO_NUM_OPS];
// 线程锁, 这里是多线程场景了, 所以有并发问题
static pthread_mutex_t bio_mutex[BIO_NUM_OPS];
// 添加任务相关的 condition, 简单的理解就是, 线程会被阻塞在这个 condition, 另一个线程可以唤醒这个 condition 上的线程
static pthread_cond_t bio_newjob_cond[BIO_NUM_OPS];
// 执行过程相关的 condition
static pthread_cond_t bio_step_cond[BIO_NUM_OPS];
// 任务列表
static list *bio_jobs[BIO_NUM_OPS];
// 存放对应的任务类型还有多少个任务等待执行
static unsigned long long bio_pending[BIO_NUM_OPS];
void bioInit(void) {
pthread_attr_t attr;
pthread_t thread;
size_t stacksize;
int j;
// 初始锁, condition, 任务列表
for (j = 0; j < BIO_NUM_OPS; j++) {
pthread_mutex_init(&bio_mutex[j],NULL);
pthread_cond_init(&bio_newjob_cond[j],NULL);
pthread_cond_init(&bio_step_cond[j],NULL);
bio_jobs[j] = listCreate();
bio_pending[j] = 0;
}
//设置线程栈空间
pthread_attr_init(&attr);
pthread_attr_getstacksize(&attr,&stacksize);
if (!stacksize)
stacksize = 1;
while (stacksize < REDIS_THREAD_STACK_SIZE)
stacksize *= 2;
pthread_attr_setstacksize(&attr, stacksize);
// 创建线程, 并存放到 bio_threads 这个线程数组
for (j = 0; j < BIO_NUM_OPS; j++) {
void *arg = (void*)(unsigned long) j;
// 创建线程, 线程执行的逻辑为 bioProcessBackgroundJobs
if (pthread_create(&thread,&attr,bioProcessBackgroundJobs,arg) != 0) {
serverLog(LL_WARNING,"Fatal: Can't initialize Background Jobs.");
exit(1);
}
bio_threads[j] = thread;
}
}
线程执行的逻辑
void *bioProcessBackgroundJobs(void *arg) {
struct bio_job *job;
unsigned long type = (unsigned long) arg;
sigset_t sigset;
// 任务类型校验
if (type >= BIO_NUM_OPS) {
serverLog(LL_WARNING, "Warning: bio thread started with wrong type %lu",type);
return NULL;
}
// 配置 thread 能够在任何时候被杀掉
pthread_setcancelstate(PTHREAD_CANCEL_ENABLE, NULL);
pthread_setcanceltype(PTHREAD_CANCEL_ASYNCHRONOUS, NULL);
// 获取锁
pthread_mutex_lock(&bio_mutex[type]);
sigemptyset(&sigset);
sigaddset(&sigset, SIGALRM);
if (pthread_sigmask(SIG_BLOCK, &sigset, NULL))
serverLog(LL_WARNING, "Warning: can't mask SIGALRM in bio.c thread: %s", strerror(errno));
// 线程主逻辑
while(1) {
listNode *ln;
// 没有任务, 进行等待,
if (listLength(bio_jobs[type]) == 0) {
pthread_cond_wait(&bio_newjob_cond[type],&bio_mutex[type]);
continue;
}
// 获取列表的第一个任务
ln = listFirst(bio_jobs[type]);
job = ln->value;
// 释放锁, 这个锁的功能主要是为了确保任务的获取
pthread_mutex_unlock(&bio_mutex[type]);
if (type == BIO_CLOSE_FILE) {
close((long)job->arg1);
} else if (type == BIO_AOF_FSYNC) {
redis_fsync((long)job->arg1);
} else if (type == BIO_LAZY_FREE) {
if (job->arg1)
lazyfreeFreeObjectFromBioThread(job->arg1);
else if (job->arg2 && job->arg3)
lazyfreeFreeDatabaseFromBioThread(job->arg2,job->arg3);
else if (job->arg3)
lazyfreeFreeSlotsMapFromBioThread(job->arg3);
} else {
serverPanic("Wrong job type in bioProcessBackgroundJobs().");
}
zfree(job);
// 获取锁
pthread_mutex_lock(&bio_mutex[type]);
// 删除任务
listDelNode(bio_jobs[type],ln);
// 需要执行的任务减 1
bio_pending[type]--;
// 唤醒所有等待在 bio_step_cond 上的线程
pthread_cond_broadcast(&bio_step_cond[type]);
}
}
添加任务
void bioCreateBackgroundJob(int type, void *arg1, void *arg2, void *arg3) {
struct bio_job *job = zmalloc(sizeof(*job));
job->time = time(NULL);
job->arg1 = arg1;
job->arg2 = arg2;
job->arg3 = arg3;
// 获取锁
pthread_mutex_lock(&bio_mutex[type]);
// 添加任务
listAddNodeTail(bio_jobs[type],job);
bio_pending[type]++;
// 通知等待在 bio_newjob_cond 的线程
pthread_cond_signal(&bio_newjob_cond[type]);
// 释放锁
pthread_mutex_unlock(&bio_mutex[type]);
}
7.3 pipe - 父子进程通信
Redis 的 AOF 重写机制和 RDB 类型, 也是通过 fork 创建子进程, 将整个 AOF 重写过程交给子进程处理。
不同的时: AOF 重写过程中会不断和父进程通信获取父进程的命令缓存。 父子进程之间就是通过 pipe 进行通讯的。
这里只做一下简单的了解。
#include <unistd.h>
int Pipe(int pipefd[2]);
通过 pipe 的函数可以在 2 个文件描述符之间建立一个通道, 第一个用来读 read(fd[0]), 第二个用来写 write(fd[1])。
具体的分析可以看一下这篇文章 APUE读书笔记—进程间通信(IPC)之管道和有名管道(FIFO)
而 Redis 中建立了 3 套通道
int aofCreatePipes(void) {
int fds[6] = {-1, -1, -1, -1, -1, -1};
int j;
// parent -> children data
if (pipe(fds) == -1) goto error;
// children -> parent ack
if (pipe(fds+2) == -1) goto error;
// parent -> children ack
if (pipe(fds+4) == -1) goto error;
// 同步非阻塞
if (anetNonBlock(NULL,fds[0]) != ANET_OK) goto error;
if (anetNonBlock(NULL,fds[1]) != ANET_OK) goto error;
// 注册一个事件, 执行的函数为 aofChildPipeReadable, 里面的逻辑就是读取 aof_pipe_read_ack_from_child 的数据到 aof_pipe_write_ack_to_child
if (aeCreateFileEvent(server.el, fds[2], AE_READABLE, aofChildPipeReadable, NULL) == AE_ERR) goto error;
// 6 个通道
server.aof_pipe_write_data_to_child = fds[1];
server.aof_pipe_read_data_from_parent = fds[0];
server.aof_pipe_write_ack_to_parent = fds[3];
server.aof_pipe_read_ack_from_child = fds[2];
server.aof_pipe_write_ack_to_child = fds[5];
server.aof_pipe_read_ack_from_parent = fds[4];
server.aof_stop_sending_diff = 0;
return C_OK;
}
最终形成的效果如下:
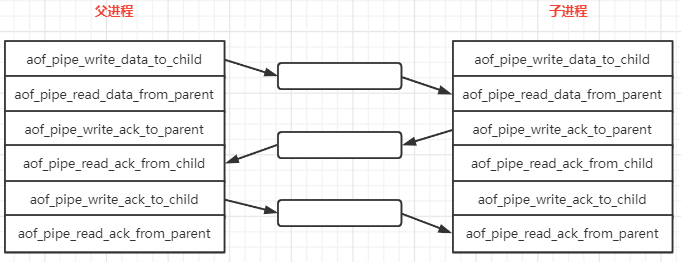
父进程写入到 aof_pipe_read_data_from_parent 的数据会自动同步到子进程的 aof_pipe_read_data_from_parent, 另外 2 个类似。
至此, AOF 的一些概念和源码中相关的一些代码就介绍完了, 下篇开始真正的 AOF 源码分析。