1 问题描述
在geolife 笔记:将所有轨迹放入一个DataFrame-CSDN博客中,已经将所有的轨迹放入一个DataFrame中了,我们现在需要比较,在不同的轨迹距离度量方法下,轨迹相似度的效果。

这里采用论文笔记:Deep Representation Learning for Trajectory Similarity Computation-CSDN博客中的方法:

2 收集每一个id对应的轨迹
2.1 经纬度转化成墨卡托坐标系
2.1.1 相关坐标系转换函数
def lonlat_to_Mercator_(lon,lon_y):
x=lon*20037508.34/180
y=math.log(math.tan((90 + lon_y) * math.pi / 360)) / (math.pi / 180)
y=y*20037508.34/180
return x,y
def Webmercater2latlon(mer_x,mer_y):
lon_x=mer_x/20037508.34*180
lon_y=mer_y/20037508.34*180
lon_y=180/math.pi*(2*math.atan(math.exp(lon_y*math.pi/180))-math.pi/2)
return(lon_x,lon_y)2.1.2 将traj中的经纬度转换
import math
traj['mer_x'],traj['mer_y']=zip(*traj.apply(lambda row:lonlat_to_Mercator_(row['Longitude'],row['Latitude']),axis=1))
traj
2.2 收集每个用户的轨迹,并且分成Qa和Qb
2.2.1 轨迹数量(id数量)计数
iid=traj['id'].unique()
iid
'''
array(['5_0_0', '5_0_1', '6_0_0', ..., '18669_0_0', '18669_0_1',
'18669_1_0'], dtype=object)
'''
len(iid)
#265062.2.2 每一个id的轨迹是一个二维数组
usr_lst_a=[]
usr_lst_b=[]
for i in range(len(iid)):
print(str(i)+'/26506')
tmp=traj[traj['id']==iid[i]]
usr_lst_a.append(tmp.iloc[0::2][['mer_x','mer_y']].values.tolist())
usr_lst_b.append(tmp.iloc[1::2][['mer_x','mer_y']].values.tolist())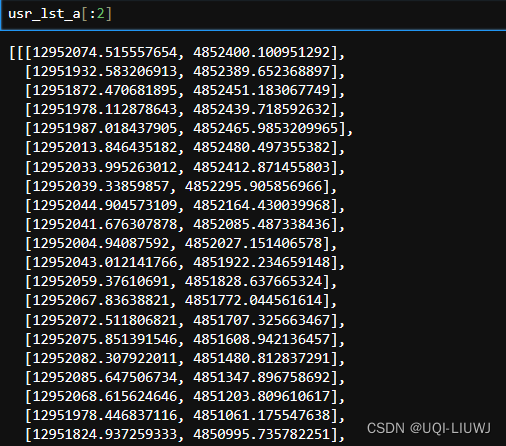
2.2.3 【番外篇】如何保存这样的一个usr_lst_a
使用pickle即可保存
import pickle
file=open('usr_lst_a.pkl', 'wb')
# 打开一个文件用于写入
pickle.dump(usr_lst_a, file)
# 使用 pickle 将列表保存到文件
加载也是用pickle即可
import pickle
file=open('usr_lst_a.pkl', 'rb')
# 打开包含列表的文件
usr_lst_a_loaded = pickle.load(file)
# 从文件中加载列表
# 现在 usr_lst_a_loaded 包含了原始列表的内容
3 获取 query和db的轨迹
3.1 获取 query的index
这里我们假设取100条query轨迹
import numpy as np
query_index=np.random.choice(range(26506),100,replace=False)
query_index3.2 获取db的index
db中不能有query中相同的index,需要将其去掉
remaining_index=np.setdiff1d(range(26506),query_index)
#剥离掉query_index中出现过的index
db_index_200=np.random.choice(remaining_index,200,replace=False)
#不放回地取200条db轨迹3.3 获得index对应的query和db
#query是usr_lst_a的轨迹
#db是usr_lst_b的轨迹
query_a=[np.array(usr_lst_a[i]) for i in query_index]
# query的轨迹
db_200=[np.array(usr_lst_b[i]) for i in query_index]
#前面图中的D'Q部分
tmp=[np.array(usr_lst_b[i]) for i in db_index_200]
#前面图中的D'P部分
db_200.extend(tmp)
len(db_200)
#300
#合并D'Q 和D'P4 进行不同轨迹距离metric的比较
这里我们使用traj_dist 笔记:测量轨迹距离-CSDN博客
4.1 DTW
4.1.1 计算距离
matrix=tdist.cdist(query_a,db_200,metric='dtw')
matrix.shape
#(100, 300)
matrix
'''
array([[3.99011261e+03, 1.26255574e+05, 1.66553907e+06, ...,
8.98934874e+05, 7.84387213e+05, 5.95675251e+05],
[1.28147933e+05, 9.01677894e+02, 1.55506527e+06, ...,
1.03084098e+06, 6.73764954e+05, 1.83283089e+05],
[1.67968070e+06, 1.56695085e+06, 5.33874317e+03, ...,
3.50815209e+06, 1.65426137e+06, 1.38635168e+06],
...,
[3.01319981e+05, 1.77685546e+05, 1.27850210e+06, ...,
1.62103431e+06, 7.59119890e+05, 1.09910254e+06],
[5.33804206e+05, 3.42443346e+05, 2.76131608e+06, ...,
7.79191042e+05, 7.07501918e+05, 3.45680219e+05],
[6.03068982e+05, 1.00838365e+06, 2.75499248e+06, ...,
9.87143735e+05, 1.53889762e+06, 2.25913510e+06]])
'''
# 距离矩阵排序
sort_index=np.argsort(matrix)
sort_index
'''
array([[ 0, 121, 225, ..., 135, 47, 201],
[ 1, 21, 124, ..., 47, 201, 271],
[ 2, 241, 111, ..., 29, 226, 271],
...,
[ 97, 110, 240, ..., 60, 135, 271],
[ 98, 284, 26, ..., 29, 81, 170],
[ 99, 239, 27, ..., 47, 201, 170]])
'''4.1.2 计算hit rate
即hit rate @1,有多少的top-1轨迹正好是对应的Ta‘
num=0
for i in range(100):
if(i in sort_index[i][:1]):
num+=1
num/100
#0.974.1.3 计算 mean rank
每一条轨迹的平均rank
num=0
for i in range(len(sort_index)):
tmp=sort_index[i].tolist()
#每一个T'a对应的rank
num+=tmp.index(i)
num/100+1
#这里+1的原因是,index是从0开始计数的,rank则是从1开始的
#1.034.2 其他
其他的也是类似的
#EDR
matrix_edr=tdist.cdist(query_a,db_200,metric='edr',eps=1000)
#ERP
matrix_erp=tdist.cdist(query_a,db_200,metric='erp',g=g)
#LCSS
matrix_lcss=tdist.cdist(query_a,db_200,metric='lcss',eps=1000)
#hausdorff
matrix_hau=tdist.cdist(query_a,db_200,metric='hausdorff')