目录
Part.01 关于HDP
Part.02 核心组件原理
Part.03 资源规划
Part.04 基础环境配置
Part.05 Yum源配置
Part.06 安装OracleJDK
Part.07 安装MySQL
Part.08 部署Ambari集群
Part.09 安装OpenLDAP
Part.10 创建集群
Part.11 安装Kerberos
Part.12 安装HDFS
Part.13 安装Ranger
Part.14 安装YARN+MR
Part.15 安装HIVE
Part.16 安装HBase
Part.17 安装Spark2
Part.18 安装Flink
Part.19 安装Kafka
Part.20 安装Flume
十八、安装Flink
1.配置Ambari的flink资源
(1)创建flink源
下载链接为
https://repo.huaweicloud.com/apache/flink/flink-1.9.3/flink-1.9.3-bin-scala_2.12.tgz
https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.6.5-7.0/flink-shaded-hadoop-2-uber-2.6.5-7.0.jar
http://www.java2s.com/Code/JarDownload/javax.ws/javax.ws.rs-api-2.0.jar.zip
上传到hdp01上,并复制到/var/www/html下
mkdir /var/www/html/flink
cp /opt/flink-1.9.3-bin-scala_2.12.tgz /var/www/html/flink/
cp /opt/flink-shaded-hadoop-2-uber-2.6.5-7.0.jar /var/www/html/flink/
cp /opt/javax.ws.rs-api-2.0.jar /var/www/html/flink/
(2)下载ambari-flink-service服务
在外网服务器上
git clone https://ghproxy.com/https://gitee.com/liujingwen-git/ambari-flink-service-master.git /root/FLINK
注:github.com无法直接下载,可以使用gproxy.com进行代理加速,拼接形成加速URL;或者将github.com在本地强制解析为140.82.114.4
将FLINK文件夹上传到hdp01的/var/lib/ambari-server/resources/stacks/HDP/3.1/services/上,对应的版本可在集群的服务器中查看
hdp-select status hadoop-client | sed 's/hadoop-client - \([0-9]\.[0-9]\).*/\1/'
(3)文件说明
从github上下载的ambari-flink-service文件较多,有些可以删除以及修改

(4)修改metainfo.xml文件
文件位置:
/var/lib/ambari-server/resources/stacks/HDP/3.1/services/FLINK/metainfo.xml
修改版本
<name>FLINK</name>
<displayName>Flink</displayName>
<comment>Apache Flink is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams.</comment>
<version>1.9.3</version>
删除FLINK_MASTER,仅保留安装FLINK_CLIENT,在Flink on YARN模式下,master与ResourceManager合设,无需单独安装
<components>
<component>
<name>FLINK_CLIENT</name>
<displayName>FlinkCLIENT</displayName>
<category>CLIENT</category>
<cardinality>1+</cardinality>
<commandScript>
<script>scripts/flink_client.py</script>
<scriptType>PYTHON</scriptType>
<timeout>10000</timeout>
</commandScript>
</component>
</components>
(5)修改flink-ambari-config.xml文件
文件位置:
/var/lib/ambari-server/resources/stacks/HDP/3.1/services/FLINK/configuration/flink-ambari-config.xml
修改安装路径
<property>
<name>flink_install_dir</name>
<value>/usr/hdp/3.1.5.0-152/flink</value>
<description>Location to install Flink</description>
</property>
修改安装包下载地址
<property>
<name>flink_download_url</name>
<value>http://hdp01.hdp.com/flink/flink-1.9.3-bin-scala_2.12.tgz</value>
<description>Snapshot download location. Downloaded when setup_prebuilt is true</description>
</property>
<property>
<name>flink_hadoop_shaded_jar</name>
<value>http://hdp01.hdp.com/flink/flink-shaded-hadoop-2-uber-2.6.5-7.0.jar</value>
<description>Flink shaded hadoop jar download location. Downloaded when setup_prebuilt is true</description>
</property>
</configuration>
(6)修改flink-env.xml文件
文件位置:
/var/lib/ambari-server/resources/stacks/HDP/3.1/services/FLINK/configuration/flink-env.xml
修改JAVA环境变量
env.java.home: /usr/local/jdk1.8.0_351/jre/
(7)修改flink_client.py文件
文件位置:
/var/lib/ambari-server/resources/stacks/HDP/3.1/services/FLINK/package/scripts/flink_client.py
该文件的作用调用相关的环境变量,来实现整个安装过程
内容如下:
#!/usr/bin/env ptyhon
from resource_management import *
class FlinkClient(Script):
def install(self, env):
print 'Install the Flink Client'
import params
env.set_params(params)
self.configure(env)
# create flink log dir
Directory(params.flink_log_dir,
owner=params.flink_user,
group=params.flink_group,
create_parents=True,
mode=0775
)
Execute(format("rm -rf {flink_install_dir}/log/flink"))
Execute(format("ln -s {flink_log_dir} {flink_install_dir}/log/flink"))
def configure(self, env):
import params
env.set_params(params)
# write out flink-conf.yaml
properties_content = InlineTemplate(params.flink_yaml_content)
File(format(params.flink_install_dir + "/conf/flink-conf.yaml"), content=properties_content)
def status(self, env):
raise ClientComponentHasNoStatus()
if __name__ == "__main__":
FlinkClient().execute()
(8)修改parameter.py文件
文件位置:
/var/lib/ambari-server/resources/stacks/HDP/3.1/services/FLINK/package/scripts/params.py
该文件定义了部分环境变量
内容如下:
#!/usr/bin/env python
from resource_management import *
from resource_management.libraries.script.script import Script
import sys, os, glob
from resource_management.libraries.functions.version import format_stack_version
from resource_management.libraries.functions.default import default
# server configurations
config = Script.get_config()
# params from flink-ambari-config
flink_install_dir = config['configurations']['flink-ambari-config']['flink_install_dir']
flink_numcontainers = config['configurations']['flink-ambari-config']['flink_numcontainers']
flink_numberoftaskslots= config['configurations']['flink-ambari-config']['flink_numberoftaskslots']
flink_jobmanager_memory = config['configurations']['flink-ambari-config']['flink_jobmanager_memory']
flink_container_memory = config['configurations']['flink-ambari-config']['flink_container_memory']
setup_prebuilt = config['configurations']['flink-ambari-config']['setup_prebuilt']
flink_appname = config['configurations']['flink-ambari-config']['flink_appname']
flink_queue = config['configurations']['flink-ambari-config']['flink_queue']
flink_streaming = config['configurations']['flink-ambari-config']['flink_streaming']
hadoop_conf_dir = config['configurations']['flink-ambari-config']['hadoop_conf_dir']
flink_download_url = config['configurations']['flink-ambari-config']['flink_download_url']
flink_hadoop_shaded_jar_url = config['configurations']['flink-ambari-config']['flink_hadoop_shaded_jar']
javax_ws_rs_api_jar = config['configurations']['flink-ambari-config']['javax_ws_rs_api_jar']
conf_dir=''
bin_dir=''
# params from flink-conf.yaml
flink_yaml_content = config['configurations']['flink-env']['content']
flink_user = config['configurations']['flink-env']['flink_user']
flink_group = config['configurations']['flink-env']['flink_group']
flink_log_dir = config['configurations']['flink-env']['flink_log_dir']
flink_log_file = os.path.join(flink_log_dir,'flink-setup.log')
temp_file='/tmp/flink.tgz'
(9)添加用户及组
添加用户和组
groupadd flink
useradd -d /home/flink -g flink flink
(10)重启ambari服务
重启服务
ambari-server restart
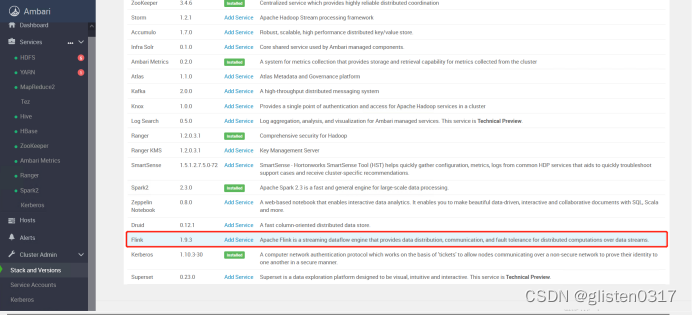
在ambari中的Stack and Versions中可以看到flink的信息
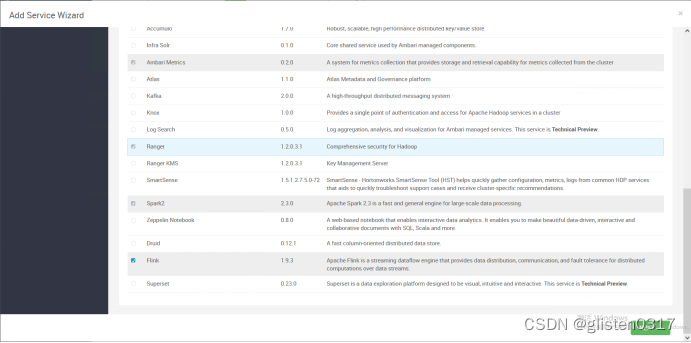
2.安装
添加flink服务

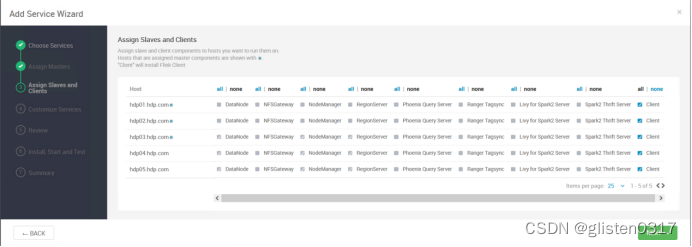
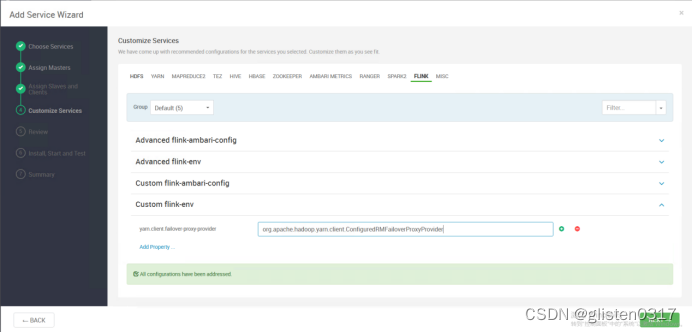
在Custom flink-env中新增
Key:yarn.client.failover-proxy-provider
Value:org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider
3.实验:wordcount
实验:wordcount
从尚硅谷下载实验用的程序代码,在idea中对以socket形式接收数据流的代码进行修改,从192.168.111.1的nc处接收数据流,然后对词频统计后输出到本地文件中
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream<String> stream = env.socketTextStream("192.168.111.1", 1234);
DataStream<Tuple2<String, Integer>> resultStream = stream.flatMap(new Tokenizer())
.keyBy(0)
.sum(1);
resultStream.print();
resultStream.writeAsText("/tmp/wc_result.txt");
env.execute("Flink Streaming Java API Skeleton");
}
在idea中的Build->Build Artifacts中选择build生成jar包,然后上传到hdp05上,使用一个租户进行kerberos认证后,提交flink任务。
cd /usr/hdp/3.1.5.0-152/flink/bin/
./flink run -m yarn-cluster /root/flink-tutorial-master.jar -c WordCountFromSocket
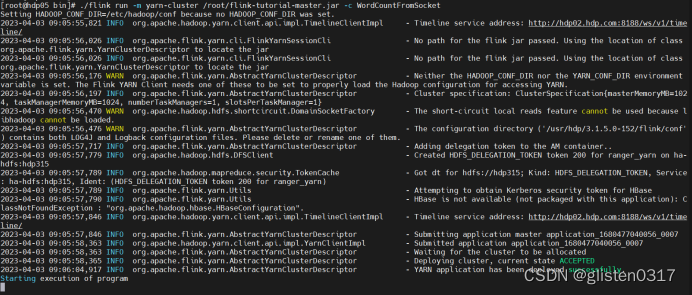
在192.168.111.1上启动nc
nc -l 1234

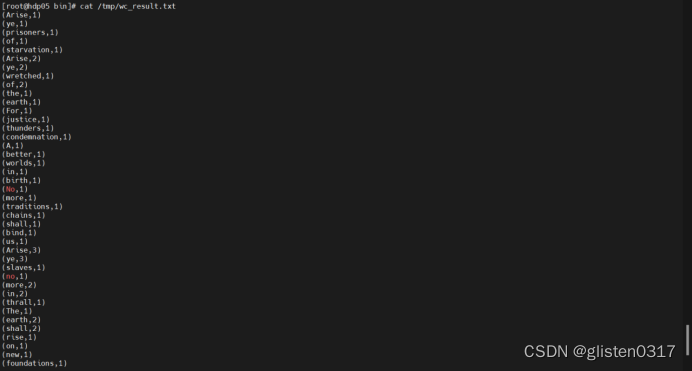
输入数据流后,中断nc进程,然后在hdp05上查看结果文件/tmp/wc_result.txt
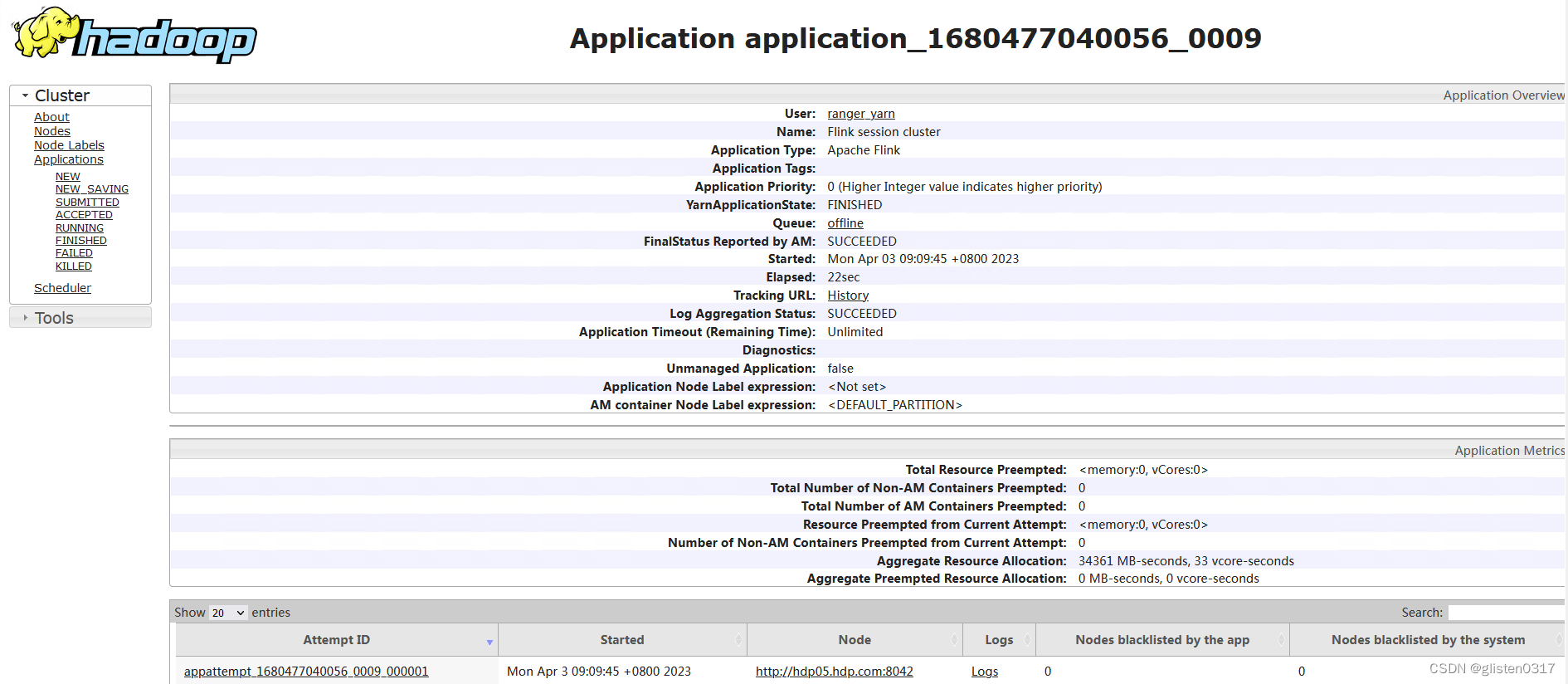
在yarn上可以查看到对应的应用信息
4.常见报错
(1)安装时报错Unable to run the custom hook script
报错信息:Error: Error: Unable to run the custom hook script [‘/usr/bin/python’, ‘/var/lib/ambari-agent/cache/stack-hooks/before-ANY/scripts/hook.py’, ‘ANY’, ‘/var/lib/ambari-agent/data/command-1360.json’, ‘/var/lib/ambari-agent/cache/stack-hooks/before-ANY’, ‘/var/lib/ambari-agent/data/structured-out-1360.json’, ‘INFO’, ‘/var/lib/ambari-agent/tmp’, ‘PROTOCOL_TLSv1_2’, ‘’]
2023-03-26 22:23:31,445 - The repository with version 3.1.5.0-152 for this command has been marked as resolved. It will be used to report the version of the component which was installed
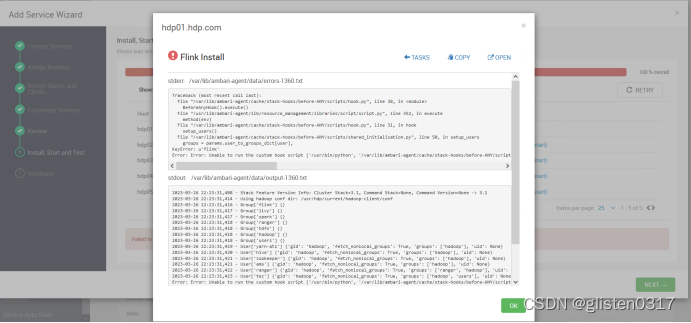
通过ambari添加自定义服务时,总是不能自动增加service账号
python configs.py -u admin -p lnyd@LNsy115 -n HDP315 -l hdp01 -t 8080 -a get -c cluster-env | grep -i ignore_groupsusers_create
python configs.py -u admin -p lnyd@LNsy115 -n HDP315 -l hdp01 -t 8080 -a set -c cluster-env -k ignore_groupsusers_create -v true

(2)安装后启动报错parent directory /usr/local/flink/conf doesn’t exist
安装后在启动时报错:resource_management.core.exceptions.Fail: Applying File[‘/usr/local/flink/conf/flink-conf.yaml’] failed, parent directory /usr/local/flink/conf doesn’t exist
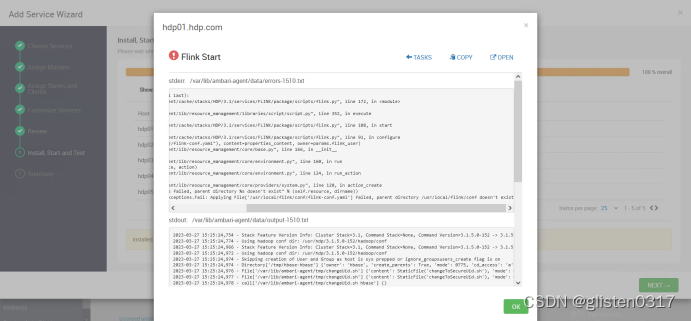
不知什么原因没解压过去,需要手动解压到该目录
tar -zxvf /opt/flink-1.9.3-bin-scala_2.12.tgz -C /root/
mv /root/flink-1.9.3/* /usr/local/flink/
(3)提交任务报错java.lang.NoClassDefFoundError
报错信息:
java.lang.NoClassDefFoundError: com/sun/jersey/core/util/FeaturesAndProperties
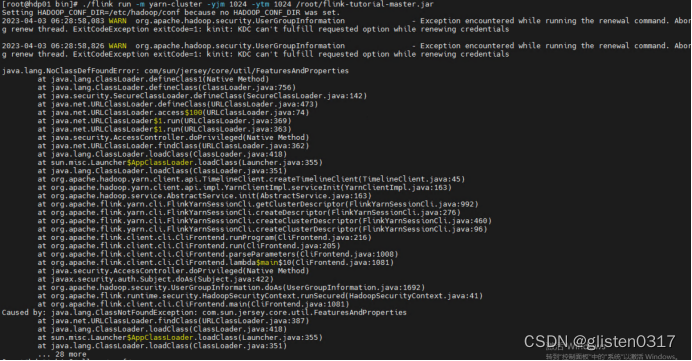
maven会自动下载相关的依赖jar包,因此需要将project下的jersey依赖jar包拷贝至flink的lib目录下