文章目录
- 1 概念
- 1.1 组件
- 1.2 插件
- 1.3 术语
- 1.4 Pod类型
- 1.4.1 RS
- 1.4.2 Deployment
- 1.4.3 DaemonSet
- 1.4.4 Job & CronJob
- 1.5 service服务发现
- 1.5.1 ipvs代理模式
- 1.5.2 Service实验
- 1.5.3 Ingress
- 1.6 网络空间
- 1.7 资源
- 1.8 容器生命周期
- 1.8.1 容器hook
- 1.8.2 Pod状态含义
1 概念
k8s用于大规模部署和运维容器
优点:
- 自动部署
- 自动修复
- 水平扩展
- 服务发现
- 滚动更新
- 版本回退
- 密钥配置管理(类似热部署)
- 存储编排(持久化)
- 批处理(定时任务)
1.1 组件
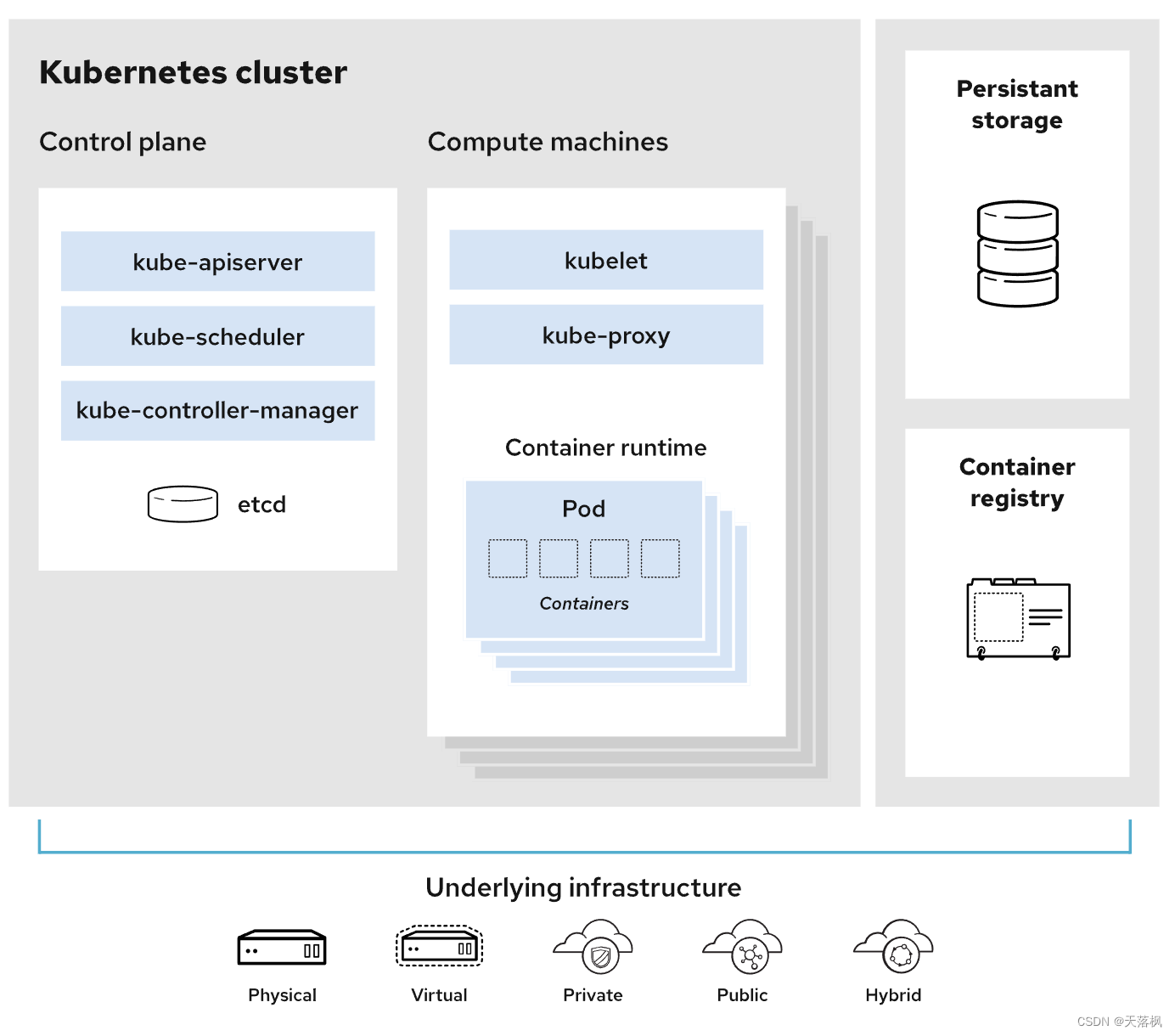
master:主节点,其下包含:
- api server:Kubernetes 控制平面的前端,用于处理内部和外部请求,所有服务访问的统一入口
- controller manager:处理后台任务,资源控制,控制器负责实际运行集群,维持副本期望数目
- scheduler:节点调度,选择node节点部署应用,检测集群和节点状态
- etcd:用于存储集群中的相关数据,键值对
worker node:工作节点,其下包含:
- kubelet:类似于node节点的agent,管理当前节点的容器,管理容器生命周期
- kube proxy:提供网络上的代理,实现负载均衡等功能,写入iptables、ipvs等端口映射
1.2 插件
CoreDNS:为集群中的SVC创建一个域名IP的对应解析
Dashboard:给集群提供一个B/S访问体系
Ingress Controller:官方只有四成代理,ingress可以实现七层代理
Federation:提供一个跨集群中心多k8s统一管理
Prometheus:提供集群监控
elk:提供日志分析
1.3 术语
主机(Master): 用于控制 Kubernetes 节点的计算机。所有任务分配都来自于此。
节点(Node):负责执行请求和所分配任务的计算机。由 Kubernetes 主机负责对节点进行控制。
容器集(Pod):被部署在单个节点上的,且包含一个或多个容器的容器组。同一容器集中的所有容器共享同一个 IP 地址、IPC、主机名称及其它资源。容器集会将网络和存储从底层容器中抽象出来。这样,您就能更加轻松地在集群中移动容器。
复制控制器(Replication controller):用于控制应在集群某处运行的完全相同的容器集副本数量。
服务(Service):将工作内容与容器集分离。Kubernetes 服务代理会自动将服务请求分发到正确的容器集——无论这个容器集会移到集群中的哪个位置,甚至可以被替换掉。
Kubelet:运行在节点上的服务,可读取容器清单(container manifest),确保指定的容器启动并运行。
kubectl: Kubernetes 的命令行配置工具。
1.4 Pod类型
Pod分为:
- 自主式:Pod推出了,不会被创建
- 控制器管理的:在控制器的生命周期中,始终要维持Pod副本数
一个pod默认启动时会创建一个初始容器:pause,其余在该pod上的容器会公用pause的【网络栈】和【存储卷】,即一个pod中的容器的端口不能冲突
pod中有多种控制器:
- ReplicationController(RC):确保容器副本数保持在用户定义的数量,容器异常会自动回收并创建新的(现在建议使用RS取代RC,RC已淘汰)
- ReplicaSet(RS):功能和RC一样,支持集合式的selector,打标签
- Deployment:RC独立使用不如使用Deployment来管理好用,可以无需担心兼容问题,如RS不支持rolling-update,但是Deployment支持,通过声明式语法来定义和管理Pod,提供滚动升级、扩容缩容、暂停和继续
- DaemonSet:每个DeamonSet都会确保全部或部分Node上只运行归他管理的【一个】Pod,新增的Node会自动创建一个Pod,删除的Node会自动回收Pod,删除DaemonSet会删除所有其创建的Pod。
- Job:负责批处理任务,只执行一次,确保正常退出(可配置),没成功会重新创建执行
- CronJob:通过定时创建Job进行管理Pod,周期性的执行,定时(集群版本>1.8,之前的集群可以通过启动api server时传递:
--runtime-config=batch/v2alpha1=true开启) - StatefullSet:为了解决有状态服务的问题,使用场景:
- 1 稳定持久化存储,重新调度数据部会丢失(基于PVC);
- 2 稳定网络标识,重新调度PodName和HostName不变(基于Headless Service即无集群IP的Service实现);
- 3 有序部署,前一个running和ready才部署下一个(基于init c);
- 4 有序收缩
HPA:平滑扩展,仅适用于Deployment和RS,在v1中支持根据pod的cpu利用率扩容,后面版本支持根据内存和其他值标扩缩容,通过控制控制器来对Pod进行管理,需要提供一个资源控制方案才可以进行控制
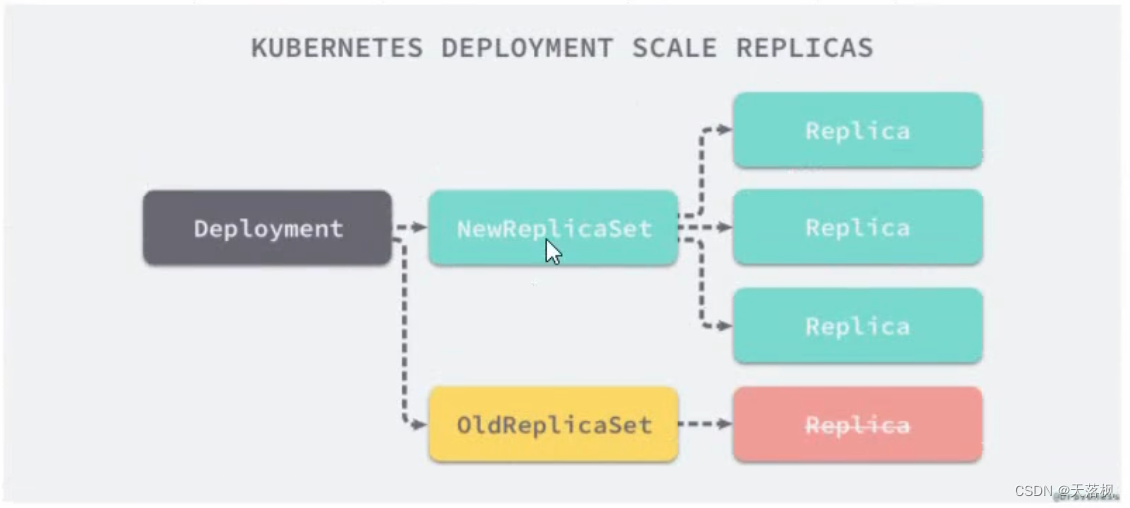
Deployment:会通过创建RS,达到管理Pod的能力,滚动更新机制是,创建新的RS,新RS创建新Pod,旧RS删除旧Pod,以此过渡,最终旧RS停用(不删除),回滚时,旧RS启动流程一样
HPA:比如通过监听CPU>80,则创建新的pod,直到指定上限,使用率下来后会减少pod,直到下限
DaemonSet:常用于在每个Node上都要有一个的服务:1 运行集群存储;2 运行日志收集;3 运行监控
CronJob:常用于数据库备份、发送邮件
StatefullSet:该控制器对MySQL依然不太稳定,MongoDB比较稳定
对于RS创建出来的Pod,如果选择方式为:matchLabels,那改变创建出来的Pod的label,则RS会重新创建一个原来label的Pod,因为RS按照选择方式去控制Pod数量,被改变的那个Pod则不归RS管了
1.4.1 RS
RS测试样例:
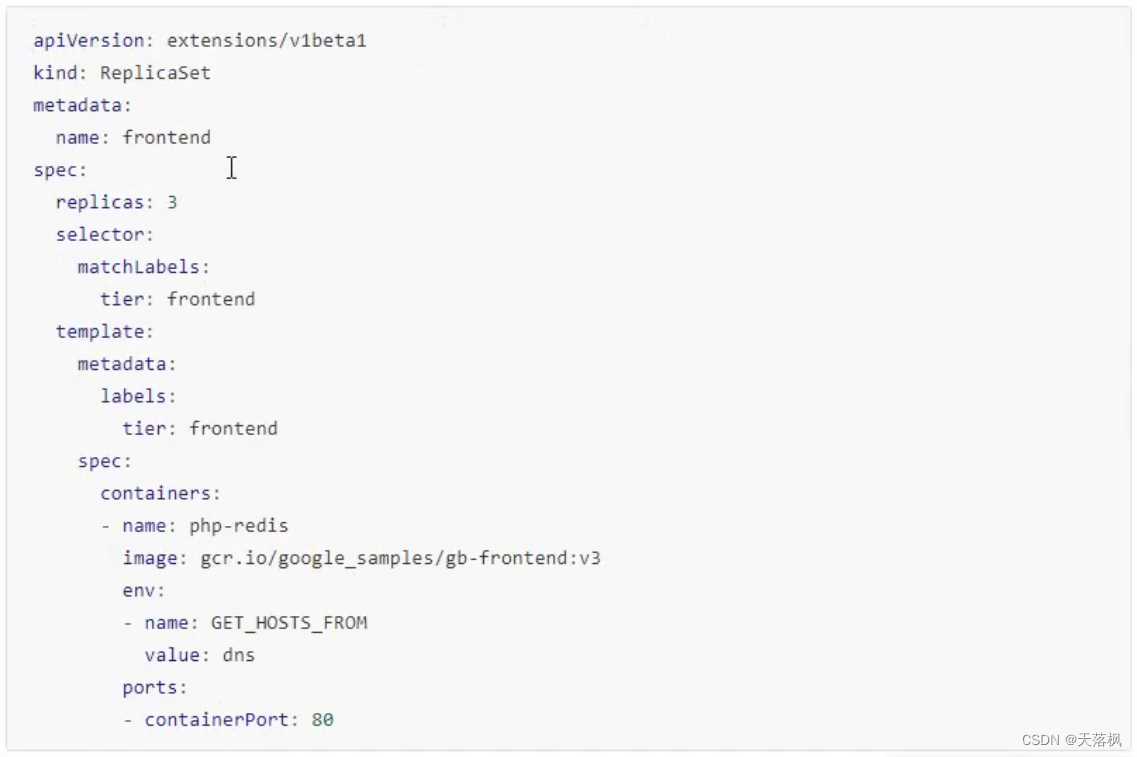
末尾的containerPort可写可不写,因为内部网络所有端口都可以访问,extensions/v1beta1可以改成apps/v1,查看apiVersion可以:kubectl api-resources |grep Deployment
1.4.2 Deployment
Deployment与RS关系:
Deployment测试样例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-dep
spec:
replicas: 3
selector:
matchLabels:
name: nginx
template:
metadata:
labels:
name: nginx
spec:
containers:
- name: mynginx
image: nginx
[root@master ~]# kubectl apply -f deployment-nginx.yaml --record
deployment.apps/nginx-dep created
[root@master ~]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-dep 1/3 3 1 15s
[root@master ~]# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-dep-fbd97f5b7 3 3 1 22s
[root@master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-dep-fbd97f5b7-dg87j 1/1 Running 0 2m37s name=nginx,pod-template-hash=fbd97f5b7
nginx-dep-fbd97f5b7-fbk6s 1/1 Running 0 2m37s name=nginx,pod-template-hash=fbd97f5b7
nginx-dep-fbd97f5b7-qkvzw 1/1 Running 0 2m37s name=nginx,pod-template-hash=fbd97f5b7
[root@master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-dep-fbd97f5b7-dg87j 1/1 Running 0 4m49s 10.244.2.5 node1 <none> <none>
nginx-dep-fbd97f5b7-fbk6s 1/1 Running 0 4m49s 10.244.2.4 node1 <none> <none>
nginx-dep-fbd97f5b7-qkvzw 1/1 Running 0 4m49s 10.244.1.2 node2 <none> <none>
[root@master ~]# curl 10.244.2.5
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
Deployment扩容:kubectl scale deployment 名称 --replicas=数量
[root@master ~]# kubectl scale deployment nginx-dep --replicas=10
deployment.apps/nginx-dep scaled
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-dep-fbd97f5b7-2shcs 1/1 Running 0 94s
nginx-dep-fbd97f5b7-cbws9 1/1 Running 0 94s
nginx-dep-fbd97f5b7-dg87j 1/1 Running 0 16m
nginx-dep-fbd97f5b7-fbk6s 1/1 Running 0 16m
nginx-dep-fbd97f5b7-kxtks 1/1 Running 0 94s
nginx-dep-fbd97f5b7-qkvzw 1/1 Running 0 16m
nginx-dep-fbd97f5b7-qskjr 1/1 Running 0 94s
nginx-dep-fbd97f5b7-wt59c 1/1 Running 0 94s
nginx-dep-fbd97f5b7-wzfdz 1/1 Running 0 94s
nginx-dep-fbd97f5b7-xjfrr 1/1 Running 0 94s
Deployment滚动更新:kubectl set image deployment/nginx-dep mynginx=nginx:1.23
[root@master ~]# kubectl set image deployment/nginx-dep mynginx=nginx:1.23
deployment.apps/nginx-dep image updated
[root@master ~]# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-dep-7f4688fd7f 5 5 0 39s
nginx-dep-fbd97f5b7 8 8 8 32m
注意:
- Deployment更新时,可以保证在期望值中,最多比不可用期望多一个不可用,最多比可用期望多出一个可用的
- 如果在一次更新中,更新前,原来的的Pod副本还未创建齐全,会直接kill掉已有的,直接创建新的!
一般来说一次会25%的Pod数量替换
Deployment回滚:kubectl rollout undo deployment/nginx-dep
[root@master ~]# kubectl rollout undo deployment/nginx-dep
deployment.apps/nginx-dep rolled back
查看当前Deployment回滚状态:kubectl rollout status deployment/nginx-dep
查看当前Deployment回滚历史:kubectl rollout history deployment/nginx-dep,此处如果在创建Deployment时没有加参数--record则回滚方式为NONE
指定回退版本:kubectl rollout undo deployment/nginx-dep --to-revision=2
暂停更新:kubectl rollout pause deployment/nginx-dep
Deployment更新历史记录保留策略
可以通过.spec.revisionHistoryLimit来指定保留多少次记录,默认会保留所有,如果设置为0则不允许回退(因为没有历史记录了)
查看上一条命令的执行结果,0表示成功
echo $?
1.4.3 DaemonSet

需要注意的是:虽然daemonset会在所有的节点上创建pod,但是不会在主节点上创建,因为主节点被默认打了污点,不会参与调度
1.4.4 Job & CronJob

查看pod的控制台显示日志:kubectl log Pod名称
Job Spec设置
- spec.template 和其他Pod一样
- RestartPolicy只支持Never or OnFailure
- 单个Pod时,运行成功Job结束
- spec.completions 标志Job结束需要成功几个Pod,默认为1
- spec.parallelism 标志并行运行Pod,默认为1
- spec.activeDeadlineSeconds 标志失败Pod最大重试时间,超过则停止重试
CronJob Spec
- spec.schedule 必填,指定运行周期,分时日月周
- spec.jobTemplate 必填,同Job
- spec.startingDeadlineSeconds 该字段指定如果在指定时间范围内,由于原因导致该job没有被执行,错过了调度时间,则被认为是失败
- spec.concurrencyPolicy 并发策略:(只控制当前CronJob,别的CronJob创建的不影响)
- Allow 允许
- Forbid 禁止,前一个没运行完,下一个跳过
- Replace 替换,取消当前,用新的替换
- spec.suspend 如果改成true,则后续的Job会挂起,之前的不影响
- spec.successfulJobsHistoryLimit 成功保留历史数,默认3个Job,0表示不保留
- spec.failedJobsHistoryLimit 失败保留数,默认1个,0表示不保留

注意:删除cronjob不会删除job,需要手动删除job,且cronjob无法判断job是否成功执行
1.5 service服务发现
通常对于多个副本的Pod提供一种服务的,k8s方案是在Pod上层提供一个service层,用于管理该服务,然后对外或其他Pod提供访问方式,简单来说,可以将提供一个服务的一组Pod加上service 层,看成一个服务去访问,这就是服务发现,用于管理集群中的服务
在创建一个SVC时,过程如下:
- apiserver接受创建指令,将请求写入etcd
- kube-proxy监听etcd中SVC和Pod信息变化,将新增的SVC地址和转发Pod规则写入iptables中
- 访问某个Pod时,通过iptables直接流量转发到目的Pod上
最终看起来就是:访问svc然后转发到对应pod
通常采用Label Selector进行管理Pod,匹配到标签后,Pod的信息会被写入到svc中,对外提供访问,策略是轮询
注意:SVC虽然能提供轮询的负载均衡机制,但是只能基于IP和端口进行转发,也就是4层负载均衡能力(没有7层,不能通过主机名或域名的方案去做),可以使用Ingress来支持7层
SVC有四种类型:
- ClusterIP:默认,自动分配一个集群内部可访问的虚拟网IP(VIP)
- Nodeport:在ClusterIP基础上为SVC在每个机器(Node)上绑定一个端口,这样可以通过NodeIP:NodePort来访问服务(增加一个Nginx反向代理到Node可以实现7层负载均衡)user->nginx->svc->pod
- LoadBalancer:在NodePort基础上借助云供应商创建外部负载均衡转发到NodePort上
- ExternalName:Pod访问外部是直接访问,如果外部服务IP、Port改变会影响服务,所以将外部的服务在集群内部建立一个SVC,用于记录外部服务的IP和端口,内部集群访问外部时去这个SVC上查询(相当于做了一个配置),外部改变时,只需要重新配置这个SVC,不用每个Pod都去改

首先kube-proxy会监控每个Pod的信息,按照标签分类将信息写入iptables中
apiserver通过监控kube-proxy来实现服务的发现
在用户访问某个服务时,访问的是iptables,重定向到某个Pod完成访问
k8s在1.14版本中默认使用ipvs代理
为什么不实用DNS进行负载均衡?因为DNS有缓存,不会及时更新
代理模式分类:
- userspace:Pod_x->iptables->kube-proxy->SVC->Pod_y
- iptables:Pod_x->iptables->SVC->Pod_y,去掉了kube-proxy的中间代理
- ipvs:用ipvs代替了iptables,因为iptables插入数据过多性能不佳,ipvs实现了snat,借助iptables又实现了dnat
ipvs和iptables都是防火墙配置工具,ipvs支持dnat
1.5.1 ipvs代理模式
kube-proxy监控SVC和Endpoints,调用netlink接口创建ipvs规则,并与SVC和Endpoints同步ipvs规则
ipvs使用哈希表作为底层数据结构,并在内核空间工作,可以更快的重定向流量,同步时也有更好的性能,支持多重负载均衡算法:
- rr 轮询
- lc 最小链接
- dh 目标哈希
- sh 源哈希
- sed 最短期望延迟
- nq 不排队调度
注意:ipvs模式要求kube-proxy启动前,节点需要安装ipvs内核模块,并已ipvs代理模式启动,启动时如果验证节点未安装ipvs,kube-proxy会退回到iptables代理模式
1.5.2 Service实验
先创建Deployment,副本数3:
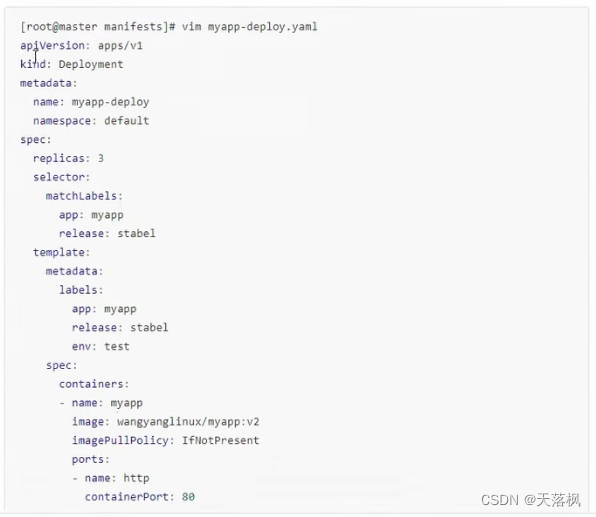
创建Service:

kubectl delete -f 文件
可以通过这种方式去删除对应的资源(由该文件创建出来的)
headless service:

此时该service无法通过vip的方式进行访问,但是可以通过域名访问,通过查看coredns域名解析pod的解析,可以看到该service下确实管理着之前创建的Pod
NodePort:
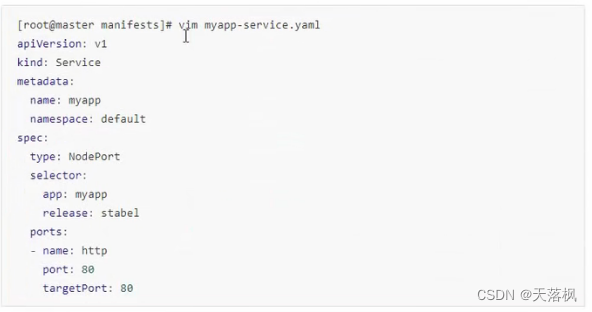
查询结果:kubectl get svc可以看到将80端口代理到了node的xxx端口,通过访问node的xxx端口即可访问Pod
LoadBalancer
和nodeport类似,只是在前面多了一层云服务商提供的负载均衡服务,由k8s的provider cloud去创建的LB,需要购买云服务商提供的LAAS服务
externalname
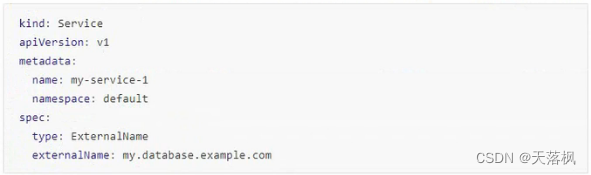
此时访问域名:SVC名称.命名空间.svc.cluster.local,会被集群内部DNS重定向到externalName指定的域名上,发生在DNS层,不会进行代理和转发(简单理解就是做了一个DNS的别名操作)
1.5.3 Ingress
案例背景:如果对外需要提供一个HTTPS的连接,SVC是没有这个功能的,只能在每个Pod上都要配置HTTPS连接才行
而如果在集群外部配置一个Nginx,Nginx对外可以采用HTTPS连接,对内反向代理采用HTTP连接,这样就可以实现了。(但是外部Nginx和集群是HTTP,所以其实还是有一定风险的)
因此,最优方案是:外部访问集群使用的HTTPS,集群内部提供一个Nginx去做反向代理到不同的SVC,Ingress就是做这样的事。
注意:为什么不自己在内部部署一个nginx服务去做这个呢,因为ingress的nginx配置文件是会自动生成对应的SVC反向代理,无需手动配置。
Ingress内部逻辑:
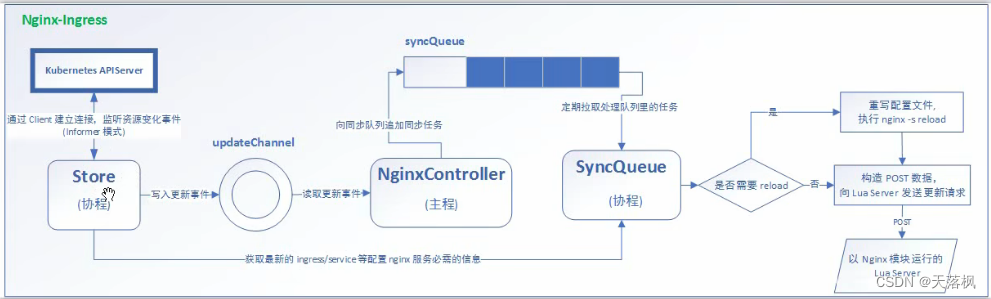
如果需要高可用,建议将master做主备,然后再在外部使用Nginx做负载均衡连接两台master,master内部通过ingress-nginx做内部的Pod的负载均衡
部署Ingress-Nginx
# 启动ingress 控制器
kubectl apply -f mandatory.yaml
# 设置为nodeport暴露方式
kubectl apply -f service-nodeport.yaml
参考:https://kubernetes.github.io/ingress-nginx/deploy
Ingress HTTP访问
deployment service ingress 配置
apiVersion: extension/v1beta1
kind: Deployment
metadata:
name: nginx-dm
spec:
replicas: 2
template:
metadata:
labels:
name: nginx
spec:
containers:
- name: nginx
image: xxxx/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
spec:
port:
- port: 80
targetPort: 80
protocol: TCP
selector:
name: nginx
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: nginx-test
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /
backend:
serviceName: nginx-svc
servicePort: 80
执行:kubeclt apply -f ingress.http.yaml
# 查看当前创建的svc
kubectl get svc # 可以直接访问下集群的svc地址获取服务
# 查询当前ingress在宿主机上暴露出去的端口
kubectl get svc -n ingress-nginx
# 查看当前的ingress
kubectl get ingress
此时当前NodePort模式暴露后,可以在主机上配置好DNS访问:nodeIP foo.bar.com
宿主机上访问:foo.bar.com:ingress暴露的端口
宿主机访问域名,其实相当于访问nodeport的ip,然后ingress暴露了端口给nodeport,所以外部可以通过这个端口访问到ingress,而ingress代理访问了内部svc的端口和地址,svc又可以访问到pod,服务就联通了
与直接使用svc比,ingress还可以通过不同路径来访问不通服务,svc必须通过不通的域名或者ip来访问不同服务
ingress HTTPS访问
首先需要创建证书:
openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=nginxsvc/O=nginxsvc"
kubectl create secret tls tls-secret --key tls.key --cert tls.crt
创建ingress:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: nginx-test
spec:
tls:
- hosts:
- foo.bar.com
secretName: tls-secret
rules:
- host: foo.bar.com
http:
path:
- path: /
backend:
seviceName: nginx-svc
servicePort: 80
Nginx BasicAuth
对Nginx进行基础授权认证,在进入网站时弹出用户名和密码框
yum -y install httpd
htpasswd -c 文件名 用户名
kubectl create secret generic basic-auth --from-file=文件名
这里使用文件名:auth,用户名:foo
apiVersion: extensions/b1beta1
kind: Ingress
metadata:
name: ingress-with-auth
annotations:
nginx.ingress.kubernetes.io/auth-type: basic
nginx.ingress.kubernetes.io/auth-secret: basic-auth
nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required - foo'
spec:
rules:
- host: foo2.bar.com
http:
path:
- path: /
backend:
seviceName: nginx-svc
servicePort: 80
Nginx 重写

apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: nginx-test
annotations:
nginx.ingress.kubernetes.io/rewrite-target: http://foo.bar.com:31795/hostname.html
spec:
rules:
- host: foo10.bar.com
http:
path:
- path: /
backend:
seviceName: nginx-svc
servicePort: 80
1.6 网络空间
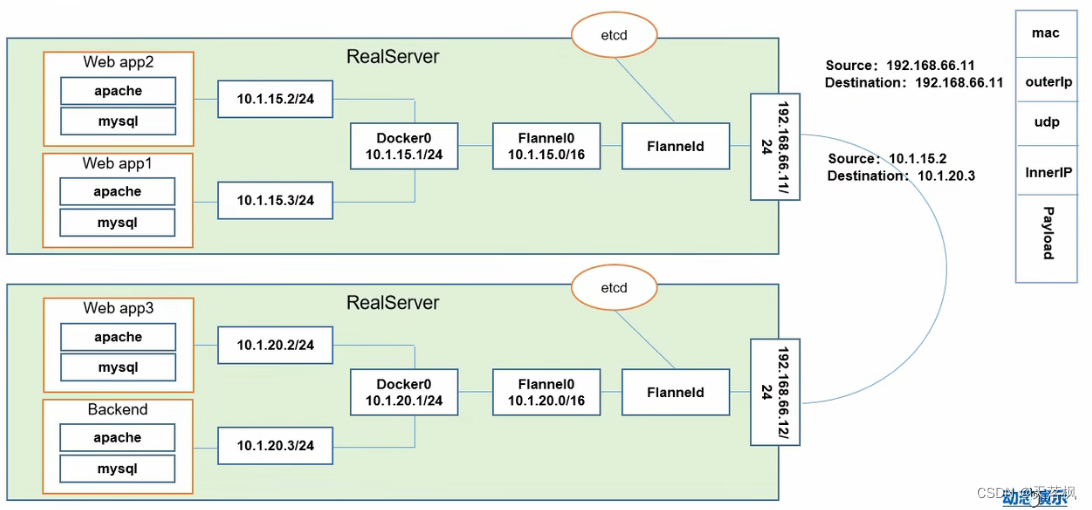
k8s模型是假定所有Pod都在一个可以直接连通的扁平化的网络空间中,所以,搭建集群时,我们必须确保不同节点上的Docker互相打通。(flannel可以实现扁平网络空间)
网络通讯示意图

同一个Pod内的多个容器之间的通讯:lo(本地回路localhost,即docker0组成的虚拟网桥)
Pod之间的通讯:Overlay Network
Pod与Service通讯:各节点的Iptables规则(建议使用LVS,性能更好)
Pod与外网访问:通过查找路由表,转发到宿主几网卡,然后网卡执行Masquerade,将源IP改为宿主机IP,向外部发送请求(SNAT)
外网与Pod访问:通过Service
Etcd和Flannel之间的关系:
- 存储管理flannel可分配地址段资源
- 监控Etcd中每个Pod实际地址,并建立Pod节点路由表
Flannel:CoreOS团队创建,让集群不同Node上的Docker有集群唯一IP,且创建一个Overlay Network,让数据包可以原封不动的从一个容器传送到另一个容器内
1.7 资源
k8s中所有内容都被抽象为资源,资源实例化后,叫做对象
名称空间级别
工作负载类型资源:Pod、RS、Deployment、StatefulSet、DaemonSet、Job、CronJob
服务发现及负载均衡类型资源:Service、Ingress
配置与存储资源:Volume、CSI(容器存储接口,可扩展第三方卷存储)
特殊类型存储娟:ConfigMap(当配置中心来使用)、Secret(保护敏感数据)、DownwardAPI(把外部信息输出给容器)
集群级别
Namespace
Node
Role
ClusterRole
RoleBinding
ClusterRoleBinding
元数据级别
HAP
PodTemplate
LimitRange
YAML文件语法tips
对象类型可以写成:hash: { name: pp, age: 18 }
或hash: name: pp age: 18数组类型可以写成:animal: [Cat, Dog]
或animal: - Cat - Dog类型强制转换:!!类型
a: !!str 123 b: !!str true类型:
字符串:可以不用引号,但如果有特殊字符需要放在引号中,且双引号不会对特殊字符转义,单引号中如果还有单引号必须使用两个单引号来表示
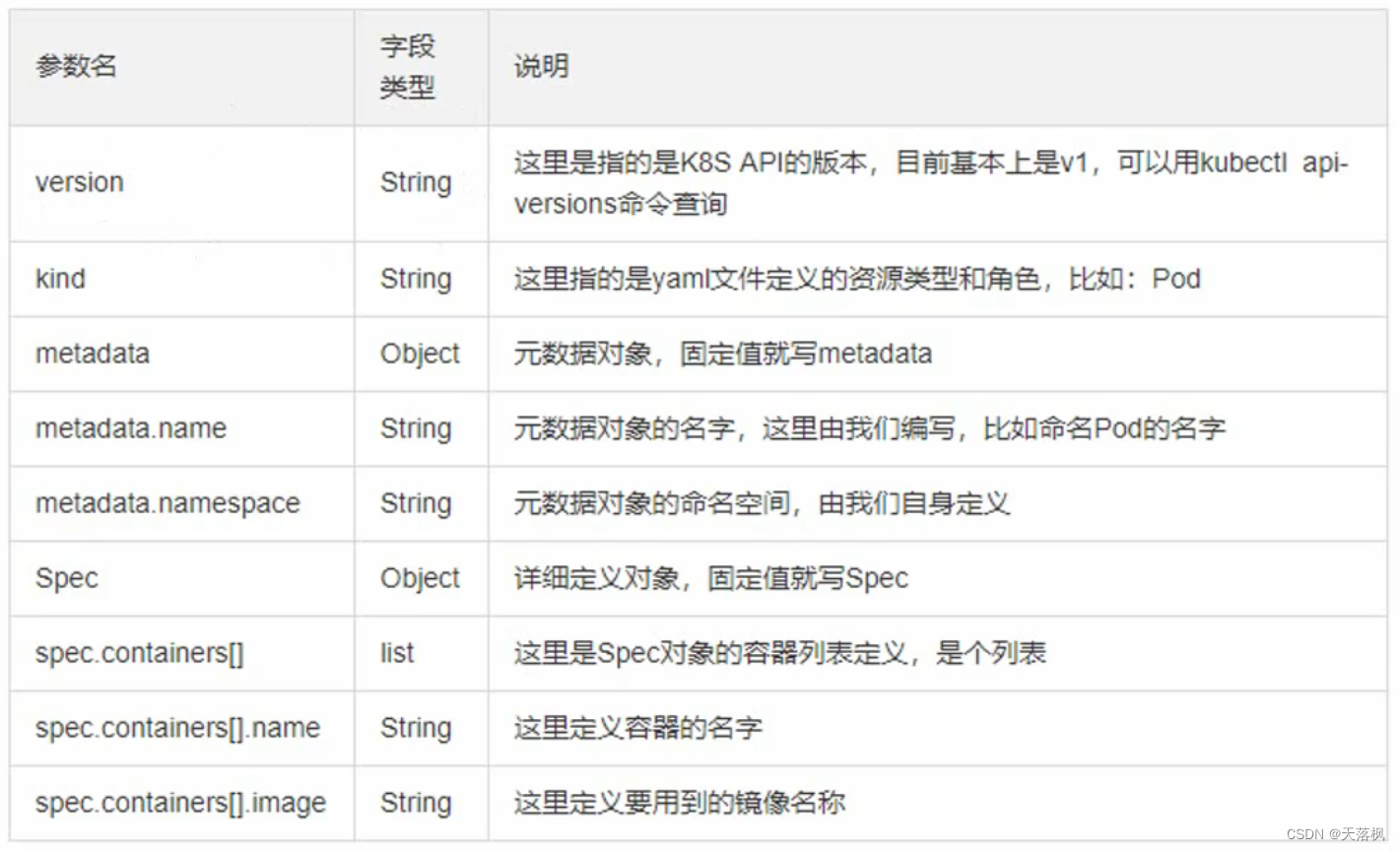
k8s定义一个Pod所需yml配置文件的必填字段类型及含义:
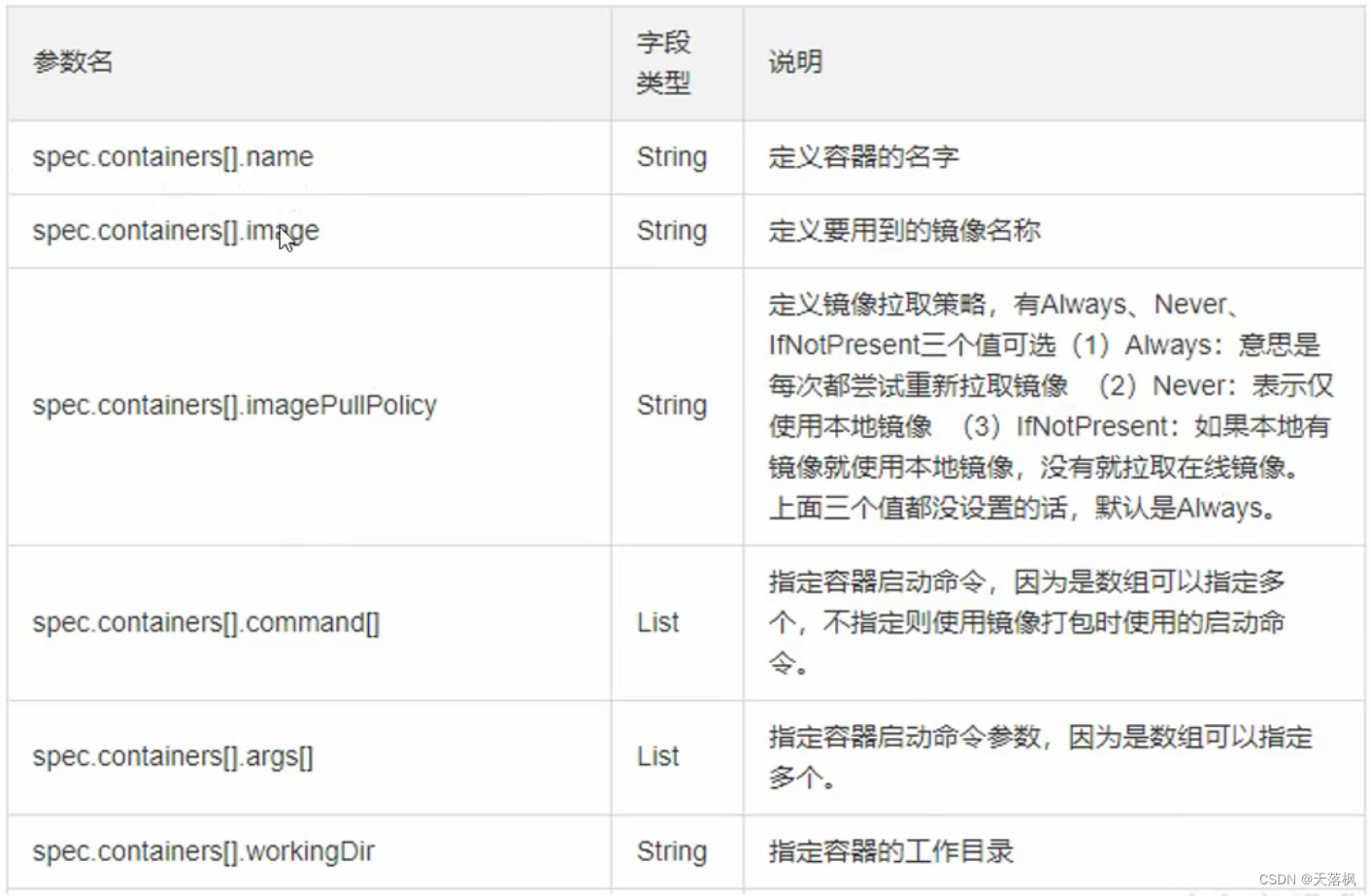
重要的一些参数:
此处提供一个Pod模板供参考:
apiVersion: v1
kind: Pod
metadata:
name: myapp
labels:
app: myapp
version: v1
spec:
containers:
- name: app
image: localhost:5000/xiaopi3/httpd:v1
- name: test
image: localhost:5000/xiaopi3/httpd:v1
注意:如果镜像下载策略为默认的即always,且镜像没有版本号或版本号为latest,则容器每次都会拉取最新镜像进行下载
1.8 容器生命周期
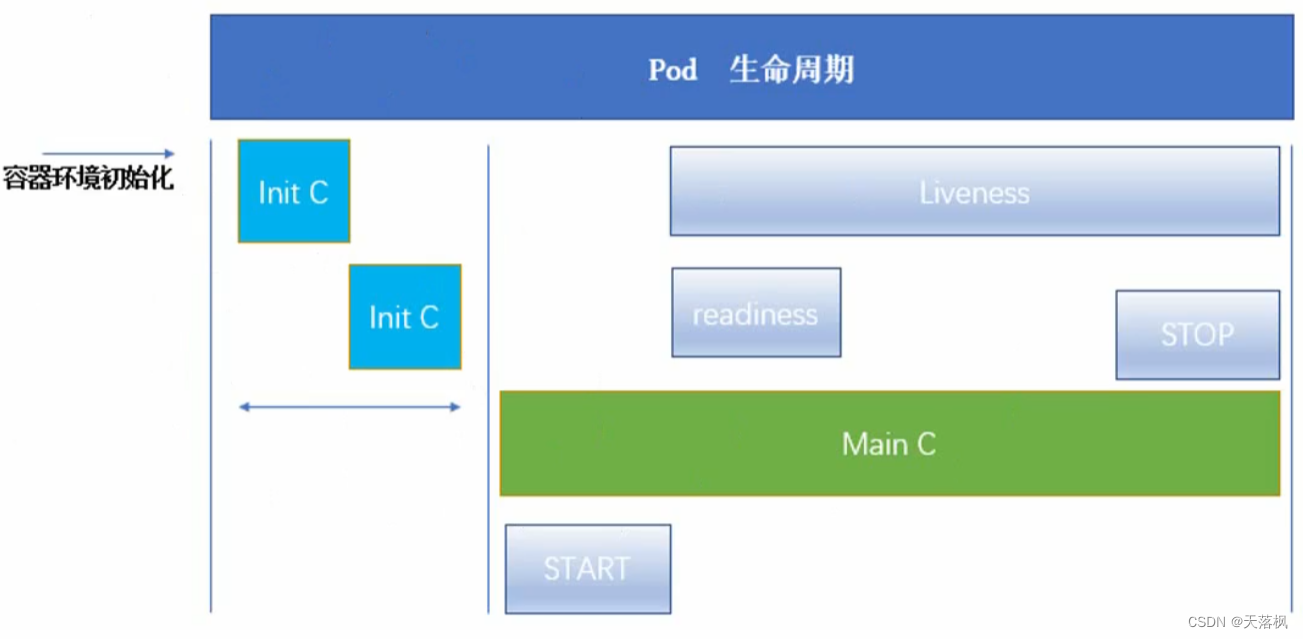
在容器启动前有很多initC容器进行容器环境初始化
有很多探测,在生命周期中会进行检测
start:容器启动
readiness:容器就绪,可提供服务了
liveness:容器生存
stop:容器停止
init容器
与普通容器很像,必须运行到成功为止,且串行,前一个必须成功才会运行后一个,如果没有成功运行,则pod会重启,直到成功。如果pod对应restartPolicy策略为Never,则不会重启
- 将主容器的运行环境准备好(如安装工具、配置文件),放在init C中,用于主容器运行前的环境初始化
- init C可以赋予和主容器不同的权限,如可以访问到更机密的文件用于创建环境,而不用给主容器该权限
- init C有启动顺序,且串行,不同于主容器的并行,所以可以执行一些有前提的程序,直到满足条件才启动主容器
简单理解:A容器需要访问B容器才能启动,如果AB同时启动,有可能导致A容器启动失败(B并未ready),可以在A容器启动前加入【探测B容器是否正常运行的探测程序】作为init C,然后启动AB即可
init模板
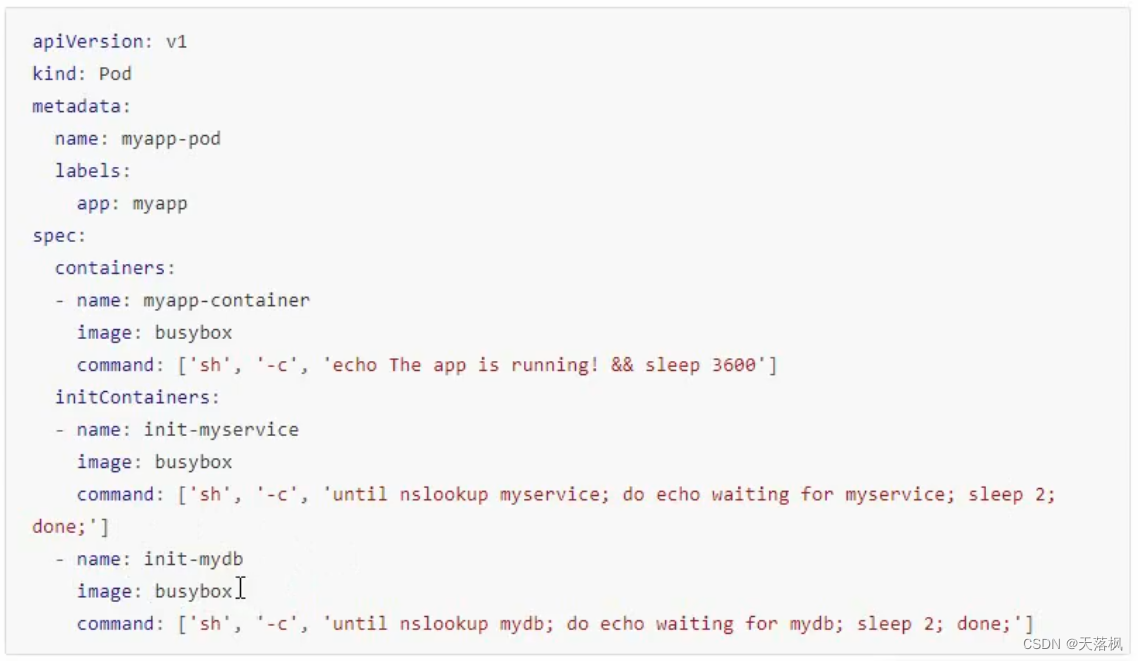
启动两个init C,直到两个都成功结束才会运行主容器,此处必须启动下面这个两个pod才能让init C检测通过(成功运行的含义是容器退出代码为0)

需要注意的是:
- Pod在启动过程中,最先启动的是pause容器,初始化网络和数据卷,然后再启动init C,最后启动主容器
- init C会采用Pod的重启策略restartpolicy
- init C执行过程中,Pod状态为Pending,执行完毕,Pod才会变成Ready,在这之前,Service中都不会收集该Pod的端口
- Pod重启,init C需要重新执行
- 对正在运行的Pod进行edit,如果修改init容器的image字段,则整个Pod会重新启动
- init C和主容器所具有的字段一样,除了readinessProbe字段没有
- init C名字要在当前Pod中唯一,端口可重复
1.8.1 容器hook
容器探针
由kubelet对容器发起定期诊断,有三种探测方式:
- ExecAction:在容器中执行命令,返回0则成功
- TCPSocketAction:对指定端口上的容器的IP地址进行TCP检查,如果端口打开则成功
- HTTPGetAction:对指定端口和容器IP执行HTTPGET请求,响应码>=200 <400,则成功
注意:诊断结果有三种:成功、失败、未知。未知不会采取任何行动
探测策略有两种:
- livenessProbe:指示容器正在运行,如果探测失败,kubelet会kill容器,如果容器不提供存活探针,则默认状态为success,容器指示RUNNING状态
- readinessProbe:指示容器是否准备好提供服务,如果失败,【端点控制器】会将与Pod匹配的所有Service的端点中删除该Pod的IP,在初始延迟前状态默认为Failure,如果容器不提供就绪探针,默认为success,容器指示Ready状态
注意:两种检测策略可以同时存在




生命周期hook

1.8.2 Pod状态含义
- Pending:Pod被集群控制中,但有容器还在创建中,或者镜像下载中
- Running:Pod已经绑定到节点了,所有容器都被创建了,至少有一个容器在运行或者处于启动或者重启状态
- Succeeded:Pod中所有容器都已终止,全部正常结束,且不会再重启
- Failed:Pod中所有容器都已终止,且存在容器失败终止的情况
- 未知:无法取得Pod状态,通常网络问题