学习冯诺伊曼体系结构之前,我们要本着两个问题来学习:
- 什么是冯诺伊曼体系结构?
- 为什么要有冯诺伊曼体系结构?
一、冯·诺伊曼体系结构
1. 什么是冯诺伊曼体系结构?
那我们就先来回答一下什么是冯诺伊曼体系结构:
首先我们要确定的是冯诺伊曼这个人发明了这个结构,这个结构是由CPU、输入设备、输出设备和存储器组成的;
而且如今的计算机基本都是冯诺伊曼体系结构,这也就证实了这个结构的可行性和泛用性。我们先有对这个结构的简单的认识,之后再去学习这个结构具体解决了什么问题,具有什么价值。
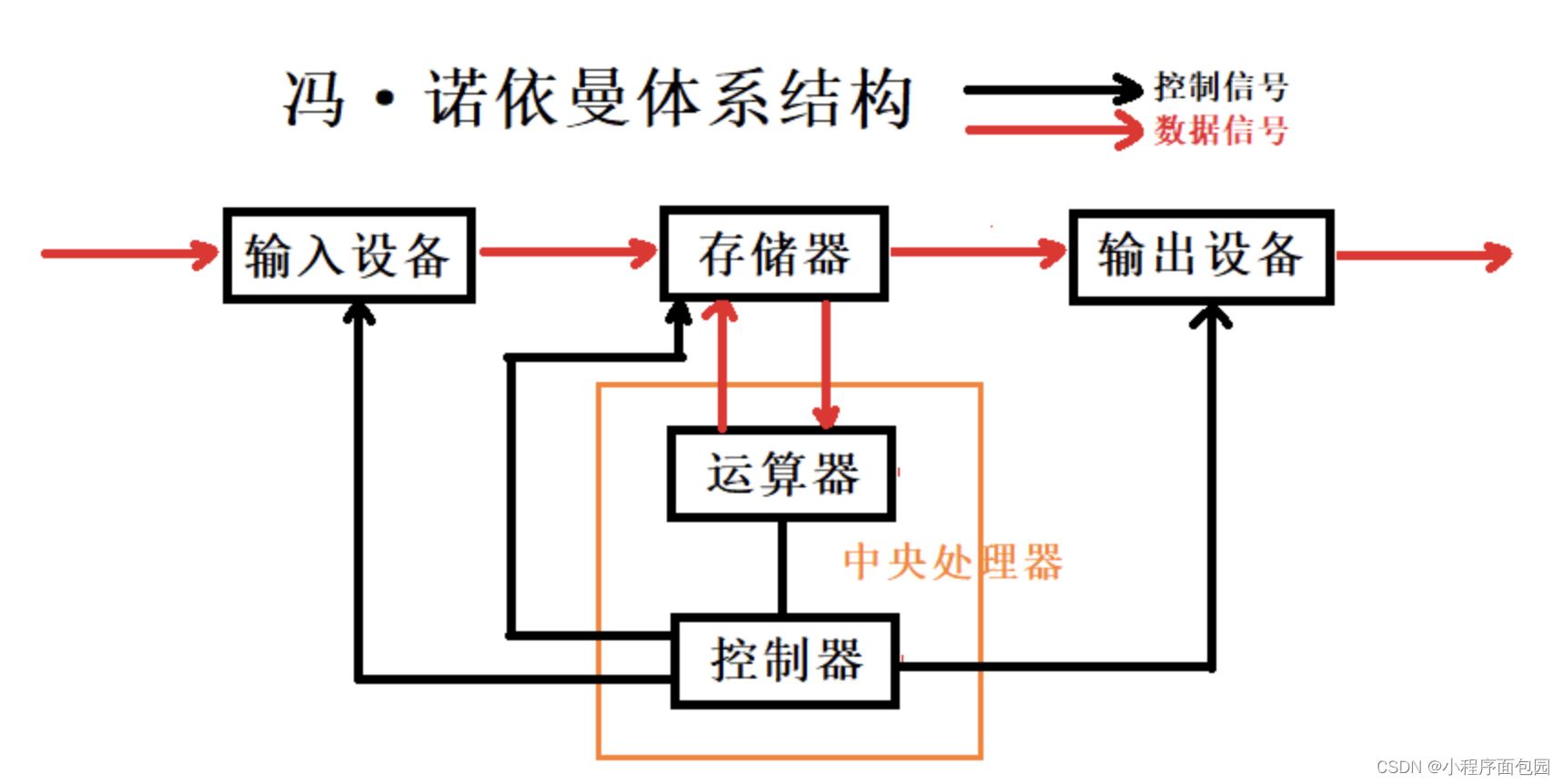
首先就来看一下冯·诺伊曼体系结构的内容:
- 输入设备:话筒、摄像头、键盘、鼠标、磁盘、网卡等;
- 输出设备:显示器、声卡、网卡、显卡、磁盘、打印机等;
- CPU(中央处理器):包括运算器(算术运算+-*/、逻辑运算&|^ ~);
- 存储器:内存(掉电易失)
掉电易失:
比如我们在编辑一个文档,我们只编辑没有保存,你的电脑关机了,此时我们重新开机的时候,是找不到这个文档里面的内容的;因为我们没有保存起来,没有保存的时候,文档是存储在内存中的,内存具有掉电易失的特性,所以关机之后就找不到了,而我们保存了之后,是将文档保存在磁盘中,此时关机再打开也能找到该文档;
一句话概括:内存不具备永久存储的功能
2. 为什么要有冯诺伊曼体系结构?
在弄清为什么要有冯诺伊曼体系结构之前,我们先看看这些设备之间是怎样来发挥作用的,因为在我们的认知里,对键盘设备的输入字符,一定是为了向显示器设备输出,比如我们通过微信给朋友发送信息,一定是将我们从键盘输入的信息,发送到朋友电脑的显示器上输出的,所以正因为这样的现象,我们可以看出设备之间一定是连接起来共同作用的,因为数据的传递不可能只是一个设备完成的;所以连接的目的其实就是让数据在不同设备之间进行流动。
那我们设立一个场景:在编辑文档的时候,我们先编辑一段文档,保存,关闭,再打开,我们会发现打开的文档依旧是之前写的文档,此时我们再进行编辑,但是不保存,直接关闭。这个时候磁盘的文档是修改之后的,还是修改之前的呢?毋庸置疑,一定是修改之前的,所以我们会发现一个事情:磁盘的文档和我们打开之后存在内存的文档是两个独立的文档,一个改变不会影响另外一个,除非再次保存;这就说明了一个事情,数据在不同设备之间的流动,本质上其实是在不同设备之间的拷贝,不同设备之间的数据相互独立,互不影响,除非进行了保存这类操作。
不同设备之间的拷贝,一定是需要花费时间的,所以拷贝一定也是有速度的,那计算机的速度其实就是设备之间整体拷贝的速度;众所周知的是CPU的速度是非常快的,而我们的外设(输入输出设备)的速度是很慢的,所以CPU如果和我们的外设之间传数据,速度就会被外设牵累,变慢;这很像木桶原理,不能以长处为标准,要以短板为准;那这时,怎么来提升计算机的速度呢?
首先我们先看这张图片:存储金字塔
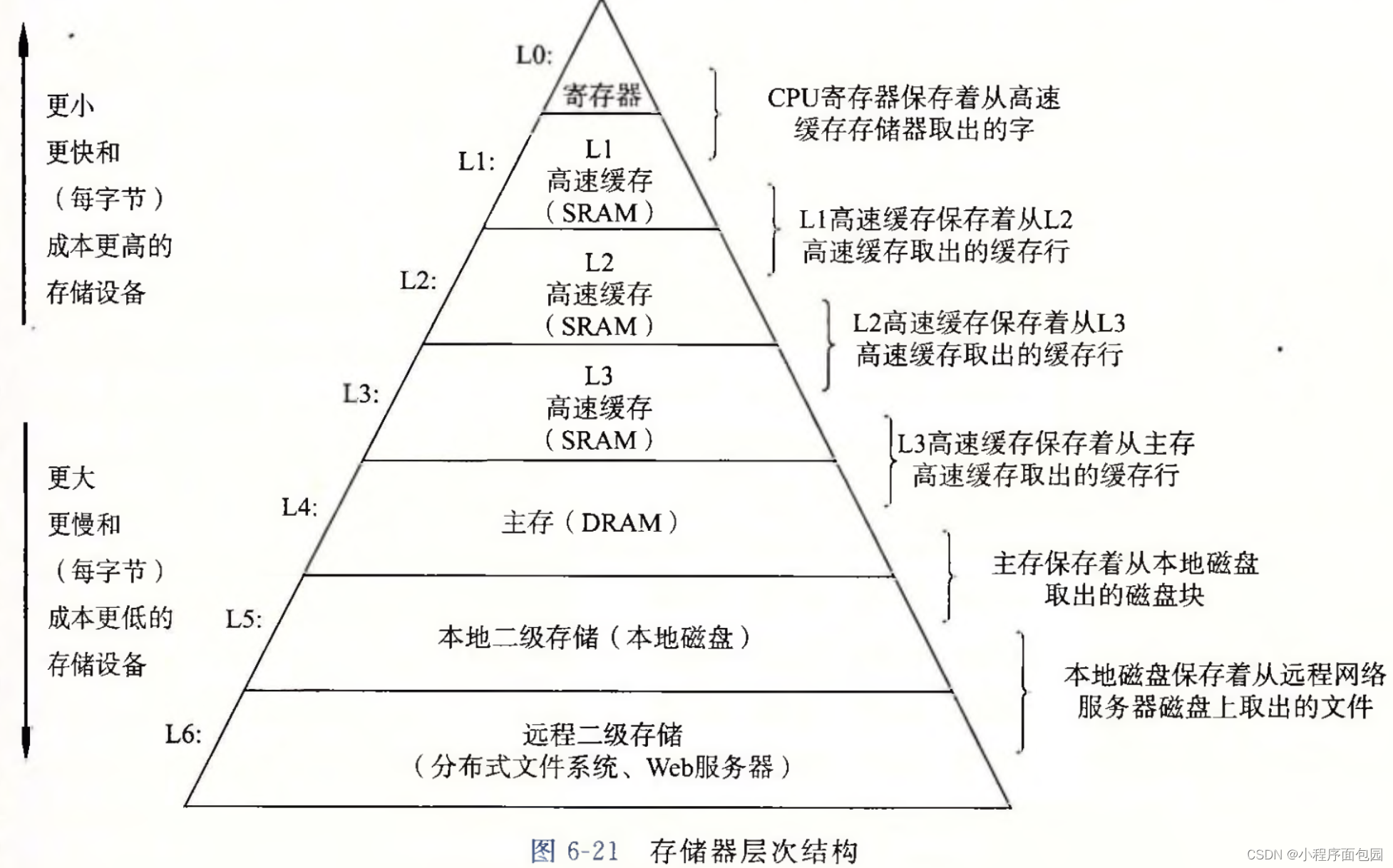
这个结构就是表明了各个设备的速度,我们可以看到外设是最底层的,速度最慢,但是价格却很便宜,大家要记住计算机之所以可以家喻户晓的原因就是因为造价不是很昂贵,家家都可以拥有;所以我们在解决计算机的速度的时候,完全可以让寄存器贯穿计算机的所有设备,因为这可以使计算机的速度变的飞快,但是价格也是十分的昂贵;所以这不利于计算机的广泛传播。基于这两个原因,既要提速,又要控制价格。就有了内存这个中间者,这也是冯诺伊曼体系结构的核心所在,正是这个结构有了内存,才会被计算机广泛应用。
在这里讲解一下内存是如何提高效率的:
我们知道最开始效率低下是因为外设直接和CPU传数据,这就是计算机的速度以外设为标准,大大降低了整体的速度。而内存的引入,是完全有效地提高了整体的速度的,大家这里一定有了疑问,最开始是外设 —> CPU,而加入内存之后,外设 —> 内存 —> CPU,这看起来并没有提高速度,反而还降低了速度啊。其实并不是这样的,我们的内存提高效率的原因是在于,可以将数据预先加载到内存中,然后由内存直接和CPU对接,CPU操作完的也是先放到内存中的缓存里,等CPU闲置了,再一并发送给外设。这样的流程也就注定了计算机的速度是以内存为准了,大大提高了计算机的整体效率。
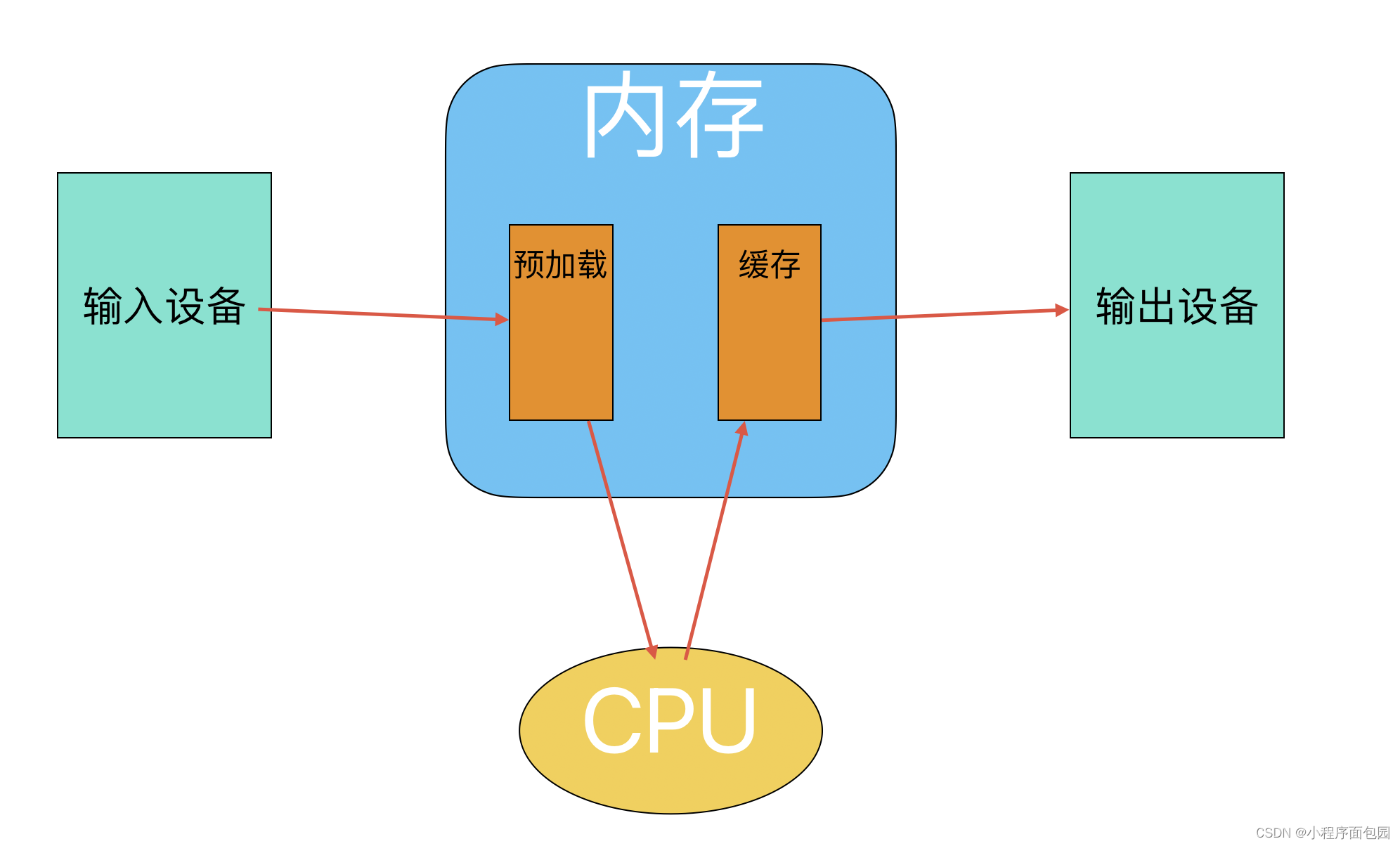
所以到了这里,我们也就不难去模拟一个数据传输的过程了
场景设立:我发送hello给小杨
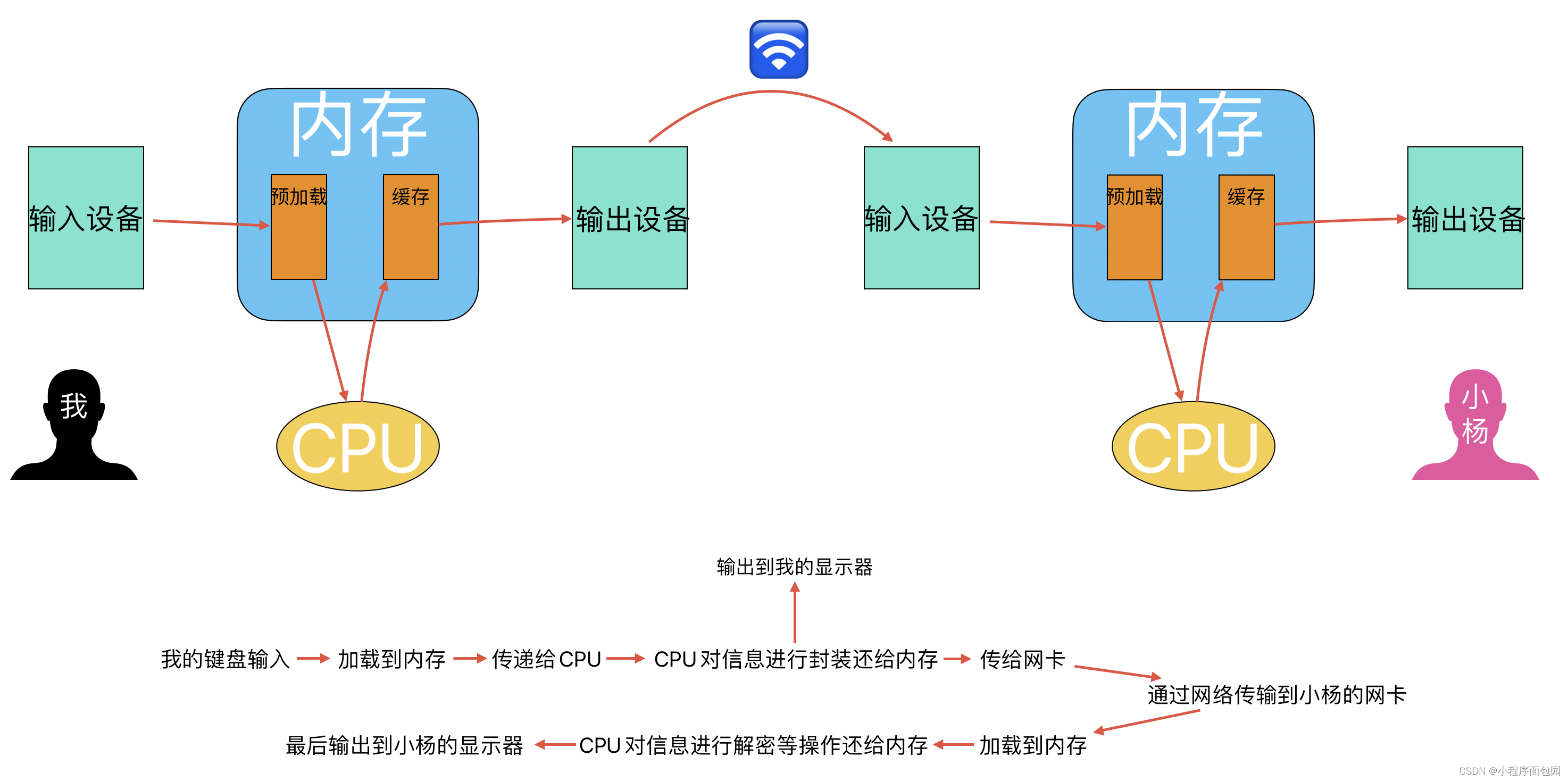
所以总结一下:冯诺伊曼体系结构是一个以内存为核心的结构、外设和CPU传送数据必须要通过内存、这样既提高了计算机的效率,价格也不贵。
二、操作系统(OS)
想真正弄懂操作系统是一个过程,不是一篇博客可以解释清楚的,你需要在漫长的学习生活中去感受它,我们现在大多数学习的知识都是具有滞后性的,所以下面的内容,将会让你对操作系统有初步的认识,但不会让你秒懂。
学习之前,依旧是要提出两个问题:
- 什么是操作系统?
- 为什么要有操作系统?
1. 什么是操作系统?
操作系统是一个进行软硬件资源管理的软件
既然是一个软件,那么它就是一个可执行的程序,既然是一个可执行的程序,那么就注定是必须要运行的,既然必须被运行,就一定会经过CPU的处理,一定会被加载到内存上。
所以操作系统是第一个被加载到内存的软件。这个加载的现象大家是都看到过的,在我们电脑开机的那段时间,就是进行着对操作系统加载到内存的操作!
那我们来分析一下什么叫对软硬件的资源做管理,重点要落在管理这个词上,管理的存在,就注定了有管理者和被管理者,如学校、公司、医院等,校长、董事长、院长这几个角色就是管理者,他们要分别对学生、员工、病人和医护人员进行管理,那他们会挨个人的管理吗?答案是肯定不会的,所以管理者是不会直接对被管理者本身做管理的,如果你是管理者,一定是希望去管理被管理者的信息,做成表格去管理。所以管理者是对信息做管理,那管理的本质就是对信息或者数据做管理!
思考这样一个问题,一个学校有上万个人,管理者对这些人的数据一定不会是一个一个看的,一定是要建立在某种数据结构之上的,并且要具备增删查改等操作。而每个人都是不一样的个体,有自己的姓名、年龄、喜好、住址等等,但是这些都是人人必备的元素,也是管理他们信息的必备的标识,所以我们可以建立一个结构体来记录他们的信息,之后组成顺序表、链表等数据结构,并且具有增删查改的功能。
那么对人的管理,就是对数据的管理,最后就演变成对数据结构的增删查改!得到他们的信息之前必须的步骤就是先描述人的信息,再组织数据结构。总结就是先描述,再组织。所以管理,其实就是对数据进行先描述,再组织的过程。那回到操作系统这里,操作系统对软硬件资源的管理,其实就是对这些软硬件的信息的管理,也就是对存放软硬件信息的数据结构做管理!因为语言的本质就是对数据做管理,我们可以回想写代码的时候,无一不是对数据的管理,增删查改、输出输入、判断等等。
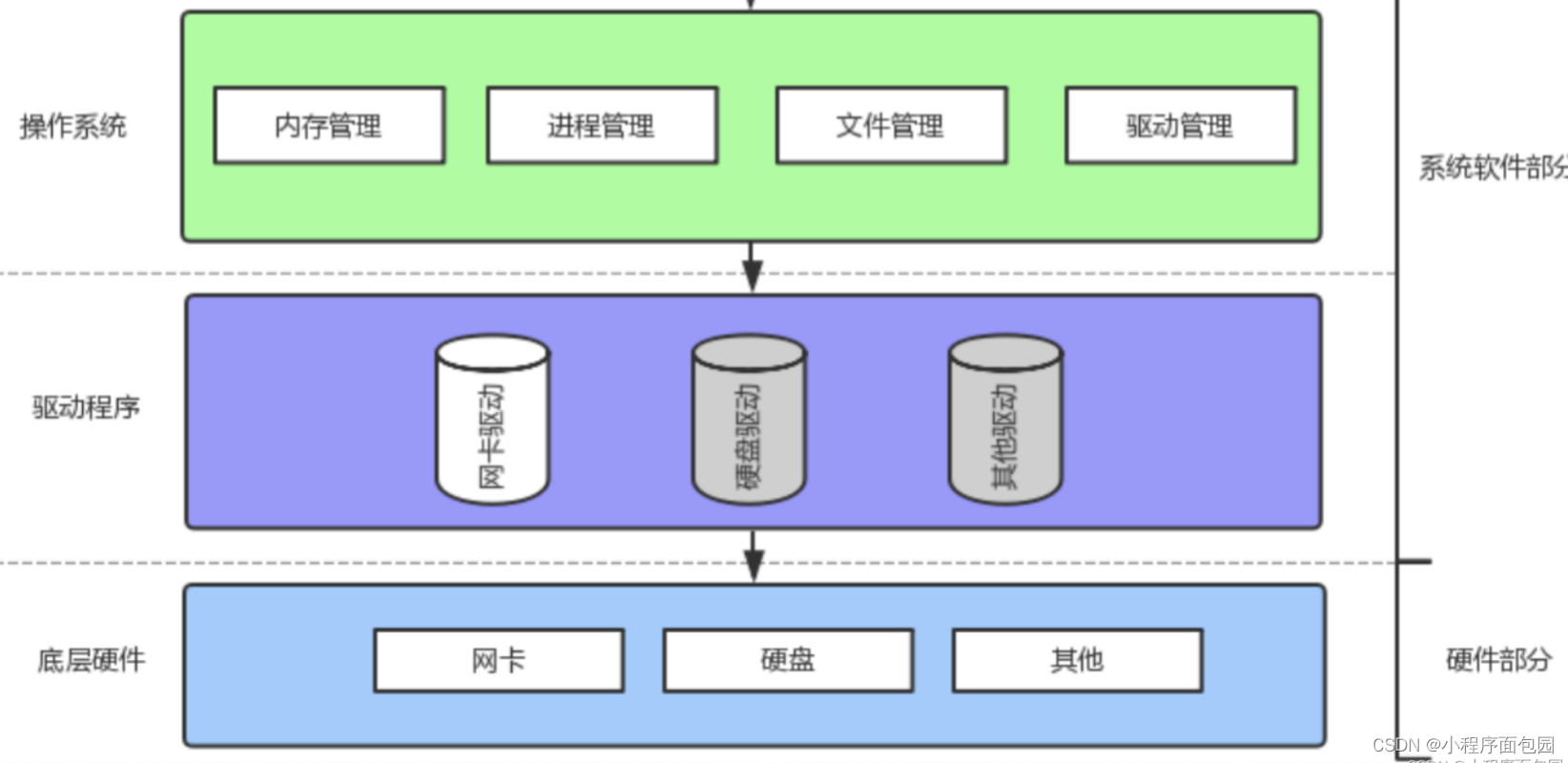
操作系统是通过驱动程序来管理硬件的,而软件其实就是一个个可执行的程序,可执行程序是要加载到内存中的,因为要经过CPU的处理,所以必须到内存,而操作系统就是在内存里的,所以操作系统管理软件是在内存中去管理的。
2. 为什么要有操作系统?
既然我们知道什么是操作系统了,也知道操作系统是管理软硬件信息的,那到底为什么要有操作系统呢?操作系统有什么作用呢?
先给结论:对下可以管理好软硬件资源,对上可以给用户提供稳定、高效和安全的运行环境
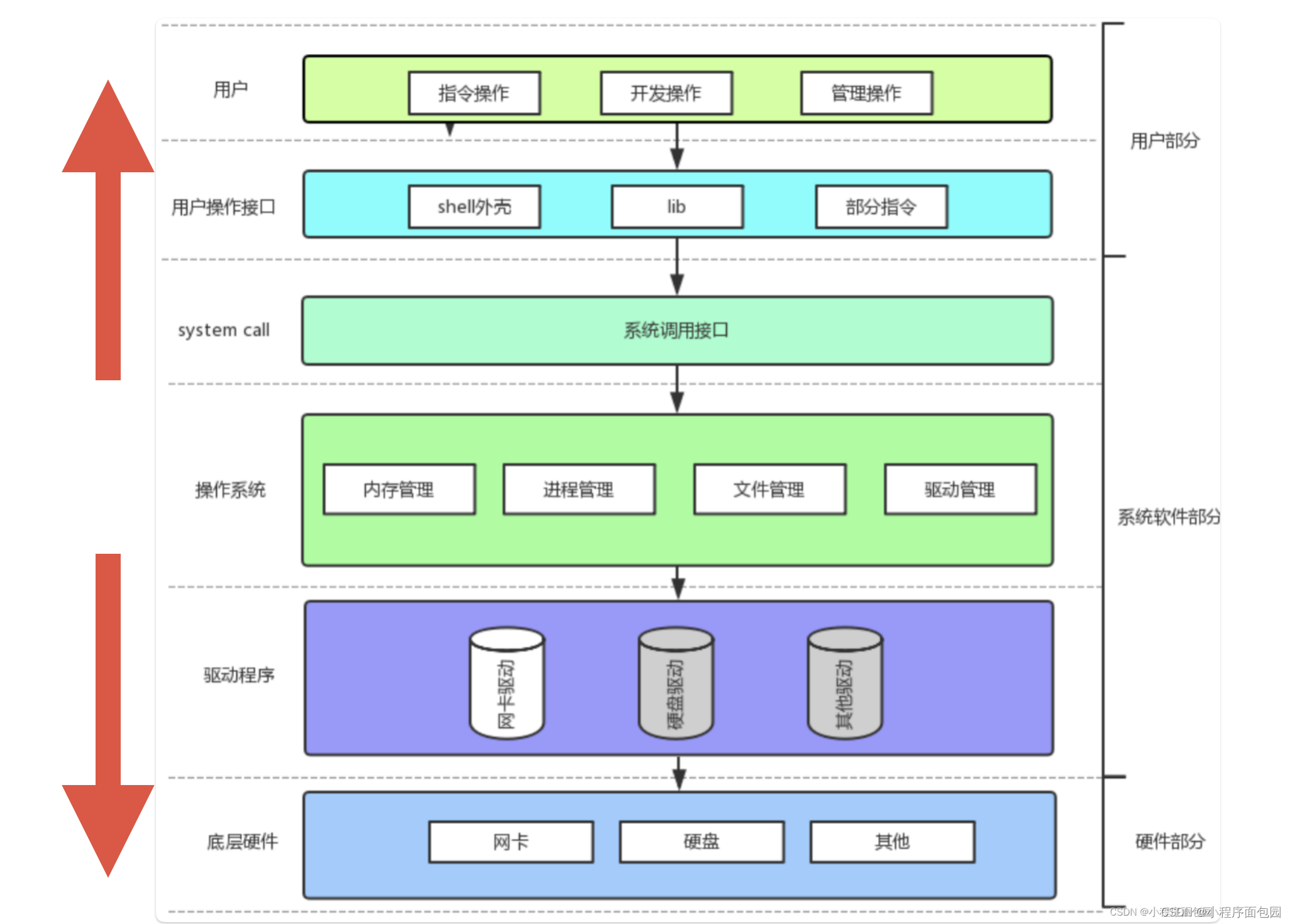
管理好软硬件资源不用解释了,上面已经解释清楚了,那为什么可以给用户提供稳定、高效和安全的运行环境呢?
比如一家银行、你能让取钱的直接去金库拿钱吗?肯定不能,因为怕偷钱。这换在计算机上就是更改计算机的底层数据,是不被允许的,所以银行才有银行窗口帮你办理,操作系统也是一个道理,为了让计算机安全,坚决不能让用户直接访问计算机底层的数据,否则带来的影响十分不好。那用户应该如何来访问数据呢?这时操作系统就提供了一个系统调用接口,我们要访问数据,必须通过系统调用接口来访问,这就类似于类里面的public,而数据就是private。但是用户直接使用系统调用接口的成本太高,不利于操作,就出现了指令、shell外壳和lib(库)这样的操作来供我们使用,我们只需要发送指令,调用库函数,他们就会自动匹配系统调用接口,但是我们依旧是可以直接使用系统调用接口的。
比如printf和scanf函数,这两种函数是涉及到输入输出的,也就是涉及到了硬件的改变,硬件是属于操作系统内部的,用户不可以直接访问,就一定要通过系统调用接口,而printf和scanf其实就是对系统调用接口进行了封装,使用这两个函数之后,会自动匹配系统调用接口来完成操作;所以只要涉及对硬件信息的更改,就一定要通过系统调用接口。
大家可以思考这样的问题,现在市面上的操作系统有Unix、Linux、macOS、Windows等,这些操作系统的系统调用接口一定是不同的,我们一定听说过某个语言是具备可移植性和跨平台性的,原因就是他们的lib(库)是可以实现对不同系统的系统调用接口的使用,实际就是对不同接口进行了封装。简单理解,条件编译,如果是Unix系统就用这个系统调用接口、Linux就用Linux的、Windows就用Windows的接口等等
综上所述,操作系统存在的意义就是两方面:
- 对下可以管理好软硬件资源
- 对上提供良好的运行环境
![[cleanrl] ppo_continuous_action源码解析](/images/no-images.jpg)