文章目录
- 一、了解什么是字体加密
- 二、Python打开字体加密文件
- 三、字体加密的通杀
- 1.静态的字体文件+固定顺序的字体
- 2.其他动态变化情况
一、了解什么是字体加密
字体加密是页面和前端字体文件想配合完成的一个反爬策略。通过css对其中一些重要数据进行加密,使我们在代码获取的和在页面上看到的数据是不同的。
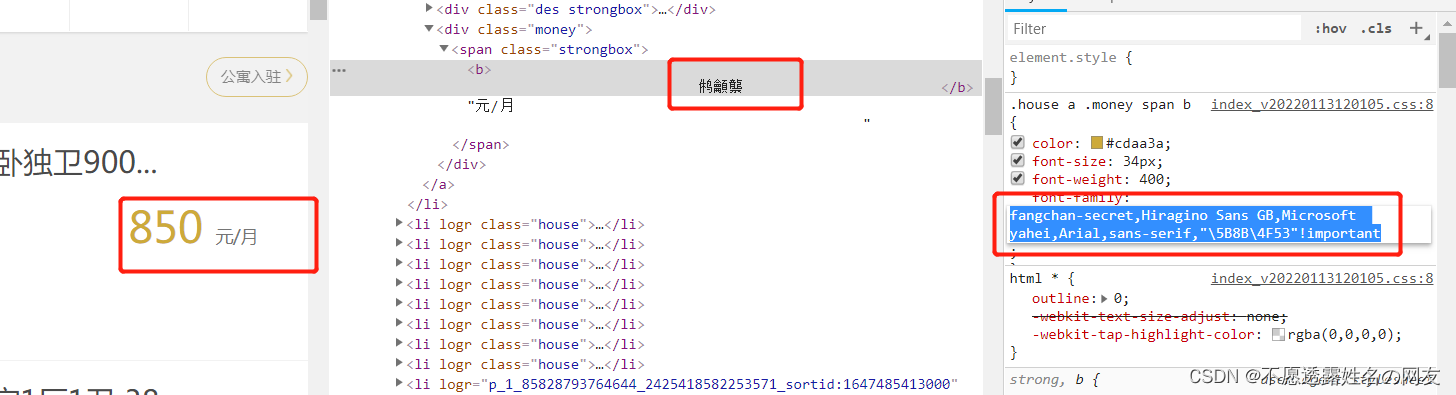
前端人员通过使用font-face来达到这个目的,font-face是CSS3中的一个模块,他主要是把自己定义的Web字体嵌入到你的网页中。而font-face的格式为:
@font-face {
font-family: <FontName>; # 定义字体的名称。
src: <source> [<format>][,<source> [<format>]]*; # 定义该字体下载的网址,包括ttf,eof,woff格式等
}
我们要打开ttf,eof,woff这些格式的字体文件有两种方式:
- FontCreator工具:https://www.high-logic.com/font-editor/fontcreator
- 在线FontEditor工具:http://fontstore.baidu.com/static/editor/index.html
我们抓包一个字体文件,在Font那一列,复制这个url到浏览器就可以下载下来

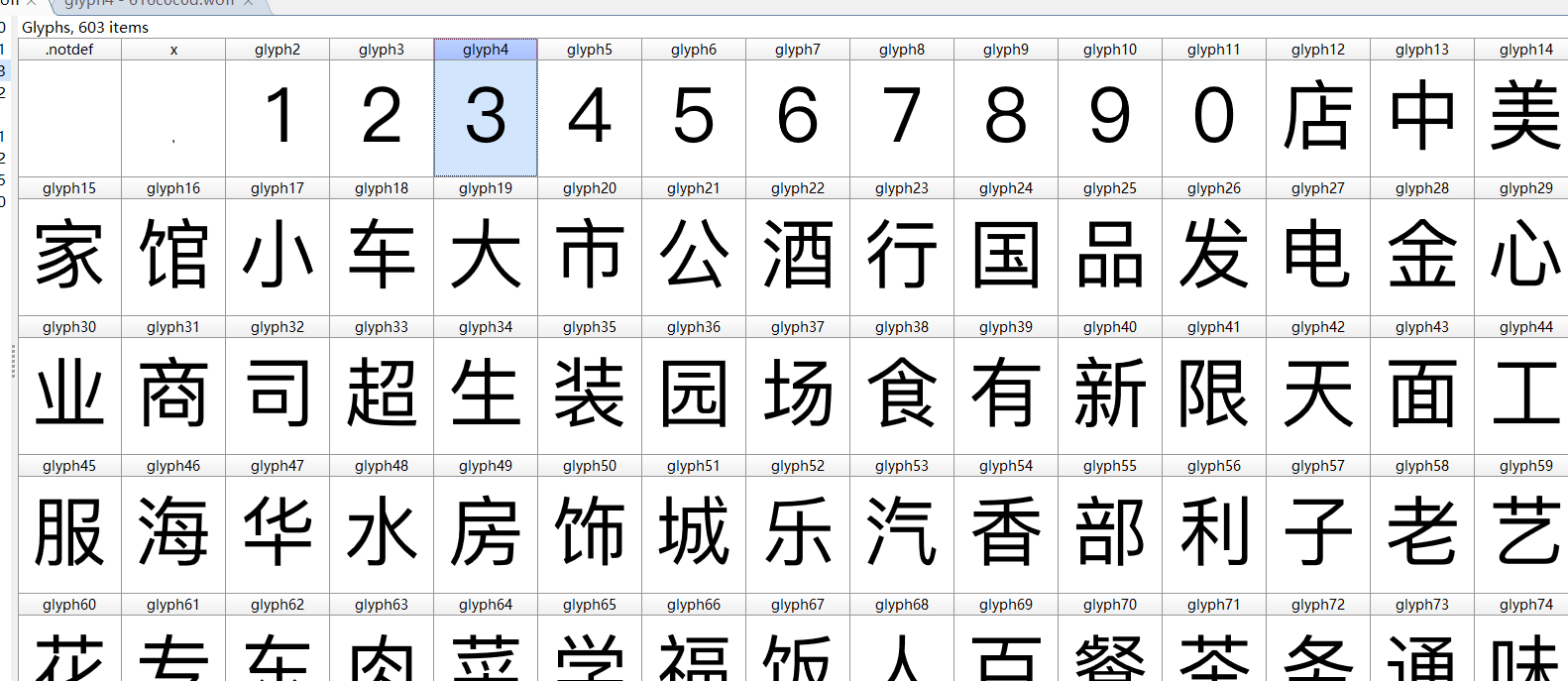
下载下来后,我们使用FontCreator打开
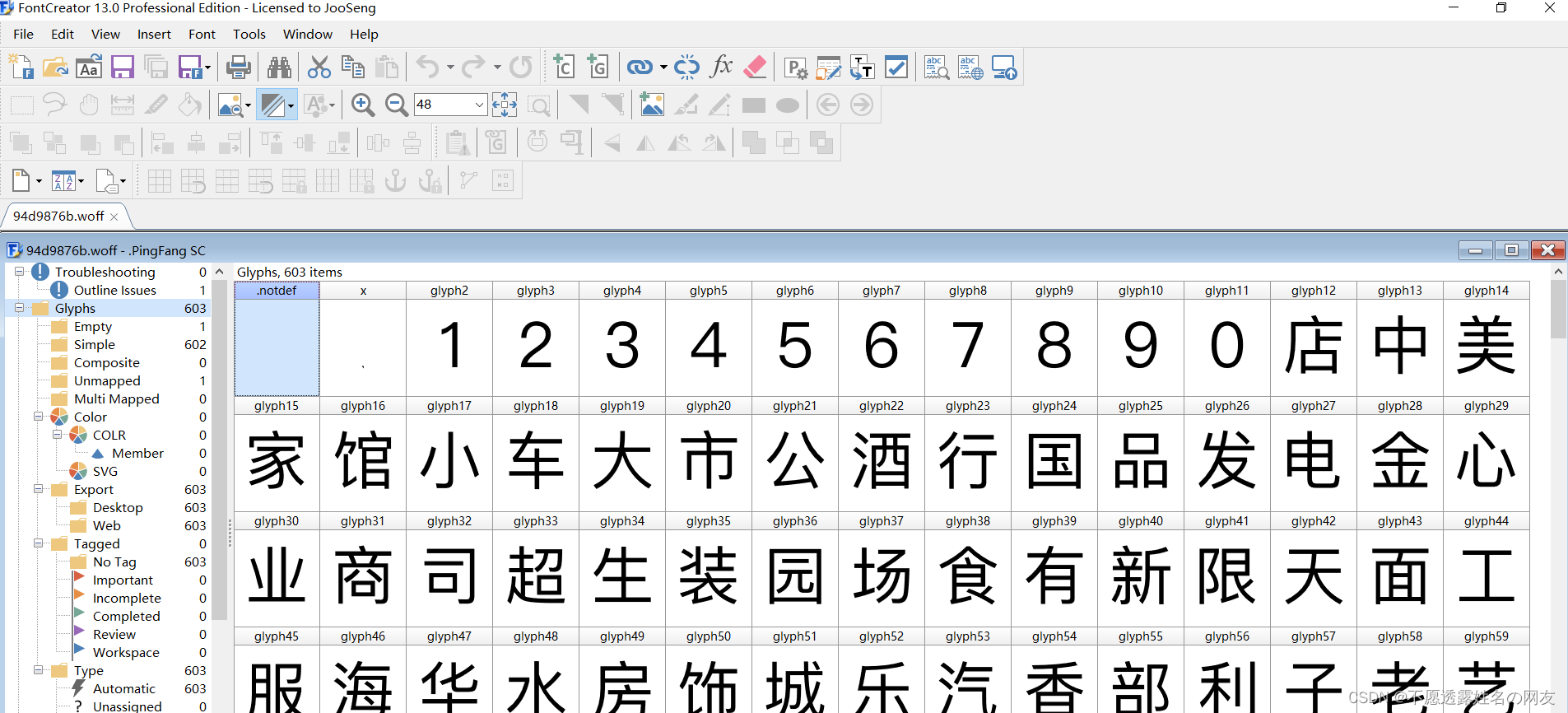
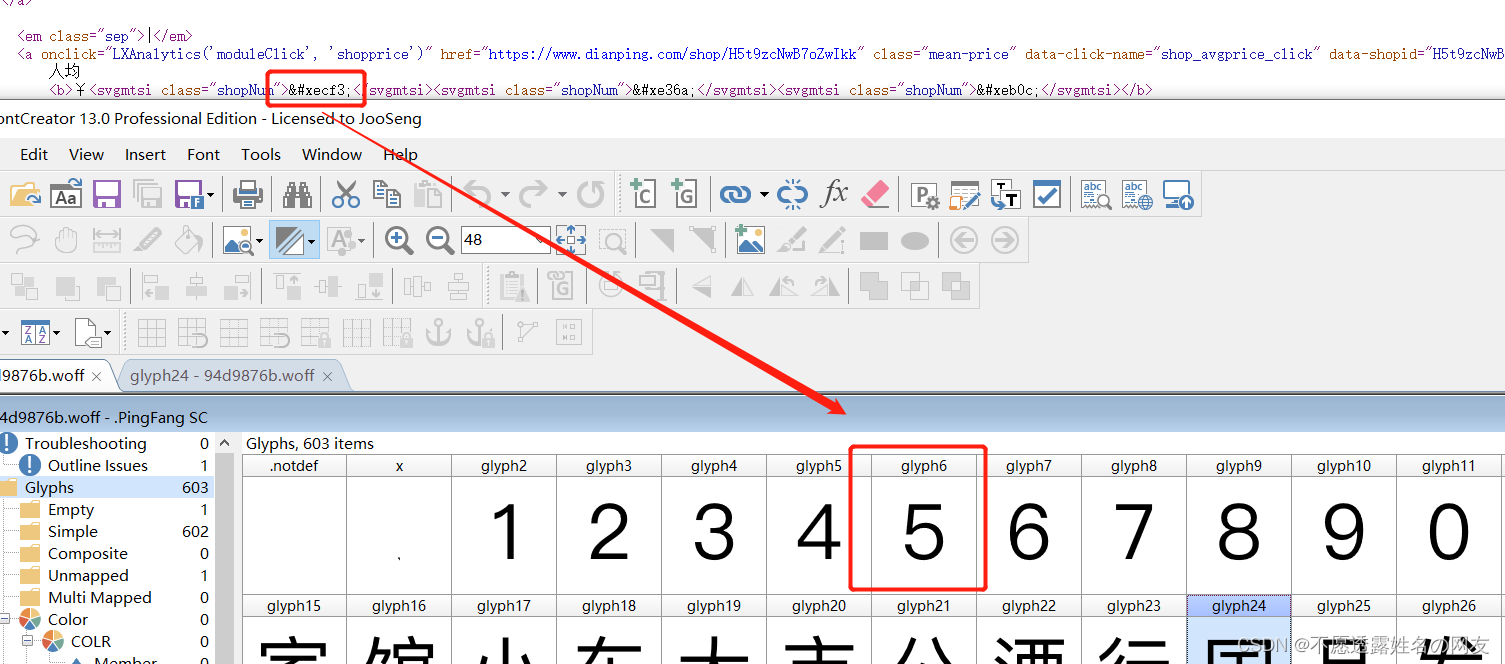
对应页面的数字。页面源码的字符前缀是&#x,woff文件的前缀是uni
二、Python打开字体加密文件
刚才是直观的看到我们的对应关系,但是我们主要是通过python代码,自动的替换加密字体。这个时候就需要借助其他模块来实现。
pip install fontTools
然后一些常见方法见 https://blog.csdn.net/weixin_43411585/article/details/103484643
这里我们演示打开woff格式的文件。文件下载地址
https://www.python-spider.com/static/font/challenge12/aiding.woff
演示代码
from fontTools.ttLib import TTFont
# 加载字体文件
font = TTFont('local.woff')
# 保存为xml文件
font.saveXML('local.xml')
# 获取各节点名称,返回为列表
print(font.keys())
# ['GlyphOrder', 'head', 'hhea', 'maxp', 'OS/2', 'hmtx', 'cmap', 'loca', 'glyf', 'name', 'post', 'GSUB']
# 获取getGlyphOrder节点的name值,返回为列表
print(
font.getGlyphOrder()) # ['glyph00000', 'x', 'uniF013', 'uniF4D4', 'uniEE40', 'uniF7E1', 'uniF34B', 'uniE1A0', 'uniF1BE', 'uniE91E', 'uniF16F', 'uniF724']
print(
font.getGlyphNames()) # ['glyph00000', 'uniE1A0', 'uniE91E', 'uniEE40', 'uniF013', 'uniF16F', 'uniF1BE', 'uniF34B', 'uniF4D4', 'uniF724', 'uniF7E1', 'x']
# 获取cmap节点code与name值映射, 返回为字典
print(
font.getBestCmap()) # {120: 'x', 57760: 'uniE1A0', 59678: 'uniE91E', 60992: 'uniEE40', 61459: 'uniF013', 61807: 'uniF16F', 61886: 'uniF1BE', 62283: 'uniF34B', 62676: 'uniF4D4', 63268: 'uniF724', 63457: 'uniF7E1'}
# 获取glyf节点TTGlyph字体xy坐标信息
print(font['glyf'][
'uniE1A0'].coordinates) # GlyphCoordinates([(50, 335),(50, 468),(76, 544),(95, 638),(148, 676),(202, 710),(282, 710),(402, 710),(459, 617),(487, 574),(504, 501),(520, 437),(519, 335),(520, 271),(508, 166),(494, 126),(466, 46),(362, -39),(282, -49),(176, -35),(115, 37),(43, 121),(43, 335),(135, 335),(135, 154),(177, 95),(229, 35),(282, 35),(343, 35),(385, 107),(428, 155),(428, 339),(428, 515),(385, 576),(344, 635),(286, 635),(218, 635),(179, 583),(135, 506)])
# 获取glyf节点TTGlyph字体xMin,yMin,xMax,yMax坐标信息
print(font['glyf']['uniE1A0'].xMin, font['glyf']['uniE1A0'].yMin,
font['glyf']['uniE1A0'].xMax, font['glyf']['uniE1A0'].yMax) # 0 -49 521 711
# 获取glyf节点TTGlyph字体on信息
print(font['glyf'][
'uniE1A0'].flags) # array('B', [1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0])
# 获取GlyphOrder节点GlyphID的id信息, 返回int型
print(font.getGlyphID('uniE1A0')) # 7
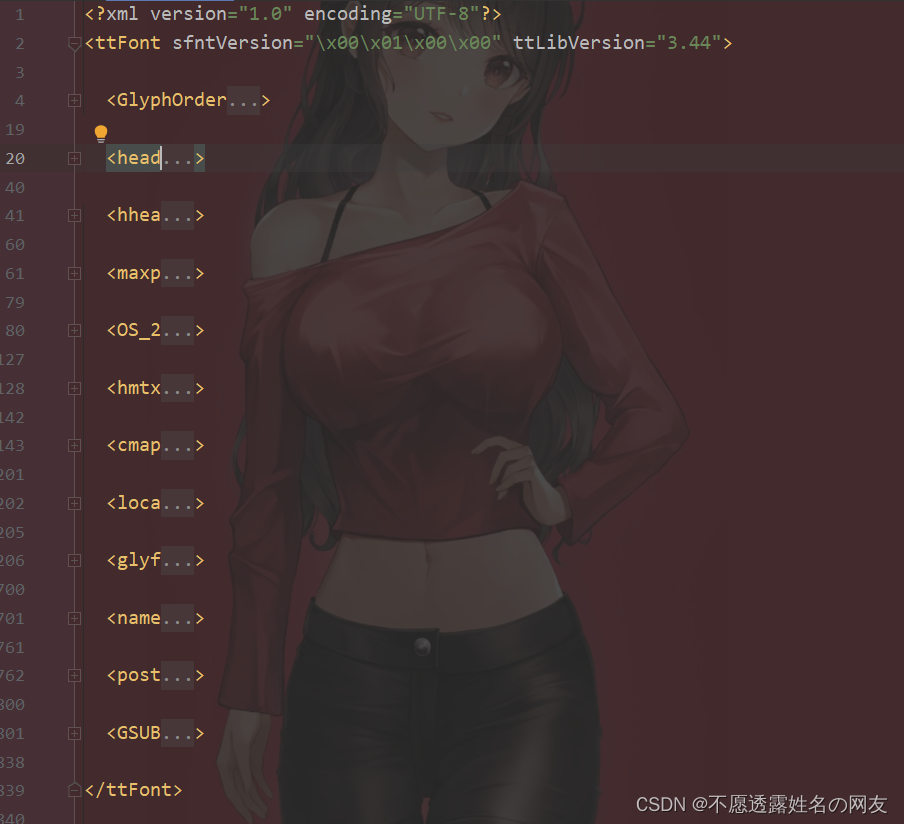
生成的xml文件
三、字体加密的通杀
1.静态的字体文件+固定顺序的字体
这类就是字体文件是固定的,而且坐标不变,字体的顺序也是不变的。这一类我们直接找到映射关系后可以直接写死替换,一劳永逸,也是最简单的字体反爬。
例如从这个网站下载woff文件:https://www.python-spider.com/static/font/challenge12/aiding.woff
,下载完打开woff
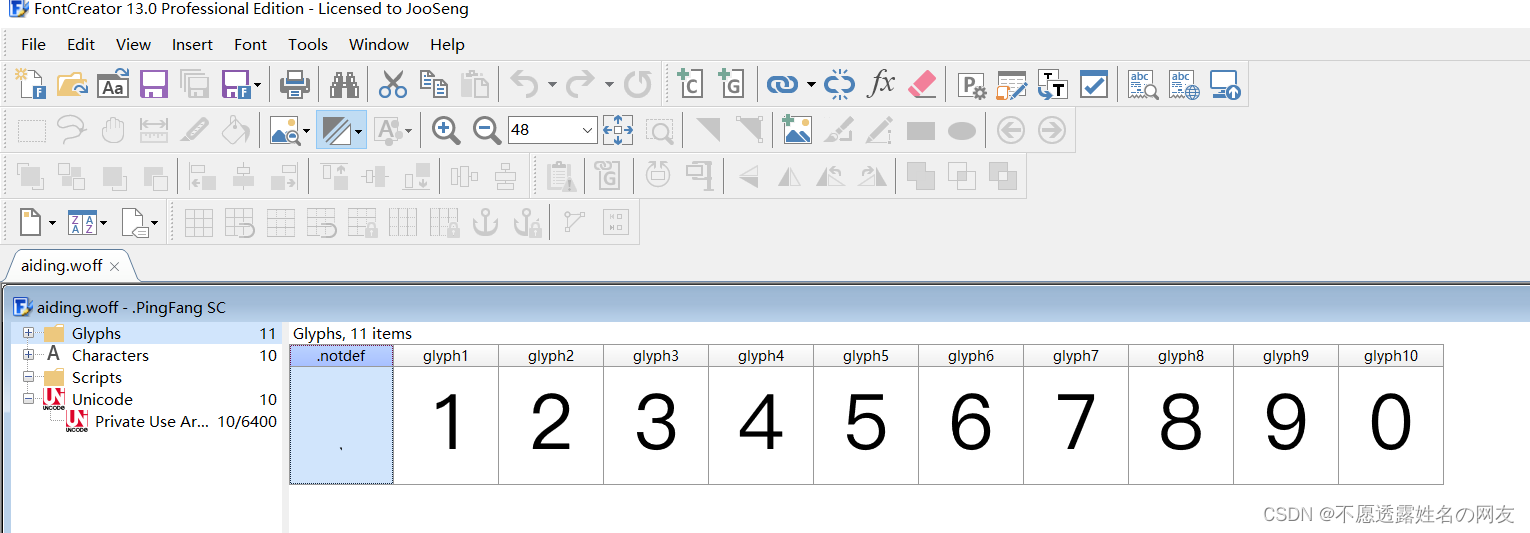
python解析出映射关系,直接replace替换字典
from fontTools.ttLib import TTFont
font = TTFont('./aiding.woff')
font.saveXML('./aiding.xml')
font_names = font.getGlyphOrder()
print(font_names)
woff_dict = {}
for name in font_names[1:]:
woff_dict[name.replace('uni', '&#x')] = font.getGlyphID(name) if font.getGlyphID(name) != 10 else 0
print(woff_dict)

2.其他动态变化情况
这里把不是第一种的统一看成其他
- 动态字体文件+固定字体顺序
- 动态字体文件+动态编码+固定字体信息
- 动态字体文件+动态编码+固定字体信息
- 动态字体文件+动态编码+动态字体信息
这些的解决办法我们现在有一种大佬想的新方案:
传统的方式就是找到目标ttf 文件,人为得映射乱码和真实字符。但是当ttf更新频繁时,人为对照成本就很高了。针对上面的痛点,想了一种成本较低得方法来解决这个问题。通过调研发现Python 的image类是可以加载字体文件的,那结合机器学习文字识别那就可以很轻松的拿到乱码和字体的映射。现在问题是找到一个靠谱的汉字识别模型。对比市面上的汉字识别模型, 最终采用了cnocr 模型。当然使用模型是有准确率的,最终的结果最好还是自己验证一次。
环境安装:
python : 3.8.8
安装cnocr: pip install cnocr
如果报错 :
ERROR: Failed building wheel for Polygon3
直接通过whl 安装Polygon3
https://www.lfd.uci.edu/~gohlke/pythonlibs/#polygon
即在上述链接中 选择 Polygon3-3.0.9.1-cp38-cp38-win_amd64.whl 下载安装即可
在实际执行中发现 cv2找不到 某个函数,不要犹豫,大概率是opencv-python 的差异
建议直接升级到最高版本
pip install --user opencv-python --upgrade
代码演示:
import os
from PIL import ImageFont, Image, ImageDraw
from cnocr import CnOcr
import numpy as np
from fontTools.ttLib import TTFont
import requests
from io import BytesIO
def font_to_img(code_list, filename, ignore_flag=True, score=0.95):
normal_dict = {}
be_padding_dict = {}
ocr = CnOcr()
"""
将字体画成图片
code_list: 加密字符列表
filename: 字体文件
ignore_flag:是否忽视 sorce 返回结果
score: 识别准确率默认 95%以上
"""
for char_list in code_list:
char_code = char_list.encode().decode()
img_size = 1024
img = Image.new('1', (img_size, img_size), 255)
draw = ImageDraw.Draw(img)
font = ImageFont.truetype(filename, int(img_size * 0.7))
x, y = draw.textsize(char_code, font=font)
draw.text(((img_size - x) // 2, (img_size - y) // 2), char_code, font=font, fill=0)
# 将单通道 转为 三通道
img = img.convert("RGB")
# word = ocr.ocr_for_single_line("%s.jpg" % mame_ocr)
word = ocr.ocr_for_single_line(np.array(img))
if word["score"] >= score:
# 处理重复名字
# img.save("%s_%s.jpg" % (char_code, word["text"]))
normal_dict[char_code] = word["text"]
else:
be_padding_dict[char_code] = word
img.save("%s_%s_be_padding.jpg" % (char_code, word["text"]))
if ignore_flag:
normal_dict[char_code] = word["text"]
return normal_dict, be_padding_dict
def ttf_parse(url, ttf_name):
"""
根据url 获取返回值
"""
response = requests.get(url).content
font_parse = TTFont(BytesIO(response))
font_parse.save(ttf_name)
m_dict = font_parse.getBestCmap()
unicode_list = []
for key, _ in m_dict.items():
unicode_list.append(key)
# 获取需要判断的字符
char_list = [chr(ch_unicode) for ch_unicode in unicode_list]
normal_dict, error_dict = font_to_img(char_list, ttf_name)
print(normal_dict)
print(error_dict)
# 删除字体文件
os.remove(ttf_name)
if __name__ == '__main__':
ttf_parse('https://s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/616c0c0d.woff', '1.jpg')
结果:
{'x': '', '\ue006': '其', '\ue00f': '町', '\ue03a': '觉', '\ue042': '意', '\ue055': '串', '\ue05e': '所', '\ue069': '气',
'\ue07e': '3', '\ue083': '跟', '\ue084': '旅', '\ue08f': '际', '\ue0d1': '前', '\ue0dd': '费', '\ue0e5': '清',
'\ue0ee': '成', '\ue0f8': '关', '\ue10b': '宾', '\ue10f': '苑', '\ue11c': '张长', '\ue11e': '楼', '\ue133': '5',
'\ue143': '临', '\ue154': '笑', '\ue159': '凯', '\ue161': '色', '\ue16c': '拍', '\ue177': '少', '\ue17d': '座',
'\ue189': '了', '\ue195': '差', '\ue19c': '房', '\ue1b7': '角', '\ue1be': '着', '\ue1d0': '的', '\ue1ea': '自',
'\ue1ee': '也', '\ue1fc': '要', '\ue20a': '向', '\ue215': '没', '\ue216': '值', '\ue229': '客', '\ue22f': '金',
'\ue236': '营', '\ue23b': '镇', '\ue247': '衣', '\ue24d': '度', '\ue257': '浦', '\ue26f': '啦', '\ue290': '餐',
'\ue29f': '情', '\ue2a0': '让', '\ue2bb': '子', '\ue2c3': '纪', '\ue2d8': '于', '\ue2f3': '路', '\ue2f4': '机',
'\ue2fa': '样', '\ue2fe': '宏', '\ue304': '宝', '\ue336': '横', '\ue337': '因', '\ue338': '人', '\ue33a': '京',
'\ue34b': '找', '\ue34c': '线', '\ue358': '庆', '\ue36b': '真', '\ue374': '同', '\ue376': '排', '\ue379': '造',
'\ue37c': '青', '\ue389': '馆', '\ue38e': '寓', '\ue390': '西', '\ue397': '总', '\ue3a0': '特', '\ue3a4': '带',
'\ue3a7': '校', '\ue3ac': '光', '\ue3ae': '港', '\ue3cf': '春', '\ue3e4': '售', '\ue3f0': '正', '\ue402': '助',
'\ue406': '香', '\ue40b': '适', '\ue416': '做', '\ue425': '容', '\ue42b': '余科', '\ue430': '讯', '\ue435': '面',
'\ue440': '舟受', '\ue445': '锦', '\ue44e': '全', '\ue455': '惠', '\ue463': '玉', '\ue467': '窗', '\ue469': '员',
'\ue487': '代', '\ue488': '学', '\ue492': '我', '\ue495': '都', '\ue498': '9', '\ue49b': '保', '\ue4a0': '铺',
'\ue4a8': '巷', '\ue4ab': '饭', '\ue4ae': '顺', '\ue4b8': '8', '\ue4ba': '内', '\ue4c3': '栋', '\ue4ce': '发',
'\ue4f3': '央', '\ue4f7': '器', '\ue4ff': '酸令', '\ue505': '用', '\ue508': '几', '\ue536': '在', '\ue537': '七',
'\ue53c': '松', '\ue548': '2', '\ue553': '步', '\ue558': '卫', '\ue55e': '古', '\ue55f': '生', '\ue56c': '经',
'\ue583': '杂', '\ue591': '店', '\ue597': '中', '\ue5b4': '嘉', '\ue5c2': '事', '\ue5c4': '庄', '\ue5c9': '艺',
'\ue5d3': '无', '\ue5ec': '有', '\ue609': '然', '\ue60c': '谷', '\ue619': '社', '\ue61d': '专', '\ue634': '农',
'\ue63b': '桌', '\ue63d': '能', '\ue640': '火', '\ue652': '品', '\ue656': '起', '\ue66a': '药', '\ue66b': '喝',
'\ue66c': '每', '\ue673': '强', '\ue678': '公', '\ue688': '酱', '\ue697': '车', '\ue69b': '接', '\ue6a2': '富',
'\ue6a7': '式', '\ue6a8': '江', '\ue6ac': '这', '\ue6ae': '美', '\ue6b4': '销', '\ue6b7': '算', '\ue6bd': '打',
'\ue6e4': '景', '\ue6f2': '且', '\ue724': '材', '\ue730': '湾', '\ue744': '修', '\ue74c': '制', '\ue755': '文',
'\ue756': '诚', '\ue758': '方', '\ue75a': '司', '\ue76e': '利', '\ue778': '泉', '\ue78d': '名', '\ue792': '东',
'\ue795': '超', '\ue797': '底', '\ue7a0': '六', '\ue7ad': '字', '\ue7ba': '走', '\ue7be': '个', '\ue7c7': '钢',
'\ue7d9': '是', '\ue7e4': '岭', '\ue7ff': '博', '\ue80d': '影', '\ue818': '完', '\ue829': '妆', '\ue831': '不',
'\ue838': '更', '\ue848': '比', '\ue849': '赞', '\ue856': '候', '\ue85b': '安', '\ue85c': '院', '\ue85d': '便',
'\ue862': '麻', '\ue864': '元', '\ue870': '坊', '\ue88c': '福', '\ue88d': '天', '\ue897': '心', '\ue89e': '太',
'\ue8ad': '6', '\ue8b9': '与', '\ue8ce': '弄', '\ue8e2': '试', '\ue8ed': '限良', '\ue90d': '康', '\ue916': '省',
'\ue917': '兴', '\ue91a': '管', '\ue920': '0', '\ue92a': '地', '\ue934': '银', '\ue941': '可', '\ue959': '时',
'\ue967': '风', '\ue97e': '海', '\ue981': '但', '\ue989': '吉', '\ue990': '堂', '\ue996': '理', '\ue99e': '达',
'\ue9a3': '胜', '\ue9b8': '年', '\ue9bb': '叉', '\ue9c0': '4', '\ue9ca': '网', '\ue9cc': '层', '\ue9de': '八',
'\ue9e0': '粉', '\ue9e5': '上', '\ue9e6': '去', '\ue9ea': '处', '\ue9f1': '童', '\ue9fa': '性', '\uea01': '种',
'\uea09': '量', '\uea0d': '彩', '\uea12': '健', '\uea27': '连', '\uea3b': '府', '\uea45': '湖', '\uea4f': '第',
'\uea56': '厂', '\uea59': '较', '\uea6f': '贸', '\uea7c': '错', '\uea7f': '木', '\uea84': '段', '\uea98': '城',
'\ueaa6': '门', '\ueaa7': '工', '\ueaab': '出', '\ueab1': '昌', '\ueabe': '重', '\ueac8': '日', '\uead0': '份',
'\ueadc': '计', '\ueadd': '育', '\ueae2': '型', '\ueaf3': '矢口', '\ueafd': '三', '\ueb02': '产', '\ueb11': '泰',
'\ueb1b': '停', '\ueb1d': '多', '\ueb3f': '汇', '\ueb49': '杨', '\ueb5a': '务', '\ueb64': '解', '\ueb67': '会',
'\ueb6f': '斯', '\ueb75': '1', '\ueb8e': '果', '\uebb1': '训', '\uebbf': '部', '\uebfa': '振', '\uebfe': '汽',
'\uec04': '贝', '\uec07': '盛', '\uec0b': '干', '\uec10': '沙', '\uec14': '放', '\uec1d': '奶', '\uec1f': '双',
'\uec23': '维', '\uec29': '源', '\uec2f': '汉', '\uec4e': '武', '\uec54': '一', '\uec5d': '州', '\uec5e': '屋',
'\uec6e': '养', '\uec6f': '选', '\uec83': '下', '\uec84': '和', '\uec9f': '边', '\ueca0': '星', '\uecb4': '开',
'\uecbc': '买', '\uecbf': '瑞', '\uecce': '欢', '\uecd5': '石', '\uecd9': '医', '\uecda': '包', '\uecdd': '鑫',
'\uecde': '爱', '\uece2': '以', '\ueceb': '家', '\uecf4': '迎', '\uecf6': '朝月', '\ued05': '很', '\ued09': '团',
'\ued15': '饼', '\ued28': '快', '\ued2d': '明月', '\ued32': '祥', '\ued3b': '岗', '\ued4d': '周', '\ued6c': '活',
'\ued7d': '服', '\ued89': '米', '\ued8a': '7', '\ued8e': '实', '\ued98': '四', '\ueda2': '马', '\uedb1': '鸡',
'\uedc3': '桂', '\uedce': '作', '\uedd0': '棒', '\uedd8': '鞋', '\ueddd': '井', '\uede1': '记', '\uedf0': '微',
'\uedf7': '黄', '\uedfb': '氏', '\uee16': '之', '\uee1a': '手', '\uee20': '还', '\uee24': '加', '\uee34': '尚',
'\uee38': '力', '\uee44': '间', '\uee52': '才', '\uee56': '当', '\uee59': '评', '\uee73': '教', '\uee80': '境',
'\uee81': '卖', '\uee9a': '近', '\uee9d': '酒', '\uee9e': '吧', '\ueeb0': '汤', '\ueebe': '头', '\ueec1': '鸿',
'\ueec3': '室', '\ueec7': '世', '\ueecf': '德', '\ueed0': '热', '\ueef2': '看', '\uef13': '块', '\uef3c': '等',
'\uef46': '龙', '\uef4b': '桥', '\uef57': '津', '\uef61': '滨', '\uef62': '局', '\uef64': '副', '\uef6f': '别',
'\uef81': '旁', '\uef8b': '拉', '\uef8d': '体', '\uef8f': '万', '\uef90': '台', '\uefad': '十', '\uefae': '分',
'\uefbd': '布', '\uefc4': '片牌', '\uefec': '办', '\uefee': '兰', '\ueff2': '山', '\ueff8': '单', '\uf00a': '料',
'\uf01d': '回', '\uf01e': '园', '\uf020': '洗', '\uf034': '大', '\uf03f': '妇', '\uf042': '又', '\uf055': '蛋',
'\uf05d': '烟', '\uf067': '行', '\uf069': '珠', '\uf081': '原', '\uf092': '南', '\uf0ab': '置', '\uf0b8': '后',
'\uf0ba': '位', '\uf0bd': '配', '\uf0d0': '哈', '\uf0d4': '里', '\uf0d8': '丰', '\uf0dc': '皮', '\uf0e3': '想',
'\uf0e4': '乡', '\uf0f9': '站', '\uf10a': '而', '\uf11c': '电', '\uf11e': '对', '\uf136': '峰', '\uf138': '云',
'\uf14d': '凤', '\uf155': '厅', '\uf15a': '阿', '\uf15f': '刚', '\uf16a': '水', '\uf187': '丁', '\uf18a': '他',
'\uf18c': '次', '\uf18e': '主', '\uf194': '来', '\uf199': '像', '\uf1af': '整', '\uf1b0': '道', '\uf1b1': '百',
'\uf1ce': '区', '\uf1ee': '小', '\uf1f4': '铁', '\uf1fa': '培', '\uf20a': '环', '\uf211': '羊', '\uf22d': '感',
'\uf237': '们', '\uf243': '那', '\uf244': '嫩', '\uf248': '点', '\uf250': '红', '\uf252': '购', '\uf261': '片',
'\uf272': '批', '\uf282': '虾', '\uf289': '长', '\uf28d': '村', '\uf291': '果', '\uf29b': '如', '\uf2bc': '就',
'\uf2c2': '信', '\uf2cb': '荣', '\uf2d3': '队人', '\uf2df': '塘', '\uf2ef': '紫', '\uf2fb': '糕', '\uf2fe': '虫工',
'\uf309': '锅', '\uf30c': '口', '\uf31b': '味末', '\uf325': '过', '\uf329': '陵', '\uf32b': '饰', '\uf32d': '商',
'\uf336': '食', '\uf33f': '甜', '\uf349': '态', '\uf34d': '友', '\uf35f': '女', '\uf362': '九', '\uf365': '货',
'\uf36b': '合', '\uf373': '入', '\uf375': '幢童', '\uf393': '秀', '\uf396': '洲', '\uf3a1': '得', '\uf3a8': '绿',
'\uf3bf': '永', '\uf3c1': '高', '\uf400': '价', '\uf41f': '五', '\uf422': '板', '\uf428': '挺', '\uf42d': '好',
'\uf431': '老', '\uf438': '荐', '\uf443': '溪', '\uf45f': '业', '\uf462': '话', '\uf478': '术', '\uf49e': '二',
'\uf4a0': '居', '\uf4a4': '科', '\uf4b0': '尔', '\uf4db': '街', '\uf4ec': '动', '\uf4fd': '市', '\uf50f': '佳',
'\uf516': '非', '\uf51c': '厦', '\uf53d': '满', '\uf540': '塔', '\uf548': '幼', '\uf555': '政', '\uf55d': '本',
'\uf57f': '些', '\uf590': '轩', '\uf594': '尝', '\uf5a2': '鱼', '\uf5ac': '最', '\uf5bd': '王', '\uf5c7': '定',
'\uf5de': '附', '\uf5e8': '说', '\uf5ec': '联', '\uf5f4': '进', '\uf5f6': '技', '\uf5f7': '外', '\uf5f8': '华',
'\uf5fa': '级', '\uf602': '沿', '\uf603': '安束', '\uf606': '济', '\uf630': '丽', '\uf632': '吃', '\uf63e': '烤',
'\uf653': '期', '\uf655': '集', '\uf668': '牛', '\uf670': '岛', '\uf67c': '直', '\uf68d': '化', '\uf691': '北',
'\uf698': '午', '\uf69d': '民', '\uf6b9': '鲜羊', '\uf6cd': '川', '\uf6d0': '油', '\uf6d8': '现', '\uf6f1': '隆',
'\uf6f7': '己', '\uf6f8': '鸭', '\uf702': '田', '\uf712': '广', '\uf715': '柳', '\uf71d': '阿', '\uf722': '场',
'\uf727': '花', '\uf72c': '甲', '\uf735': '调', '\uf746': '国', '\uf759': '肉', '\uf75f': '格', '\uf764': '精',
'\uf778': '豆', '\uf779': '雅', '\uf780': '阳', '\uf78f': '师', '\uf7a7': '推', '\uf7ac': '为', '\uf7ad': '提',
'\uf7b2': '旗', '\uf7b6': '建', '\uf7b7': '什', '\uf7c8': '平', '\uf7d0': '具', '\uf7d6': '号', '\uf7d7': '侧',
'\uf7d9': '到', '\uf7e1': '梅', '\uf7f0': '茶', '\uf7f3': '设', '\uf7f6': '晚', '\uf803': '白', '\uf805': '莲',
'\uf813': '只', '\uf814': '运', '\uf816': '给', '\uf821': '恒', '\uf824': '菜', '\uf838': '么', '\uf843': '足',
'\uf84d': '你', '\uf853': '厨', '\uf85c': '烫', '\uf85f': '喜', '\uf867': '装', '\uf86c': '两', '\uf87d': '物',
'\uf884': '河', '\uf888': '再', '\uf891': '交', '\uf89c': '朋', '\uf8c7': '常', '\uf8ca': '烧', '\uf8cf': '宁',
'\uf8d7': '乐', '\uf8e1': '林', '\uf8ee': '通', '\uf8f9': '县', '\uf8fb': '儿', '\uf8fe': '新'}
以评分95% 做分割 ,下面是可能不对的,经过对比图片发现没有错误。只是评分较低。
{'\ue05e': {'text': '所', 'score': 0.7101963758468628}, '\ue069': {'text': '气', 'score': 0.8201217651367188},
'\ue07e': {'text': '3', 'score': 0.9448353052139282}, '\ue08f': {'text': '际', 'score': 0.8827687501907349},
'\ue0dd': {'text': '费', 'score': 0.9348242282867432}, '\ue11c': {'text': '张长', 'score': 0.8512042164802551},
'\ue133': {'text': '5', 'score': 0.8904429078102112}, '\ue154': {'text': '笑', 'score': 0.9278842210769653},
'\ue159': {'text': '凯', 'score': 0.9020307064056396}, '\ue161': {'text': '色', 'score': 0.6160538196563721},
'\ue17d': {'text': '座', 'score': 0.9377821683883667}, '\ue189': {'text': '了', 'score': 0.9472777843475342},
'\ue1b7': {'text': '角', 'score': 0.9137881398200989}, '\ue1be': {'text': '着', 'score': 0.9061774611473083},
'\ue29f': {'text': '情', 'score': 0.6765124201774597}, '\ue3f0': {'text': '正', 'score': 0.9489812254905701},
'\ue406': {'text': '香', 'score': 0.9193495512008667}, '\ue42b': {'text': '余科', 'score': 0.31485822796821594},
'\ue430': {'text': '讯', 'score': 0.7896761894226074}, '\ue440': {'text': '舟受', 'score': 0.4272177815437317},
'\ue445': {'text': '锦', 'score': 0.93426513671875}, '\ue495': {'text': '都', 'score': 0.9491526484489441},
'\ue498': {'text': '9', 'score': 0.9058276414871216}, '\ue4ae': {'text': '顺', 'score': 0.8457756638526917},
'\ue4b8': {'text': '8', 'score': 0.745848536491394}, '\ue4ff': {'text': '酸令', 'score': 0.23059628903865814},
'\ue536': {'text': '在', 'score': 0.9107916355133057}, '\ue53c': {'text': '松', 'score': 0.8348405957221985},
'\ue548': {'text': '2', 'score': 0.7965168356895447}, '\ue5c2': {'text': '事', 'score': 0.9056740999221802},
'\ue61d': {'text': '专', 'score': 0.780048131942749}, '\ue640': {'text': '火', 'score': 0.901986300945282},
'\ue673': {'text': '强', 'score': 0.9025680422782898}, '\ue6a7': {'text': '式', 'score': 0.9470093846321106},
'\ue6ae': {'text': '美', 'score': 0.9245206713676453}, '\ue6e4': {'text': '景', 'score': 0.5590194463729858},
'\ue74c': {'text': '制', 'score': 0.7929206490516663}, '\ue755': {'text': '文', 'score': 0.9355360269546509},
'\ue756': {'text': '诚', 'score': 0.9329637289047241}, '\ue758': {'text': '方', 'score': 0.9357324242591858},
'\ue76e': {'text': '利', 'score': 0.7340298891067505}, '\ue7e4': {'text': '岭', 'score': 0.6351971626281738},
'\ue7ff': {'text': '博', 'score': 0.9468564987182617}, '\ue848': {'text': '比', 'score': 0.8979260325431824},
'\ue849': {'text': '赞', 'score': 0.8741719126701355}, '\ue856': {'text': '候', 'score': 0.7024070024490356},
'\ue85d': {'text': '便', 'score': 0.61191725730896}, '\ue897': {'text': '心', 'score': 0.9427058100700378},
'\ue8ad': {'text': '6', 'score': 0.7724475860595703}, '\ue8ed': {'text': '限良', 'score': 0.8311377763748169},
'\ue920': {'text': '0', 'score': 0.5414958000183105}, '\ue92a': {'text': '地', 'score': 0.47658202052116394},
'\ue967': {'text': '风', 'score': 0.9264501929283142}, '\ue9c0': {'text': '4', 'score': 0.8089628219604492},
'\ue9de': {'text': '八', 'score': 0.4221823215484619}, '\ue9e6': {'text': '去', 'score': 0.9465771317481995},
'\ue9ea': {'text': '处', 'score': 0.729453444480896}, '\ue9f1': {'text': '童', 'score': 0.8890518546104431},
'\ue9fa': {'text': '性', 'score': 0.8406746983528137}, '\uea01': {'text': '种', 'score': 0.9463455677032471},
'\uea0d': {'text': '彩', 'score': 0.9497383832931519}, '\uea56': {'text': '厂', 'score': 0.9360781311988831},
'\ueaa6': {'text': '门', 'score': 0.9319864511489868}, '\ueab1': {'text': '昌', 'score': 0.8610723614692688},
'\ueaf3': {'text': '矢口', 'score': 0.9479916095733643}, '\ueafd': {'text': '三', 'score': 0.9098818302154541},
'\ueb1d': {'text': '多', 'score': 0.9341955780982971}, '\ueb3f': {'text': '汇', 'score': 0.926189661026001},
'\ueb6f': {'text': '斯', 'score': 0.9391093254089355}, '\ueb8e': {'text': '果', 'score': 0.39117464423179626},
'\uebb1': {'text': '训', 'score': 0.9340453743934631}, '\uec0b': {'text': '干', 'score': 0.5374392867088318},
'\uec4e': {'text': '武', 'score': 0.9499560594558716}, '\uec54': {'text': '一', 'score': 0.8632733821868896},
'\uec83': {'text': '下', 'score': 0.9410864114761353}, '\ueca0': {'text': '星', 'score': 0.9497742056846619},
'\uecf6': {'text': '朝月', 'score': 0.8974940776824951}, '\ued2d': {'text': '明月', 'score': 0.5373875498771667},
'\ued7d': {'text': '服', 'score': 0.4188182055950165}, '\ued8a': {'text': '7', 'score': 0.7986817359924316},
'\uedb1': {'text': '鸡', 'score': 0.6929422616958618}, '\uedce': {'text': '作', 'score': 0.6247490644454956},
'\ueddd': {'text': '井', 'score': 0.9002070426940918}, '\uee1a': {'text': '手', 'score': 0.9290779829025269},
'\uee24': {'text': '加', 'score': 0.9063721895217896}, '\uee9e': {'text': '吧', 'score': 0.9220173358917236},
'\ueec7': {'text': '世', 'score': 0.925752580165863}, '\ueecf': {'text': '德', 'score': 0.9239265322685242},
'\uef64': {'text': '副', 'score': 0.9384047985076904}, '\uef6f': {'text': '别', 'score': 0.8920194506645203},
'\uefad': {'text': '十', 'score': 0.8840975165367126}, '\uefc4': {'text': '片牌', 'score': 0.4957613945007324},
'\uf03f': {'text': '妇', 'score': 0.8898952007293701}, '\uf042': {'text': '又', 'score': 0.8956716656684875},
'\uf05d': {'text': '烟', 'score': 0.8573434948921204}, '\uf069': {'text': '珠', 'score': 0.75028395652771},
'\uf0bd': {'text': '配', 'score': 0.7989603877067566}, '\uf0d8': {'text': '丰', 'score': 0.7629039883613586},
'\uf0e4': {'text': '乡', 'score': 0.7125524878501892}, '\uf10a': {'text': '而', 'score': 0.9461195468902588},
'\uf136': {'text': '峰', 'score': 0.9324420690536499}, '\uf14d': {'text': '凤', 'score': 0.8371238708496094},
'\uf15f': {'text': '刚', 'score': 0.8563844561576843}, '\uf1ee': {'text': '小', 'score': 0.6941447257995605},
'\uf20a': {'text': '环', 'score': 0.8093100786209106}, '\uf211': {'text': '羊', 'score': 0.817395806312561},
'\uf22d': {'text': '感', 'score': 0.9368784427642822}, '\uf237': {'text': '们', 'score': 0.9287102818489075},
'\uf244': {'text': '嫩', 'score': 0.7814606428146362}, '\uf29b': {'text': '如', 'score': 0.32676398754119873},
'\uf2d3': {'text': '队人', 'score': 0.5490540862083435}, '\uf2fe': {'text': '虫工', 'score': 0.5634275674819946},
'\uf309': {'text': '锅', 'score': 0.8993457555770874}, '\uf31b': {'text': '味末', 'score': 0.24660344421863556},
'\uf32b': {'text': '饰', 'score': 0.6643277406692505}, '\uf375': {'text': '幢童', 'score': 0.3151859641075134},
'\uf3a8': {'text': '绿', 'score': 0.7714439034461975}, '\uf42d': {'text': '好', 'score': 0.8344385027885437},
'\uf45f': {'text': '业', 'score': 0.7493254542350769}, '\uf49e': {'text': '二', 'score': 0.8919293284416199},
'\uf4ec': {'text': '动', 'score': 0.6594783663749695}, '\uf50f': {'text': '佳', 'score': 0.8723465204238892},
'\uf516': {'text': '非', 'score': 0.9436918497085571}, '\uf5ec': {'text': '联', 'score': 0.5172083973884583},
'\uf603': {'text': '安束', 'score': 0.613476037979126}, '\uf630': {'text': '丽', 'score': 0.9419771432876587},
'\uf653': {'text': '期', 'score': 0.9299824237823486}, '\uf668': {'text': '牛', 'score': 0.643532931804657},
'\uf67c': {'text': '直', 'score': 0.9217656850814819}, '\uf6b9': {'text': '鲜羊', 'score': 0.7307806015014648},
'\uf6f8': {'text': '鸭', 'score': 0.7272024750709534}, '\uf712': {'text': '广', 'score': 0.9106811285018921},
'\uf715': {'text': '柳', 'score': 0.8577496409416199}, '\uf722': {'text': '场', 'score': 0.6829107403755188},
'\uf72c': {'text': '甲', 'score': 0.9237180948257446}, '\uf735': {'text': '调', 'score': 0.9441312551498413},
'\uf78f': {'text': '师', 'score': 0.8918313980102539}, '\uf7b7': {'text': '什', 'score': 0.6794707179069519},
'\uf803': {'text': '白', 'score': 0.949399471282959}, '\uf805': {'text': '莲', 'score': 0.939042866230011},
'\uf814': {'text': '运', 'score': 0.9052926301956177}, '\uf838': {'text': '么', 'score': 0.9014909863471985},
'\uf888': {'text': '再', 'score': 0.9475842714309692}, '\uf8fb': {'text': '儿', 'score': 0.8162266612052917}}